

使用宽表模型的表引擎查询数据时存在依赖主键以及根据属性查询效率低的问题,表格存储提供了二级索引和多元索引用于解决宽表模型的数据查询问题。您也可以为数据表创建映射关系后,像使用传统数据库一样使用SQL查询表中数据。
表引擎
宽表模型通过数据表存储数据。不同的数据分区可以加载到不同的机器上,实现水平扩展。如下图所示。
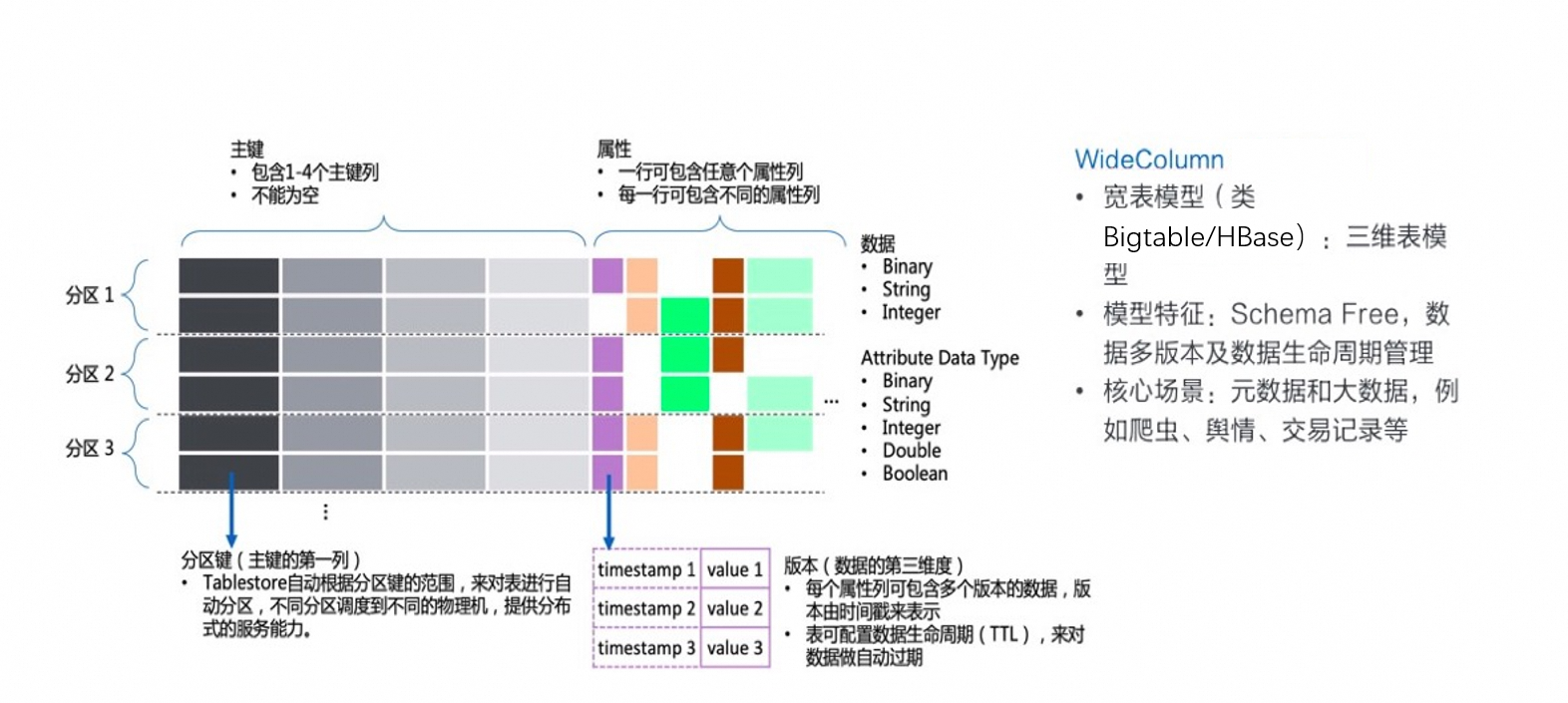
表格存储的宽表模型包含多个主键列,多列主键列按照顺序共同构成一个主键,类似MySQL的联合主键,也可以把多个主键列拼接起来看作HBase的RowKey,每一列其实都只是整体主键的一部分。采用多列主键主要原因如下:
-
业务常需要多个字段来构成主键,如果只支持一个主键列,业务需要进行拼接,多列主键列避免了业务层做主键拼接和拆解。
-
第一个主键列是分区键,保证了分区键相同的行一定在同一个分区上。分区键可以帮助实现分区内事务(Transaction)、分区内自增列等功能。
说明
主键的范围查询(GetRange接口)是指整体主键的范围,而非单独某一列的范围。
表格存储宽表模型具有完全水平扩展、提供表模型、Schema Free等优势以及存在查询数据依赖主键和根据属性查询效率低的问题。详细说明请参见下表。
|
维度 |
描述 |
|
宽表模型优势 |
|
|
宽表模型劣势 |
|
在实际业务中,主键查询常常不能满足使用需求,而使用Filter在数据规模大的情况下查询效率很低,那么要如何解决表引擎存在的数据查询问题?
由于数据查询的效率与底层扫描的数据量正相关,而Filter模式慢在符合条件的数据太分散,必须扫描大量的数据并从中筛选。解决此问题有如下两种思路:
-
让符合条件的数据不再分散分布
使用二级索引,将某列或某几列作为二级索引的主键。相当于通过数据冗余,直接把符合条件的数据预先排在一起,查询时直接精确定位和扫描,效率极高。
-
加快筛选的速度
使用多元索引,多元索引底层提供了倒排索引、BKD-Tree等数据结构。以查询某属性列值为例,为该列建立多元索引后,表格存储会为该列的值建立倒排索引,倒排索引实际上记录了某个值对应的所有主键的集合,即Value->List。因此要查询属性列为某个Value的所有记录时,直接通过倒排索引获取所有符合条件的主键,进行读取即可。本质上是加快了从海量数据中筛选数据的效率。
二级索引
二级索引采用的仍然是表引擎,数据表建立了全二级索引后,相当于多了一张索引表。索引表相当于为数据表提供了另外一种排序的方式,即针对查询条件预先设计了一种数据分布,来加快数据查询的效率。
二级索引包括全局二级索引和本地二级索引。全局二级索引和本地二级索引在同步方式、对第一列主键要求、同步延迟和读取一致性方面的区别请参见下表说明。
|
维度 |
全局二级索引 |
本地二级索引 |
|
同步方式 |
异步方式 |
同步方式 |
|
第一列主键要求 |
可选数据表中的任意主键列或者预定义列 |
必须和数据表的第一列主键相同 |
|
同步延迟 |
毫秒级别 |
实时 |
|
读取一致性 |
最终一致性 |
强一致性 |
二级索引的使用方式与数据表类似,主要查询方式仍然是主键点查、主键范围查、主键前缀范围查。更多信息,请参见 二级索引简介 。
例如有一张数据表存储文件的MD5和SHA1值,表结构如下。

通过这张表的主键,您可以查询文件对应的MD5和SHA1值,但是通过MD5或SHA1反查文件名却不容易。此时您可以为这张表建立两张全局二级索引表,表结构分别为如下:
重要
为了确保主键的唯一性,二级索引会将数据表的原主键的主键列也添加到主键列中,例如图中的FilePath列。
图 1:
索引1
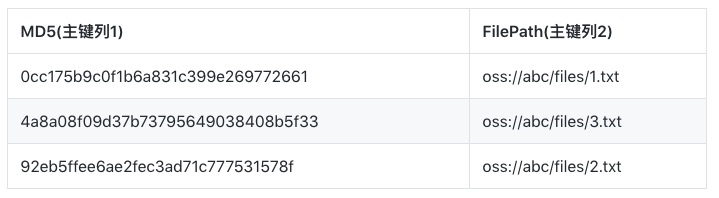
图 2:
索引2
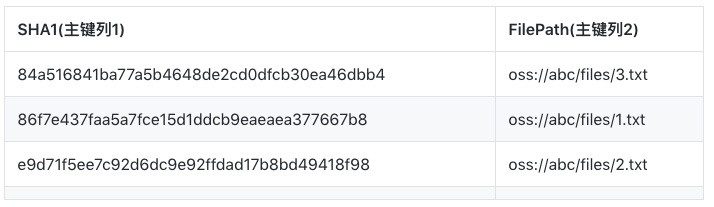
有了这两张索引表,即可通过索引表的主键前缀范围查询的方式来精确定位某个MD5或某个SHA1对应的文件名。
多元索引
多元索引引擎相对于表引擎,底层增加了倒排索引、多维空间索引等,支持多条件组合查询、模糊查询、地理空间查询、全文索引等功能,还提供一些统计聚合能力。更多信息,请参见 多元索引介绍 。
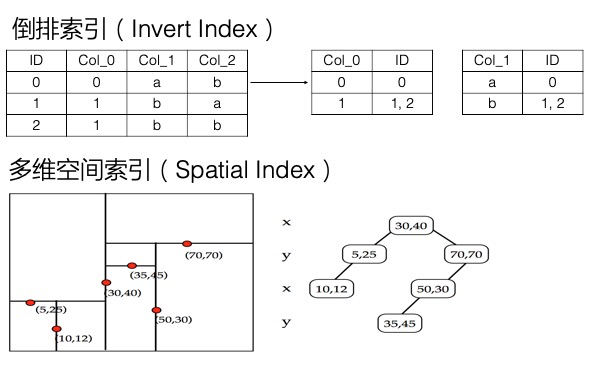
倒排索引不仅可以解决单列值的检索问题,还可以解决多条件组合查询的问题。例如下表为一个订单记录。
表中一共16个字段,需要按照任意多个字段组合查询,例如查询某一售货员、某一产品类型、单价在xx元之上的所有记录。这样的排列组合会有非常多,因此不太可能预先将任何一种查询条件的数据放到一起来加快查询的效率,这需要建立很多的二级索引。而如果采用Filter方式,则可能需要扫描全表,效率不高。
折中方式是先对某个字段建立二级索引缩小数据范围,然后再对其中数据进行Filter。那么是否有更好的方式进行数据查询呢?
多元索引可以很好地解决这一类问题,而且只需要建立一个多元索引,将所有可能查询的列添加到该多元索引中即可,添加的顺序无要求。多元索引中的每一列默认都会建立倒排,倒排表中记录了Value到List的映射。针对多列的多个条件,在每列的倒排表中找到对应的List,这称为一个倒排链,而筛选符合多个条件的数据即为计算多个倒排链的交并集,此处底层有着大量的优化,可以高效地实现这一操作。因此多元索引在处理多条件组合查询方面效率很高。
此外,多元索引还支持全文索引、模糊查询、地理空间查询等,以地理空间查询为例,多元索引通过底层的BKD-Tree结构,支持高效地查询一个地理多边形内的点,也支持按照地理位置排序、聚合统计等。