重新训练
:使用通用数据和领域数据混合,from scratch(从头开始)训练了一个大模型,最典型的代表就是BloombergGPT。
二次预训练
:在一个通用模型的基础上做continue pretraining(继续预训练,二次预训练),像LawGPT就是做了二次预训练的。身边有很多人尝试过这个方案,但普遍反应效果一般(没有SFT来得直接),很有可能是数据配比的问题。
基础大模型微调
:在一个通用模型的基础上做instruction tuning(sft),这也是现在开源社区最普遍的做法,有大量的工作比如Huatuo,ChatLaw等等。这种做法的优势是可以快速看到不错的结果,但会发现要提高上限比较困难。
通用大模型+向量知识库
:领域知识库加上通用大模型,针对通用大模型见过的知识比较少的问题,利用向量数据库等方式根据问题在领域知识库中找到相关内容,再利用通用大模型强大的summarization和qa的能力生成回复。
In context learning类似微调
:直接用in context learning的方法,通过构造和领域相关的prompt,由通用大模型直接生成回复。随着业界把context window越做越大,prompt中可以放下越来越多的领域知识,直接用通用大模型也可以对领域问题有很好的回复。
以上对硬件资源+数据 的消耗也是不同的:
可以像【重新训练】一样几乎重新训练一遍模型,需要几百张卡
也可以像【基础达模型微调】一样用几百条数据做做sft,可能几张卡就够了
目前很多没有技术团队的大模型解决方案,会以【基础达模型微调】+【向量知识库】为主。
以下是垂直领域可能会覆盖的任务:

如果选择【重新训练大模型】那要面临的资源需求变得异常苛刻:
训练的硬件资源要求
垂直领域最难的应该就是准备数据,现在基本上都是这样的指令数据结构:
{"instruction": instruction, "input": input, "output": output}
如果你只有5k数据,建议你在Chat模型上进行微调;
如果你有10w数据,建议你在Base模型上进行微调。
同时在训练的时候,如果是chat需要保持与之前chat模型一致的数据结构
【重新训练的训练数据配比很重要】
BloombergerGPT,就会发现模型的能力其实很差,比通用大模型会差很多。这里面犯的最大的错误就是数据配比,他们应该是用1:1的比例混合通用数据和金融数据。
首先,不知道他们对金融数据是如何清洗和保证数据质量的,个人觉得他们500B的金融数据质量可能是低于500B的通用数据的质量的,这个对模型最后能力的局限有比较大的影响,通用数据和金融数据必须是用同样的标准做了高质量清洗和质量控制的。
其次,1:1的数据比例大概率是一个很差的选择。对于复现chatgpt3.5来说,数据配比应该是OpenAI最核心的秘密和比别人领先最后的地方。和很多OpenAI的人员交流下来,他们在这块做了大量的实验并积累了大量的经验。
【二次预训练】领域数据比例要在15%以下
对continue pretraining来说,如果要让模型不丢失通用能力,比如summarization,qa等,「领域数据的比例要在15%以下」,一旦超过这个阈值,模型的通用能力会下降很明显。
和不少同行交流下来,感觉大家的范围都在10%-15%左右。而且,该阈值和预训练模型的大小,预训练时原始数据的比例等条件都息息相关,需要在实践中反复修正(这个时候就能看出scaling law的重要性了)。
这个结果其实和ChatGPT大概用不到10%的中文数据就能得到一个很不错的中文模型的结果还挺相似的。
这个经验也告诉我们不要轻易用continue pretraing或者from scratch pretraining的方法做行业大模型,每100B的领域数据,需要配上700B-1000B的通用数据,这比直接训练通用大模型要困难多了。
【基础大模型微调】大概领域数据和通用数据比例在1:1的时候还是有不错的效果的
对sft来说,这个比例就可以提高不少,大概领域数据和通用数据比例在1:1的时候还是有不错的效果的。当然,如果sft的数据量少,混不混数据的差别就不太大了。所以说,做pretraining不仅耗资源,需要大量的卡和数据,还需要大量的实验去调数据配比。每次有人和我说通过pretraining的方法做了行业大模型的时候,我通常是不信的。做sft不是香多了吗?
领域数据训练后,往往通用能力会有所下降,需要混合通用数据以缓解模型遗忘通用能力。
如果仅用领域数据进行模型训练,模型很容易出现灾难性遗忘现象,通常在领域训练过程中加入通用数据。那么这个比例多少比较合适呢?目前还没有一个准确的答案,BloombergGPT(从头预训练)预训练金融和通用数据比例基本上为1:1,ChatHome(继续预训练)发现领域:通用数据比例为1:5时最优。个人感觉应该跟领域数据量有关,当数据量没有那多时,一般数据比例在1:5到1:10之间是比较合适的。
现有大模型在预训练过程中都会加入书籍、论文等数据,那么在领域预训练时这两种数据其实也是必不可少的,主要是因为这些数据的数据质量较高、领域强相关、知识覆盖率(密度)大,可以让模型更适应考试。当然不是说其他数据不是关键,比如领域相关网站内容、新闻内容都是重要数据,只不过个人看来,在领域上的重要性或者知识密度不如书籍和技术标准。
大模型的训练成本,以GPT-3为例:GPT-3需要400-500个A100/年(用400-500张A100训1年),假设不买显卡,租公有云,现在8张A100包年的价格大概一年80万,一次性走量打五折40万,训练GPT-3的成本大概是2500万人民币。
上面的讨论是按照GPU跑满100%的使用率来计算,实际上GPU永远是有被浪费的时候,浪费的原因可能是:
显卡不稳定,可能会挂掉
由于显卡容易挂掉,需要做checkpointing,而每次checkpoint的保存可能也需要分钟级别的时间成本
CUDA core大多数时候也是跑不满的,需要等显存带宽的I/O、 IB网络的I/O等等
上一条先在在小模型上做实验的方法,又会遇到在小模型上的实验挺好,但一到100B这个级别就会发现各种loss的不收敛/猛增/飞掉的问题。采用的策略可能是回退几步,或者扔掉这一部分数据,然后接着往前走。
FP32/FP16/BF16的选择问题:更倾向于BF16,因为看起来更好收敛。
在硬件的选择上,尽可能用最先进的显卡进行训练,因为:第一,性能上的差异巨大,以A800和H100为例,算力差了六倍,然后通信带宽也差了两倍;第二,在落后的显卡上去训练,需要考虑更多的分布式问题,而将来迁移到高端显卡上的时候,在老显卡上累积的经验能直接用上的不多。
并行计算方案的选择:Megatron-DeepSpeed是现在比较SOTA的一个方案。
团队组织上:算法研究员们更喜欢用Pytorch去反复调它的模型架构,但最后还需要工程人员把这些调整翻译到Megatron这套框架上,因此现阶段更倾向于算法人员和工程人员大家彼此知识是交融的,坐下来一起去讨论如何去实现。
通过人工标注,然后纯做finetune,可以达到八成效果。但是想走的更远的话,那只能靠强化学习。
奖励模型(RM)训练叫做reward hacking的现象,开放的决策对于模拟打分环境来说难度太大了,对奖励模型的泛化程度有极其高的要求。最终大概率你的模型学习到了输出一堆没什么用的东西,但是RM分数很高。这就是reward hacking(来自 【大模型训练的一些坑点和判断】 )
评估的问题:同时模型的评估也是一个可能会有坑点的地方:
评估做不好 = 费钱费时;所以你做实验慢了,相当于比别人少了GPU
过拟合的问题:只用领域数据非常容易过拟合到领域数据上,对OOD的处理会表现的非常差。对各个环节的数据配比要求会很高,最好是在原来规模程度的数据上,增加额外的场景数据,重新走部分流程。但是困难的是,原有数据保持分布的采样,你拿到的模型是个黑盒,别人并没有给你原始的数据分布,更何况海涉及到了惊细的清洗。有可能整体要付出的成本不下于重新塑造一个通用大模型。
大模型LLM微调经验总结&项目更新
有这么三种大模型训练的方式:无参、少参数、全参数
In-Context Learning(ICL) (参考:In-context Learning学习笔记)
对大模型进行全量参数训练,主要借助DeepSpeed-Zero3方法,对模型参数进行多卡分割,并借助Offload方法,将优化器参数卸载到CPU上以解决显卡不足问题。
Freeze方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或多卡,不进行TP或PP操作就可以对大模型进行训练。
PT方法,即P-Tuning方法,参考ChatGLM官方代码 ,是一种针对于大模型的soft-prompt方法。
Lora方法,即在大型语言模型上对指定参数(权重矩阵)并行增加额外的低秩矩阵,并在模型训练过程中,仅训练额外增加的并行低秩矩阵的参数。当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量也就很小
大模型训练团队的人员配置:
大模型项目团队和传统的大项目团队最大的不同在于:传统的大项目需要堆一大批人;而大模型的特点是极少量的idea要指挥的动极大的资源,因此团队必然精简,不可能使用人海战术。
根据BigScience的经验,可以总结出几种类型的团队人员配置:
数据这块大概就是大数据工程师加少量的法务人员。大数据工程师可能偏数据工作,法务人员可能观察一下比如说数据的 license 是否合理。
不超过10个的 NLP 算法工程师,他们更关心模型架构以及训练过程中所有的超参的选型。
分布式训练系统的开发工程师,负责把训练框架给支起来,协调、运维和管理这么多机器。
可能还需要少量的前后端开发,例如一到两个人,负责做一些数据相关的工具。
【播客笔记】大模型是如何炼成的-训练篇
大模型训练的一些坑点和判断
垂直领域大模型的一些思考及开源模型汇总
大模型LLM微调经验总结&项目更新
领域大模型-训练Trick&落地思考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:
http://www.liansuoyi.cn/news/60672736.html
如若内容造成侵权/违法违规/事实不符,请联系连锁易网进行投诉反馈email:xxxxxxxx@qq.com,一经查实,立即删除!
相关文章
MySQL 之 瓶颈及优化篇数据库瓶颈阶段一:企业刚发展的阶段,最简单,一个应用服务器配一个关系型数据库,每次读写数据库。
阶段二:无论是使用 MySQL 还是 Oracle 还是别的关系型数据库,数据库通常不会先成为性能瓶颈,通常随着企业规模的扩大,一台应用服务器扛不住上游过来…
春节前后,员工流动性增加,企业确实需要特别关注离职员工可能带来的数据安全风险。离职员工,尤其是那些掌握核心商业秘密或敏感信息的员工,可能在离开公司时有意或无意地带走或泄露这些信息。为了防范这种风险,企业可以采取以下措施:提前预警:对即将离职的员工进行预警,…
1、硬链接
硬连接指通过索引节点号来进行连接。
inode是可以对应多个文件名的在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。
在Linux中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬连接。
硬连接…
scikit-learn是一个用于Python的机器学习库,提供了大量用于数据挖掘和数据分析的工具。以下是对这些函数和方法的简要描述:clear_data_home: 清除数据集目录的内容。
dump_svmlight_file: 将数据集保存为SVMLight格式的文件。
fetch_20newsgroups: 下载20个新闻组的文本数据集…
数据可视化,作为信息时代的一项重要技术,正在企业中崭露头角,逐渐成为业务决策和运营管理的得力助手。企业之所以对数据可视化如此重视,是因为它为企业带来了诸多实际利益和战略优势。下面我就以可视化从业者的角度来简单聊聊这个话题。首先,数据可视化为企业提供了更直观…
cp [options] source dest或cp [选项] 源文件 目标文件选项说明:-a:此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于 dpR 参数组合。
-d:复制时保留链接。这里所说的链接相当于 Windows 系统中的快捷方式。
-r 或 --recursive:用于…
前言
生成分布式唯一ID的方式有很多种如常见的有UUID、Snowflake(雪花算法)、数据库自增ID、Redis等等,今天我们来讲讲.NET集成IdGenerator生成分布式全局唯一ID。
分布式ID是什么?
分布式ID是一种在分布式系统中生成唯一标识符的方法,用于解决多个节点之间标识符重复或性…
人类与机器学习1. 人类与机器学习的关键差距
1.1. 老式人工智能使用的是人类程序员对智能行为构建的显性规则
1.2. DNN这种“从数据中学习”的方法已被逐渐证实比“普通的老式人工智能”策略更成功
1.3. ConvNets的学习过程与人类的学习过程并不是很相似
1.3.1. ConvNets在多个…
Axure rp9入门图文教程-基操及介绍免费版安装包请点击此处(避免审查,请点击这)[^这里]
一、界面介绍1. 复制、剪切及粘贴区域
2. 选择模式
3. 插入形状
4. 控点(编辑控点)
5. 置顶和置底
6. 组合和取消组合
7. 调整大小
8. 对齐
9. 预览、共享
10. 元件样式
11. 文本设置
…
1.将下载的iconfont包,解压缩放到assets目录下,并且建立一个iconfont.wxss文件; 2.在app.json文件中引用(全局可用),
@import /assets/iconfont/iconfont.wxss;
3.iconfont.wxss内部结构:
如果下面这种情况,不能用@font-face {font-family: "iconfont"; /* P…
1.题目介绍
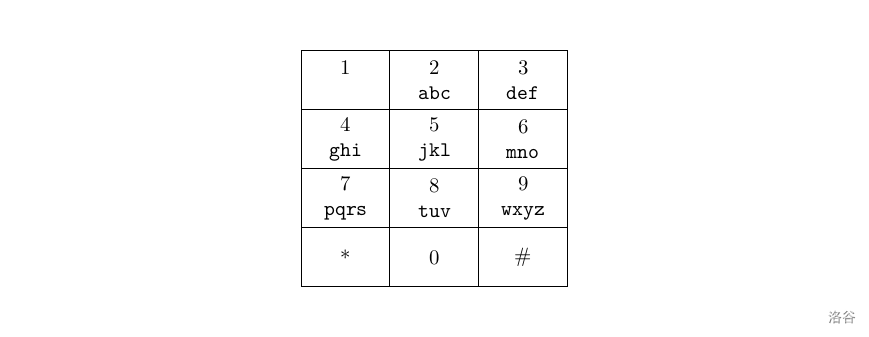
一般的手机的键盘是这样的:要按出英文字母就必须要按数字键多下。例如要按出 \(\tt x\) 就得按 \(9\) 两下,第一下会出 \(\tt w\),而第二下会把 \(\tt w\) 变成 \(\tt x\)。\(0\) 键按一下会出一个空格。
你的任务是读取若干句只包含英文小写字母和…
使用 eBPF 来进行可观测性需要进行应用层协议解析,但云上微服务软件架构中的应用层协议往往比较复杂,这也给协议解析带来了不小的挑战。传统的协议解析方式存在 CPU、内存占用高,错误率高等问题,在应用监控 eBPF 版中,我们提出一种高效的协议解析方案,实现对应用层协议的…
五、TIM定时器
TIM简介TIM(Timer)定时器
定时器可以对输入的时钟进行计数,并在计数值达到设定值时触发中断
16位计数器、预分频器、自动重装寄存器组成时基单元,在72MHz计数时钟下可以实现最大59.65s的定时
不仅具备基本的定时中断功能,而且还包含内外时钟源选择、输入捕获…
虚拟机开启仅主机模式一:前期准备
1.打开windows虚拟机,使用仅主机模式
(虚拟机(M)→设置(S)→网络适配器)2.修改Windows ip可选范围为192.168.1.204到192.168.1.207
对应地址池IP为192.168.101--200二:安装DHCP
1.从开始打开服务器管理器,点击添加角色与功能2点下一步直到…
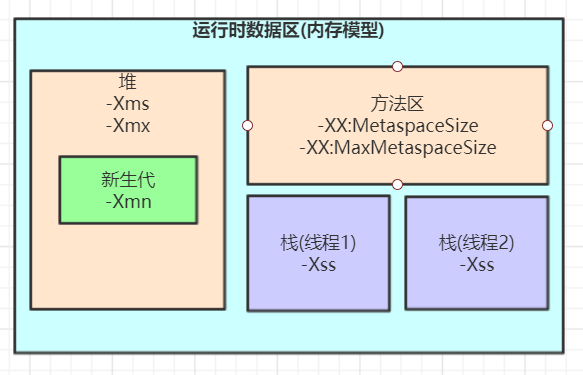
JVM内存模型JVM内存参数设置Spring Boot程序的JVM参数设置格式(Tomcat启动直接加在bin目录下catalina.sh文件里):
java -Xms2048M -Xmx2048M -Xmn1024M -Xss512K -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -jar xxx.jar
-Xss:每个线程的栈大小,默认1M
-Xms:设置堆…
\(\Huge{\textbf{「今日我们相聚于此」}}\)
\(\Huge{\textbf{「是为了纪念我们的警钟」}}\)
\(\Huge{\textbf{「她的牺牲对于整个蒟蒻而言」}}\)
$\Huge{\textbf{ 「值得长达 \(\textbf{eps}\) 秒的摆烂缅怀」}}$AC900寄:一种基于否定的否定仍然是否定的模拟bool方式提交4k寄:…
DataFrame对象可以从RDD转换而来,都是分布式数据集,其实就是转换一下内部存储的结构,转换为二维表结构将RDD转换为DataFrame方式1:
调用spark