import pandas as pd
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
mpl.rcParams["axes.unicode_minus"] = False
try:
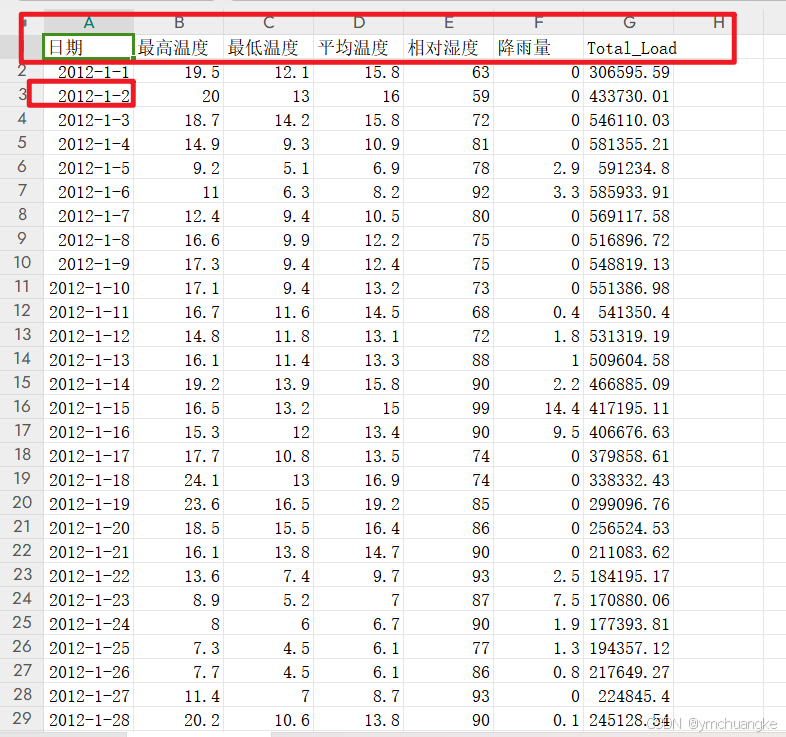
data = pd.read_csv('fuhe_load_total.csv', encoding='gbk')
except UnicodeDecodeError:
data = pd.read_csv('fuhe_load_total.csv', encoding='utf-8')
1. 引言
找出数据中的异常值是数据预处理的必备工作之一,如果数据中存在异常值对于一些数据分析算法具有重大的影响。
本文主要探讨关于寻找异常值(离群值)的注意事项。
2. 离群值
离群值是指跟大部分数据差异很大的样本。比如,在一项统计国民收入的例子中,少数富豪的收入就很像离群值。离群值对于一些数据分析方法会有很大的影响。我们不妨来举个栗子。
观察上图,为两个线性模型的分析结果,可以发现右侧只是增加一个离群值,我们的分析结果就会差很多。因此,如果没有处理好离群值,对于数据分析的结果可能会产生重大影响。
离群点,是一个数据对象,它显著不同于其他数据对象,与其他数据分布有较为显著的不同。有时也称非离群点为“正常数据”,离群点为“异常数据”。
离群点跟噪声数据不一样,噪声是被观测变量的随机误差或方差。一般而言,噪声在数据分析(包括离群点分析)中不是令人感兴趣的,需要在数据预处理中剔除的,减少对后续模型预估的影响,增加精度。
离群点检测是有意义的,因为怀疑产生它们的分布不同于产生其他数据的分布。因此,在离群点检测时,重要的是搞清楚是哪种外力产生的离群点。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-Means,BIRCH这些一般只适用于凸样本集的聚类相比,DBSCAN既可以适用于凸样本集,也可以适用于非凸样本集。这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。
使用场景: 用于不均匀的簇大小,以及非平坦的集合结构
欢迎来到我们全面的数据挖掘教程系列!在这里,我们为您精心准备了200多篇深入且实用的教程文档,旨在帮助您掌握数据挖掘的核心概念、技术和应用。无论您是初学者还是有经验的专业人士,这些教程都能满足您的学习需求。
教程涵盖了从基础的统计分析、数据预处理,到高级的机器学习算法、深度学习技术、自然语言处理等
数据处理和分析之数据预处理:异常值处理(DBSCAN算法在异常值检测中的应用)