오랜만에 블로그에 알림이 떠서 보니, 어떤 분 께서 예전에 올린 파이썬 웹크롤링 예제 글에 질문을 해주셨다.
포스팅을 열심히 했으나 생각보다 댓글이 없어서 흥미를 잃어갔는데 이렇게 반응해주시는게 감사해서,
일 마치고 밤에 바로 해결해 보았다.
2020/05/13 - [Programming/Python] - Python) 파이썬 BeautifulSoup4를 이용해 웹 크롤링 예제 만들어 보기
질문자의 요지는, 내가 포스팅한 bs4 웹크롤링 예제에서
AttributeError: 'NoneType' object has no attribute 'get_text'
라는 오류가 발생한다는 것이였다.
읽어보니, 크롤링한 정보에서 get_text로 빼올 것이 없다는 오류인 것 같아 원인을 찾아보았다.
문제가 된 부분은 코로나 확진자 정보를 받아오는 부분으로,
ncov.mohw.go.kr
코로나바이러스감염증-19(COVID-19)
코로나바이러스감염증-19 정식 홈페이지로 발생현황, 국내발생현황, 국외발생현황, 시도별발생현황, 대상별 유의사항, 생활 속 거리 두기, 공적마스크 공급현황, 피해지원정책, 홍보자료, FAQ, 관
ncov.mohw.go.kr
이 사이트에서 웹크롤링을 해오는 부분이였다. 오류를 보자마자 웹사이트의 html정보가 바뀌어서, 크롤링이 제대로 되지 않을 가능성이 가장 크다고 생각했다.
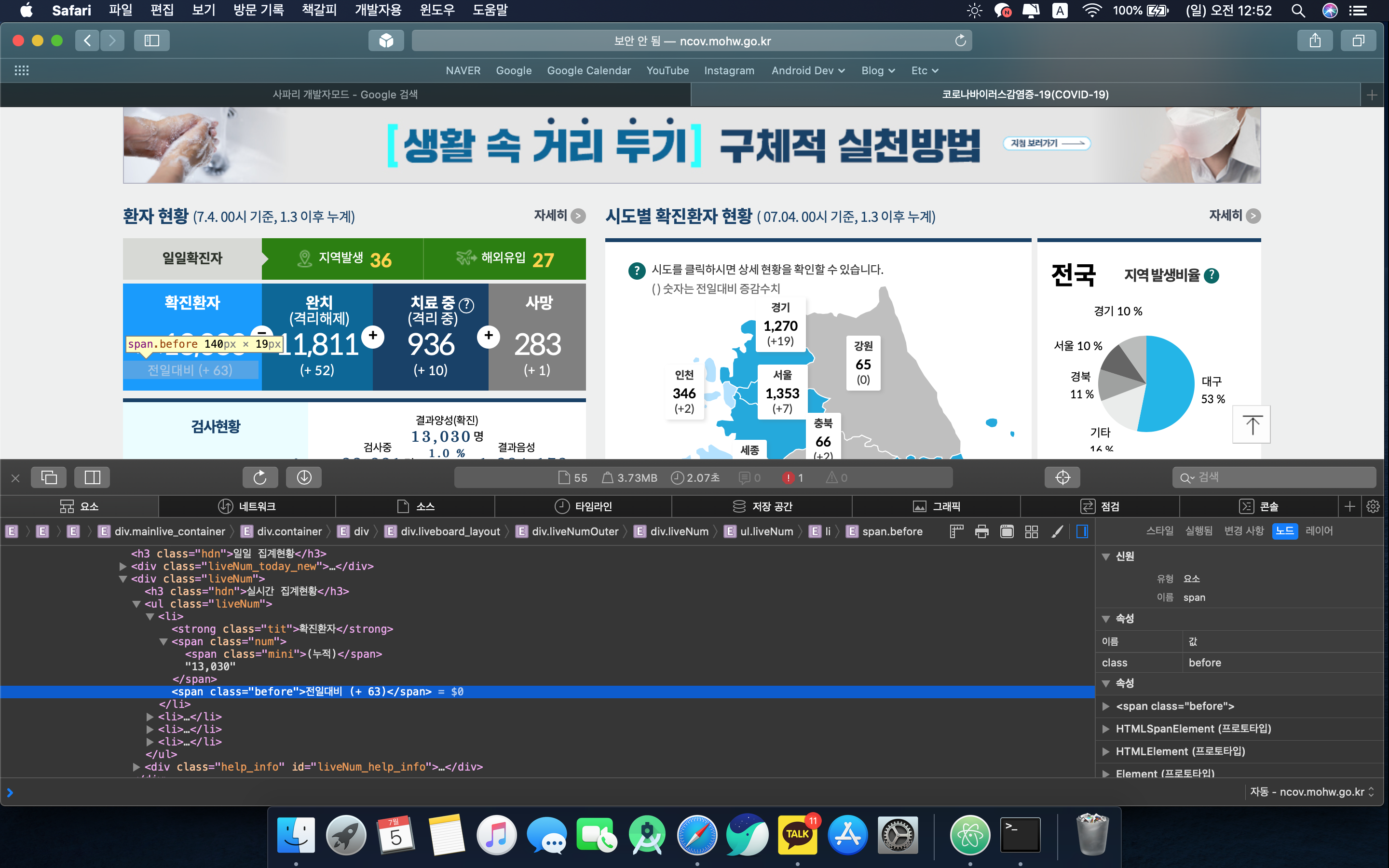
우선 웹 브라우저의 개발자 도구를 켜서, 내가 따올 부분의 html 소스를 분석한다.
신규 확진자의 정보를 알려주는 부분의 html span태그 클래스 이름이
"before"
이고, 누적 확진자의 정보를 알려주는 부분은
"num"
이다.
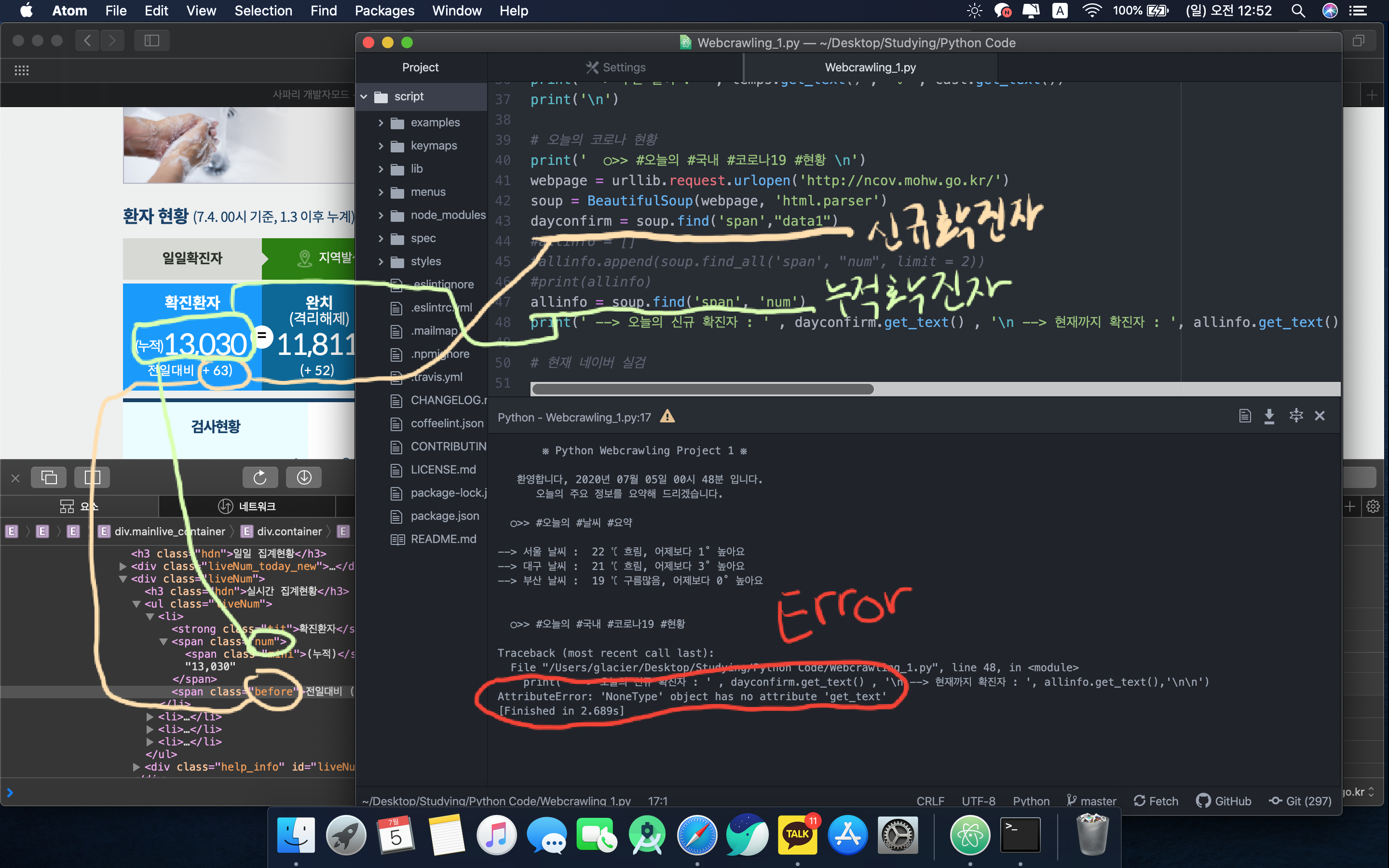 Python bs4 webcrawling 오류 수정본
Python bs4 webcrawling 오류 수정본
질문자께서 말하신 오류가 내 기존 코드에서도 발생하고 있었다.
그래서 기존코드를 분석해보니 아니나 다를까 신규확진자 부분의 bs4 웹크롤링 코드가 잘못되었다.
예전에는 span태그의 클래스가 "data1" 이였나 보다.
하지만 지금은 "
before
" 로 변경되었기 때문에 해당부분을 변경해주자.
누적 확진자 부분은 똑같이 num이기 때문에 건드리지 않아도 된다.
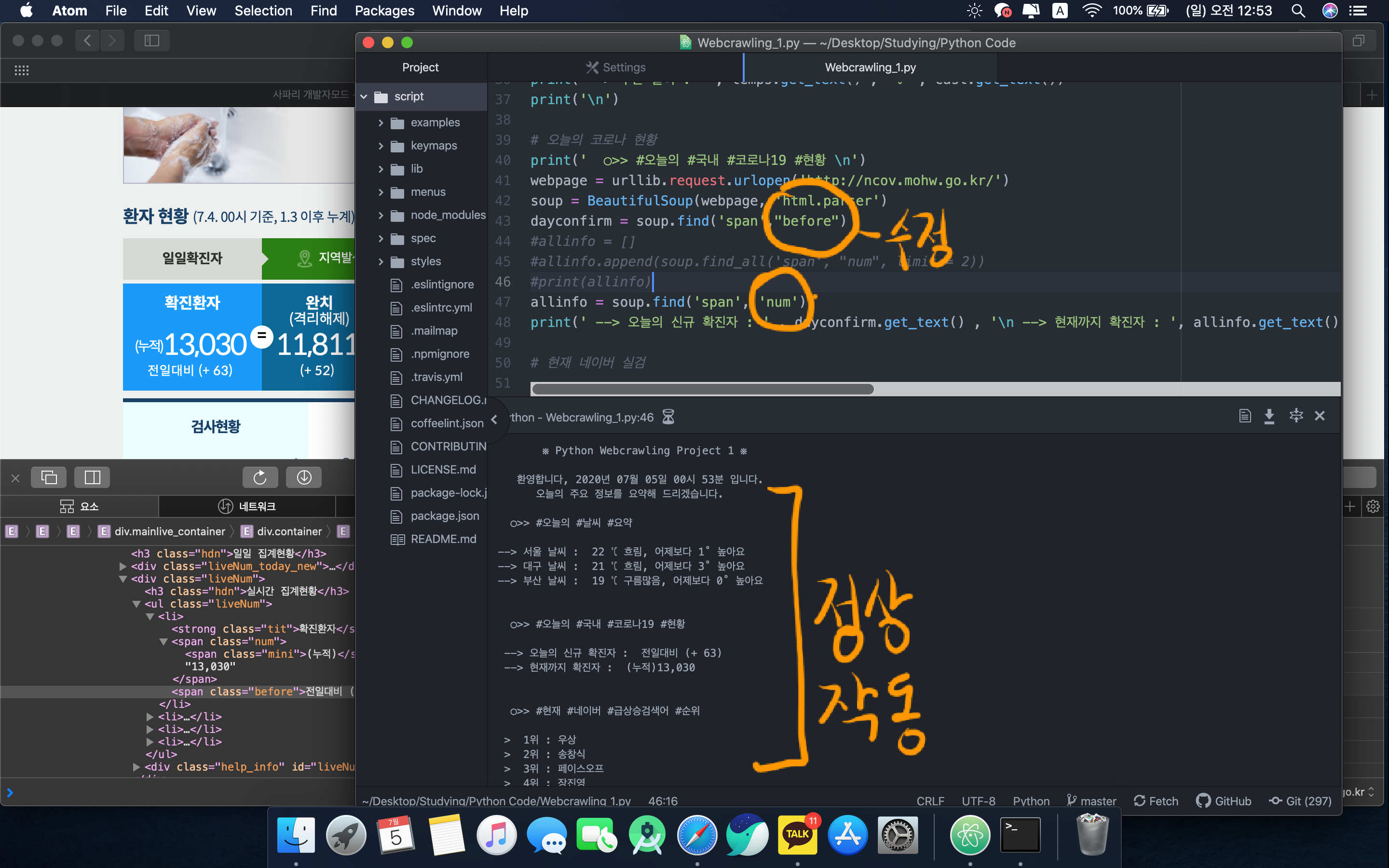 오류 수정후 정상작동하는 모습
오류 수정후 정상작동하는 모습
해당 오류를 수정하니 코드가 정상작동하는 모습이다.
질문해주신 분께 감사의 말씀 드리고
내 포스팅이 도움이 되었으면 좋겠다는 마음으로
새벽 포스팅을 마무리한다.

