准备工作
🍉
本系列的awk教程中,将大量使用到如下示例文件a.txt。
ID name gender age email phone
1 Bob male 28 [email protected] 18023394012
2 Alice female 24 [email protected] 18084925203
3 Tony male 21 [email protected] 17048792503
4 Kevin male 21 [email protected] 17023929033
5 Alex male 18 [email protected] 18185904230
6 Andy female 22 [email protected] 18923902352
7 Jerry female 25 [email protected] 18785234906
8 Peter male 20 [email protected] 17729348758
9 Steven female 23 [email protected] 15947893212
10 Bruce female 27 [email protected] 13942943905
一、awk用法入门
🍅
awk 'awk_program' a.txt
-
a.txt是awk要读取的文件,可以是0个文件或者1个文件,也可以是多个文件。当第一个文件执行完再按照循序依次执行。如果不给定任何文件,但又需要读取文件,则表示从标准输入中读取。
-
单引号包围的是awk代码,也称为awk程序。尽量使用单引号,因为在awk中经常使用
$
符号,而
$
符号在Shell中是变量符号,如果使用双引号包围awk代码,则
$
符号会被Shell解析为变量,然后进行Shell变量替换。使用单引号包围awk代码,则会使
$
脱离Shell的魔掌,使得
$
符号留给了awk去解析。
-
awk程序中,大量使用大括号,大括号表示代码块,代码块中间可以直接连用,代码块内部多个语句需使用分号
;
分隔。
# awk输出第一列,不指定读取的文件,则在标准输入中进行读取。
awk '{print $1}'
# 输出a.txt中的每一行
awk '{print $0}' a.txt
# 多个代码块,代码块中多个语句。输出每行之后还输出两行:hello行和world行
awk '{print $0}{print "hello";print "world"}' a.txt
对于
awk '{print $0}' a.txt
,它类似于shell的while循环
while read line;do echo "$line";done <a.txt
。awk隐藏了读取每一行的while循环,它会自动读取每一行,其中的
{print $0}
对应于Shell的while循环体
echo "$line"
部分。
下面再分析该awk命令的执行过程:
-
读取文件第一行(awk默认按行读取文件)
-
将所读取的行赋值给awk的变量
$0
,于是
$0
中保存的就是本次所读取的行数据
-
进入代码块
{print $0}
并执行其中代码
print $0
,即输出
$0
,也即输出当前所读取的行
-
执行完本次代码之后,进入下一轮awk循环:继续读取下一行(第二行)
-
将第二行赋值给变量
$0
-
进入代码块执行
print $0
-
执行完代码块后再次进入下一轮awk循环,即读取第三行,然后赋值给
$0
,再执行代码块
-
…不断循环,直到读完文件所有数据…
-
退出awk
二、BEGIN 和 END 语句块
🥕
awk的所有代码(目前这么认为)都是写在语句块中的。
每个语句块前面可以有pattern,所以格式为:
pattern1{statement1}pattern2{statement2;statement3;...}
语句块可分为3类:BEGIN语句块、END语句块和main语句块。其中BEGIN语句块和END语句块都是的格式分别为
BEGIN{...}
和
END{...}
,而main语句块是一种统称,它的pattern部分没有固定格式,也可以省略,main代码块是在读取文件的每一行的时候都执行的代码块。
分析下面三个awk命令的执行结果:
# 示例一:
awk 'BEGIN{print "我在前面"}{print $0}' a.txt
ID name gender age email phone
......
# 示例二
awk 'END{print "我在后面"}{print $0}' a.txt
ID name gender age email phone
......
10 Bruce female 27 [email protected] 13942943905
# 示例三
awk 'BEGIN{print "我在前面"}{print $0}END{print "我在后面"}' a.txt
ID name gender age email phone
......
10 Bruce female 27 [email protected] 13942943905
我在后面
根据上面3行命令的执行结果,可总结出如下有关于BEGIN、END和main代码块的特性:
BEGIN代码块:
-
在读取文件之前执行,且执行一次
-
在BEGIN代码块中,无法使用
$0
或其它一些特殊变量
main代码块:
-
读取文件时循环执行,(默认情况)每读取一行,就执行一次main代码块
-
main代码块可有多个
END代码块:
-
在读取文件完成之后执行,且执行一次
-
有END代码块,必有要读取的数据(可以是标准输入)
-
END代码块中可以使用
$0
等一些特殊变量,只不过这些特殊变量保存的是最后一轮awk循环的数据。
三、awk命令行结构和awk语法结构
🌽
1、awk命令行结构
awk [ -- ] program-text file ... (1)
awk -f program-file [ -- ] file ... (2)
awk -e program-text [ -- ] file ... (3)
-
program-text
即 awk 命令行中的 awk 代码部分,一般使用单引号包围。
-
-f program-file
表示将 awk 代码部分写在文件中,然后使用
-f
选项去引用这个文件。
-
-e program-text
也用于指定 awk 代码,所以语法(1)和语法(3)是等价的,但是既要使用 -f 又要在命令行写 awk 代码,则必须使用
-f
和
-e
,即
awk -f file -e 'awk_code'
,而不能是
awk -f file 'awk_code'
。
2、awk语法结构
awk语法结构即awk代码部分的结构。
awk的语法充斥着
pattern{action}
的模式,它们称为awk rule。
例如:
awk '
BEGIN{n=3}
/^[0-9]/$1>5{$1=333;print $1}
/Alice/{print "Alice"}
END{print "hello"}
' a.txt
# 等价的单行式:
awk 'BEGIN{n=3} /^[0-9]/{$1>5{$1=333;print $1} /Alice/{print "Alice"} END{print "hello"}' a.txt
上面示例中,有BEGIN语句块,有END语句块,还有2个main代码块,两个main代码块都使用了正则表达式作为pattern。
关于awk的语法:
-
多个
pattern{action}
可以直接连接连用
-
action中多个语句如果写在同一行,则需使用分号分隔
-
pattern部分用于筛选行,action表示在筛选通过后执行的操作
-
pattern和action都可以省略
-
省略 pattern ,等价于对每一行数据都执行 action
-
例如:
awk '{print $0}' a.txt
-
省略代码块 {action} ,等价于 {print} ,即输出所有行
-
例如:
awk '/Alice/' a.txt
等价于
awk '/Alice/{print $0}' a.txt
-
省略代码块中的 action ,表示对筛选的行什么都不做
-
例如:
awk '/Alice/{}' a.txt
-
pattern{action} 任何一部分都可以省略
3、pattern 和 action
对于
pattern{action}
语句结构(都称之为语句块),其中的pattern部分可以使用下面列出的模式:
# 特殊pattern
BEGIN
# 布尔代码块
/regular expression/ # 正则匹配成功与否 /a.*ef/{action}
relational expression # 即等值比较、大小比较 3>2{action}
pattern && pattern # 逻辑与 3>2 && 3>1 {action}
pattern || pattern # 逻辑或 3>2 || 3<1 {action}
! pattern # 逻辑取反 !/a.*ef/{action}
(pattern) # 改变优先级
pattern ? pattern : pattern # 三目运算符决定的布尔值
# 范围pattern,非布尔代码块
pattern1, pattern2 # 范围,pat1打开、pat2关闭,即flip,flop模式
action部分,可以是任何语句,例如print。
四、awk 选项、预定义变量
🥦
1、选项
-e program-text
--source program-text
指定awk程序表达式,可结合-f选项同时使用
在使用了-f选项后,如果不使用-e,awk program是不会执行的,它会被当作ARGV的一个参数
-f program-file
--file program-file
从文件中读取awk源代码来执行,可指定多个-f选项
-F fs
--field-separator fs
指定输入字段分隔符(FS预定义变量也可设置)
--non-decimal-data
识别文件输入中的8进制数(0开头)和16进制数(0x开头)
echo '030' | awk -n '{print $1+0}'
-o [filename]
格式化awk代码。
不指定filename时,则默认保存到awkprof.out
指定为`-`时,表示输出到标准输出
-v var=val
--assign var=val
在BEGIN之前,声明并赋值变量var,变量可在BEGIN中使用
2、预定义变量
预定义变量分为两类:控制awk工作的变量和携带信息的变量。
第一类:控制AWK工作的预定义变量
-
RS
:输入记录分隔符,默认为换行符
\n
-
IGNORECASE
:默认值为0,表示所有的正则匹配不忽略大小写。设置为非0值(例如1),之后的匹配将忽略大小写。例如在BEGIN块中将其设置为1,将使FS、RS都以忽略大小写的方式分隔字段或分隔record
-
FS
:读取记录后,划分为字段的字段分隔符。
-
FIELDWIDTHS
:以指定宽度切割字段而非按照FS。
-
FPAT
:以正则匹配匹配到的结果作为字段,而非按照FS划分。
-
OFS
:print命令输出各字段列表时的输出字段分隔符,默认为空格。
-
ORS
:print命令输出数据时在尾部自动添加的记录分隔符,默认为换行符
\n。
-
CONVFMT
:在awk中数值隐式转换为字符串时,将根据CONVFMT的格式按照s
printf()
的方式自动转换为字符串。默认值为
%.6g。
-
OFMT
:在print中,数值会根据OFMT的格式按照sprintf()的方式自动转换为字符串。默认值为
%.6g
。
第二类:携带信息的预定义变量
五、awk 读取行
🍄
1、详细分析 awk 如何读取文件
awk读取输入文件时,每次读取一条记录(record)(默认情况下按行读取,所以此时记录就是行)。每读取一条记录,将其保存到
$0
中,然后执行一次main代码段。
awk '{print $0}' a.txt
如果是空文件,则因为无法读取到任何一条记录,将导致直接关闭文件,而不会进入main代码段。
touch x.log # 创建一个空文件
awk '{print "hello world"}' x.log
可设置表示输入记录分隔符的预定义变量RS(Record Separator)来改变每次读取的记录模式。
# RS="\n" 、 RS="m"
awk 'BEGIN{RS="\n"}{print $0}' a.txt
awk 'BEGIN{RS="m"}{print $0}' a.txt
RS通常设置在BEGIN代码块中,因为要先于读取文件就确定好RS分隔符。
RS指定输入记录分隔符时,所读取的记录中是不包含分隔符字符的。例如
RS="a"
,则
$0
中一定不可能出现字符a。
RS有两种可能情况:
-
RS为单个字符:直接使用该字符分割记录
-
RS为多个字符:将其当作正则表达式,只要匹配正则表达式的符号,都用来分割记录
特殊的RS值用来解决特殊读取需求:
-
RS=""
:按段落读取
-
RS="\0"
:一次性读取所有数据,但有些特殊文件中包含了空字符
\0
-
RS="^$"
:真正的一次性读取所有数据,因为非空文件不可能匹配成功
-
RS="\n+"
:按行读取,但忽略所有空行
# 按段落读取:RS=''
$ awk 'BEGIN{RS=''}{print $0""}' a.txt
# 一次性读取所有数据:RS='\0' RS="^$"
$ awk 'BEGIN{RS='\0'}{print $0""}' a.txt
$ awk 'BEGIN{RS='^$'}{print $0""}' a.txt
# 忽略空行:RS='\n+'
$ awk 'BEGIN{RS='\n+'}{print $0""}' a.txt
# 忽略大小写:预定义变量IGNORECASE设置为非0值
$ awk 'BEGIN{IGNORECASE=1}{print $0""}' RS='[ab]' a.txt
预定义变量RT:
在awk每次读完一条记录时,会设置一个称为RT的预定义变量,表示Record Termination。
当RS为单个字符时,RT的值和RS的值是相同的。
当RS为多个字符(正则表达式)时,则RT设置为正则匹配到记录分隔符之后,真正用于划分记录时的字符。
当无法匹配到记录分隔符时,RT设置为控制空字符串(即默认的初始值)。
# 示例一
awk 'BEGIN{RS="(fe)?male"}{print RT}' a.txt
female
......
# 示例二
awk 'BEGIN{RS="m"}{print RT}' a.txt
......
2、两种行号:NR和FNR
在读取每条记录之后,将其赋值给$0,同时还会设置NR、FNR、RT。
-
NR:所有文件的行号计数器
-
FNR:是各个文件的行号计数器
awk '{print NR}' a.txt a.txt
awk '{print FNR}' a.txt a.txt
3、$0重构 ->
$1=$1
注意下面的分割和计算两词:分割表示使用FS(field Separator),计算表示使用预定义变量OFS(Output Field Separator)。
-
修改
$0
,将使用
FS
重新分割字段,所以会影响
$1、$2...
-
修改
$1、$2
,将根据
$1
到
$NF
等各字段来重新计算
$0
,即使是
$1 = $1
这样的原值不变的修改,也一样会重新计算
$0
-
为不存在的字段赋值,将新增字段并按需使用空字符串填充中间的字段,并使用
OFS
重新计算
$0
。
awk 'BEGIN{OFS="-"}{$(NF+2)=5;print $0}' a.txt
-
增加NF值,将使用空字符串新增字段,并使用
OFS
重新计算
$0
awk 'BEGIN{OFS="-"}{NF+=3;print $0}' a.txt
-
减小NF值,将丢弃一定数量的尾部字段,并使用
OFS
重新计算
$0
awk 'BEGIN{OFS="-"}{NF-=3;print $0}' a.txt
当读取一条record之后,将原原本本地被保存到
$0
当中。
awk '{print $0}' a.txt
但是,只要出现了上面所说的任何一种导致
$0
重新计算的操作,都会使用
OFS
去重建
$0
。
换句话说,没有导致
$0
重建,
$0
就一直是原原本本的数据,所以指定OFS也无效。
awk 'BEGIN{OFS="-"}{print $0}' a.txt # OFS此处无效
当
$0
重建后,将自动使用OFS重建,所以即使没有指定OFS,它也会采用默认值(空格)进行重建。
awk '{$1=$1;print $0}' a.txt # 输出时将以空格分隔各字段
awk '{print $0;$1=$1;print $0}' OFS="-" a.txt
如果重建
$0
之后,再去修改OFS,将对当前行无效,但对之后的行有效。所以如果也要对当前行生效,需要再次重建。
# OFS对第一行无效
awk '{$4+=10;OFS="-";print $0}' a.txt
# 对所有行有效
awk '{$4+=10;OFS="-";$1=$1;print $0}' a.txt
当我们为字段变量赋值时,即。值为
$1
分配给字段
$1
,awk 实际上通过用默认字段分隔符(或 OFS) 空间连接它们来重建其
$0
。
技巧1:
$0
重建。例如,下面通过重建
$0
的技巧来实现去除行首行尾空格并压缩中间空格:
$ echo " a b c d " | awk '{$1=$1;print}'
a b c d
$ echo " a b c d " | awk '{$1=$1;print}' OFS="-"
a-b-c-d
技巧2:添加
1
快捷方式。1是打印当前记录的常见AWK技巧,相当于
{print $0}
# 以下三条命令等价,输出相同结果
awk 'BEGIN{print "abc"}1' a.txt
awk 'BEGIN{print "abc"}{print}' a.txt
awk 'BEGIN{print "abc"}{print $0}' a.txt
六、详细分析awk字段分割
🐼
awk读取每一条记录之后,会将其赋值给
$0
,同时还会对这条记录按照
预定义变量FS
划分字段,将划分好的各个字段分别赋值给
$1 $2 $3 $4...$N
,同时将划分的字段数量赋值给
预定义变量NF
。
1、引用字段的方式
$N
引用字段:
-
N=0
:即
$0
,引用记录本身
-
0<N<=NF
:引用对应字段
-
N>NF
:表示引用不存在的字段,返回空字符串
-
N<0
:报错
可使用变量或计算的方式指定要获取的字段序号。
awk '{n = 5;print $n}' a.txt
awk '{print $(2+2)}' a.txt # 括号必不可少,用于改变优先级
awk '{print $(NF-3)}' a.txt
2、分割字段的方式
读取record之后,将使用预定义变量FS、FIELDWIDTHS或FPAT中的一种来分割字段。分割完成之后,再进入main代码段(所以,在main中设置FS对本次已经读取的record是没有影响的,但会影响下次读取)。
(1)划分字段方式(一):FS或-F
FS
或者
-F
:字段分隔符
-
FS为单个字符时,该字符即为字段分隔符
-
FS为多个字符时,则采用正则表达式模式作为字段分隔符
-
特殊的,也是FS默认的情况,
FS为单个空格时,将以连续的空白(空格、制表符、换行符)作为字段分隔符
-
特殊的,FS为空字符串””时,将对每个字符都进行分隔,即每个字符都作为一个字段
-
设置预定义变量IGNORECASE为非零值,正则匹配时表示忽略大小写(只影响正则,所以FS为单字时无影响)
-
如果record中无法找到FS指定的分隔符(例如将FS设置为”\n”),则整个记录作为一个字段,即
$1
和
$0
相等
# 字段分隔符指定为单个字符
awk -F":" '{print $1}' /etc/passwd
awk 'BEGIN{FS=":"}{print $1}' /etc/passwd
# 字段分隔符指定为正则表达式
awk 'BEGIN{FS=" +|@"}{print $1,$2,$3,$4,$5,$6}' a.txt
(2)划分字段方式(二):FIELDWIDTHS(了解,gawk支持)
指定预定义变量FIELDWIDTHS按字符宽度分割字段,这是gawk提供的高级功能。在处理某字段缺失时非常好用。
用法:
-
FIELDWIDTHS="3 5 6 9" 表示第一个字段3字符,第二个字段5字符...
-
FIELDWIDTHS="8 1:5 6 2:33" 表示第一个字段读8个字符,跳过一个字符再读5个字符作为第二个字段,然后读6个字符作为第三个字段。最后跳过2个字符再读33个字符作为第四个字段(如果不足33个字符,则读到结尾)
-
FIELDWIDTHS="2 3 *" 表示第一个字段2个字符,第二个字段3个字符,第三个字符剩余所有字符,星号只能放在最后,且只能单独使用,表示剩余所有。
示例1:
# 没取完的字符串DDD被丢弃,且NF=3
$ awk 'BEGIN{FIELDWIDTHS="2 3 2"}{print $1,$2,$3,$4}' <<<"AABBBCCDDDD"
AA BBB CC
# 字符串不够长度时无视
$ awk 'BEGIN{FIELDWIDTHS="2 3 2 100"}{print $1,$2,$3,$4"-"}' <<<"AABBBCCDDDD"
AA BBB CC DDDD-
# *号取剩余所有,NF=3
$ awk 'BEGIN{FIELDWIDTHS="2 3 *"}{print $1,$2,$3}' <<<"AABBBCCDDDD"
AA BBB CCDDDD
# 字段数多了,则取完字符串即可,NF=2
$ awk 'BEGIN{FIELDWIDTHS="2 30 *"}{print $1,$2,NF}' <<<"AABBBCCDDDD"
AA BBBCCDDDD 2
示例2:处理某些字段缺失的数据。
如果按照常规的FS进行字段分割,则对于缺失字段的行和没有缺失字段的行很难统一处理,但使用FIELDWIDTHS则非常方便。
因为email字段有的是空字段,所以直接用FS划分字段不便处理。可使用FIELDWIDTHS。
# 字段1:4字符
# 字段2:8字符
# 字段3:8字符
# 字段4:2字符
# 字段5:先跳过3字符,再读13字符,该字段13字符
# 字段6:先跳过2字符,再读11字符,该字段11字符
awk '
BEGIN{FIELDWIDTHS="4 8 8 2 3:13 2:11"}
NR>1{
print "<"$1">","<"$2">","<"$3">","<"$4">","<"$5">","<"$6">"
}' a.txt
# 如果email为空,则输出它
awk '
BEGIN{FIELDWIDTHS="4 8 8 2 3:13 2:11"}
NR>1{
if($5 ~ /^ +$/){print $0}
}' a.txt
(3)划分字段方式(三):FPAT(了解,gawk支持)
FS是指定字段分隔符,来取得除分隔符外的部分作为字段。
FPAT是取得匹配的字符部分作为字段。它是gawk提供的一个高级功能。
FPAT根据指定的正则来全局匹配record,然后将所有匹配成功的部分组成
$1、$2...
,不会修改
$0
。
-
awk 'BEGIN{FPAT="[0-9]+"}{print $3"-"}' a.txt
-
之后再设置FS或FPAT,该变量将失效
FPAT常用于字段中包含了字段分隔符的场景。例如,CSV文件中的一行数据如下:
Robbins,Arnold,"1234 A Pretty Street, NE",MyTown,MyState,12345-6789,USA
其中逗号分隔每个字段,但双引号包围的是一个字段整体,即使其中有逗号。
这时使用FPAT来划分各字段比使用FS要方便的多。
echo 'Robbins,Arnold,"1234 A Pretty Street, NE",MyTown,MyState,12345-6789,USA' |\
awk '
BEGIN{FPAT="[^,]*|(\"[^\"]*\")"}
for (i=1;i<NF;i++){
print "<"$i">"
'
最后,patsplit()函数和FPAT的功能一样。
七、awk筛选行和处理字段
🦉
1、筛选行
# 1.根据行号筛选
awk 'NR==2' a.txt # 筛选出第二行
awk 'NR>=2' a.txt # 输出第2行和之后的行
# 2.根据正则表达式筛选整行
awk '/qq.com/' a.txt # 输出带有qq.com的行
awk '$0 ~ /qq.com/' a.txt # 等价于上面命令
awk '/^[^@]+$/' a.txt # 输出不包含@符号的行
awk '!/@/' a.txt # 输出不包含@符号的行
# 3.根据字段来筛选行
awk '($4+0) > 24{print $0}' a.txt # 输出第4字段大于24的行
awk '$5 ~ /qq.com/' a.txt # 输出第5字段包含qq.com的行
# 4.将多个筛选条件结合起来进行筛选
awk 'NR>=2 && NR<=7' a.txt
awk '$3=="male" && $6 ~ /^170/' a.txt
awk '$3=="male" || $6 ~ /^170/' a.txt
# 5.按照范围进行筛选 flip flop
# pattern1,pattern2{action}
awk 'NR==2,NR==7' a.txt # 输出第2到第7行
awk 'NR==2,$6 ~ /^170/' a.txt
2、处理字段
awk 'NR>1{$4=$4+5;print $0}' a.txt
awk 'BEGIN{OFS="-"}NR>1{$4=$4+5;print $0}' a.txt
awk 'NR>1{$6=$6"*";print $0}' a.txt
小测试:awk运维面试试题
从ifconfig命令的结果中筛选出除了lo网卡外的所有IPv4地址。
# 1.法一:多条件筛选
ifconfig | awk '/inet / && !($2 ~ /^127/){print $2}'
# 2.法二:按段落读取,然后取IPv4字段
ifconfig | awk 'BEGIN{RS=""}!/lo/{print $6}'
# 3.法三:按段落读取,每行1字段,然后取IPv4字段
ifconfig | awk 'BEGIN{RS="";FS="\n"}!/lo/{$0=$2;FS=" ";$0=$0;print $2}'
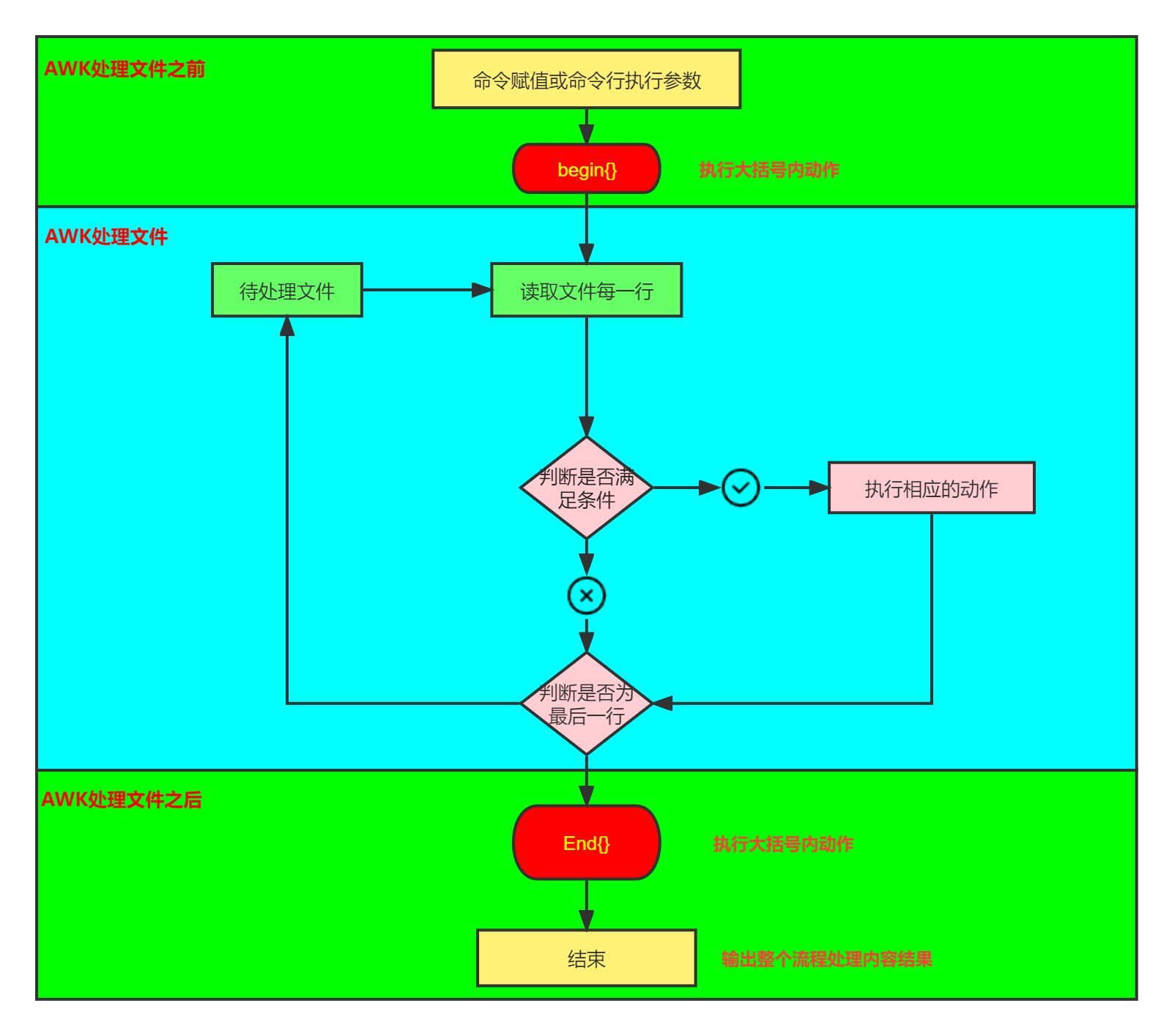
八、awk 工作流程
🐧
-
解析
-v var=val ...
选项中的变量赋值
-
编译awk源代码为可解释的内部格式,包括
-v
的变量
-
执行BEGIN代码段
-
根据输入记录分隔符RS读取文件(根据ARGV数组的元素决定要读取的文件),如果没有指定文件,则从标准输入中读取文件,同时执行main代码段
-
如果文件名部分指定var=val格式,则声明并创建变量,此阶段再BEGIN声明之后,所以BEGIN中不可用,main代码段可用
-
每读取一条记录,都将设置NR、FNR、RT、$0等变量。(默认)根据输入字段分隔符FS切割字段,将各字段保存到
$1、$2...
中。测试main代码段的pattern部分,如果测试成功,则执行action部分。
-
执行END代码段。
流程图
![AWK]()
九、getline 用法详解
🐲
除了可以从标准输入或非选项型参数所指定的文件中读取数据,还可以使用getline从其它各种渠道获取需要处理的数据,它的用法有很多种。
getline的返回值:
-
如果可以读取到数据,返回1
-
如果遇到了EOF,返回0
-
如果遇到了错误,返回负数。如-1表示文件无法打开,-2表示IO操作需要重试(retry)。在遇到错误的同时,还会设置
ERRNO
变量来描述错误
为了健壮性,getline时强烈建议进行判断。例如:
if ((getline) <= 0 ){...}
if ((getline) < 0 ){...}
if ((getline) > 0 ){...}
上面的
getline
的括号尽量加上,因为
getline < 0
表示的是输入重定向,而不是和数值0进行小于号的比较。
1、无参数的 getline
getline无参数时,表示从当前正在处理的文件中立即读取下一条记录保存到
$0
中,并进行字段分割,然后
继续执行后续代码逻辑
。
此时的getline会设置NF、RT、NR、FNR、$0和$N。
例如,匹配到某行之后,再读一行就退出:
awk '/^1/{print;getline;print;exit}' a.txt
为了更健壮,应当对getline的返回值进行判断。
awk '/^1/{print;if((getline)<=0){exit};print}' a.txt
2、一个参数的getline
没有参数的getline是读取下一条记录之后将记录保存到
$0
中,并对该记录进行字段的分割。
一个参数的getline是将读取的记录保存到指定的变量当中,并且不会对其进行分割。
getline var
此时的getline只会设置RT、NR、FNR变量和指定的变量var。因此$0和$N以及NF保持不变。
awk '
/^1/{
if((getline var)<=0){exit}
print var
print $0"--"$2
}' a.txt
3、从指定文件中读取数据
-
getline < filename
: 从指定文件filename中读取一条记录保存到$0中,会进行字段的划分,会设置变量
$0 $N $NF
,不会设置变量
NR FNR
-
getline var < filename
: 从指定文件filename 读取一条记录并保存到指定变量var中,不会划分字段,不会设置变量
NR FNR NF $0 $N
filename需使用双引号包围表示文件名字符串,否则会当作变量解析
getline < "c.txt"
。此外,如果路径是使用变量构建的,则应该使用括号包围路径部分。例如
getline < dir "/" filename
中使用了两个变量构建路径,这会产生歧义,应当写成
getline <(dir "/" filename)
。
注意,每次从filename读取之后都会做好位置偏移标记,下次再从该文件读取时将根据这个位置标记继续向后读取。
例如,每次行首以1开头时就读取c.txt文件的所有行。
awk '
/^1/{
if((getline var)<=0){exit}
print var
}' a.txt
上面的
close("c.txt")
表示在
while(getline)
读取完文件之后关掉,以便后面再次读取,如果不关掉,则文件偏移指针将一直在文件结尾处,使得下次读取时直接遇到EOF。
4、从Shell命令输出结果中读取数据
如果要再次执行cmd并读取其输出数据,则需要close关闭该命令。例如
close("seq 1 5")
,参见下面的示例。
例如:每次遇到以1开头的行都输出seq命令产生的
1 2 3 4 5
。
awk '/^1/{print;while(("seq 1 5"|getline)>0){print};close("seq 1 5")}' a.txt
再例如,调用Shell的date命令生成时间,然后保存到awk变量cur_date中:
awk '
/^1/{
print
"date +\"%F %T\""|getline cur_date
print cur_date
close("date +\"%F %T\"")
}' a.txt
可以将cmd保存成一个字符串变量。
awk '
BEGIN{get_date="date +\"%F %T\""}
/^1/{
print
get_date | getline cur_date
print cur_date
close(get_date)
}' a.txt
更为复杂一点的,cmd中可以包含Shell的其它特殊字符,例如管道、重定向符号等:
awk '
/^1/{
print
if(("seq 1 5 | xargs -i echo x{}y 2>/dev/null"|getline) > 0){
print
close("seq 1 5 | xargs -i echo x{}y 2>/dev/null")
}' a.txt
5、awk中的coprocess
awk虽然强大,但是有些数据仍然不方便处理,这时可将数据交给Shell命令去帮助处理,然后再从Shell命令的执行结果中取回处理后的数据继续awk处理。
awk通过
|&
符号来支持coproc。
awk_print[f] "something" |& Shell_Cmd
Shell_Cmd |& getline [var]
这表示awk通过print输出的数据将传递给Shell的命令Shell_Cmd去执行,然后awk再从Shell_Cmd的执行结果中取回Shell_Cmd产生的数据。
十、awk 输出操作
🐸
1、print
awk '{print $1,$2,$3}' a.txt
awk '{print ($1,$2,$3)}' a.txt
逗号分隔要打印的字段列表,各字段都
会自动转换成字符串格式
,然后通过预定义变量OFS(output field separator)的值(其默认值为空格)连接各字段进行输出。
$ awk '{print $1,$2,$3}' a.txt
ID name gender
1 Bob male
$ awk 'BEGIN{OFS="---"}{print $1,$2,$3}' a.txt
ID---name---gender
1---Bob---male
...
print要输出的数据称为输出记录,在print输出时会自动在尾部加上输出记录分隔符,输出记录分隔符的预定义变量为ORS,其默认值为
\n
。
$ awk 'BEGIN{OFS="---";ORS="_\n"}{print ($1,$2,$3)}' a.txt
ID---name---gender_
1---Bob---male_
...
括号可省略,但如果要打印的元素中包含了特殊符号
>
,则必须使用括号包围(如
print("a" > "A")
),因为它是输出重定向符号。
如果省略参数,即
print;
等价于
print $0;
。
print输出数值
print在输出数据时,总是会先转换成字符串再输出。
对于数值而言,可以自定义转换成字符串的格式,例如使用sprintf()进行格式化。
print在自动转换数值(专指小数)为字符串的时候,采用预定义变量OFMT(Output format)定义的格式按照sprintf()相同的方式进行格式化。OFMT默认值为
%.6g
,表示有效位(整数部分加小数部分)最多为6。
$ awk 'BEGIN{print 3.12432623}'
3.12433
可以修改OFMT,来自定义数值转换为字符串时的格式:
# 格式化到小数点后2为,小数点第3位数值大于等于5,会四舍五入进一位。
$ awk 'BEGIN{OFMT="%.2f" ;print 3.1415926 }'
# 格式化为整数,不会四舍五入。
$ awk 'BEGIN{OFMT="%d" ;print 3.1415926 }'
# 格式化为整数,会四舍五入。
$ awk 'BEGIN{OFMT="%.0f";print 3.99989}'
4
2、printf
printf format, item1, item2, ...
格式化字符:
|
符号
|
说明
|
|
%c
|
将ASCII码转换为字符,示例:
awk "BEGIN{printf \"%c\",65}"
输出
A
|
|
%d,%i
|
转换为整数,直接截断而不会四舍五入,示例:
awk "BEGIN{printf \"%d\",3.1415}"
输出
3
|
|
%e,%E
|
科学计数法方式输出数值
|
|
%f,%F
|
浮点数方式输出,会四舍五入,示例:
awk "BEGIN{printf \"%.2f\",1.379}"
输出1.38
|
|
%g,%G
|
输出为浮点数,或科学计数法格式
|
|
%o
|
将数字识别为8进制,然后转换为10进制,再缓缓为字符串输出
|
|
%s
|
输出字符串
|
|
%x,%X
|
经数字识别为16进制,然后再转换为10进制,再转换为自负床输出
|
|
%%
|
输出百分号%
|
3、sprintf()
sprintf()采用和printf相同的方式格式化字符串,但是它不会输出格式化后的字符串,而是返回格式化后的字符串。所以,可以将格式化后的字符串赋值给某个变量。
awk '
BEGIN{
a = sprintf("%03d", 12.34)
print a # 012
'
4、stdin、stdout、stderr
awk重定向时可以直接使用
/dev/stdin
、
/dev/stdout
和
/dev/stderr
。还可以直接使用某个已打开的文件描述符
/dev/fd/N
。
例如:
awk 'BEGIN{print "something OK" > "/dev/stdout"}'
awk 'BEGIN{print "something wrong" > "/dev/stderr"}'
awk 'BEGIN{print "something wrong" | "cat >&2"}'
awk 'BEGIN{getline < "/dev/stdin";print $0}'
$ exec 4<> a.txt
$ awk 'BEGIN{while((getline < "/dev/fd/4")>0){print $0}}'
十一、close 关闭句柄
🐳
有时我们需要用shell脚本处理一些文件,通常我们会使用awk这个强大的可编程命令来处理文本文件,当我们在一次awk调用中处理很多文件时,如果没有正确的关闭打开的文件和管道,则会造成文件句柄泄露,awk命令会报错,我们通过以下测试说明这个问题,并看看如何正确的使用close命令解决这个问题。
close(filename)
close(cmd,[from | to]) # to参数只用于coprocess的第一个阶段
如果close()关闭的对象不存在,awk不会报错,仅仅只是让其返回一个负数返回值。
close()有两个基本作用:
-
关闭文件,丢弃已有的文件偏移指针,下次再读取文件,将只能重新打开文件,重开文件会从文件最开头处开始读取。
-
发送EOF标记
awk中任何文件都只会在第一次使用时打开,之后都不会再重新打开。只有关闭之后,再使用才会重新打开。
我们先用ulimit命令查看一个进程最多可以打开多少个文件句柄,通常是1024。:
ulimit -n
生成一批测试文件,数量超过1024,这里我们生成了10000个文件用于测试:
mkdir test
cd test
for ((i=0; i < 10000; ++i)); do
filename=$(printf "file%04d" $i);
echo $filename;
for ((j=0; j < 10; ++j)); do
echo line$j >> ${filename};
done;
done
我们来看看下面这个awk命令的执行情况:
ls file* | awk 'BEGIN {
count=0;
file=$0;
if (getline line <file)
count++;
END {
print count;
}'
这个命令用于统计非空文件的个数,当然这不是最好的方法,在这里只用于awk打开文件的测试,命令执行时会提示:
awk: cmd. line:6: (FILENAME=- FNR=1022) fatal: too many pipes or input files open
可见打开了太多的文件,可以在if语句后面加上close来关闭打开的文件以解决这个问题,如下:
ls file* | awk 'BEGIN {
count=0;
file=$0;
if (getline line <file)
count++;
close(file);
END {
print count;
}'
除了打开文件占用文件句柄之外的另一种占用文件句柄的情况就是调用shell命令并用管道处理,这种情况也要用close关闭打开管道,close的参数必须与打开管道的命令字符串完全一致,例如:
ls file* | awk 'BEGIN {
count=0;
file=$0;
while ("cat "file | getline line)
count++;
close("cat "file);
END {
print count;
}'
这个问题有一个例外,就是我们用getline读入一个文件时,遇到文件结束(getline失败时)awk会自动关闭这个文件,不需要主动close,例如以下统计所有文件行数的命令是可以正确执行的,这个便利并不适用于管道,如上例所示,管道还是需要主动关闭的:
ls file* | awk 'BEGIN {
count=0;
file=$0;
while (getline line <file)
count++;
END {
print count;
}'
十二、awk 变量
🐋
1、变量赋值
awk中的变量赋值语句也可以看作是一个
有返回值
的表达式。
例如,
a=3
赋值完成后返回3,同时变量a也被设置为3。
基于这个特点,有两点用法:
-
可以
x=y=z=5
,等价于
z=5 y=5 x=5
-
可以将赋值语句放在任意允许使用表达式的地方
-
x != (y = 1)
-
awk 'BEGIN{print (a=4);print a}'
问题:
a=1;arr[a+=2] = (a=a+6)
是怎么赋值的,对应元素结果等于?
arr[3]=7
。但不要这么做,因为不同awk的赋值语句左右两边的评估顺序有可能不同。
2、awk中声明变量的位置
-
在BEGIN或main或END代码段中直接引用或赋值
-
使用
-v var=val
选项,可定义多个,必须放在awk代码的前面
-
它的变量声明早于BEGIN块
-
普通变量:
awk -v age=123 'BEGIN{print age}'
-
使用shell变量赋值:
awk -v age=$age 'BEGIN{print age}'
-
在awk代码后面使用
var=val
参数
-
它的变量声明在BEGIN之后
-
awk '{print n}' n=3 a.txt n=4 b.txt
-
awk '{print $1}' FS=' ' a.txt FS=":" /etc/passwd
-
使用Shell变量赋值:
awk '{print age}' age=$age a.txt
十三、awk 流程控制
🐬
1、if…else
语法如下所示:
# 单独的if
if(cond){
statements
# if...else
if(cond1){
statements1
} else {
statements2
# if...else if...else
if(cond1){
statements1
} else if(cond2){
statements2
} else if(cond3){
statements3
} else{
statements4
}
示例:
awk '{if($1<5){print $1}}' a.txt
awk '{if($1<5){print $1} else {print 666}}' a.txt
awk '/^[0-9]/{if($1<5){print $1}else if ($1<8&&$1>=5){print 333}else {print 666}}' a.txt
2、三目运算符?:
语法如下所示:
expr1 ? expr2 : expr3
# 相当于
if(expr1){
expr2
} else {
expr3
}
执行流程:表达式1为真返回表达式2,表达式1为假返回表达式3,示例如下
awk 'BEGIN{a=50;b=(a>60) ? "及格" : "不及格";print(b)}'
awk 'BEGIN{a=50; a>60 ? b="及格" : b="不及格";print(b)}'
awk '/^[0-9]/{$4>23 ? b="old" : b="young";print(b)}' a.txt
3、switch…case
switch (expression) {
case value1|regex1 : statements1
case value2|regex2 : statements2
case value3|regex3 : statements3
[ default: statement ]
}
awk 中的switch分支语句功能较弱,只能进行等值比较或正则匹配。
各分支结尾需使用break来终止。
awk '
switch($1){
case 1:
print("Monday")
break
case 2:
print("Tuesday")
break
case 3:
print("Wednesday")
break
case 4:
print("Thursday")
break
case 5:
print("Friday")
break
case 6:
print("Saturday")
break
case 7:
print("Sunday")
break
default:
print("What day?")
break
}' a.txt
分支穿透:
awk '{
switch($1){
case 1:
case 2:
case 3:
case 4:
case 5:
print("Weekday")
break
case 6:
case 7:
print("Weekend")
break
default:
print("What day?")
break
}' a.txt
4、while和do…while
while(condition){
statements
statements
} while(condition)
while先判断条件再决定是否执行statements,do…while先执行statements再判断条件决定下次是否再执行statements。
awk 'BEGIN{i=0;while(i<5){print i;i++}}'
awk 'BEGIN{i=0;do {print i;i++} while(i<5)}'
多数时候,while和do…while是等价的,但如果第一次条件判断失败,则do…while和while不同。
awk 'BEGIN{i=0;while(i == 2){print i;i++}}'
awk 'BEGIN{i=0;do {print i;i++} while(i ==2 )}'
所以,while可能一次也不会执行,do…while至少会执行一次。
一般用while,do…while相比while来说,用的频率非常低。
5、for循环
for (expr1; expr2; expr3) {
statement
for (idx in array) {
statement
}
示例:
awk 'BEGIN{for(i=0;i<10;i++){print i}}'
6、break和continue
break可退出for、while、do…while、switch语句。
continue可让for、while、do…while进入下一轮循环。
awk '
BEGIN{
for(i=0;i<10;i++){
if(i==5){
break
print(i)
# continue
for(i=0;i<10;i++){
if(i==5)continue
print(i)
}'
7、next和nextfile
next会在当前语句处立即停止后续操作,并读取下一行,进入循环顶部。
例如,输出除第3行外的所有行。
awk 'NR==3{next}{print}' a.txt
awk 'NR==3{getline}{print}' a.txt
nextfile会在当前语句处立即停止后续操作,并直接读取下一个文件,并进入循环顶部。
例如,每个文件只输出前2行:
awk 'FNR==3{nextfile}{print}' a.txt a.txt
8、exit
exit [exit_code]
直接退出awk程序。
注意,END语句块也是exit操作的一部分,所以在BEGIN或main段中执行exit操作,也会执行END语句块。
如果exit在END语句块中执行,则立即退出。
所以,如果真的想直接退出整个awk,则可以先设置一个flag变量,然后在END语句块的开头检查这个变量再exit。
BEGIN{
...code...
if(cond){
flag=1
if(flag){
...code...
awk '
BEGIN{print "begin";flag=1;exit}
END{if(flag){exit};print "end2"}
'
exit可以指定退出状态码,如果触发了两次exit操作,即BEGIN或main中的exit触发了END中的exit,且END中的exit没有指定退出状态码时,则采取前一个退出状态码。
$ awk 'BEGIN{flag=1;exit 2}{}END{if(flag){exit 1}}'
$ echo $?
$ awk 'BEGIN{flag=1;exit 2}{}END{if(flag){exit}}'
$ echo $?
2
十四、数组
🐟
awk数组特性:
1、awk访问、赋值数组元素
arr[idx]
arr[idx] = value
索引可以是整数、负数、0、小数、字符串。如果是数值索引,会按照CONVFMT变量指定的格式先转换成字符串。
例如:
awk '
BEGIN{
arr[1] = 11
arr["1"] = 111
arr["a"] = "aa"
arr[-1] = -11
arr[4.3] = 4.33
print arr[1] # 111
print arr["1"] # 111
print arr["a"] # aa
print arr[-1] # -11
print arr[4.3] # 4.33
'
通过索引的方式访问数组中不存在的元素时,会返回空字符串,同时会创建这个元素并将其值设置为空字符串
。
awk '
BEGIN{
arr[-1]=3;
print length(arr); # 1
print arr[1];
print length(arr) # 2
}'
2、awk数组长度
awk提供了
length()
函数来获取数组的元素个数,它也可以用于获取字符串的字符数量。还可以获取数值转换成字符串后的字符数量。
awk 'BEGIN{arr[1]=1;arr[2]=2;print length(arr);print length("hello")}'
3、awk删除数组元素
-
delete arr[idx]:删除数组 arr[idx]元素,删除不存在的元素不会报错
-
delete arr
:删除数组所有元素
$ awk 'BEGIN{arr[1]=1;arr[2]=2;arr[3]=3;delete arr[2];print length(arr)}'
2
4、awk检测是否是数组
isarray(arr)
可用于检测arr是否是数组,如果是数组则返回1,否则返回0。
awk 'BEGIN{
arr[1]=1;
print isarray(arr);
}'
5、awk测试元素是否在数组中
不要使用下面的方式来测试元素是否在数组中:
if(arr["x"] != ""){...}
这有两个问题:
-
如果不存在arr[“x”],则会立即创建该元素,并将其值设置为空字符串
-
有些元素的值本身就是空字符串
应当使用数组成员测试操作符in来测试:
# 注意,idx不要使用index,它是一个内置函数
if (idx in arr){...}
它会测试索引idx是否在数组中,如果存在则返回1,不存在则返回0。
awk '
BEGIN{
arr[1]=1;
arr[2]=2;
arr[3]=3;
arr[1]="";
delete arr[2];
print (1 in arr); # 1
print (2 in arr); # 0
}'
6、awk遍历数组
awk提供了一种for变体来遍历数组:
for(idx in arr){print arr[idx]}
因为awk数组是关联数组,元素是不连续的,也就是说没有顺序。遍历awk数组时,顺序是不可预测的。
例如:
awk '
BEGIN{
arr["one"] = 1
arr["two"] = 2
arr["three"] = 3
arr["four"] = 4
arr["five"] = 5
for(i in arr){
print i " -> " arr[i]
'
此外,不要随意使用
for(i=0;i<length(arr);i++)
来遍历数组,因为awk数组是关联数组。但如果已经明确知道数组的所有元素索引都位于某个数值范围内,则可以使用该方式进行遍历。
例如:
awk '
BEGIN{
arr[1] = "one"
arr[2] = "two"
arr[3] = "three"
arr[4] = "four"
arr[5] = "five"
arr[10]= "ten"
for(i=0;i<=10;i++){
if(i in arr){
print arr[i]
'
7、awk 子数组
子数组是指数组中的元素也是一个数组,即Array of Array,它也称为子数组(subarray)。
awk也支持子数组,在效果上即是嵌套数组或多维数组。
a[1][1] = 11
a[1][2] = 12
a[1][3] = 13
a[2][1] = 21
a[2][2] = 22
a[2][3] = 23
a[2][4][1] = 241
a[2][4][2] = 242
a[2][4][1] = 241
a[2][4][3] = 243
通过如下方式遍历二维数组:
for(i in a){
for (j in a[i]){
if(isarray(a[i][j])){
continue
print a[i][j]
}
8、awk指定数组遍历顺序
由于awk数组是关联数组,默认情况下,
for(idx in arr)
遍历数组时顺序是不可预测的。
但是gawk提供了
PROCINFO["sorted_in"]
来指定遍历的元素顺序。它可以设置为两种类型的值:
-
设置为用户自定义函数
-
设置为下面这些awk预定义好的值:
-
@unsorted
:默认值,遍历时无序
-
@ind_str_asc
:索引按字符串比较方式升序遍历
-
@ind_str_desc
:索引按字符串比较方式降序遍历
-
@ind_num_asc
:索引强制按照数值比较方式升序遍历。所以无法转换为数值的字符串索引将当作数值0进行比较
-
@ind_num_desc
:索引强制按照数值比较方式降序遍历。所以无法转换为数值的字符串索引将当作数值0进行比较
-
@val_type_asc
:按值升序比较,此外数值类型出现在前面,接着是字符串类型,最后是数组类(即认为
num<str<arr
)
-
@val_type_desc
:按值降序比较,此外数组类型出现在前面,接着是字符串类型,最后是数值型(即认为
num<str<arr
)
-
@val_str_asc
:按值升序比较,数值转换成字符串再比较,而数组出现在尾部(即认
str<arr
)
-
@val_str_desc
:按值降序比较,数值转换成字符串再比较,而数组出现在头部(即认
str<arr
)
-
@val_num_asc
:按值升序比较,字符串转换成数值再比较,而数组出现在尾部(即认
num<arr
)
-
@val_num_desc
:按值降序比较,字符串转换成数值再比较,而数组出现在头部(即认为
num<arr
)
例如:
awk '
BEGIN{
arr[1] = "one"
arr[2] = "two"
arr[3] = "three"
arr["a"] ="aa"
arr["b"] ="bb"
arr[10]= "ten"
#PROCINFO["sorted_in"] = "@ind_num_asc"
#PROCINFO["sorted_in"] = "@ind_str_asc"
PROCINFO["sorted_in"] = "@val_str_asc"
for(idx in arr){
print idx " -> " arr[idx]
# 输出如下:
a -> aa
b -> bb
1 -> one
2 -> two
3 -> three
10 -> ten
十五、awk 自定义函数
🐠
可以定义一个函数将多个操作整合在一起。函数定义之后,可以到处多次调用,从而方便复用。
1、函数定义
使用function关键字来定义函数:
function func_name([parameters]){
function_body
}
对于gawk来说,也支持func关键字来定义函数。
func func_name(){}
函数可以定义在下面使用下划线的地方:
awk '_ BEGIN{} _ MAIN{} _ END{} _'
无论函数定义在哪里,都能在任何地方调用,因为awk在BEGIN之前,会先编译awk代码为内部格式,在这个阶段会将所有函数都预定义好。
例如:
awk '
BEGIN{
function f(){
print "星期一"
print "星期二"
print "星期三"
print "星期四"
print "星期五"
print "星期六"
print "星期日"
'
2、awk函数的return语句
如果想要让函数有返回值,那么需要在函数中使用return语句。
return语句也可以用来立即结束函数的执行。
例如:
awk '
function add(){
return 40
BEGIN{
print add()
res = add()
print res
40
如果不使用return或return没有参数,则返回值为空,即空字符串。
awk '
function f1(){ }
function f2(){return }
function f3(){return 3}
BEGIN{
print "-"f1()"-"
print "-"f2()"-"
print "-"f3()"-"
-3-
3、awk函数参数
为了让函数和调用者能够进行数据的交互,可以使用参数。
awk '
function f(a,b){
print a
print b
return a+b
BEGIN{
res = f(x,y)
print res
print f(x,y)
'
例如,实现一个重复某字符串指定次数的函数:
awk '
function repeat(str,cnt,res_str){
for(i=0;i<cnt;i++){
res_str = res_str""str
return res_str
BEGIN{
print repeat("abc",3)
print repeat("-",30)
# 输出如下:
abcabcabc
------------------------------
调用函数时,实参数量可以比形参数量少,也可以比形参数量多。但是,在多于形参数量时会给出警告信息。
awk '
function repeat(str,cnt,res_str){
for(i=0;i<cnt;i++){
res_str = res_str""str
return res_str
BEGIN{
print repeat("abc",3)
print repeat("-",30,1,2,3,4)
# 输出如下
abcabcabc
awk: cmd. line:10: warning: function `repeat' called with more arguments than declared
1------------------------------
4、awk函数参数数据类型冲突问题
如果函数内部使用参数的类型和函数外部变量的类型不一致,会出现数据类型不同而导致报错。
awk '
function f(a){
a[1]=30
BEGIN{
a="hello world"
f(a) # 报错
x=10 # 报错
# 输出报错如下:
awk: cmd. line:3: fatal: attempt to use scalar parameter `a' as an array
函数内部参数对应的是数组,那么外面对应的也必须是数组类型。
5、awk参数按值传递还是按引用传递
在调用函数时,将数据作为函数参数传递给函数时,有两种传递方式:
-
传递普通变量时,是按值拷贝传递
-
直接拷贝普通变量的
值
到函数中
-
函数内部修改不会影响到外部
-
传递数组时,是按引用传递
# 传递普通变量:按值拷贝
awk '
function modify(a){
print a
BEGIN{
modify(a)
print a
# 输出如下:
40
# 传递数组:按引用拷贝
awk '
function modify(a){
a[1]=20
BEGIN{
a[1]=10
modify(a)
print a[1]
# 输出如下
20
6、awk作用域问题
awk只有在函数参数中才是局部变量,其它地方定义的变量均为全局变量。
函数内部新增的变量是全局变量
,会影响到全局,所以在函数退出后仍然能访问。
awk '
function f(){
a=30 # 新增的变量,是全局变量
print "in f: " a
BEGIN{
print a # 30
'
函数参数会遮掩全局同名变量,所以在函数执行时,无法访问到或操作与参数同名的全局变量,函数退出时会自动撤掉遮掩,这时才能访问全局变量。所以,参数具有局部效果。
awk '
function f(a){
print a # 50,按值拷贝,和全局a已经没有关系
print a # 40
BEGIN{
print a # 50,函数退出,重新访问全局变量
'
由于函数内部新增变量均为全局变量,awk也没有提供关键字来修饰一个变量使其成为局部变量。所以,awk只能将本该出现在函数体内的局部变量放在参数列表中,只要调用函数时不要为这些参数传递数据即可,从而实现局部变量的效果。
awk '
function f(a,b ,c,d){
# a,b是参数,调用时需传递两个参数
# c,d是局部变量,调用时不要给c和d传递数据
e=70 # 全局变量
print a,b,c,d,e # 30 40 50 60 70
BEGIN{
f(a,b) # 调用函数时值传递两个参数
print a,b,c,d,e # 31 41 51 61 70
'
所以,awk对函数参数列表做了两类区分:
-
arguments:调用函数时传递的参数
-
local variables:调用函数时省略的参数
为了区分arguments和local variables,约定俗成的,将local variables放在一大堆空格后面来提示用户。例如
function name(a,b, c,d)
表示调用函数时,应当传递两个参数,c和d是本函数内部使用的局部变量,不要传递对应的参数。
区分参数和局部变量:
-
参数提供了函数和它调用者进行数据交互的方式
-
局部变量是临时存放数据的地方
arguments部分体现的是函数调用时传递的参数,这些参数在函数内部会遮掩全局同名变量。例如上面示例中,函数内部访问不了全局的a和b,所有对a和b的操作都是函数内部的,函数退出后才能重新访问全局a和b。因此,arguments也有局部特性。
local variables是awk实现真正局部变量的技巧,只是因为函数内部新增的变量都是全局变量,所以退而求其次将其放在参数列表上来实现局部变量。
十六、awk数值类内置函数
🌳
1、awk数值类内置函数
int(expr) 截断为整数:int(123.45)和int("123abc")都返回123,int("a123")返回0
sqrt(expr) 返回平方根
rand() 返回[0,1)之间的随机数,默认使用srand(1)作为种子值
srand([expr]) 设置rand()种子值,省略参数时将取当前时间的epoch值(精确到秒的epoch)作为种子值
例如:
$ awk 'BEGIN{srand();print rand()}'
0.0379114
$ awk 'BEGIN{srand();print rand()}'
0.0779783
$ awk 'BEGIN{srand(2);print rand()}'
0.893104
$ awk 'BEGIN{srand(2);print rand()}'
0.893104
生成
[10,100]
之间的随机整数。
awk 'BEGIN{srand();print 10+int(91*rand())}'
2、awk字符串类内置函数
注意,awk中涉及到
字符索引的函数,索引位都是从1开始计算
,和其它语言从0开始不一样。
(1)基本函数
-
sprintf(format, expression1, ...)
:返回格式化后的字符串
-
length()
:返回字符串字符数量、数组元素数量、或数值转换为字符串后的字符数量
awk '
BEGIN{
print length(1.23) # 4 # CONVFMT %.6g
print 1.234567 # 1.23457
print length(1.234567) # 7
print length(122341223432.1213241234) # 11
}'
-
strtonum(str)
:将字符串转换为十进制数值
-
如果str以0开头,则将其识别为8进制
-
如果str以0x或0X开头,则将其识别为16进制
-
tolower(str)
:转换为小写
-
toupper(str)
:转换为大写
-
index(str,substr)
:从str中搜索substr(子串),返回搜索到的索引位置(索引从1开始),搜索不到则返回0
(2)awk substr()
-
substr(string,start[,length])
:从string中截取子串
start是截取的起始索引位(索引位从1开始而非0),length表示截取的子串长度。如果省略length,则表示从start开始截取剩余所有字符。
awk '
BEGIN{
str="abcdefgh"
print substr(str,3) # cdefgh
print substr(str,3,3) # cde
'
如果start值小于1,则将其看作为1对待,如果start大于字符串的长度,则返回空字符串。
如果length小于或等于0,则返回空字符串。
(3)awk split()和patsplit()
-
split(string, array [, fieldsep [, seps ] ])
:将字符串分割后保存到数组array中,数组索引从1开始存储。并返回分割得到的元素个数
其中fieldsep指定分隔符,可以是正则表达式方式的。如果不指定该参数,则默认使用FS作为分隔符,而FS的默认值又是空格。
seps是一个数组,保存了每次分割时的分隔符。
例如:
split("abc-def-gho-pq",arr,"-",seps)
其返回值为4。同时得到的数组a和seps为:
arr[1] = "abc"
arr[2] = "def"
arr[3] = "gho"
arr[4] = "pq"
seps[1] = "-"
seps[2] = "-"
seps[3] = "-"
split在开始工作时,会先清空数组,所以,将split的string参数设置为空,可以用于清空数组。
awk 'BEGIN{arr[1]=1;split("",arr);print length(arr)}' # 0
如果分隔符无法匹配字符串,则整个字符串当作一个数组元素保存到数组array中。
awk 'BEGIN{split("abcde",arr,"-");print arr[1]}' # abcde
-
patsplit(string, array [, fieldpat [, seps ] ])
:用正则表达式fieldpat匹配字符串string,将所有匹配成功的部分保存到数组array中,数组索引从1开始存储。返回值是array的元素个数,即匹配成功了多少次
如果省略fieldpat,则默认采用预定义变量FPAT的值。
awk '
BEGIN{
patsplit("abcde",arr,"[a-z]")
print arr[1] # a
print arr[2] # b
print arr[3] # c
print arr[4] # d
print arr[5] # e
'
(4)awk match()
-
match(string,reg[,arr])
:使用reg匹配string,返回匹配成功的索引位(从1开始计数),匹配失败则返回0。如果指定了arr参数,则arr[0]保存的是匹配成功的字符串,arr[1]、arr[2]、…保存的是各个分组捕获的内容
match匹配时,同时会设置两个预定义变量:RSTART和RLENGTH
-
匹配成功时:
-
RSTART赋值为匹配成功的索引位,从1开始计数
-
RLENGTH赋值为匹配成功的字符长度
-
匹配失败时:
例如:
awk '
BEGIN{
where = match("foooobazbarrrr","(fo+).*(bar*)",arr)
print where # 1
print arr[0] # foooobazbarrrr
print arr[1] # foooo
print arr[2] # barrrr
print RSTART # 1
print RLENGTH # 14
'
因为match()匹配成功时返回值为非0,而匹配失败时返回值为0,所以可以直接当作条件判断:
awk '
if(match($0,/A[a-z]+/,arr)){
print NR " : " arr[0]
' a.txt
(5)awk sub()和gsub()
-
sub(regexp, replacement [, target])
-
gsub(regexp, replacement [, target])
:sub()的全局模式
sub()从字符串target中进行正则匹配,并使用replacement对第一次匹配成功的部分进行替换,替换后保存回target中。返回替换成功的次数,即0或1。
target必须是一个可以赋值的变量名、$N或数组元素名,以便用它来保存替换成功后的结果。不能是字符串字面量,因为它无法保存数据。
如果省略target,则默认使用
$0
。
需要注意的是,如果省略target,或者target是
$N
,那么替换成功后将会使用OFS重新计算
$0
。
awk '
BEGIN{
str="water water everywhere"
#how_many = sub(/at/, "ith", str)
how_many = gsub(/at/, "ith", str)
print how_many # 1
print str # wither water everywhere
'
在replacement参数中,可以使用一个特殊的符号
&
来引用匹配成功的部分。注意sub()和gsub()不能在replacement中使用反向引用
\N
。
awk '
BEGIN{
str = "daabaaa"
gsub(/a+/,"C&C",str)
print str # dCaaCbaaa
'
如果想要在replacement中使用
&
纯字符,则转义即可。
sub(/a+/,"C\\&C",str)
两根反斜线:
因为awk在正则开始工作时,首先会扫描所有awk代码然后编译成awk的内部格式,扫描期间会解析反斜线转义,使得
\\
变成一根反斜线。当真正开始运行后,sub()又要解析,这时
\&
才表示的是对&做转义。
扫描代码阶段称为词法解析阶段,运行解析阶段称为运行时解析阶段。
(6)awk gensub()
gawk支持的gensub(),完全可以取代sub()和gsub()。
-
gensub(regexp, replacement, how [, target])
:
可以替代sub()和gsub()。
how指定替换第几个匹配,例如指定为1表示只替换第一个匹配。此外,还可以指定为
g
或
G
开头的字符串,表示全局替换。
gensub()返回替换后得到的结果,而target不变,如果匹配失败,则返回target。这和sub()、gsub()不一样,sub()、gsub()返回的是替换成功的次数。
gensub()的replacement部分可以使用
\N
来引用分组匹配的结果,而sub()、gsub()不允许使用反向引用。而且,gensub()在replacement部分也还可以使用
&
或
\0
来表示匹配的整个结果。
awk 'BEGIN{
a = "abc def"
b = gensub(/(.+) (.*)/, "\\2 \\1, \\0 , &", "g", a)
print b # def abc, abc def , abc def
}'
(7)awk asort()和asorti()
-
asort(src,[dest [,how]])
-
asorti(src,[dest [,how]])
asort对数组src的值进行排序,然后将排序后的值的索引改为1、2、3、4…序列。返回src中的元素个数,它可以当作排序后的索引最大值。
asorti对数组src的索引进行排序,然后将排序后的索引值的索引改为1、2、3、4…序列。返回src中的元素个数,它可以当作排序后的索引最大值。
arr["last"] = "de"
arr["first"] = "sac"
arr["middle"] = "cul"
asort(arr)得到:
arr[1] = "cul"
arr[2] = "de"
arr[3] = "sac"
asorti(arr)得到:
arr[1] = "first"
arr[2] = "last"
arr[3] = "middle"
如果指定dest,则将原始数组src备份到dest,然后对dest进行排序,而src保持不变。
how参数用于指定排序时的方式,其值指定方式和
PROCINFO["sorted_in"]
一致:可以是预定义的排序函数,也可以是用户自定义的排序函数。
参考链接
🌹
感谢以下大佬文章的支持。
1️⃣
在awk中正确使用close避免文件句柄泄露
2️⃣
精通awk系列文章 | 骏马金龙 (junmajinlong.com)
© 2024 木木博客 -
木木博客(www.whbblog.cn),记录博主的成长历程及学习经验,专注于分享F5配置教程、基础网络技术,欢迎您的访问,给您的帮助是我最大的动力。
站点已稳定运行:
90
天
16
时
32
分
26
秒