

模型在线服务 EAS(Elastic Algorithm Service)是阿里云 PAI 产品提供的一站式模型开发和部署平台,支持通过自定义部署方式来部署 RAG 服务。您可以根据自身业务需求来调整更多配置选项,从而实现更灵活的服务配置。本文将介绍如何自定义部署 RAG 服务,并以 DeepSeek 大语言模型为例,说明如何使用 RAG 服务和 LLM 服务进行知识问答。
背景信息
-
模型介绍
DeepSeek-V3 是由 DeepSeek 推出的一款拥有 6710 亿参数的专家混合(MoE)大语言模型。DeepSeek-R1 是基于 DeepSeek-V3-Base 训练的高性能推理模型。
-
部署与配置
在部署 RAG 服务后,您可以在 WebUI 页面选择大语言模型(LLM)为 EAS 服务(例如 DeepSeek)或 DashScope。在处理用户查询时,RAG 通过信息检索组件在知识库中寻找与查询相关的文档或信息片段,然后将这些检索到的内容与原始查询一同输入大语言模型。模型能够利用其现有的归纳生成能力,生成基于最新信息且符合事实的回复,而无需对模型进行重新训练。
前提条件
-
已创建专有网络(VPC)、交换机和安全组。具体操作,请参见 搭建 IPv4 专有网络 和 创建安全组 。
-
已创建 OSS 存储空间(Bucket)和目录。具体操作,请参见 控制台快速入门 。
部署 RAG 服务
-
登录 PAI 控制台 ,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击 进入 EAS 。
-
在 模型在线服务(EAS) 页面,单击 部署服务 ,然后在 自定义模型部署 区域,单击 自定义部署 。
-
在 自定义部署 页面,配置以下关键参数,其他参数配置说明,请参见 服务部署:控制台 。
参数
描述
示例
基本信息
服务名称
自定义服务名称。
rag_custom
环境信息
部署方式
选择 镜像部署 ,并勾选 开启 Web 应用 。
选择 镜像部署 ,并勾选 开启 Web 应用 。
镜像配置
RAG 服务包含三个核心镜像:API 服务镜像、WebUI 镜像和 Nginx 镜像。在此处无法直接选择 RAG 服务的镜像,您需要参照 步骤 4 完成 RAG 服务镜像的配置。
参照 步骤 4 完成 RAG 服务镜像的配置。
模型配置
建议挂载数据存储,以确保 EAS 服务重启后数据能够持久化保存。
单击 OSS ,并配置以下参数:
-
OSS :选择 OSS 存储路径。
-
挂载路径 :配置为服务本地存储路径
/app/localdata。
资源部署
部署资源
RAG 服务支持部署 CPU 和 GPU 版本。相较于 CPU 版本,GPU 版本在 PDF 文档解析、Embedding 计算以及 ReRanker 模型推理等方面有明显速度优势。因此,如果您对服务响应速度有较高要求,推荐您部署 GPU 版本。两种版本推荐使用的资源规格如下:
-
CPU 版本:建议选择 8 核以上的 CPU 资源和 16 GB 以上的内存,推荐使用 ecs.g6.2xlarge、ecs.g6.4xlarge 等机型。
-
GPU 版本:建议选择 16 GB 以上的 GPU 显存,推荐使用 A10 显卡或 GU30 显卡,例如 ecs.gn7i-c16g1.4xlarge、ml.gu7i.c16m60.1-gu30 机型。
资源规格 选择 CPU > ecs.g6.4xlarge 。
专有网络
专有网络(VPC)
-
当使用 Hologres、ElasticSearch 、Milvus 、OpenSearch 或 RDS PostgreSQL 作为向量检索库时,请确保所配置的专有网络与选定的向量检索库保持一致。
说明-
使用 OpenSearch 作为向量检索库时,此处可以使用其他专有网络,但需要确保该专有网络具有公网访问能力,并将绑定的弹性公网 IP 添加为 OpenSearch 实例的公网访问白名单。具体操作,请参见 使用公网 NAT 网关 SNAT 功能访问互联网 和 公网白名单配置 。
-
EAS 服务默认不通公网,在需要访问通义千问大模型服务 API 时,需要配置公网连接,请参考 EAS 配置公网连接 。
-
-
当使用 Faiss 作为向量检索库时,无需配置专有网络。
本方案选择已创建的专有网络(VPC)交换机和安全组,以便通过内网调用 LLM 服务。
交换机
安全组
-
-
在 服务配置 区域,单击 编辑 按钮,将 JSON 中的 containers 字段内容调整为与资源版本一致的镜像。本方案选择 CPU 版本镜像。
RAG 服务包含三个核心镜像:API 服务镜像、WebUI 镜像和 Nginx 镜像。以华东 1(杭州)为例,containers 字段对应的镜像示例如下。如果您在其他地域部署 RAG 服务,请参考 公共云 ,修改镜像 URL 中的 region 名称。
-
CPU 版本镜像示例:
{ "containers": [ "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/pai-rag:0.2.5-nginx", "port": 8680, "script": "/docker-entrypoint.sh nginx" "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/pai-rag:0.2.5-ui", "port": 8002, "script": "pai_rag ui" "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/pai-rag:0.2.5", "port": 8001, "script": "pai_rag serve" } -
GPU 版本镜像示例:
{ "containers": [ "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/pai-rag:0.2.5-nginx", "port": 8680, "script": "/docker-entrypoint.sh nginx" "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/pai-rag:0.2.5-ui", "port": 8002, "script": "pai_rag ui" "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/pai-rag:0.2.5-gpu", "port": 8001, "script": "pai_rag serve" }
-
-
参数配置完成后,单击 部署 。
部署大语言模型服务
以部署 DeepSeek-R1 模型为例,具体操作步骤如下:
-
通过
-
在 服务详情 页面,分别获取 服务访问地址 、 Token 和 模型名称 。
-
在 基本信息 区域,单击 查看调用信息 ,获取服务访问地址和 Token。
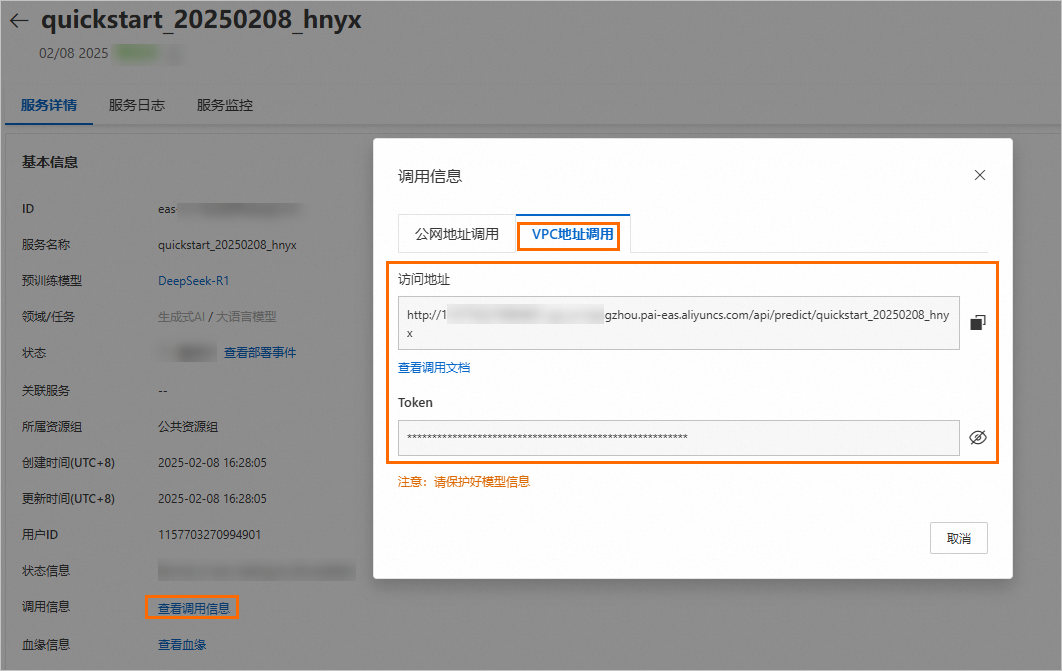
-
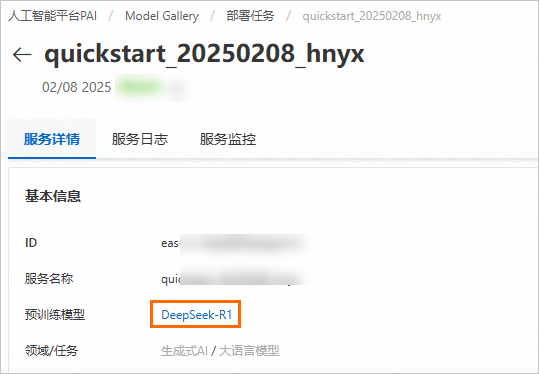
在 基本信息 区域,查询预训练模型名称为 DeepSeek-R1 。您也可以参考 模型列表 获取模型名称。
说明当使用加速部署-vLLM 方式部署服务时,需要获取模型名称。
-
配置 RAG 对话系统
RAG 服务部署成功后,单击 服务方式 列下的 查看 Web 应用 ,启动 WebUI 页面。
请按照以下操作步骤完成以下关键参数配置。更详细的配置说明,请参见 大模型 RAG 对话系统 。
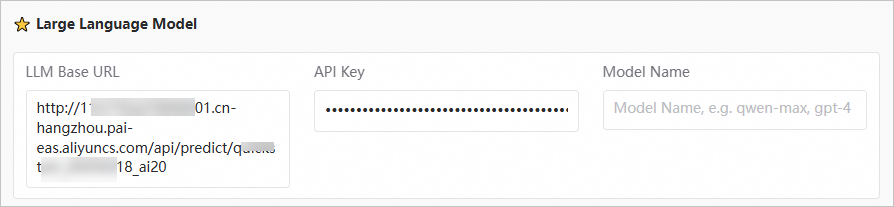
配置 LLM 大语言模型
在
WebUI
页面的
settings
页签,配置
Large Language Model
为已部署的大语言模型服务。
|
参数 |
描述 |
|
LLM Base URL |
填入已部署的大语言模型服务的访问地址。例如
|
|
API Key |
填入已部署的大语言模型服务的 Token。 |
|
Model Name |
当使用加速部署-vLLM 方式部署服务时,需填入相应的模型名称(例如 DeepSeek-R1 )。使用其他方式部署服务时,直接填入 default 或保持默认配置。 |
说明
您也可以将 LLM 大语言模型配置为百炼模型,但:
-
使用百炼模型,您需要给 EAS 配置公网连接 ,并配置百炼的 API Key。如何获取 LLM API Key,请参见 首次调用通义千问 API 。
-
百炼模型调用需单独计费,详情请参见 百炼计费项说明 。
配置向量检索库
系统默认使用
Faiss
作为向量数据库。推荐使用
Faiss
进行测试,而在正式环境中建议使用
Elasticsearch、Milvus
等向量数据库。您可以在
WebUI
页面的
Settings
页签,选择并配置向量数据库参数,具体参数配置说明,请参见
步骤一:部署
RAG
服务
中的向量检索库设置。

说明
如果您在部署 RAG 服务时未进行模型挂载配置,数据(包括 WebUI 上的配置信息)将存储在服务本地。当服务重启后,本地存储的数据会丢失,需要您重新上传数据。为确保数据的持久化存储,建议进行模型挂载配置,详情请参见 如何挂载数据源? 。配置数据源后,数据将被保存到数据源中,即使重启服务,数据也会被保存。
使用 RAG 服务
上传知识库文件 后,您可以在 WebUI 页面的 Chat 页签,进行知识问答。关于 WebUI 调用的更详细使用说明,请参见 步骤二:WebUI 页面调试 。您也可以通过 RAG API 调用模型服务(参考 步骤三:API 调用 ),或通过兼容 OpenAI 的 API 调用模型服务(参考 步骤四:API 调用 )。
-
使用 LLM 进行知识问答。

-
使用 RAG 服务+LLM 进行知识问答。

常见问题
调用 LLM 服务时,访问超时并报错。
请检查大语言模型服务调用地址是否可以访问:
-
如果当前 RAG 服务已 配置公网连接 ,则可以将 LLM Base URL 配置为 LLM 服务的公网访问地址。
-
如果当前 RAG 服务未 配置公网连接 ,则需要确认部署 RAG 服务和 LLM 服务时,绑定了相同的专有网络(VPC)。
调用 LLM 服务时,访问没有超时,直接报错。
请检查模型名称是否配置准确。当使用加速部署-vLLM
方式部署服务时,需填入相应的模型名称(请确保与部署的模型名称完全一致)。使用其他方式部署服务时,直接填入
default
即可。详情请参见
配置
LLM
大语言模型
。

如何挂载数据源?
在部署或更新
RAG
服务时,在
环境信息
区域挂载模型配置。以挂载
OSS
数据源为例:

其中:OSS
为已创建的
OSS
存储路径,挂载路径为服务本地存储路径
/app/localdata
。
相关文档
-
如何将大模型 RAG 对话系统集成到钉钉群聊、微信公众号以及企业微信等场景中,请参见 基于 AppFlow 集成钉钉与 PAI RAG 构建 AI 机器人指南 、 基于 AppFlow 集成微信公众号与 PAI RAG 构建智能客服 、 基于 AppFlow 集成企业微信与 PAI RAG 构建 AI 助手 。
-
如何使用 EAS 场景化部署方式快速部署 RAG 对话系统,请参见 大模型 RAG 对话系统 。