**#打开test.txt文本,将里边得文本使用正则表达式筛选出数字那一部分,再存入test1.txt文件中
import re
f = open("test.txt", "r", encoding='utf-8') #打开test.txt文件,以只读得方式,注意编码格式,含中文
data = f.readlines() #循环文本中得每一行,得到得是一个列表的格式<class 'list'>
f.close() #关闭test.txt文件
for line in data:
result = re.match('.*?(\d.*\d).*',line) #使用正则表达式筛选每一行的数据,自行查找正则表达式
t = (result.group(1)) #group(1)将正则表达式的(\d.*\d)提取出来
f1 = open("test1.txt", "a+", encoding='utf-8') #新建一个test1.txt文本,已追加的方式写入
f1.write(t+'\n') #将每一行打印进test1.txt文件并换行
f1.close() #关闭test1.txt文件**

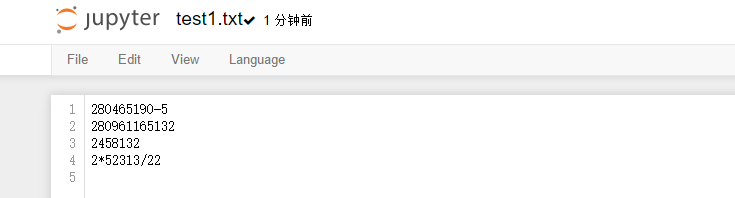
附简单的txt操作
打开文件:f = open(“test.txt”, ‘操作模式’) 加粗样式 #"test.txt"文本操作路径
w -------------------------------- 只能写入,如果之前有文件,则会被覆盖
r -------------------------------- 只能读取
a -------------------------------- 向文件追加
w+ -------------------------------- 可读可写
r+ -------------------------------- 可读可写
a+ -------------------------------- 可读可追加
wb+ ------------------------------写入进制文件
读取文本的几种方式:
test = f.read(20) #20是指定读取的文件长度
test = f.readline(20) #20是指定读取的文件行数
test = f.readlines() #按行全部读取文件
小白之路,记录下
pat = re.compile("AA") #此处的AA,是正则表达式,用来去验证其他的字符串
m = pat.search("CBA") #search字符串是被校验的内容
print(m)
print("-"*30)
m = pat.search("ABNAA")
pri...
理工类研究生的苦恼(数据批处理)
每次导师叫我们做项目的时候都会给几百甚至上千条数据,然后再到里面进行提取有用的信息进行数据处理。如果是不会编程的工科生,那研究生3年估计就没有那么好受了。利用编程进行数据批处理是每位工科生必须都会的,它能为你的后续工作节约大量的时间,但是如何处理,下面就拿简单的实例来说:
txt文件有一个缺点就是给人看上去没有那么直观,需要提取到Excel中进行处理,
我要从里面提取的有站点,时间,经纬度,以及其他信息,但是我有上千个.txt文件要将它们导入到Excel中,那么我们就要使
IC设计中难免会处理大量文本信息,我就在项目中遇到了,对于一个几万行的解码模块,提取出其中的指令,如果不用脚本将会很麻烦,下面我将一个小小的例子分享给大家,刚学python,如果有更方便的实现方法清多多指教。
1、在几万行解码模块的代码中提取出指令
2、将指令保存在一个txt文档中,要求逐行显示
import re
TXTtemp = open("test.txt...
突然想到我学过一点python,由于数据量较多,写个脚本处理明显会效率更高。
于是花了一个晚上的时间更改文件后缀名为txt,并将文件的部分内容进行删除,剩下需要提取的部分。大大小小的文件有几十个吧,花了不少功夫。
较长时间没写python了,主要用到 正则表达式 和 文件读写功能。写的过程中还遇到不少问题,编码问题,空白...
因项目上经常需修改大量脚本配置内容,故写了此脚本进行批量精确替换修改配置文件。引用模块:
#coding:utf-8#防止文件编码乱码
###################################################
#============================= 加载对应模块 ===========================================#
import re#用于从字符串中提取数据
import io#解决低版本Python 2.7.

