

ChatGPT:RLHF(从人类反馈(或偏好)中强化学习)和 扩散模型

RLHF:
最近,从人类反馈(或偏好)中强化学习(RLHF(或RLHP)已成为人工智能工具包的一个巨大补充。这一概念已经在2017年的论文《 从人类偏好中深度强化学习 》中提出。最近,它被应用于ChatGPT和类似的对话代理,如BlenderBot3或Sparrow。这个想法很简单:一旦语言模型被预先训练,我们就可以对对话生成不同的响应,并让人类对结果进行排序。在强化学习的背景下,我们可以使用这些排名(又名偏好或反馈)来训练奖励。你可以在 Huggingface 或 Weights and Bias 的这两篇精彩文章中读到更多内容。
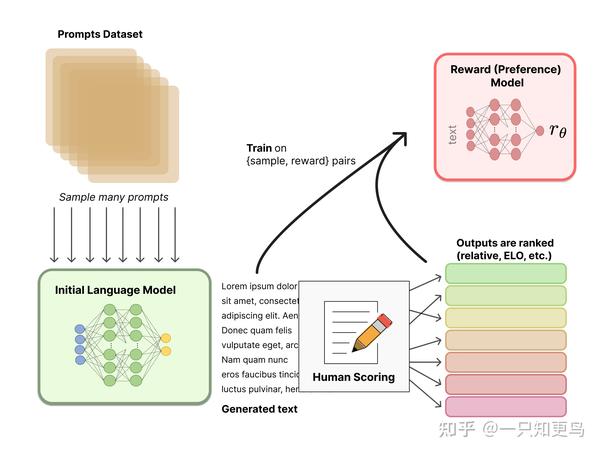
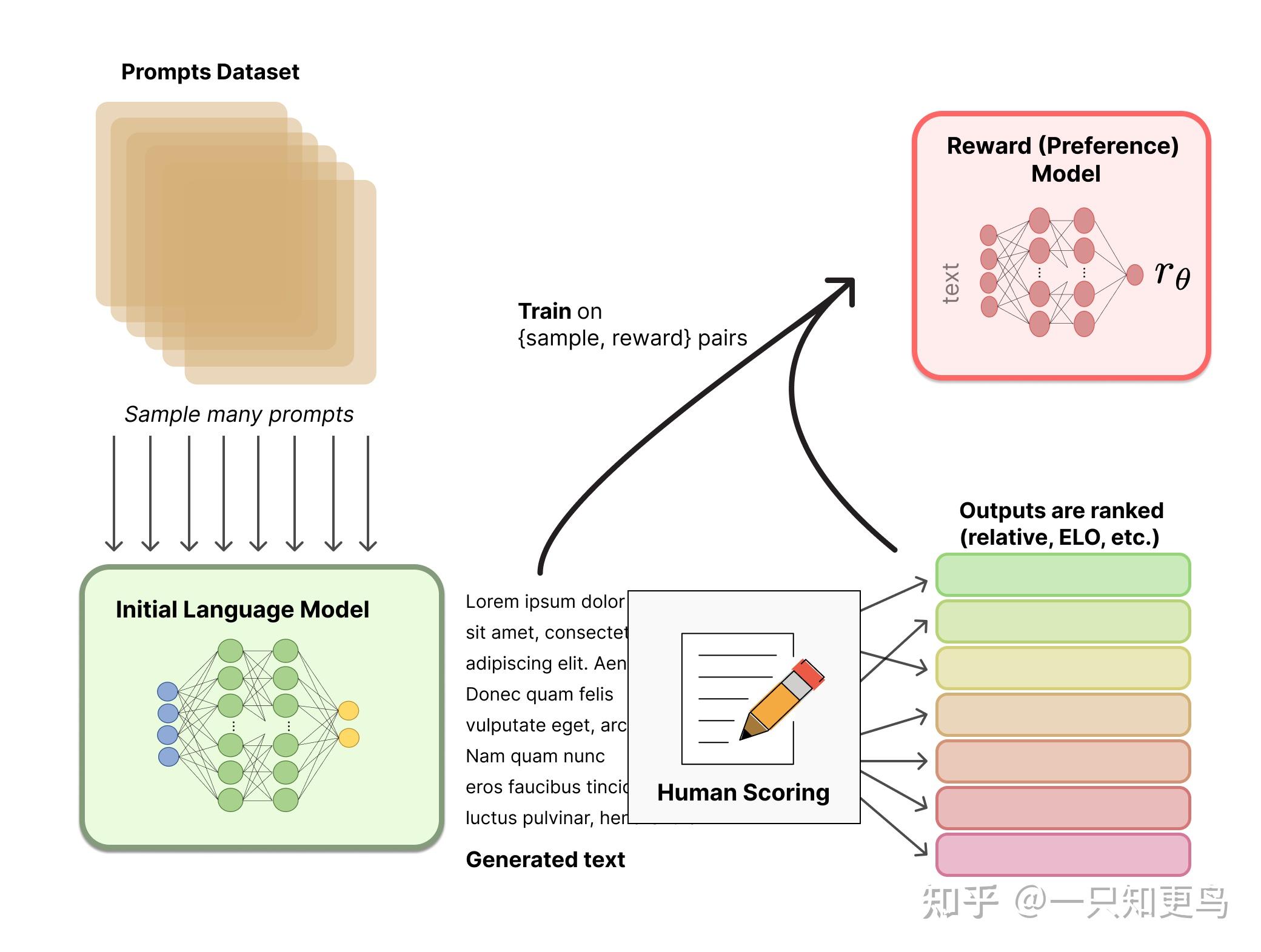
扩散模型:
扩散模型已经成为图像生成中的新SOTA,显然将之前的方法如生成对抗网络(GANs)推到了一边。什么是扩散模型?它们是一类潜变量模型训练的变分推断。在实践中,这意味着我们训练一个深度神经网络去噪一些噪声函数模糊的图像。以这种方式训练的网络实际上是在学习这些图像所代表的潜在空间。
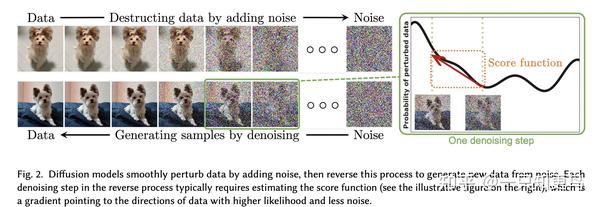

From “Diffusion Models: A Comprehensive Survey of Methods and Applications”
扩散模型与其他生成模型有关系,如著名的 生成对抗网络(GAN) ,它们在许多应用中大多被取代,特别是与(去噪)自动编码器。有些 作者 甚至会说扩散模型只是自动编码器的一个特定实例。然而,他们也承认,微小的差异确实改变了他们的应用,从自动考虑器的潜在表示到扩散模型的纯粹生成性质。
RLHF最详细的解释:
Illustrating Reinforcement Learning from Human Feedback (RLHF) (huggingface.co)