HTML 和纯文本都是网页内容的表现形式,但它们之间存在着显著的区别。HTML 是一种标记语言,用于定义网页的结构和内容,而纯文本则是不包含任何格式或标记的简单文本,尽管 HTML 可以使网页看起来漂亮且具有交互性,但有时我们需要将其转换为纯文本,例如在网络爬虫和数据分析中,经常需要将从网页中提取的 HTML 内容转换为纯文本进行进一步处理和分析。本文将介绍如何使用
JavaScript
来实现这种转换。
HTML 到纯文本转换的原理
要理解如何将 HTML 转换为纯文本,首先需要了解 HTML 标记的结构以及纯文本的特点。HTML 标记包含了各种标签和属性,而纯文本则是简单的文本内容,不包含任何标记。因此,转换的基本思路是去除 HTML 标记,只保留其中的文本内容。
使用 JavaScript 实现 HTML 到纯文本的转换
当使用 JavaScript 实现 HTML 到纯文本的转换时,有许多种方法可供选择。以下是其中几种常见的方法:
1. 使用正则表达式
正则表达式是一种强大的文本匹配工具,可以用来匹配和删除 HTML 标记。这种方法简单直接,适用于较简单的 HTML 结构。
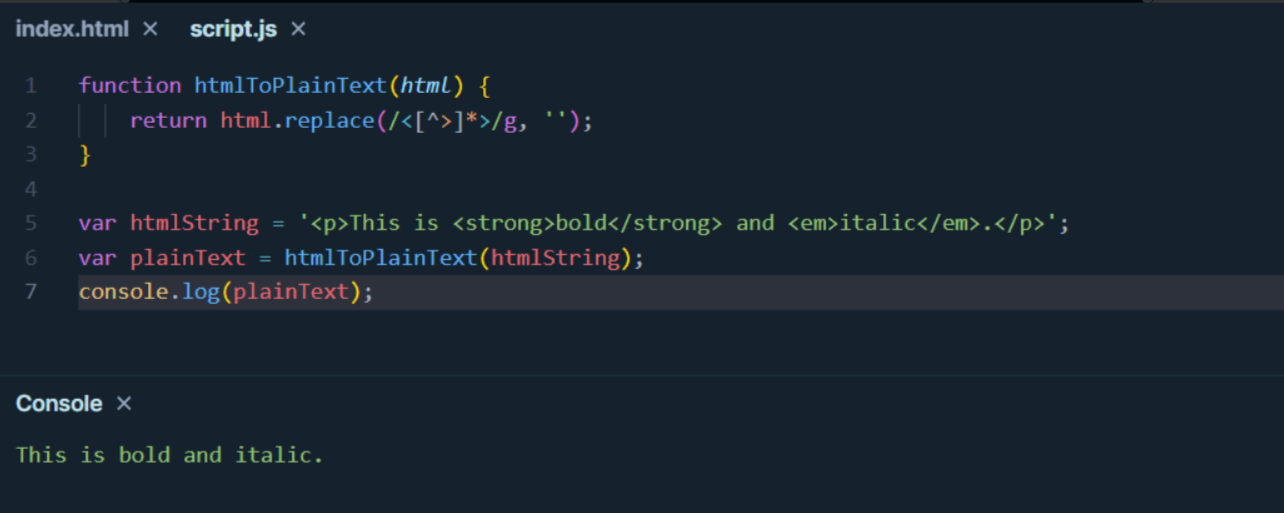
示例代码:
function htmlToPlainText(html) {
return html.replace(/<[^>]*>/g, '');
var htmlString = '<p>This is <strong>bold</strong> and <em>italic</em>.</p>';
var plainText = htmlToPlainText(htmlString);
console.log(plainText);
在这个示例中,
htmlToPlainText
函数使用正则表达式
/<[^>]*>/g
来匹配并删除 HTML 标记,从而将 HTML 转换为纯文本。这个正则表达式
/<[^>]*>/g
用于匹配 HTML 标记,其含义解释如下:
因此,整个正则表达式的含义是匹配 HTML 标记(以左尖括号
<
开始,右尖括号
>
结束),其中可以包含任意数量的除了右尖括号之外的字符。
2.
使用 DOM 解析
DOM(文档对象模型)是 JavaScript 操作 HTML 文档的标准接口,可以使用 DOM 解析器遍历 HTML 元素并提取纯文本内容。这种方法更灵活,适用于复杂的 HTML 结构。
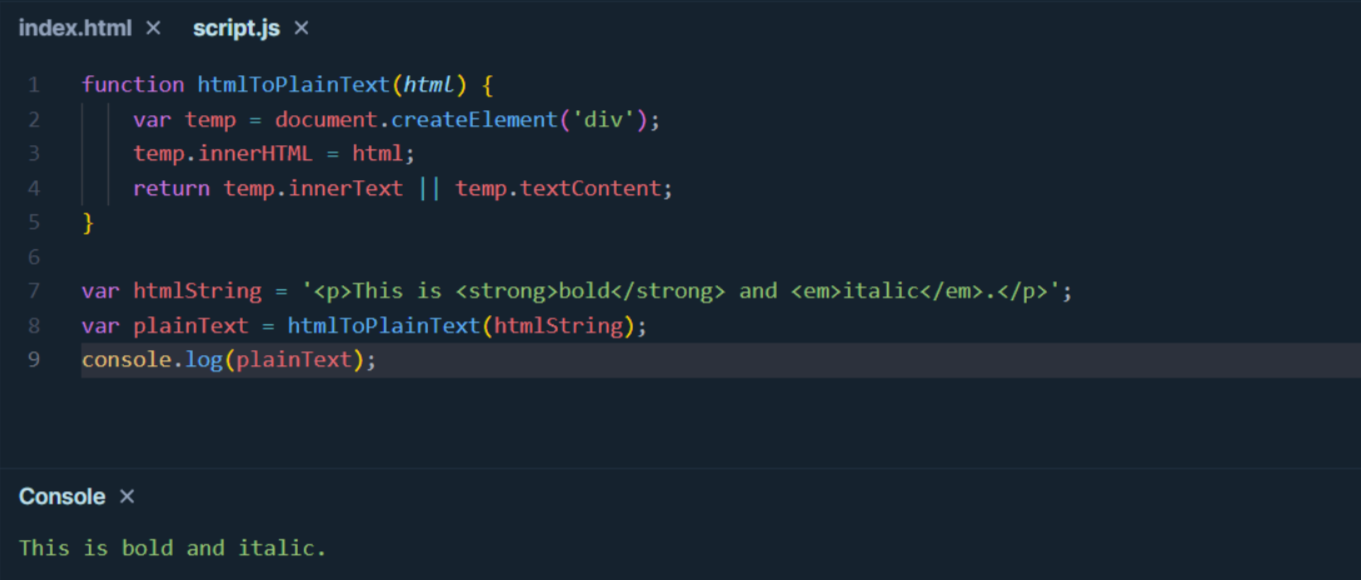
示例代码:
function htmlToPlainText(html) {
var temp = document.createElement('div');
temp.innerHTML = html;
return temp.innerText || temp.textContent;
var htmlString = '<p>This is <strong>bold</strong> and <em>italic</em>.</p>';
var plainText = htmlToPlainText(htmlString);
console.log(plainText);
除了原生的 JavaScript 方法外,还可以使用第三方库来简化 HTML 到纯文本的转换过程。例如,使用 jQuery 库可以更容易地选择和操作 HTML 元素。
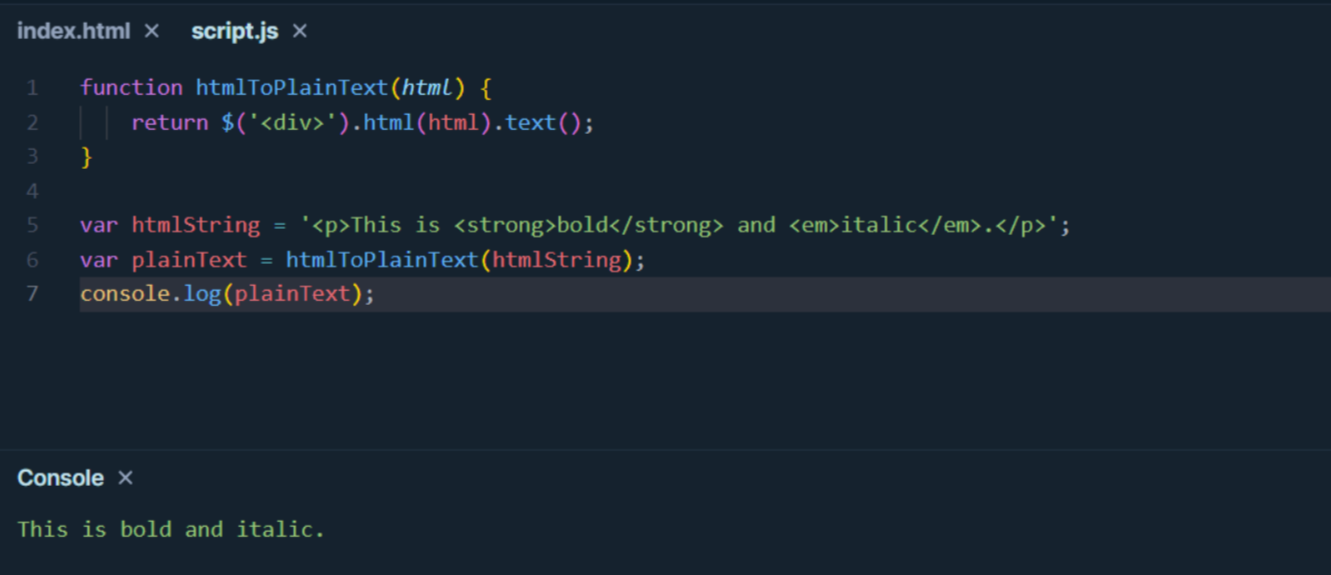
示例代码:
function htmlToPlainText(html) {
return $('<div>').html(html).text();
var htmlString = '<p>This is <strong>bold</strong> and <em>italic</em>.</p>';
var plainText = htmlToPlainText(htmlString);
console.log(plainText);
在这个示例中,我们使用 jQuery 库的
html()
方法将 HTML 字符串插入到一个临时的
<div>
元素中,然后使用
text()
方法获取纯文本内容(记得在项目的 html 中引入 jQuery)。
总结
通过本文的介绍,我们了解了如何使用 JavaScript 将 HTML 转换为格式化的纯文本,尽管这个过程可能有一些挑战,但
JavaScript
提供了许多便捷的方法来实现这一目标。将 HTML 转换为纯文本可以提高内容的可读性和可访问性,同时也为各种应用场景提供了更多的可能性。