12 月 3 日,2023
IoTDB
用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网
时序数据库
IoTDB 的技术创新、应用效果,与各行业标杆用户的落地实践、解决方案,并共同探讨时序数据管理领域的行业趋势。
我们邀请到天谋科技高级开发工程师,Apache IoTDB PMC Member 田原参加此次大会,并做主题报告——《尽其用:如何用 IoTDB 发掘数据的无限潜能》。以下为内容全文。
大家好,我是来自天谋科技的田原,在天谋科技主要负责 IoTDB 的查询引擎的相关工作。今天 talk 的题目刚才主持人也介绍了,主要也是跟数据查询相关的。
我今天的演讲主要分这四个部分去展开。先跟大家简单介绍一下 IoTDB 强大的查询性能,然后就是 IoTDB 一些具有时序特色的查询的算子。第三个部分会跟大家介绍一下 UDF 函数库,在早上的时候王老师可能也提过了,我们清华团队,其实宋老师组去做了不只有压缩的算法,还有一些工业上的数据质量的函数库,都在我们 UDF 函数库里面会去介绍。第四,会跟大家介绍一些真实的时序场景,并且会跟关系型的 SQL 去做一些对比,大家能够真实地去感受到,用 IoTDB 的 SQL 去写一些查询语句,会比关系型数据库更加容易。
01 IoTDB 强大的查询性能
首先,第一个部分就是 IoTDB 强大的查询性能。程序员可能经常会说的就是:“Talk is cheap, show me the code.” 所以在数据库领域,大家经常也会说:“talk is cheap, show me the benchmark result.” 在时序场景里面,大家可能比较公认的一个测试套件叫 TSBS,那么 IoTDB 在今年也是上榜了 benchANT。benchANT 是位于德国的一家第三方的,做云设施或者说数据库测评的一个机构,作为第三方的一个机构,它当然不仅仅是做时序数据库。它在时序数据库的这个板块,主要采用的就是刚刚说的 TSBS 这样一个测试套件。它包含两种环境,都是大家在 AWS 上面可复现的,一种是 2 核 8GB 的,还有一种是 4 核 16GB 的这两种环境。
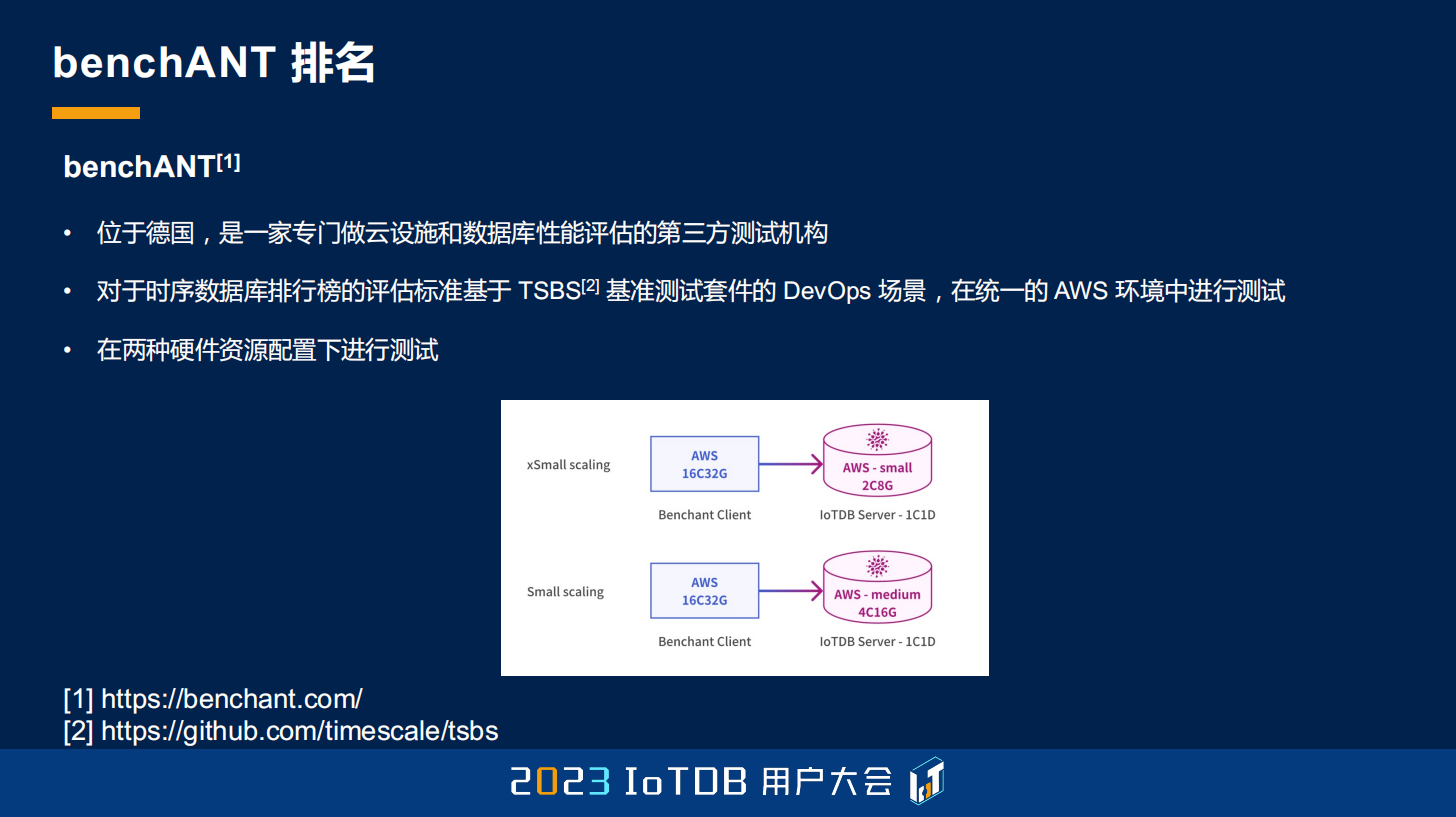
IoTDB 在这两种环境下面表现都相当优异,不能说全面碾压,只能说遥遥领先。大家可以看到,在 small 环境,就是刚刚提到的 4 核 16GB 的这个环境下面,因为查询性能分两方面,第一方面是 QPS,这里列出它每秒能达到 11497 次的查询操作,比 VictoriaMetrics 高出了 36%,是 InfluxDB 的 5 倍多,是 QuestDB 的 16 倍多。

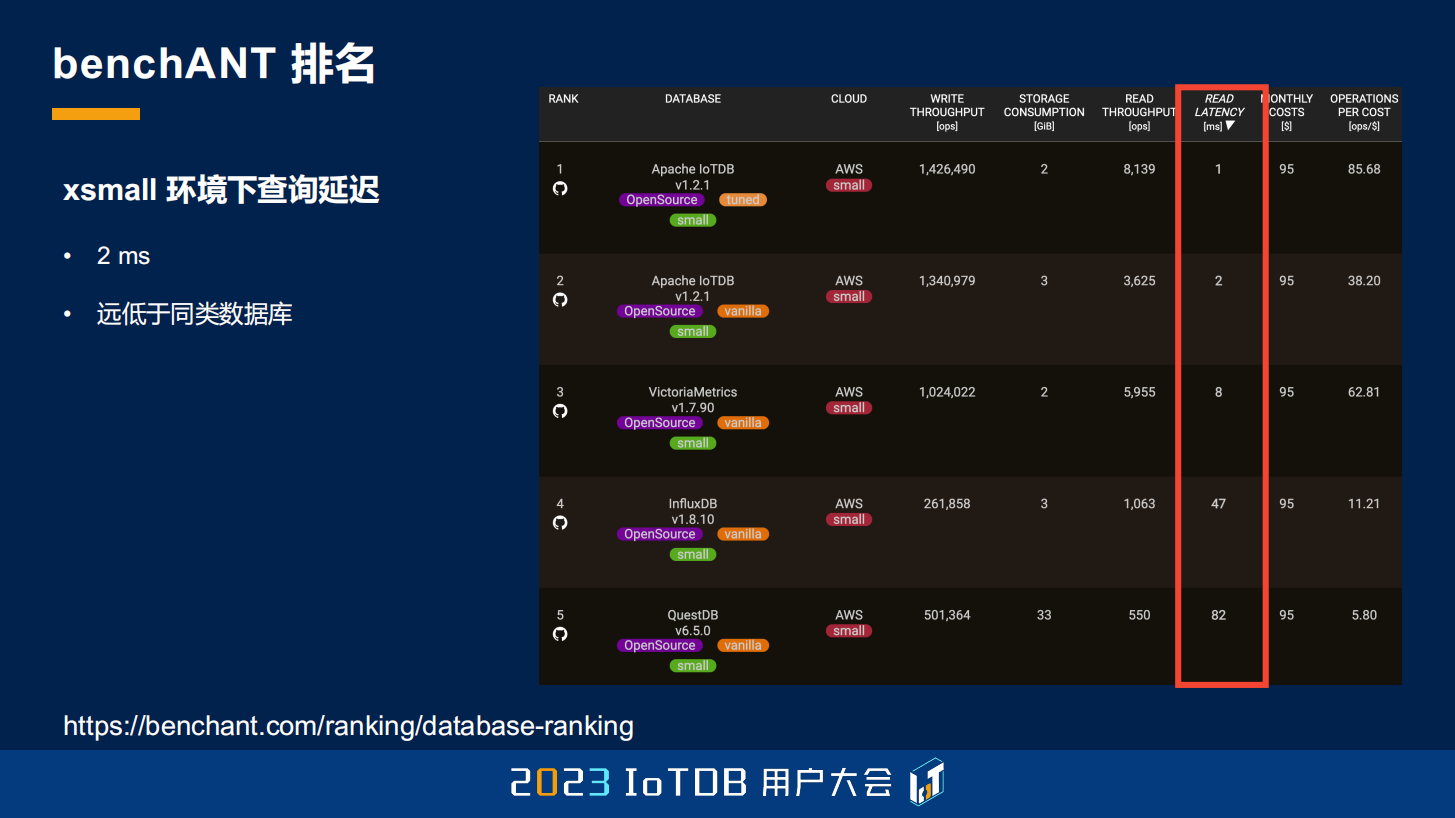
在我们的查询延迟方面,查询延迟也只有 2 到 3 毫秒,也是远低于同类的数据库,大家也可以看到。

下面是 xsmall 环境,也就是刚刚提到的 2 核 8GB 的这样一个环境,其实都跟刚刚类似,IoTDB 也是排名第一,比同类的数据库也高出不少倍。
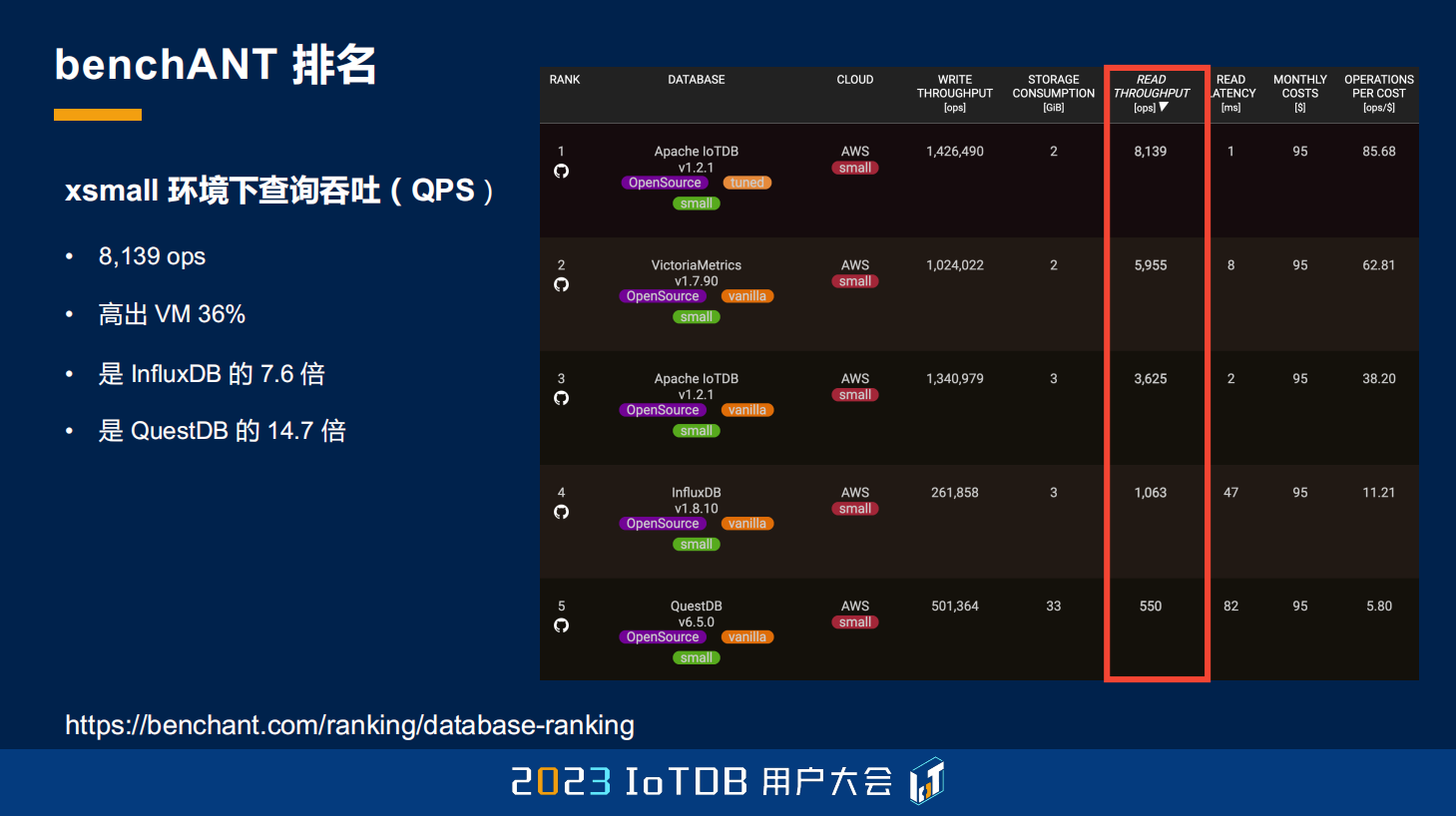
包括它的查询延迟。因为这是一个第三方的机构,大家也可以通过下面这个网址去访问的,在网上也可以看到。
这个比较好的测试结果其实是得益于 IoTDB 强大的查询引擎,它是基于 MPP 的。一条 SQL 过来之后,在 IoTDB 的节点里面,查询的节点角色分为两种:第一种是 Coordinator,它负责去接收用户的 SQL,根据这个 SQL 涉及的数据,然后根据数据分区,把它切分成不同的查询分片,再把它的查询分片发放到不同的 Worker 节点,这是另一个角色,发到 Worker 节点去做真正的执行。
当你有多副本的时候,这样一个架构可以帮你达到一个高可用的效果,因为有节点宕机或者网络分区的时候,我们可以选择把查询分片路由到它的另外一个分片上,也可以根据我们的节点负载去做实时的负载均衡。并且,这个 MPP 天然就可以把查询发到各个节点上去运行,所以它能够充分利用这种多机多核的特性。
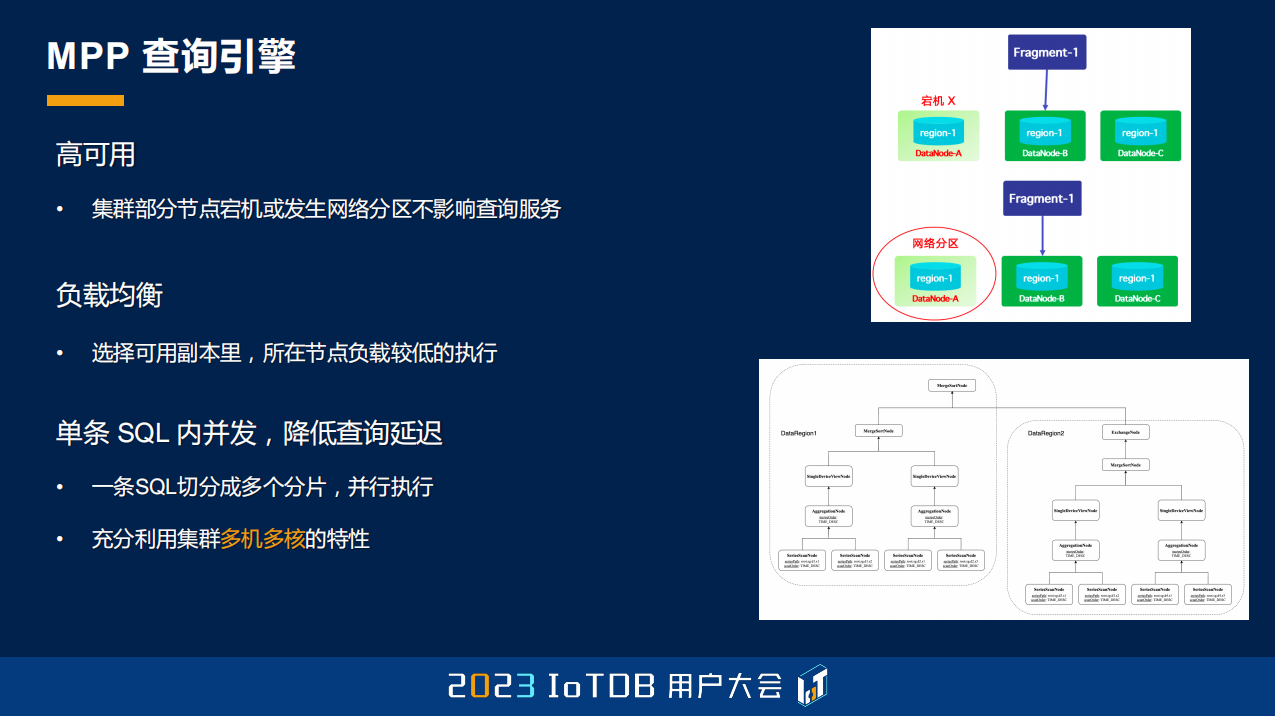
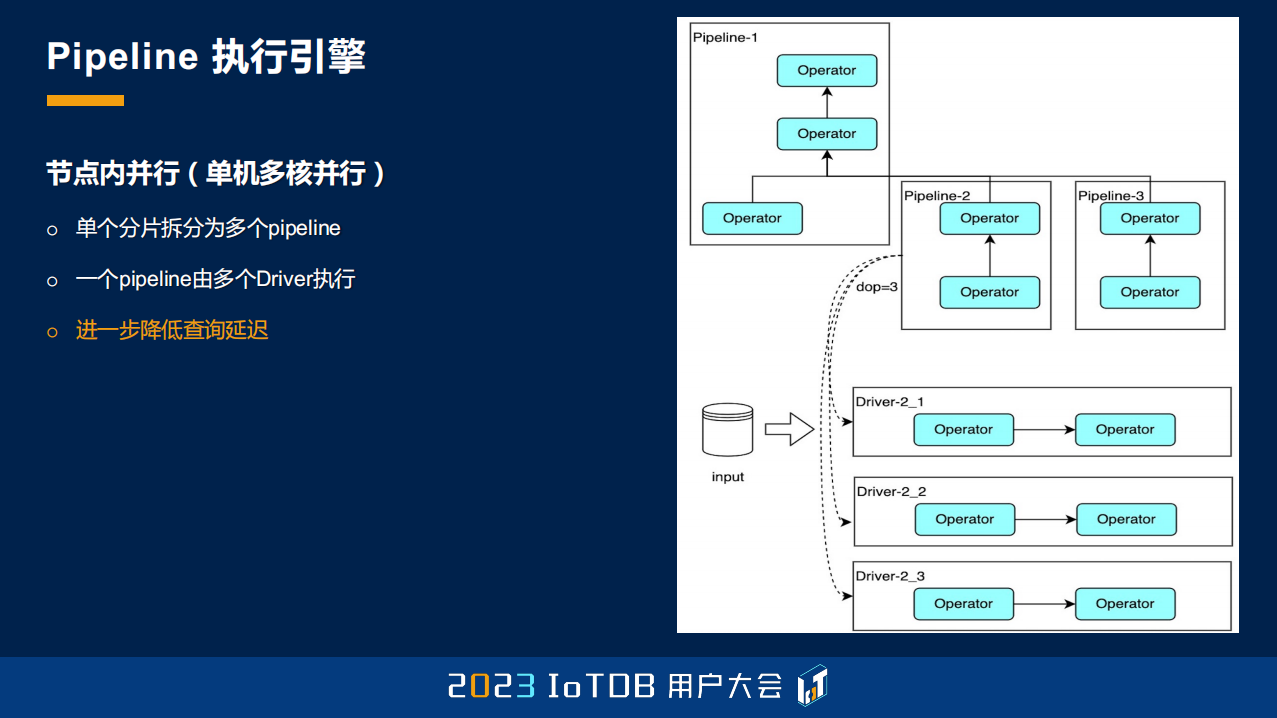
刚刚提到的是查询的切分过程,一个查询被切分之后,刚刚提到,一个单个的查询的分片会被发到一个 Worker 节点上去做执行。那这样一个 Worker 节点上在执行的时候,它还会再进一步地去做切分,进一步地去利用单机多核的特性。
这个切分的时候分两个方面,一方面可能这个算子数还是很庞大,那我还是要在这个算子数上再进行一次切分。切分完了之后,它可能每一个分片,这里的分片是指的 Pipeline,就是已经到单个 Worker 上面了。那每一个 Pipeline 可能涉及很多个数据文件,那很多个数据文件,我们还能把数据文件再分组,这些分组就对应了多个 Driver,每个 Driver 就是真正可以调度的一些 Task,所以能够进一步降低我们的查询延迟。
有了这个查询的分片任务之后,那就需要去调度了。IoTDB 设计查询调度的目标主要有三个:第一个就是因为不同的查询任务可能有不同的优先级,短任务可能有更高的优先级,因为是实时的分析任务,还有一些批量的历史数据查询,它可能涉及的时间范围比较广,它的查询的时间会比较长,那它优先级可能稍微低一些没有关系。当然,我们的长查询不能长时间地给饥饿掉,因为它的实时查询可能不断地再来,我们要保证我们的历史分析查询也能够正确地去完成。第三点就是,引入一个新的调度器之后,你要确保调度器的开销就足够小。

IoTDB 去做设计的时候也是固定了查询的线程数,可能各个数据库都会这么去做,也定制了自己的调度算法,并且也做了一些内存控制,能够去控制查询任务的总内存空间,当超过内存阈值的时候就进行服务降级,去避免突发的查询导致的 OOM。还有就是查询超时,就是一个长的查询任务,可能是一些业务人员不小心去误触发的,那这样的一个查询任务在达到查询超时时间之后,也会被自动的终止掉,去避免这样一个长查询一直占着我们服务器的资源。

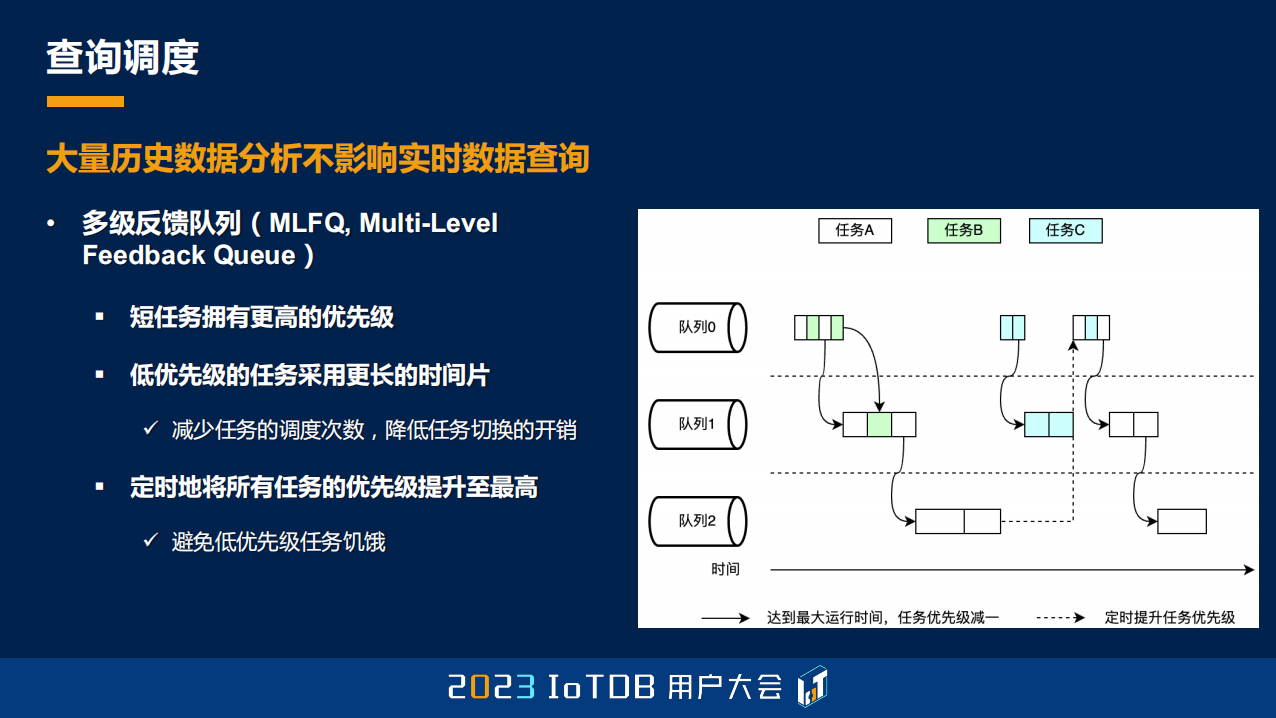
刚刚提到我们定制的,或者说自己去实现的一个调度算法叫多级反馈队列,这个其实也是操作系统里面比较经典的一个调度算法。它能够做到我们刚刚说的几点:第一点就是它的短查询会拥有更高的优先级,因为所有的任务进来的时候,都是被认为它的优先级是最高的。如果你在我给你的时间分片内执行完,那它其实就是一个短任务,永远都在第一级队列里面就执行完了。而当长查询进来的时候,第一个队列的时间分片可能用完之后还没有结束,那我就会把你放到第二级队列里面,那第二级队列里面意味着它的优先级会比较低,调度器尽量会去调度 Level 更低的队列里面的任务。
随着长查询慢慢会被放到最后一级 Level 的队列里面,那我们怎么保证它不会被饥饿呢?因为如果第一级队列一直有实时任务进来的话,其实这个 MLFQ 算法会把所有还存在的这些 Task,定期地去提高到 Level 0,这样的话就能够达到长查询不会被饥饿的效果。
02 具有时序意义的算子
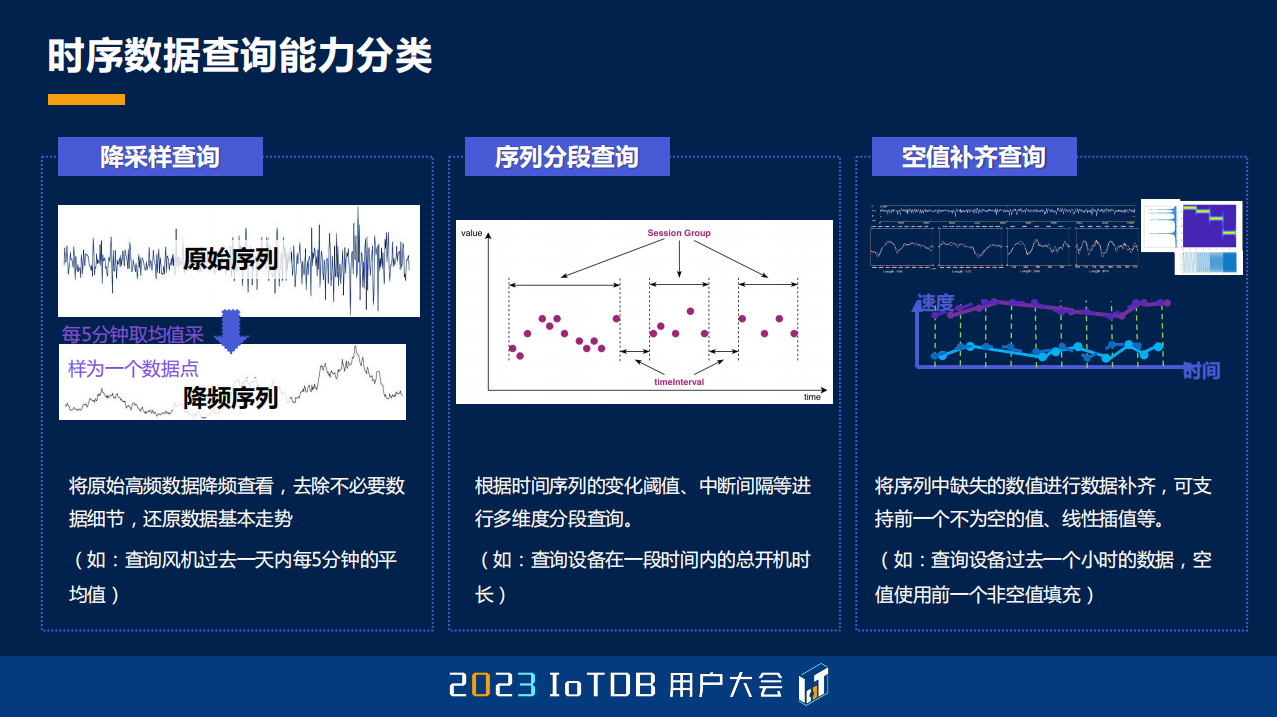
跟大家简单介绍过查询大的框架之后,跟大家去具体的介绍一下有一些时序语义的特色的算子。时序查询能力分类主要分为这几种:第一种,也是比较常见的,就是我们的降采样查询,就是把一段时间的数据的趋势去做出来就行了,因为我们可能并不需要每一个具体的点,每个具体的点画出来的时候,它可能非常不直观。上面这张图,大家也可以看到,如果能够通过降采样,其实只要反映它一定的趋势就行了。
第二点其实就是我们的分段算法,时间序列去做分段。它跟关系型数据库里面的 GROUP BY 很像,但是关系性数据库里面它大部分都是 GROUP BY 某一列,只是根据值去做这个分列,它并没有去做分组,并没有一个顺序的语义,也不会有任何除了值分组之外的一些操作,当然它会有一些 Window Function ,那后面我也会提到。
第三点就是在时序场景里面也会非常常见的,就是我们的空值补齐查询。
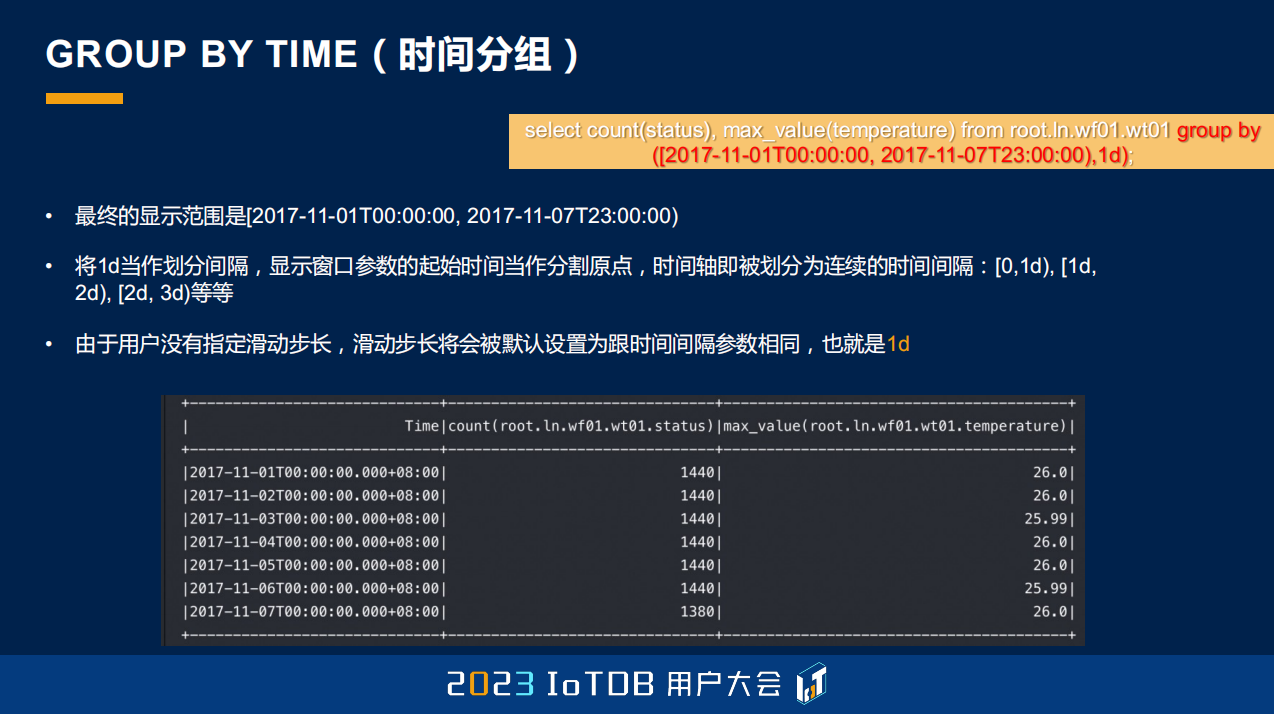
这个就是刚刚提到的,在 IoTDB 里面会去通过 GROUP BY TIME 这样一个时间分组的功能,去实现我们的聚合降采样的功能。这个可能大家会比较熟悉,它有三个参数,当然第三个参数是一个 Optional 可选的。第一个参数就是指定我们查询的整个时间窗口,第二个参数是指定我们聚合的,也就是降采样的窗口大小。

通过一个例子大家可以看到,这个例子是去做了 11 月 1 号到 11 月 7 号这七天,每一天我需要按天去做降采样,就是这么简单的一个 SQL,可以看到它会得出来每一天的最大值,还有它的每一天的行数。
刚刚是没有用到第三个参数,那如果用到第三个参数,它能做到什么呢?它能够做到我还是按每一天去对这个数据做降采样,但是我可能并不需要这一整天的数据,我可能只需要每天凌晨 0 点到凌晨 3 点的数据,那就可以通过第三个参数,这样一个滑动步长的方式去解决。
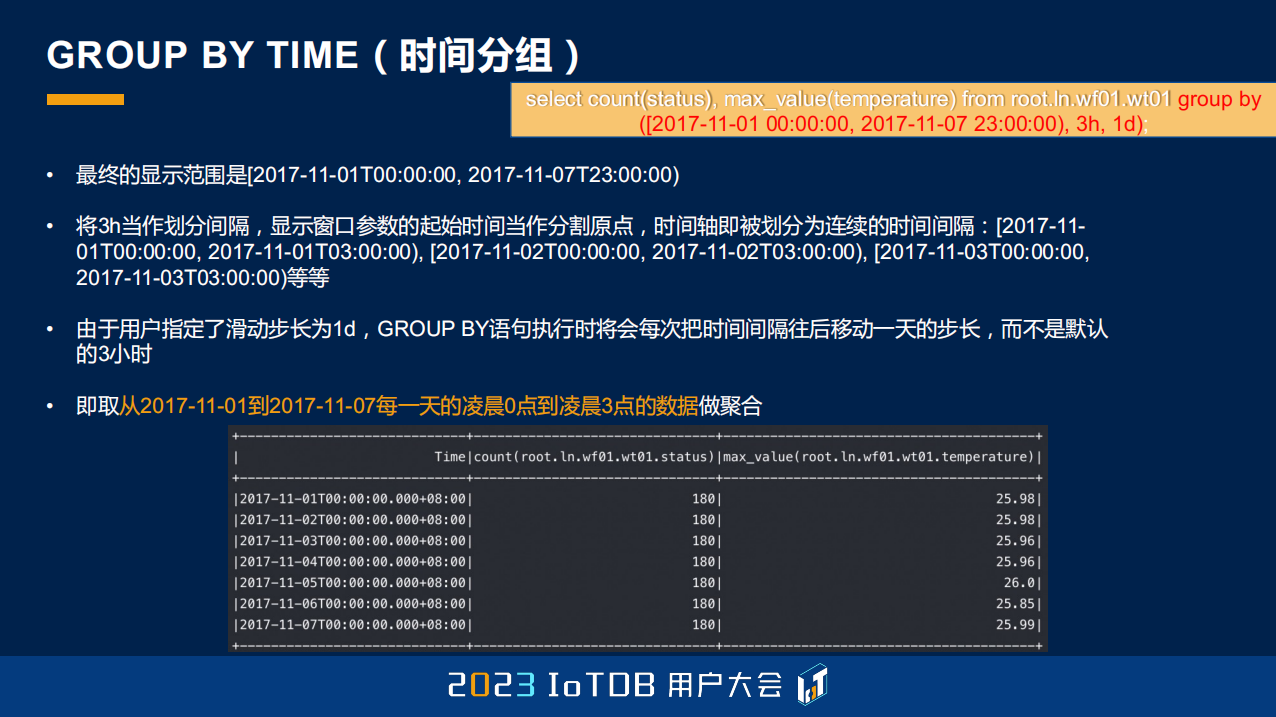
除了刚刚说到的,也有一个大家可能不太会注意到的方式。我们的 GROUP BY TIME 其实是支持两种方式的,是通过左开右闭,和左闭右开的这种方式去做到。大家可能用第一种方式,左闭右开比较多,左闭右开的话,它可能包含 0,但不包含 9,当有 0、1、2、3、4、5、6、7、8 这九个点的时候,它做完分组之后,第一个分组包含 0、1、2,第二个就包含 3、4、5,第三个就包含 6、7、8。因为 IoTDB 每一个结果集都会有一列 Time,它显示的时候也是用的起始时间,也就是我们的左端点去展示的。
但如果是左开右闭的话,那就是 0 不包含,它包含的时间点是 1 到 9。分组同样的也会做改变:1、2、3;然后 4、5、6,然后 7、8、9。它做 Time 列的展示的时候,是会用右端点进行展示的,这里是 3、6、9。
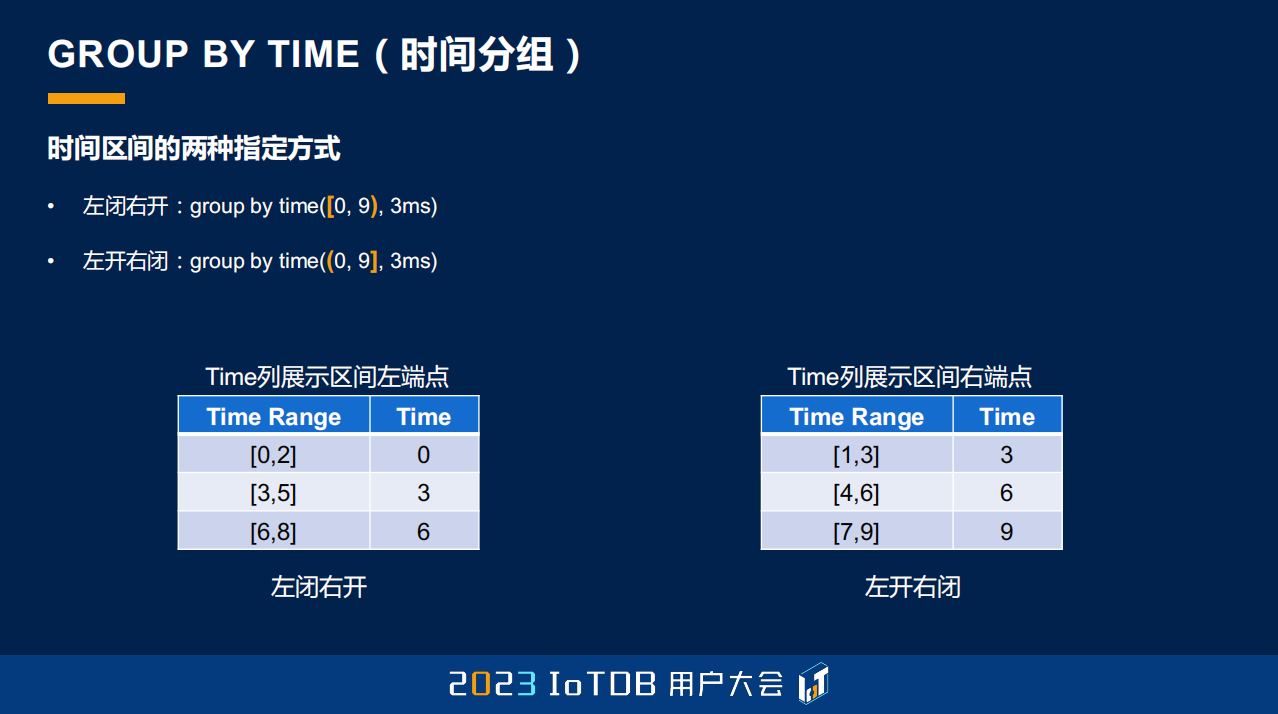
降采样跟大家提了一下,第二个就是刚刚我们说的分段的方式。这边提到了一个定义叫差值分组,它是什么意思呢?就是它会根据所有的时间序列的值,跟这个组的第一个的差值去做分段。如果这个差值超过我们所设定的阈值了,那它就不属于这个分组,它就属于下一个分组了。从这张图大家可以很容易的看出来,第一个值规定了这样分组的一个区间,后面的值如果超过它比较多,那就明显不属于这个组了,它就会属于下一个组。
这也是一个实际的例子。如果我们以 s1 这个序列去做分段,0.1 就是我们设定的阈值,从 0.9 跳到 1.2,差值已经是 0.3 了,所以它属于下一个分组了。

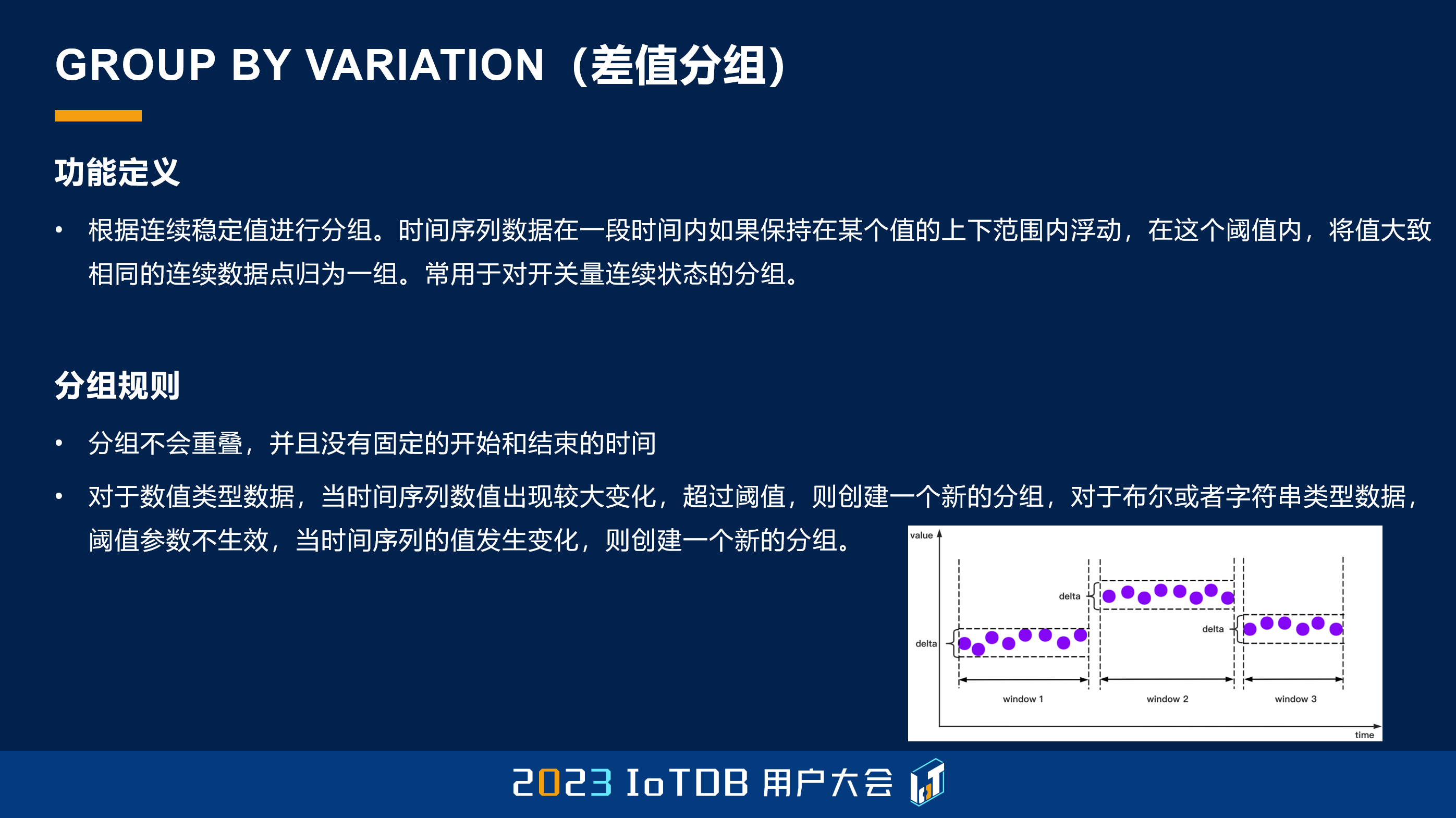
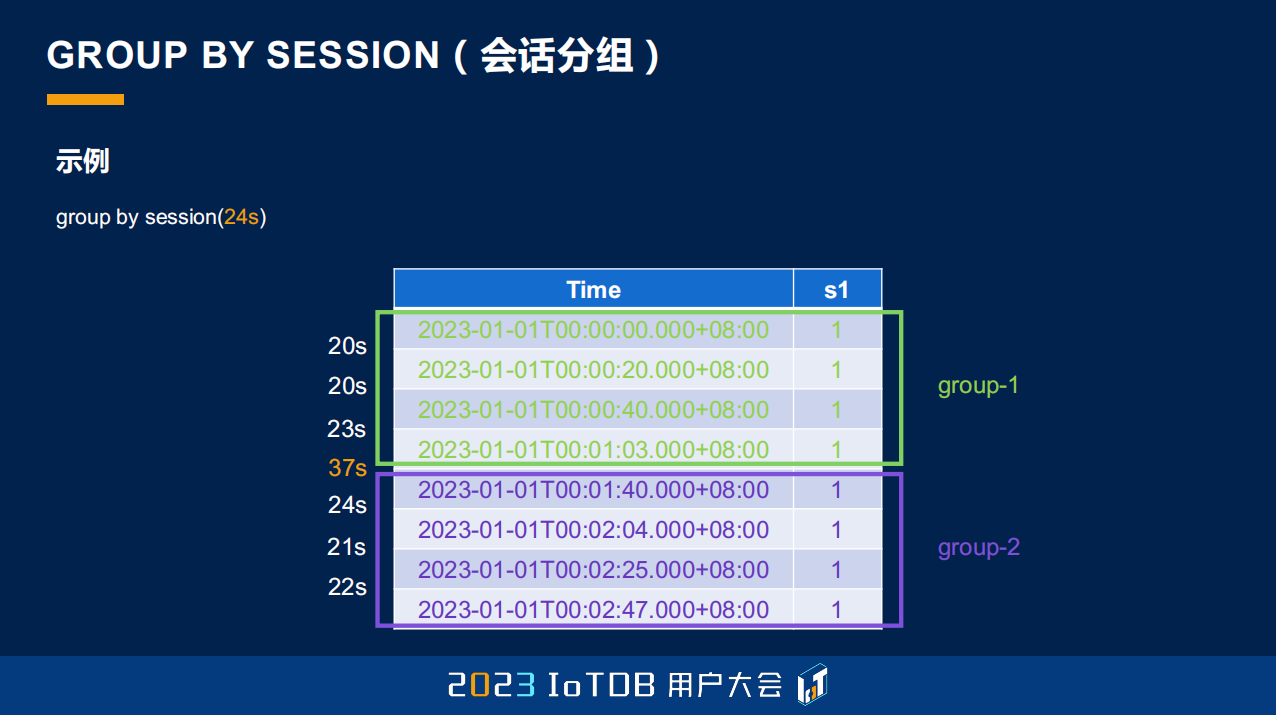
这个 GROUP BY SESSION 也是在时序场景里面可能比较常见的,它叫会话分组。会话分组和刚刚不一样的地方在于,它是对时间列去做分组操作的。比如说一台机械,它可能并不是时时刻刻都是开机的,我想要它每一次开机的平均值。它的状态可能一直是 1,就是它一直是开机的,你能看到数据,但是我要对它每一段开机做一个分段,那其实就是根据我们当前的这个时间点,它跟上一个时间点的间隔,如果超过了我们设定的阈值,我们就认为它中间可能发生了一些问题,或者发生过关机,那我们就可以把它认为是下一次开机时的状态。这个其实也是比较常见的,我们是可以通过 GROUP BY SESSION 这样一种方式去指定的。
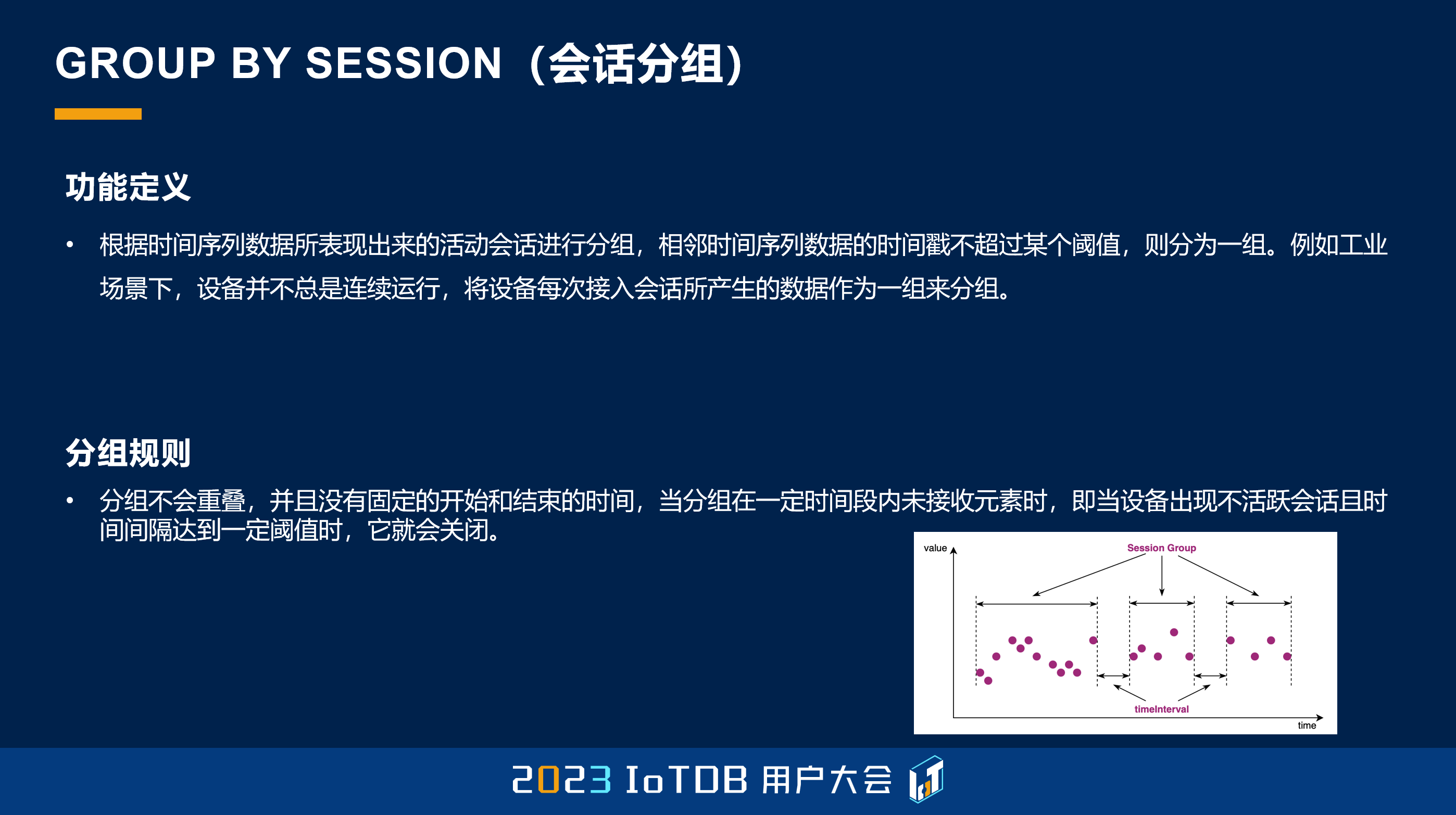
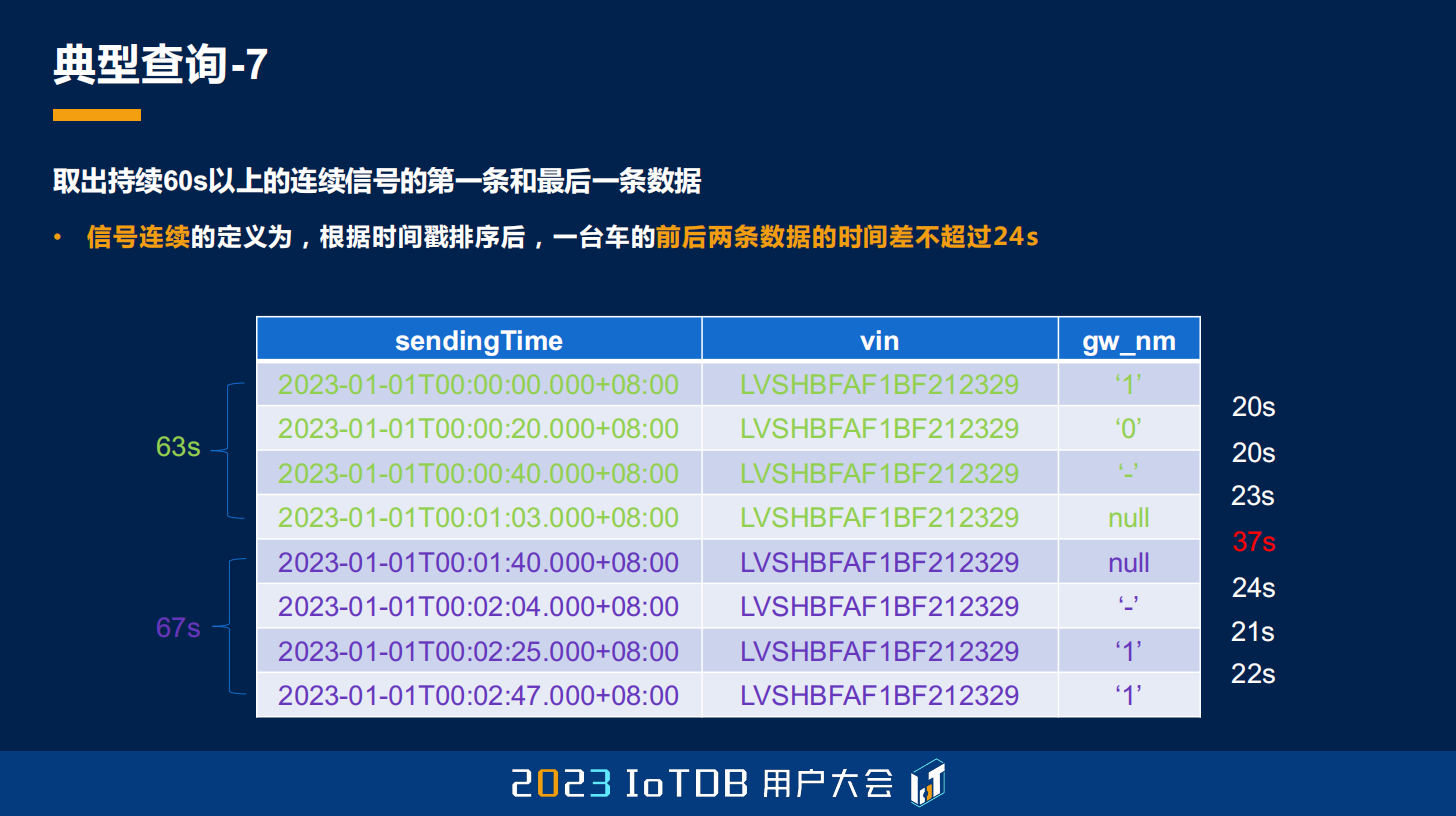
这边给了一个例子,比如说我们设定的阈值是 24 秒,这里第 4 行到第 5 行的时候,它的跨度超过了 24 秒,达到了 37 秒,那我们就把它自然而然地放到了下一个分组。
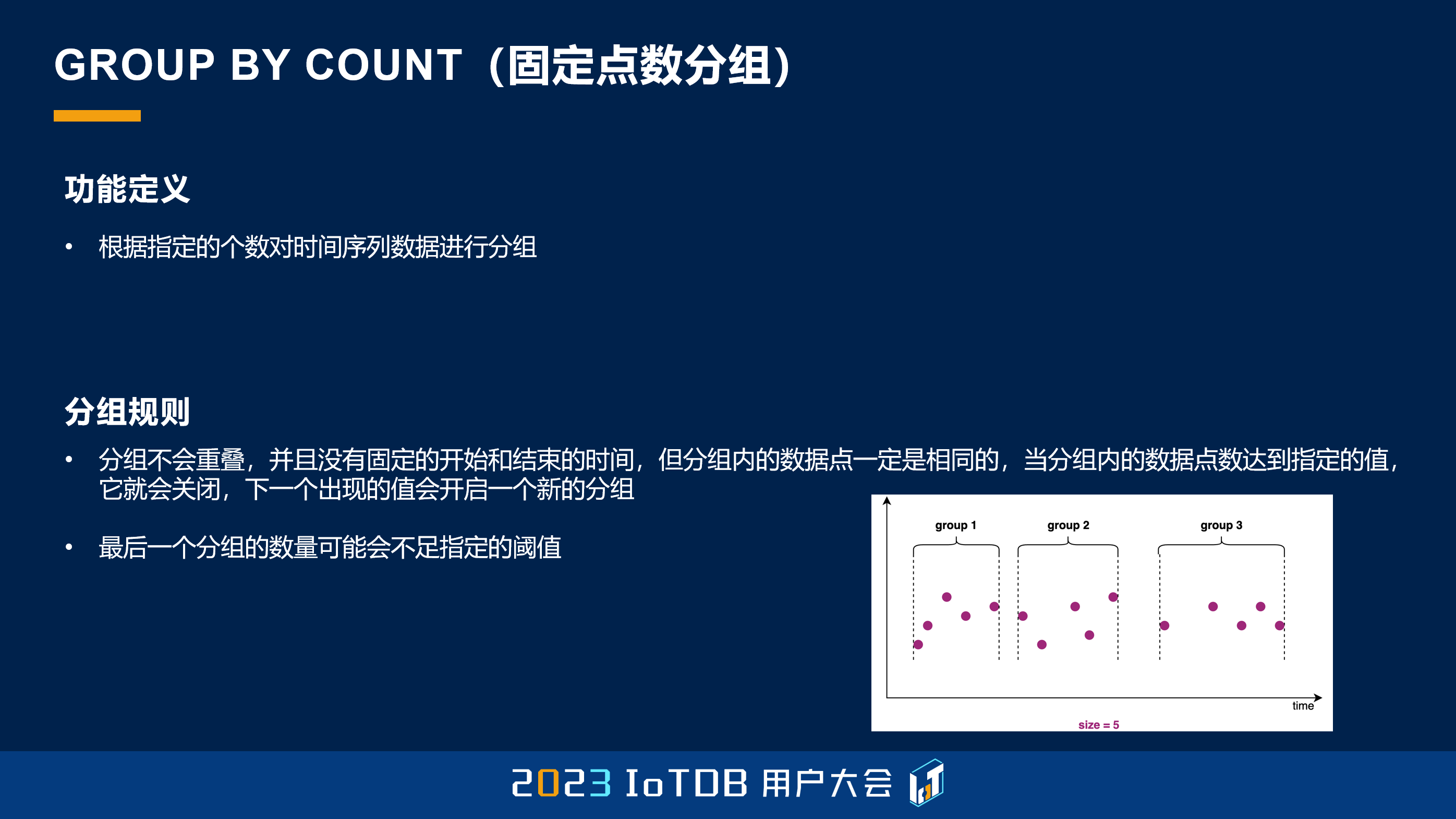
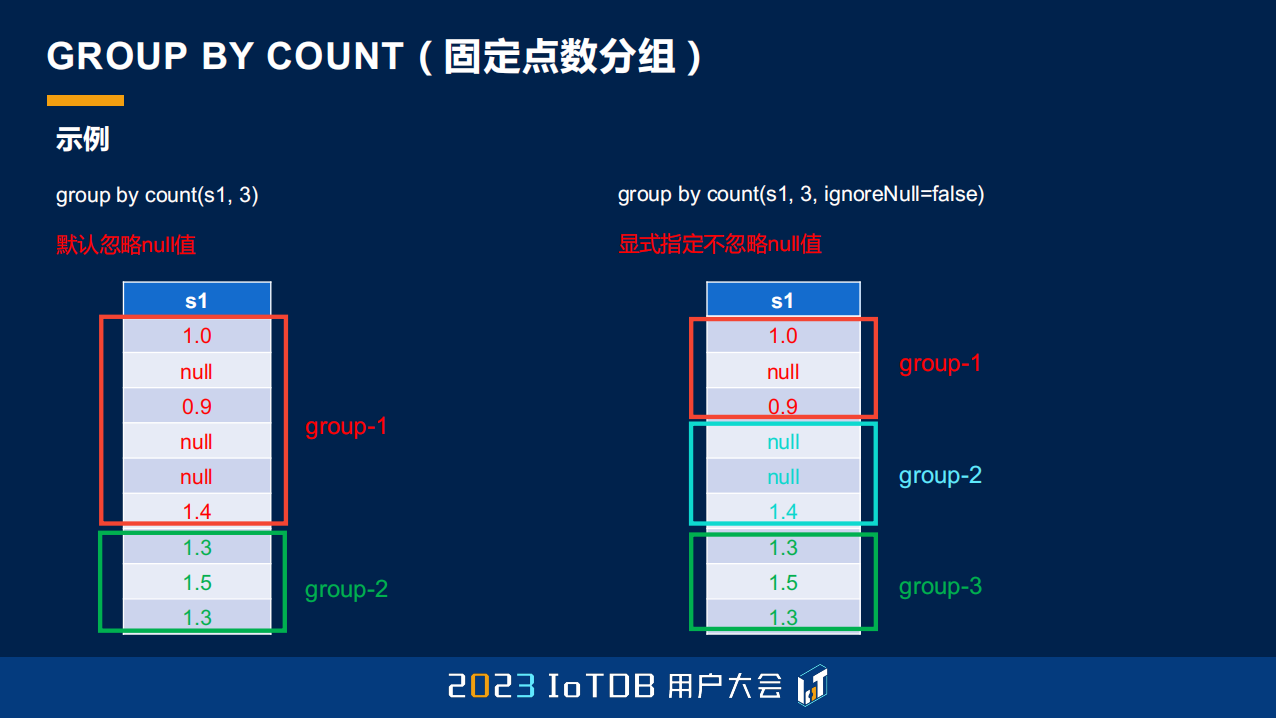
GROUP BY COUNT 这个函数很简单,跟大家快速过一下,它就是按照固定的点数分组,比如说每 5 个点分一个组。
这里也提到,因为有一些 null 值,我们还有一些参数可以支持指定忽不忽略 null 值。
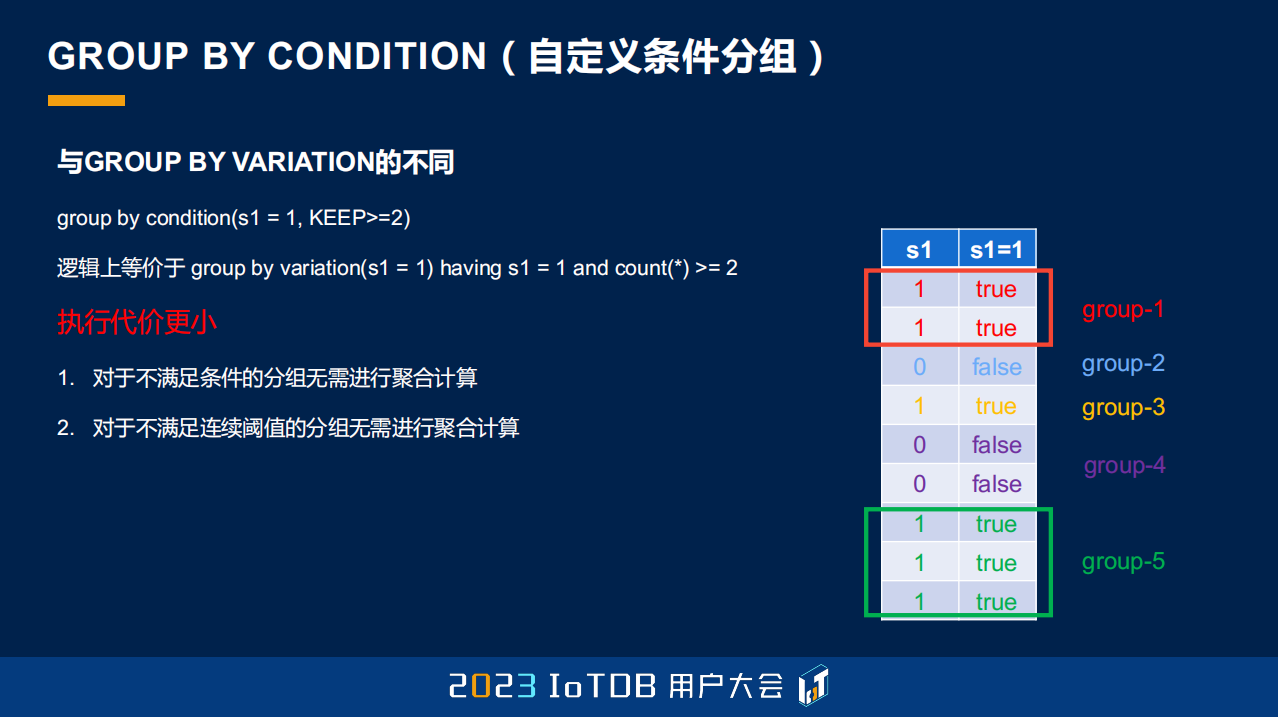
GROUP BY CONDITION 这个稍微有一些复杂,它其实可以让用户自定义一个分组条件,它的分组条件是通过 Expression 去指定的,如果计算出来的 Expression 是 true,也就是说满足我们的自定义条件,那我们就把它保留下来,那些不满足过滤条件的值可能就自动被过滤掉了,它不会放到我们的分组里面。

并且因为时序有天然的连续性,它还通过第二个参数去指定了我们连续满足多少的时候,它才会被认定为我们需要选定的分组。
这里大家可以看到,我们指定 s1=1,并且它要连续超过两个 s1=1 为 true 的时候,我们才保留它。可以看到这里只有两个 group,即使第四行它得出来是 true,但是它连续的行数只有一个,所以它并不会被摘出来,所以我们得到的分组只有 group-1 跟 group-2。

其实刚才这个查询也可以用 GROUP BY VARIATION 去实现,无非就是多一个 having,having 后面可能加一个 count(*)>=2,那它相比而言有什么好处呢?第一是它更加灵活,它支持很多这种自定义的条件,并且它的执行代价更小,因为我们不会对于不满足分组的这些数据做聚合计算。我们如果用这种 GROUP BY VARIATION 的话,它其实是一开始得到很多很多的分组,那这些分组它也会做聚合计算,只不过最后在 having 的时候被过滤掉了。
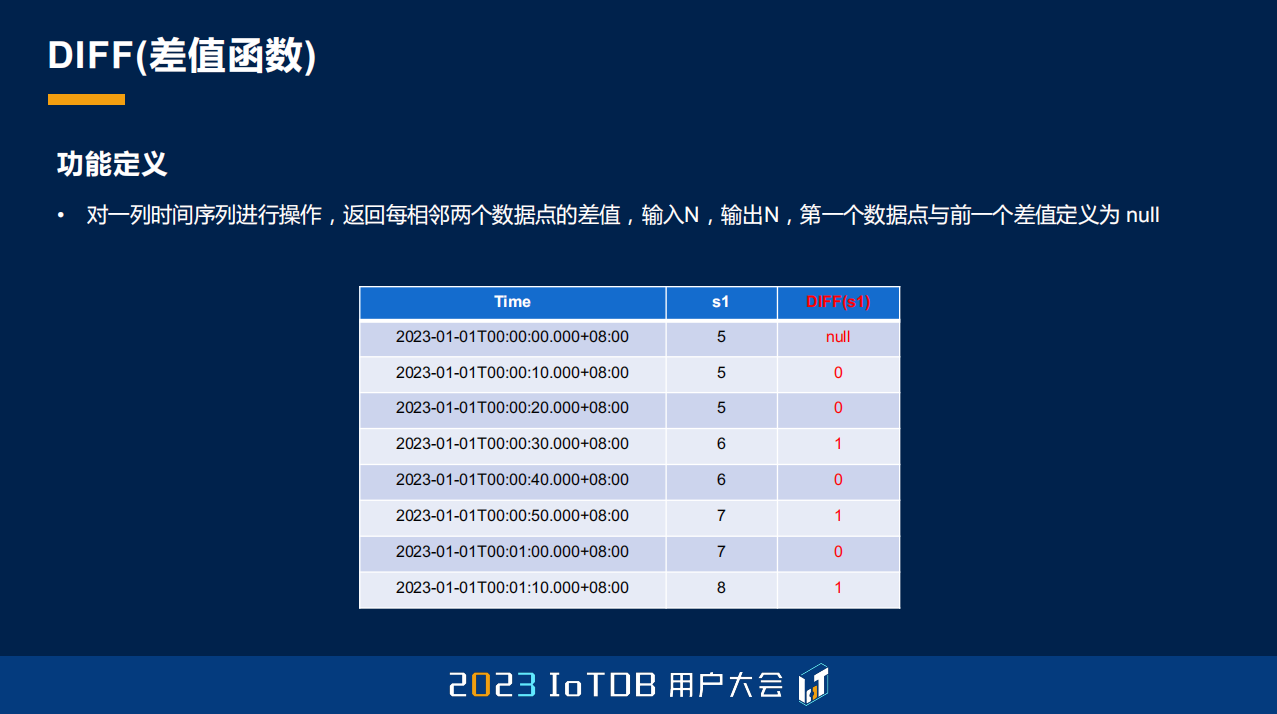
刚刚讲的都是我们分段、分组的一些方式,那这边其实讲了一个我们的标量函数,叫差值函数。这个也是在时序场景很常见,就是我们要求当前值跟上一个值的差值,这个在后面的一些例子里面我也会提到,这里给大家已经展示了一下,比如说 5-5=0。
还有就是刚刚提到,最后的空值填充的功能,我们除了能够支持 PREVIOUS 填充之外,还能支持线性填充、常量填充等等,并且在前值填充的过程当中,我们还支持指定第二个参数,这个第二参数是什么意思呢?就是我们不是无脑地直接用前一个值去填充的,如果前一个真实的值跟当前的时间戳已经超过了我们指定的一个时间范围,比如说 2 分钟,我就认为它并不是一个有效值了,不需要去填充,我就继续保持 null 就行了,所以在这一块我们也可以支持指定第二个参数。

这是刚刚提到了,有三种填充方式。

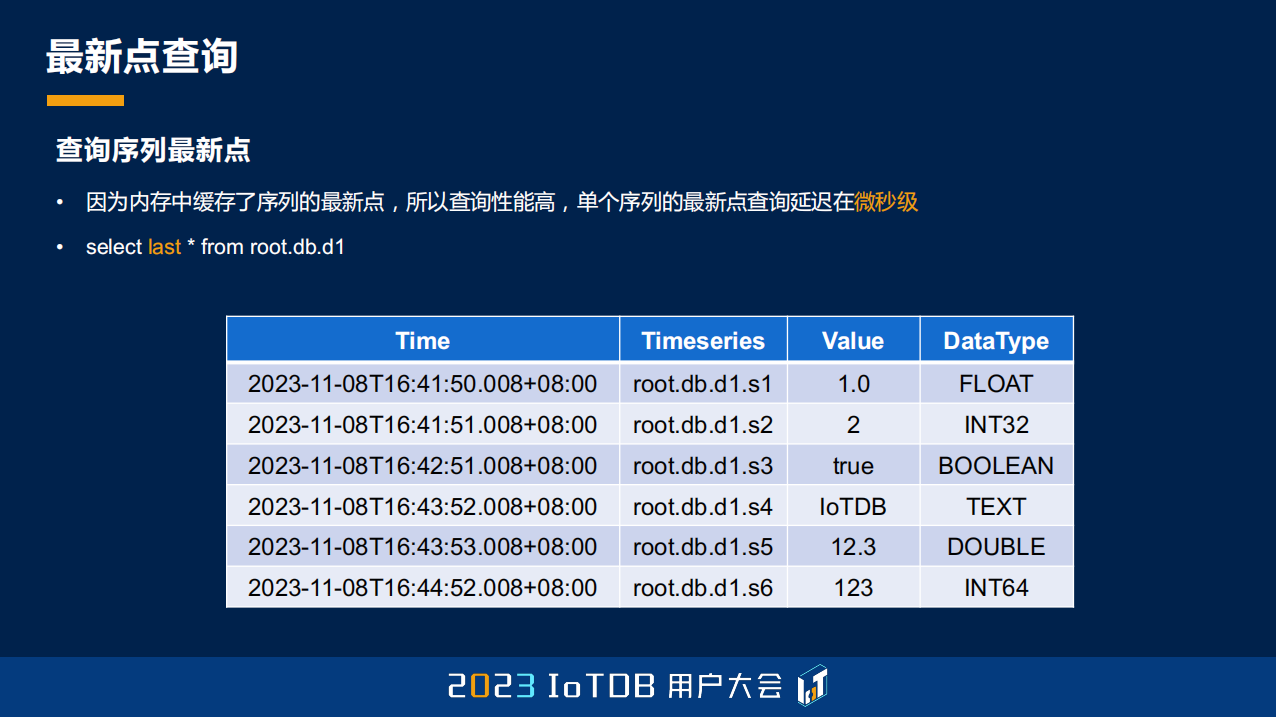
除了刚刚说到的,我们还支持最新点查询。最新点查询的语法有一点特殊,只有这种语法去做的时候,它可以去命中我们的缓存,单个序列的最新点的查询,它的延迟能够达到微秒级别。
03 UDF 函数库
第三个部分是我们的 UDF 函数库的部分,主要跟大家介绍我们实用的一些 UDF。我刚刚提到宋老师组在做的 UDF 函数库,我们现在一共有 59 个通用的函数,它包含数据质量函数、数据画像函数、异常检测、频域分析,还有数据匹配、数据修复、序列发现,包括我们今天早上提到的机器学习的一些函数。

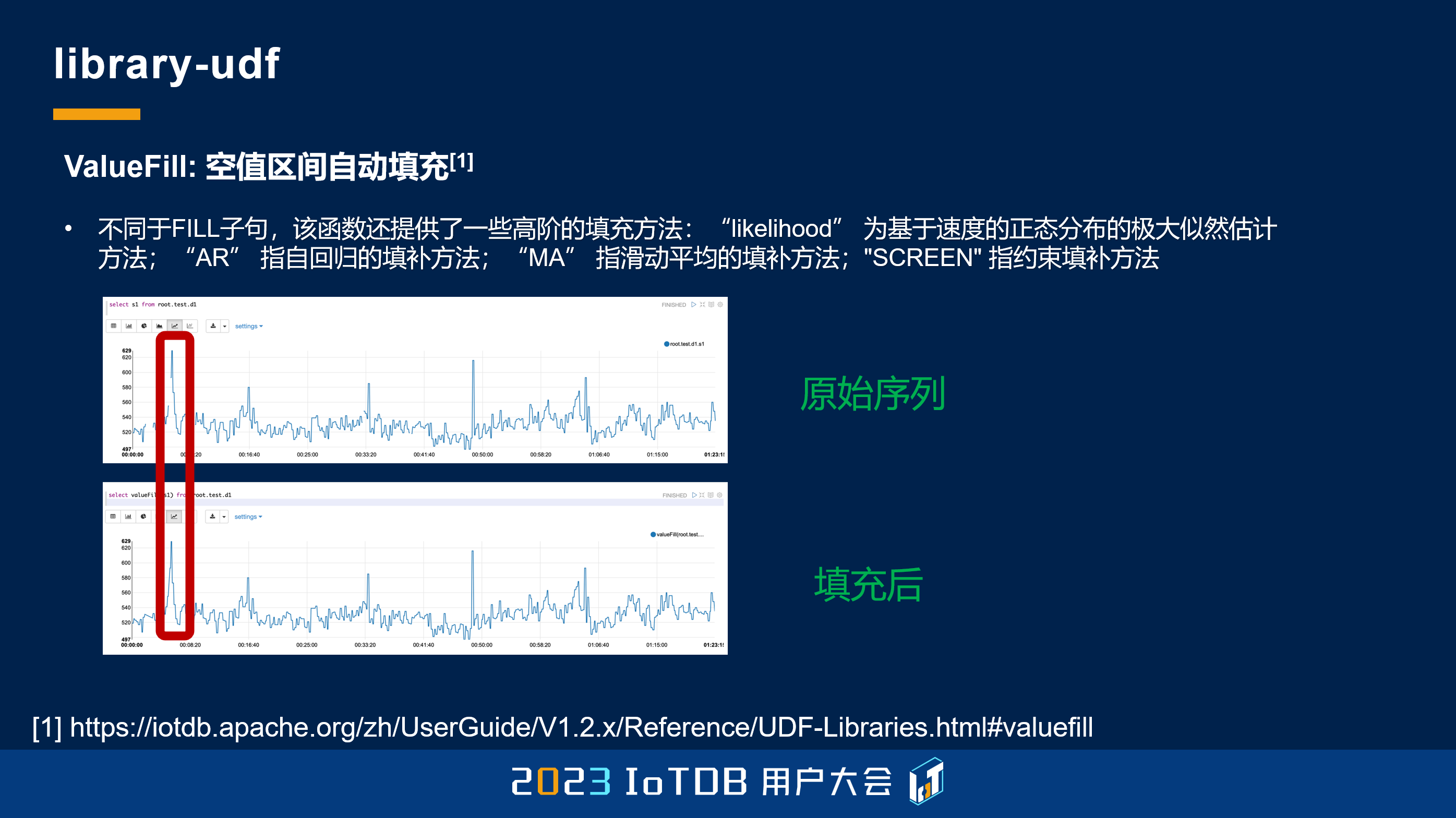
这里给大家举几个例子,比如说 ValueFill,这个其实跟刚刚的 FILL 很像,中间断了一个我们可以给你自动的填充项。
还有就是我们的异常值修复,目前是支持两种修复方式。这里可以看到,它可能有一些异常值会非常影响你的展示,上面这个图中间这些数据趋势都是平的了,但是其实把这些异常点给去掉之后,或者说修复之后,它展示出来的真正的趋势应该是下面这个图。这个还是在工业场景里面比较常用的 UDF 函数。

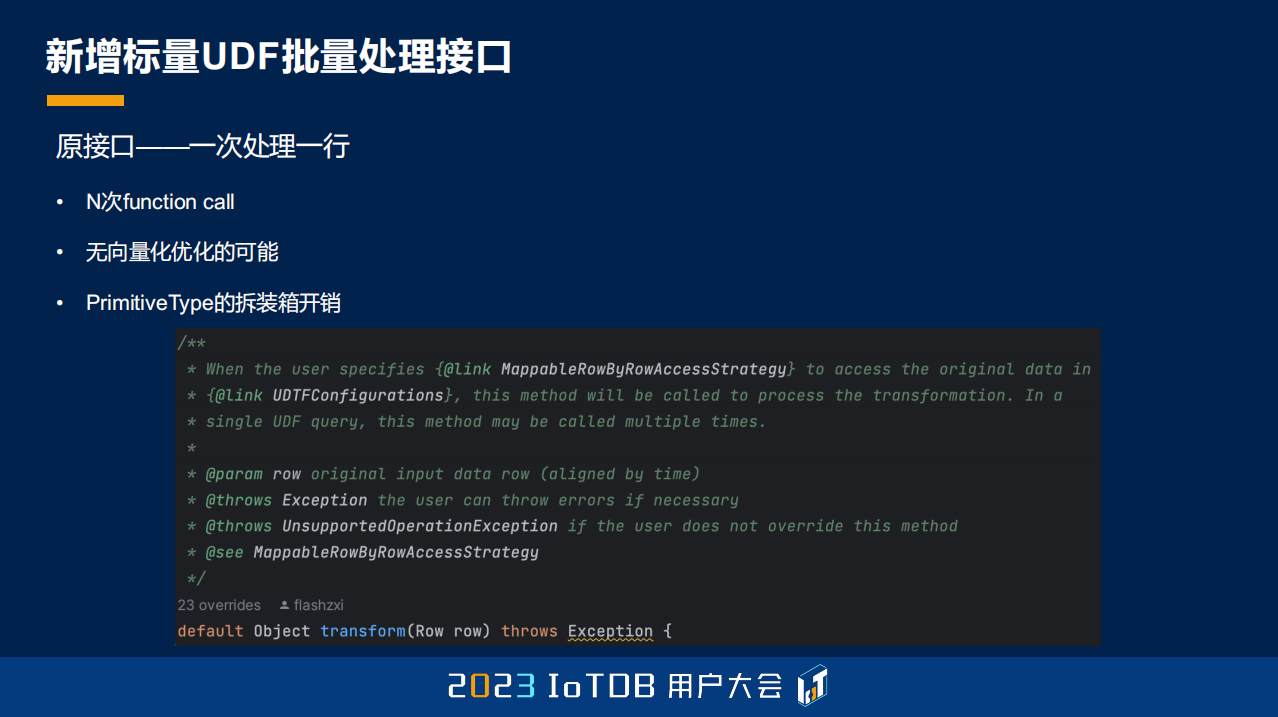
我们原来只支持行式的、迭代式的接口,在 1.3.0 版本里面,我们也支持了这种批量处理的接口,原来是一次处理一行,有 N 次的 function call,并且没有向量化优化的空间,因为我们知道 JDK 越往后发展,可能也会有一些 SIMD 的一些接口,现在在最新 JDK 版本里已经有了,但还是预览版。
那我们新的接口一次能够处理一批数据,对于一批数据只有一次 function call,并且有向量优化的可能,没有任何拆装箱的开销。
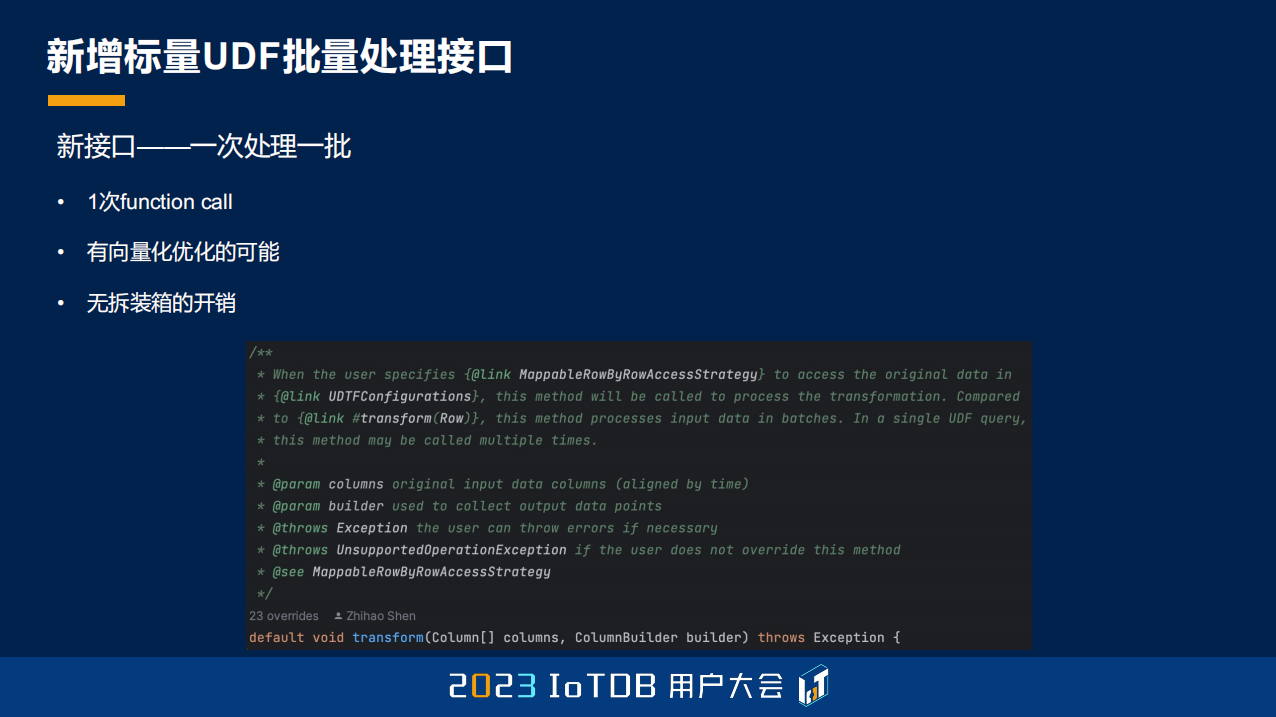
这里列了一下,我们原来用的是比较简单的加法去实现,这是原来的接口。
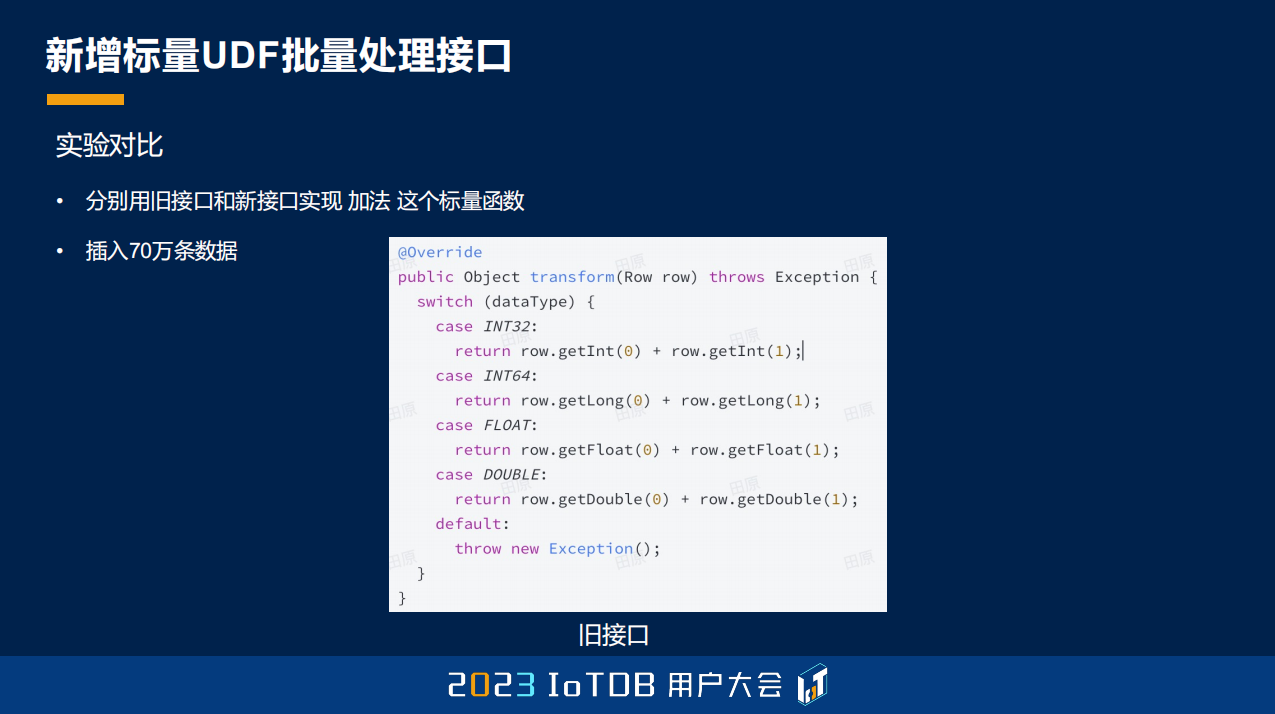
这是现在的实现接口的方式。

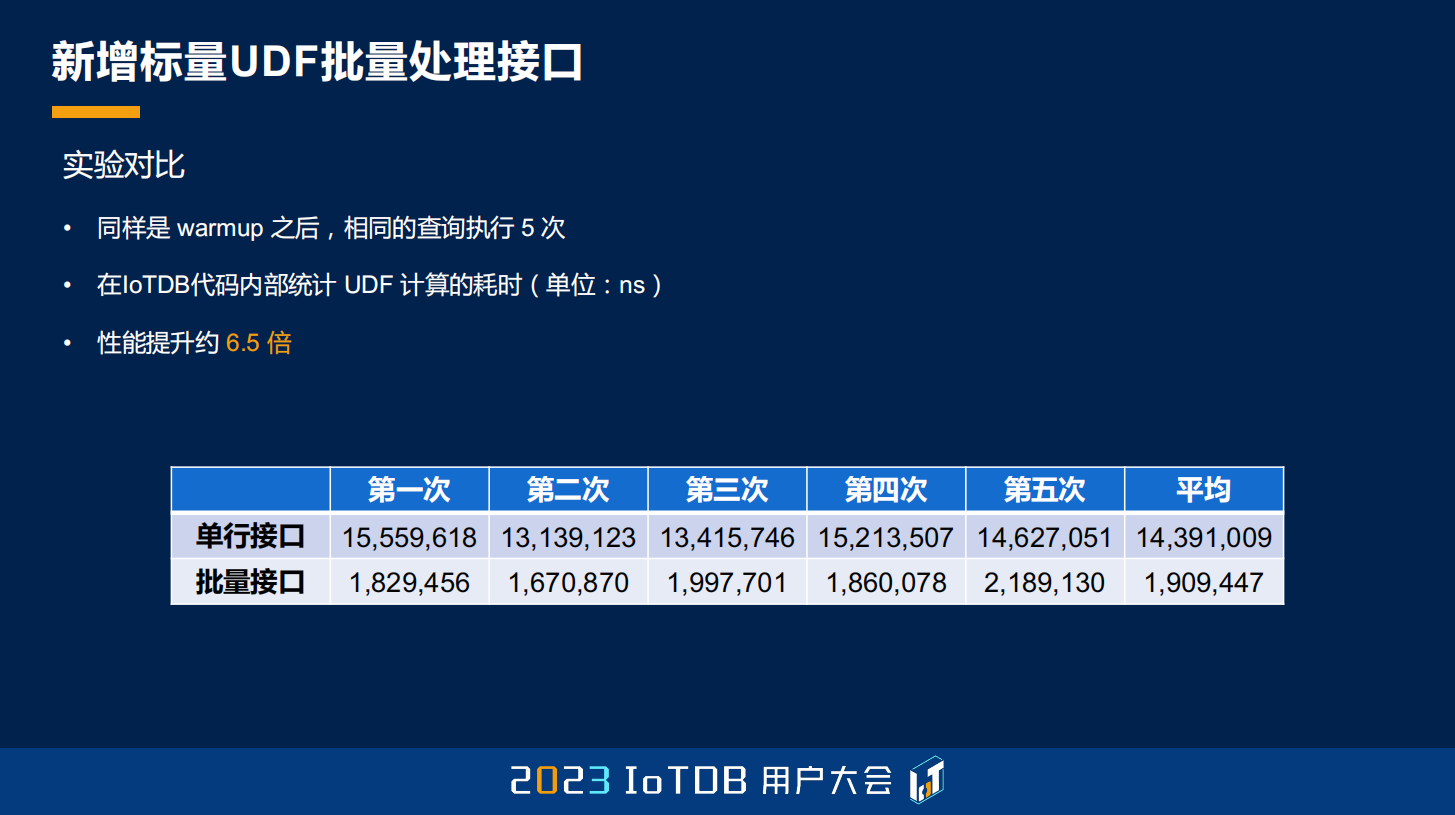
结果是差距比较大的,如果我们用批量接口的话,性能能够提升大约 6.5 倍。大家也可以试着把自己的一些旧的 UDF Function 更新成用现在的批量接口去实现,IoTDB 现在的函数库里面,如果是能够用这种优化去做的,我们都已经做了,大家也可以替换一下新的版本。
04 典型查询场景示例
第四个部分,也是今天会重点跟大家介绍的,一些典型的查询场景的实例。
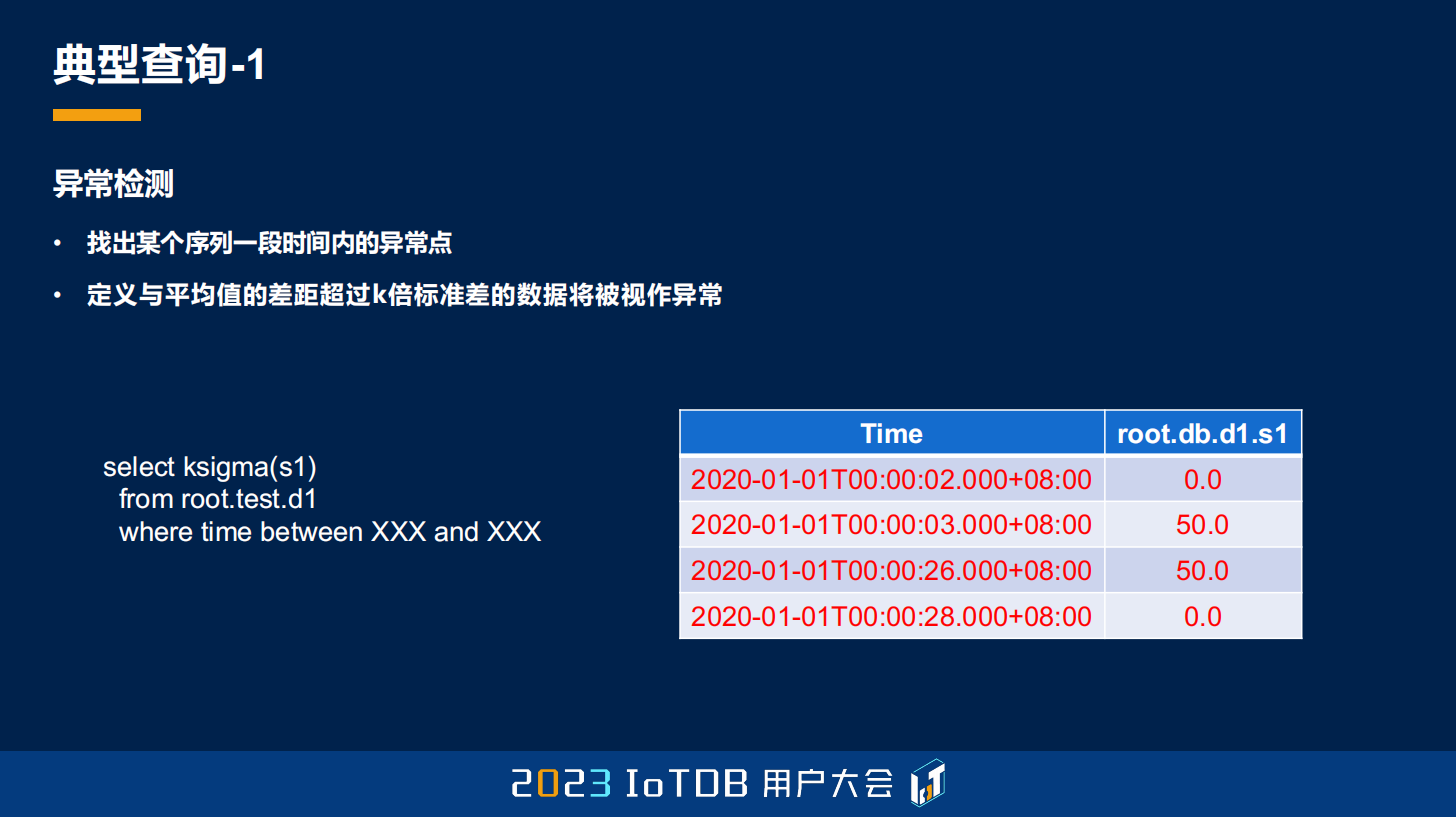
第一个,刚刚其实也跟大家稍微提到一下,就是一些 UDF,它能够做异常检测,异常检测是什么意思?就是它可能是一个序列里面,我们要找出异常的点,但对异常的这个点,每个人的定义方式可能是不一样的。比如说这里,我定义异常的方式就是平均值的差距,超过我们 k 倍的标准差的数据的时候,我们会将它视为异常数据。右边这个表里面也给大家展示了,我标红的是会被选出来的异常数据。
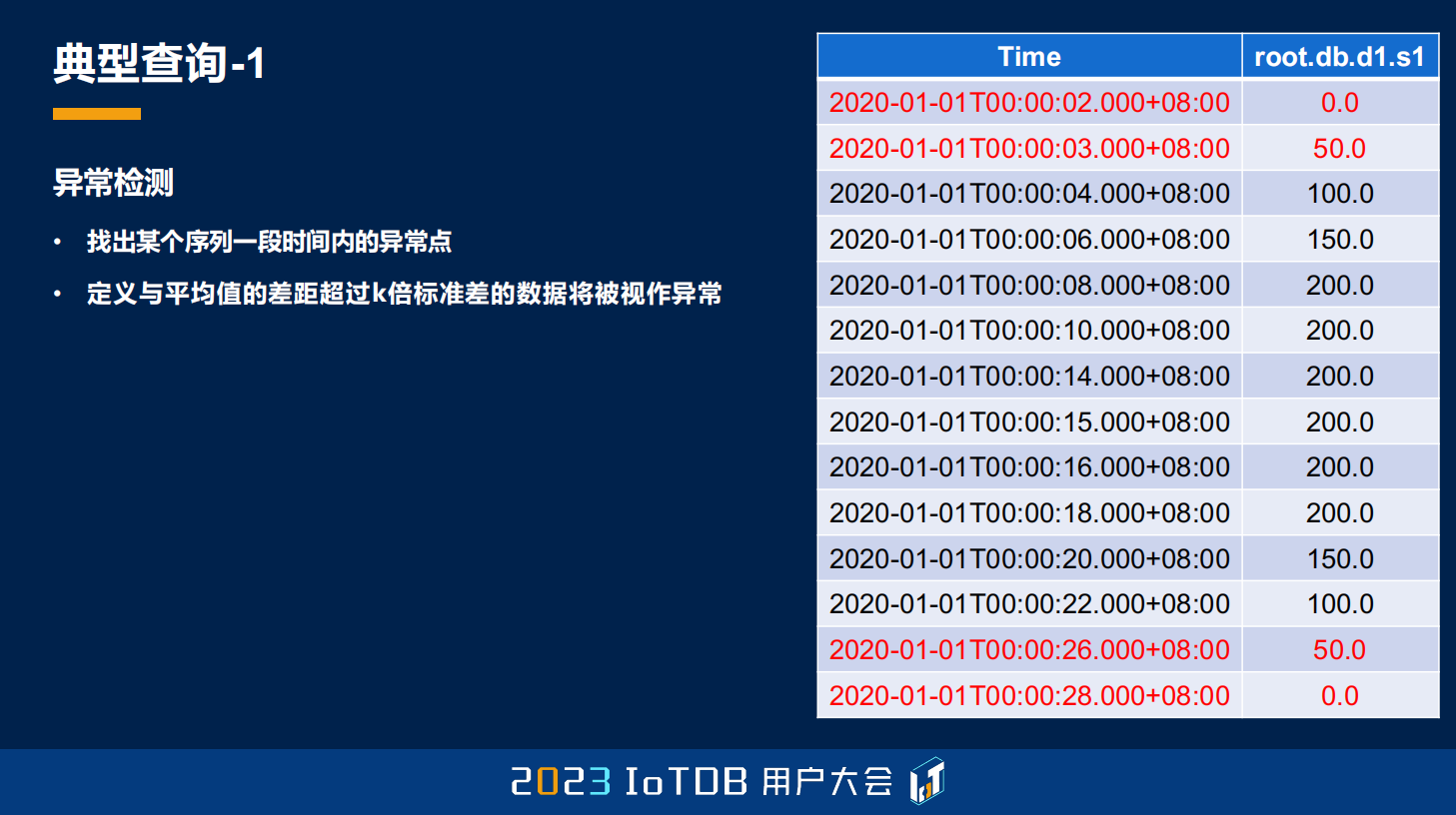
那在 IoTDB 里面你可能不需要自己去实现这种 UDF 了,因为天然有这样一个 ksigma 的函数,你直接去调用,指定这个 k 倍的 k 就够了,它就能自动帮你去筛选出来了。
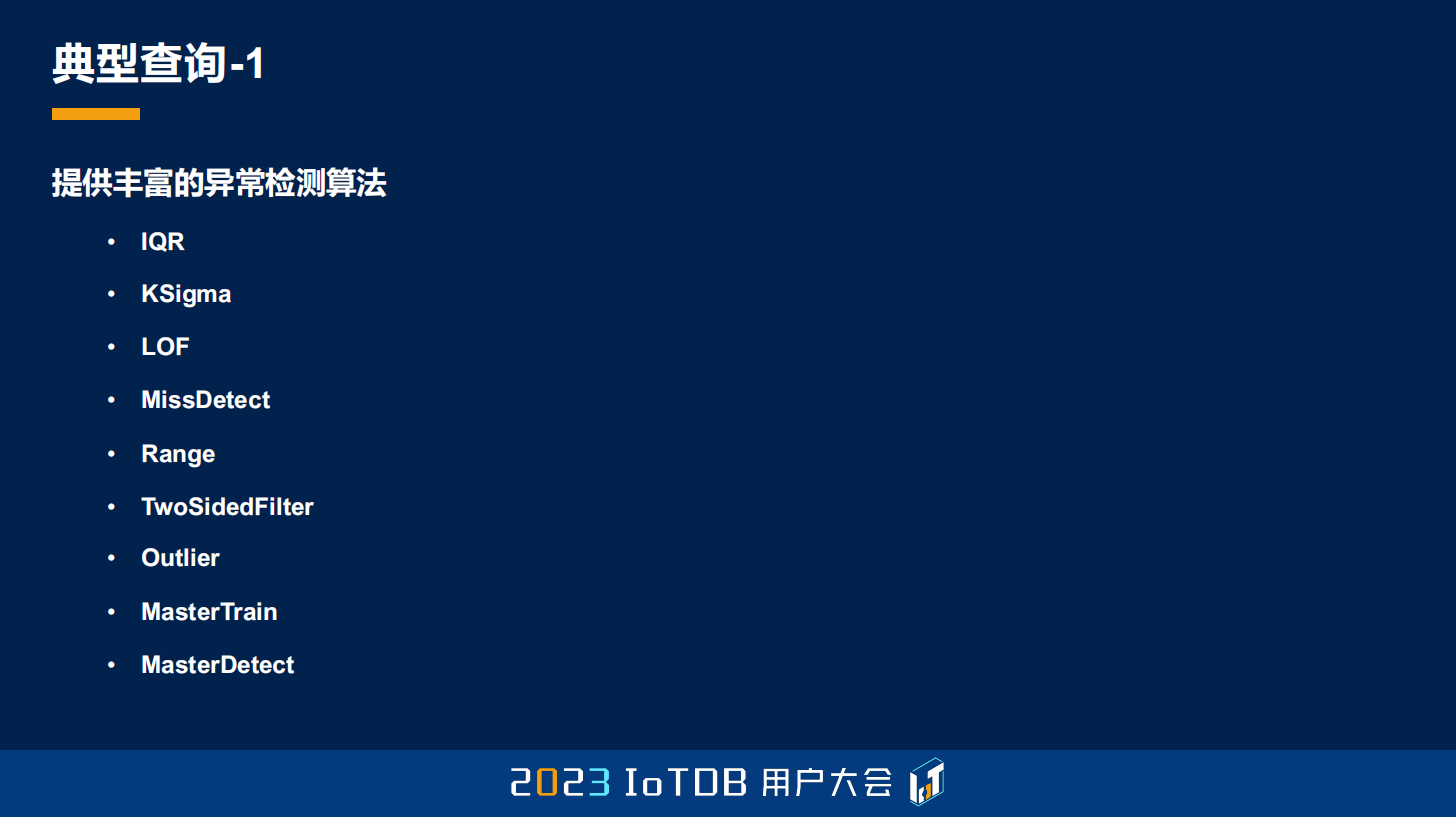
除了刚刚说的这个 ksigma 之外,还支持 IQR、LOF、MissDetect、Range、TwoSidedFilter、Outlier、MasterTrain,或者 MasterDetect 等等,总共是八种的异常检测算法,当然这个异常检测算法也在不断地补充。
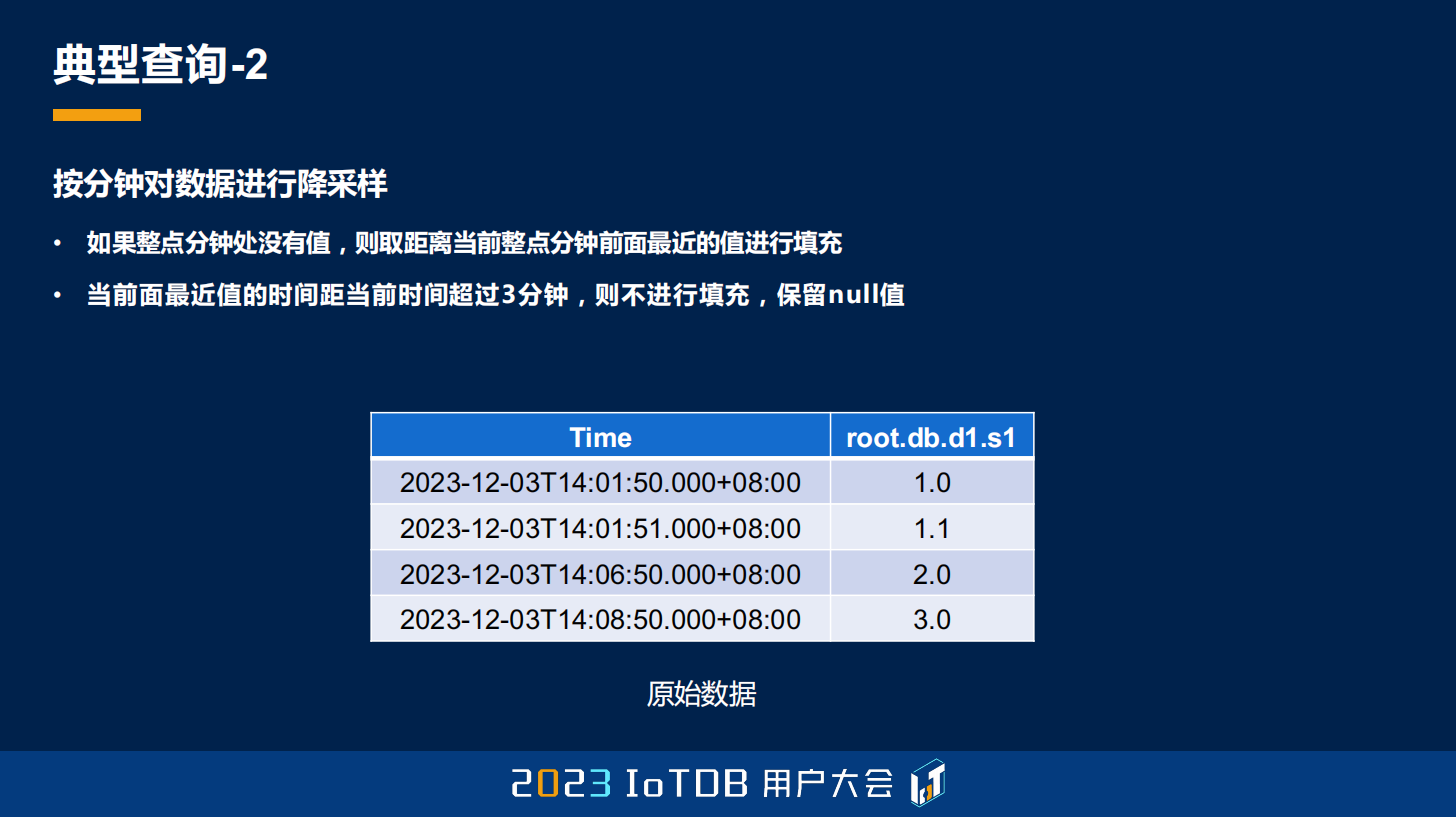
第二个其实刚刚也是提到过了,就是我们需要对数据进行降采样,其实这个降采样函数也是 GROUP BY 加上我们的 FILL 去做到的功能。比如这里,我想对数据进行整点,也就是整分钟的这种采样的时候,如果这个分钟内,比如说 12:01 分,这个分钟没有数据,那怎么办?我想要用离它最近的前一个点去做填充。
首先,既然是整点整分钟,那肯定是跟 GROUP BY TIME 相关的了。如果没有,再用前一个值填充,刚刚其实也提到过了,可能就用前值填充,FILL 的方式去做到。最后就是,我之前提到,如果前面一个值距离我当前这个值已经超过 3 分钟了,我就不需要了,我就认为这个点就是没有值的,你不需要再给我填充了。
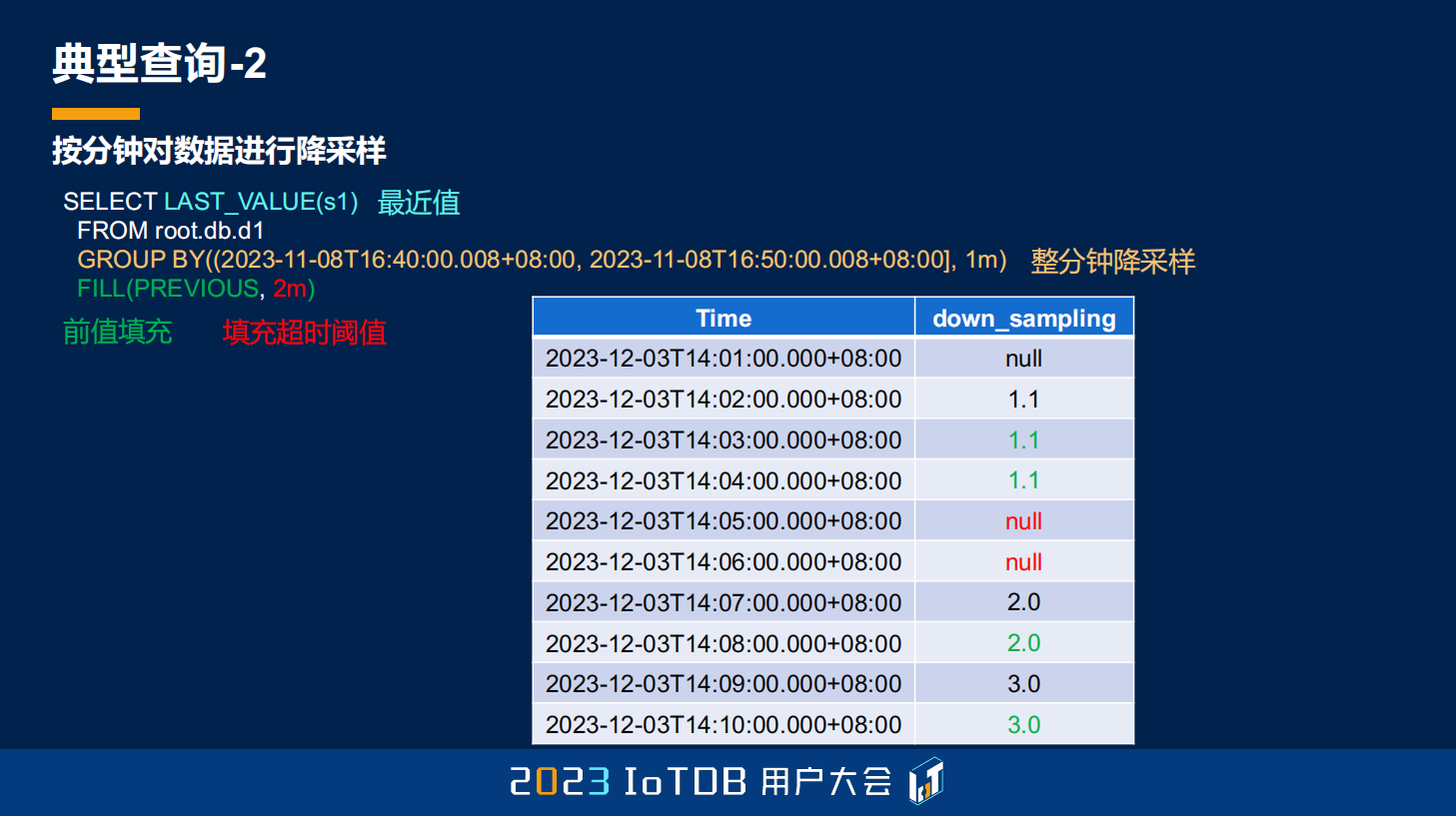
那通过我刚刚提到的 GROUP BY TIME,确定一个时间范围,然后第二个参数去指定降采样的一个 1 分钟的时间点,然后再通过 FILL PREVIOUS 这样一个前值填充的方式,第二个参数去指定它填充的超时阈值,就能够达到这样一个效果。
最后得出来的结果,刚刚可以看到,上面是我们的原始数据结果,它只在 14:01:50、14:01:51、14:06:50 和 14:08:50 有数据,中间的 14:03 分、14:04 分、14:05 分,14:06 分这些,还包括 14:08 分、14:10 分的数据都是需要去填充的。只不过对于 14:05 分跟 14:06 分,这两行数据是因为超过了我们的填充阈值,我们没有对它进行填充。
第三点其实在工业里面也比较常见,就是我们每个机器去开启跟关闭的时长。这个跟我刚刚说的还不一样,我刚刚说的 GROUP BY SESSION,它可能对关闭的状态就不会去采集数据了,但有一些机器,它关闭的时候也要去采集它的数据。所以它有一个字段就是专门用来标识它的关闭或开启的状态的,就是这个 on 字段,那它想做什么查询呢?就是去查询每一次机器它开启和关闭的时长。
这里可以看到它虽然只有 0/1 值,但可以看到它每一次 0 的时候,连续的 0 的时间范围是多少,连续的 1 的时间范围是多少。那在关系型数据库里面,使用 GROUP BY ON 的话,它没有办法区分第一段跟第三段,因为都是 0,这两段会被放在一起。
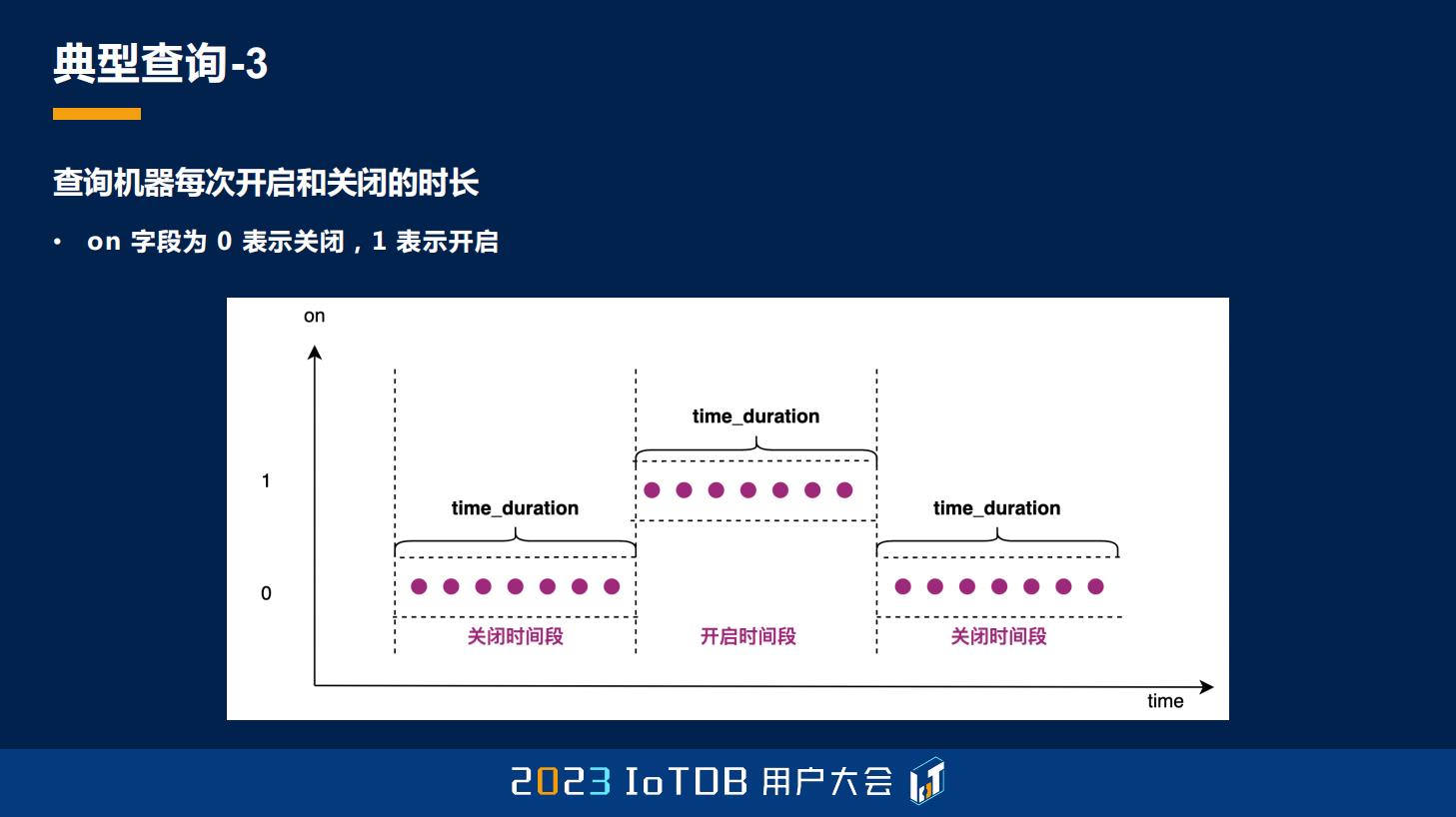
在 IoTDB 里面,可能只需要用 GROUP BY VARIATION 就可以做到,因为 GROUP BY VARIATION 其实就是做这个的,它只要当前值跟上一个值不一样,那不一样是指多少呢?其实这里就是和 0 对比,默认就是 0。也就是说, 你只要不一样,差值超过 0 了,我就认为你是下一个分组了。time_duration 就是一个我们的聚合函数,也是用来求这一段的最后一个值跟第一个值的时间戳的差值,也能够达到我们这个求时长的效果。

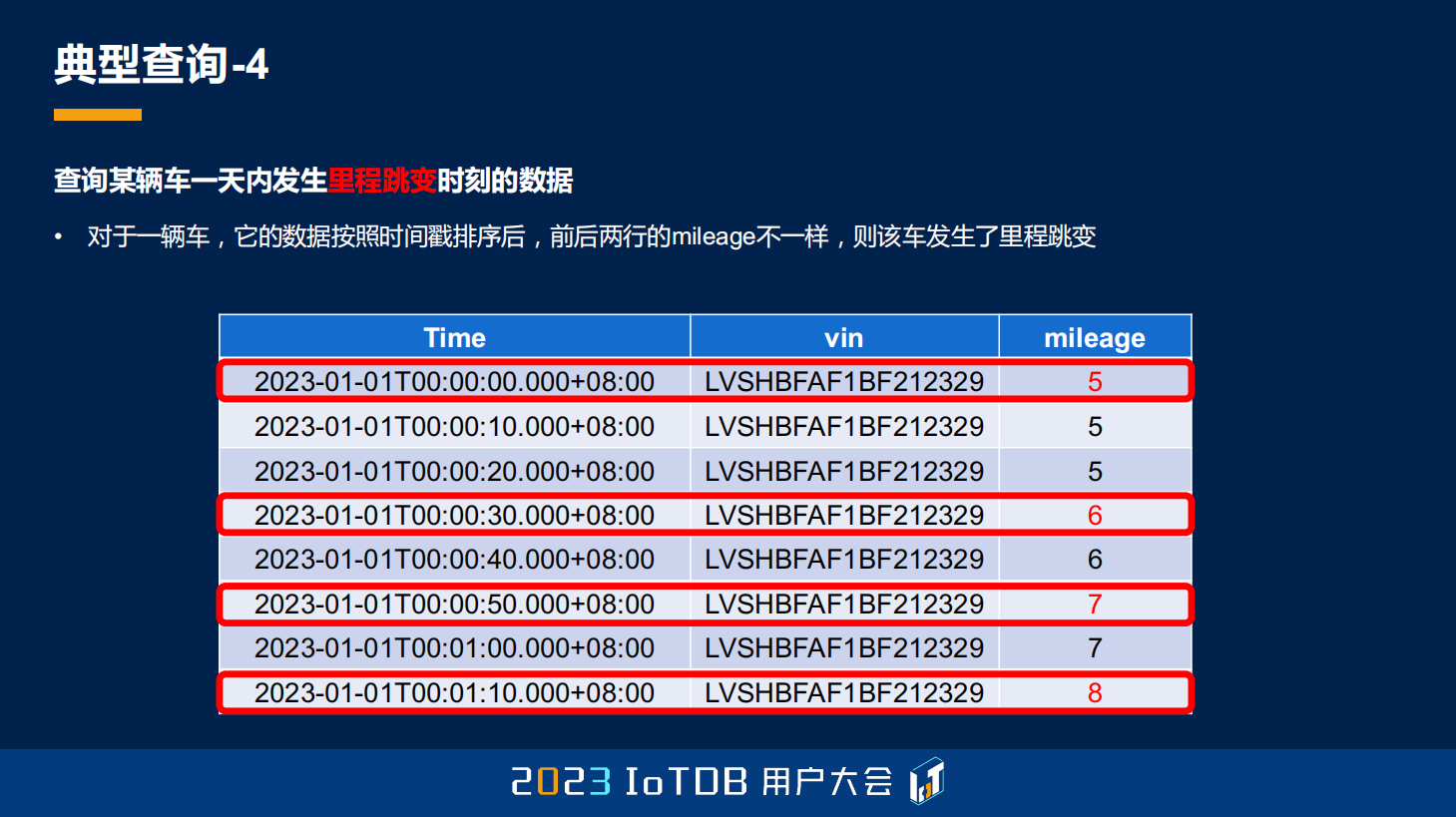
第四点是一个车联网场景里面比较常见的,它想要去查车的里程跳变的时刻。因为车的里程单位统计可能是用公里,开一段时间以后,里程就会一公里跳一下,那我们可能想要去筛选出来这些跳变的时刻,这就是里程跳变的含义。其实我们用肉眼去看的话,很容易找到这些里程跳变的时刻,比如图中框出的这些 5、6、7、8,框出的 5 是第一个里程值,所以我们也会把它选出来。
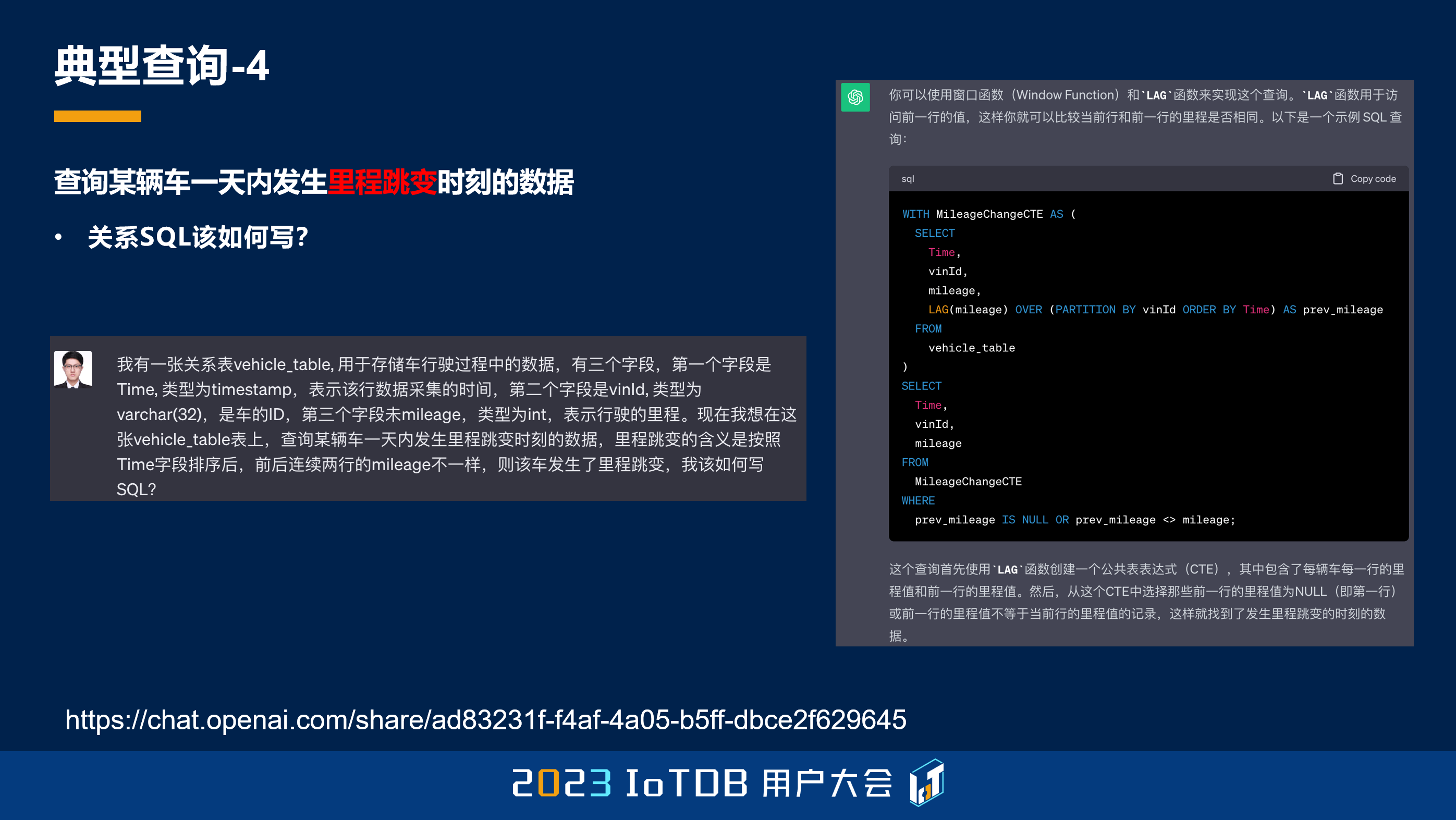
这种情况下关系 SQL 该如何写呢?因为最近 ChatGPT 比较火,我就去跟 ChatGPT 聊,我说你给我建一张关系表,这个关系表里面第一列是时间列,第二列是这个车列,即车的 ID,第三列是我刚刚说的 mileage,我跟它去描述了里程跳变的含义是什么,然后我让它给我去写一个 SQL。
该说不说,ChatGPT 还是很聪明的,它知道要用窗口函数去实现这样一个功能,比如说这边的 LAG 函数,就是去求当前行的上一行。因为关系数据库中是无序的,所以这个窗口函数想要有序,它需要在窗口函数的子句里面去指定排序键,也就是这边的 ORDER BY Time,它根据时间戳的排序是这样排的。
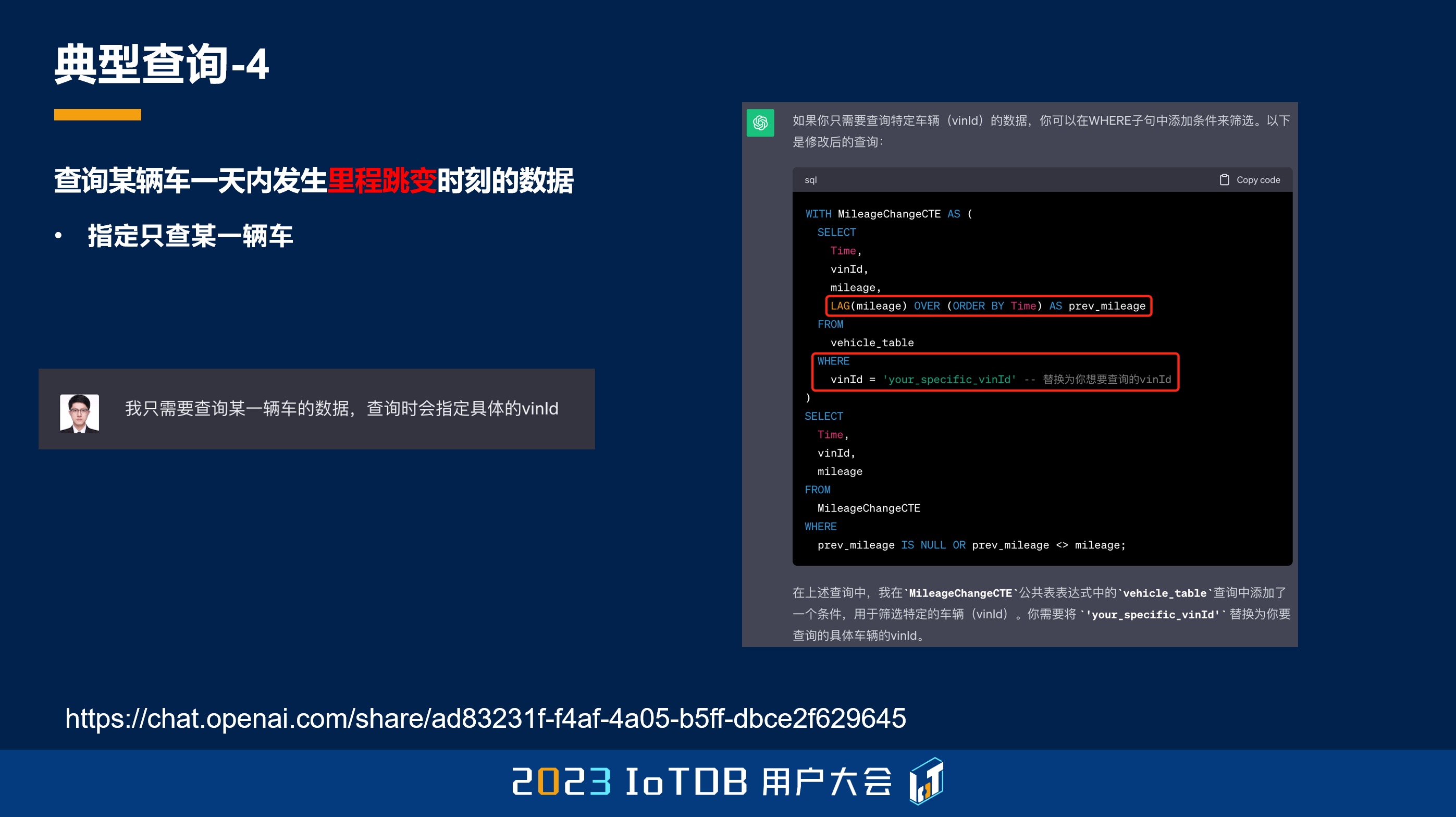
但是 ChatGPT 其实忽略了一个事情,它需要人去慢慢给它提示,所以我告诉它,我只需要查一辆车的值,查询的时候需要指定具体的 vinId,因为它前面其实是没有指定 vinId 的。然后它就给出了一个比较正确的查询,它在 where 子句里面指定了这个 vinId。
可以看到,用关系 SQL 写出来,可能还要用嵌套、子查询,包括 CTE 这些表达,这些写出来已经是比较长的语句了,对一个不熟悉窗口函数的人来讲,它可能还写不出来这样的方式。
而在 IoTDB 里面其实非常简单,就是用我刚刚提到的 DIFF 函数,只要 DIFF 不等于 0,就证明里程发生跳变了,然后用 where time 指定一个时间区间,就能够直接做到将里程跳变时刻的数据筛选出来了。

这里我还想举一个例子,就是发生里程跳变之后,我们想要知道一天内发生里程跳变的次数。对于关系型数据库,刚刚子查询的部分,需要再做一个 COUNT。
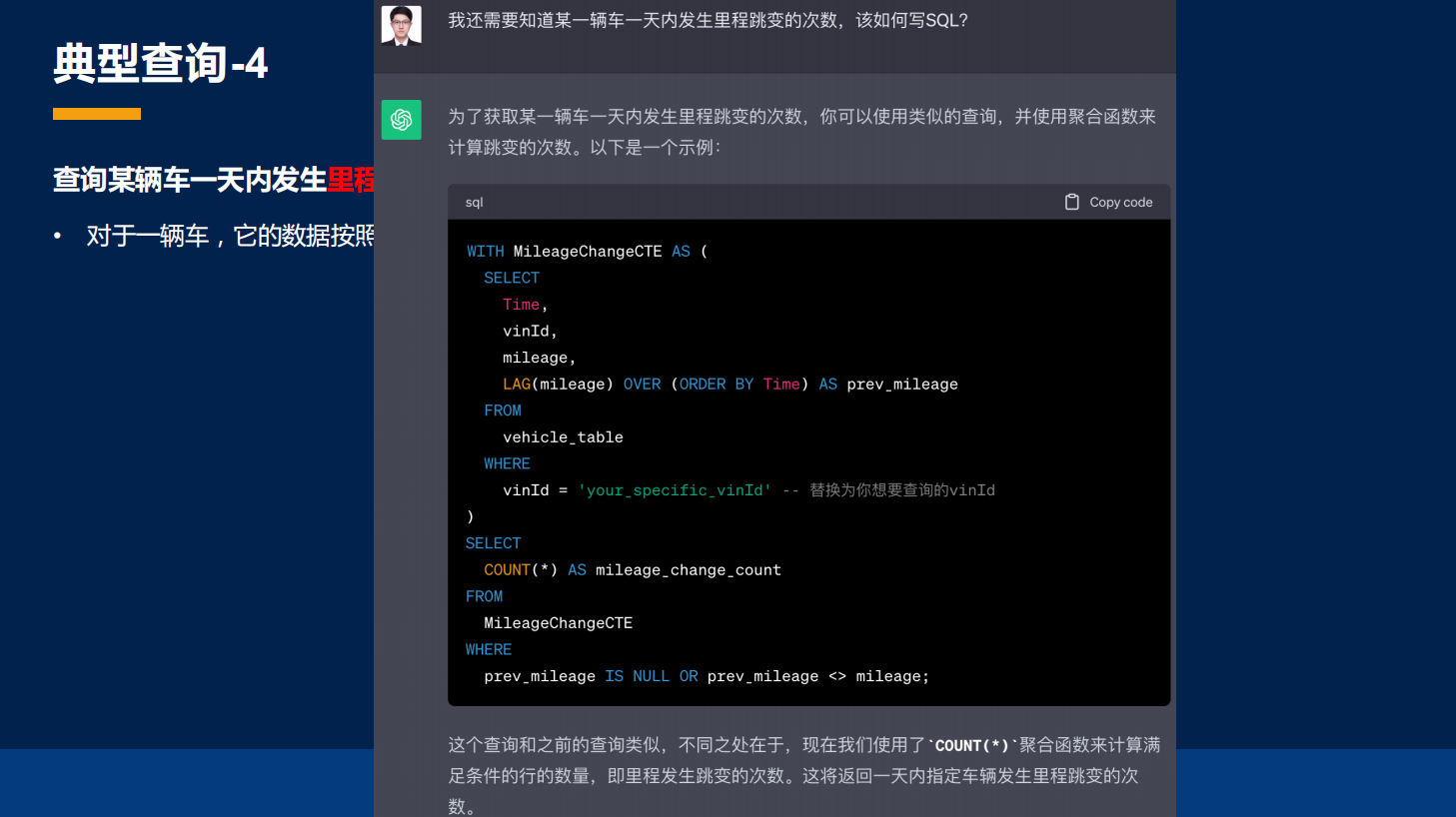
那在 IoTDB 里面其实也比较容易做到,它不需要用任何子查询也能做到,就是在我们的 COUNT 里面嵌套一个 CASE WHEN 的子句,只不过在 CASE WHEN 里面,我们指定了 DIFF 这样一个标量函数,只要 DIFF 不等于 0,输出结果就是 1,然后再把这些数起来就行了。

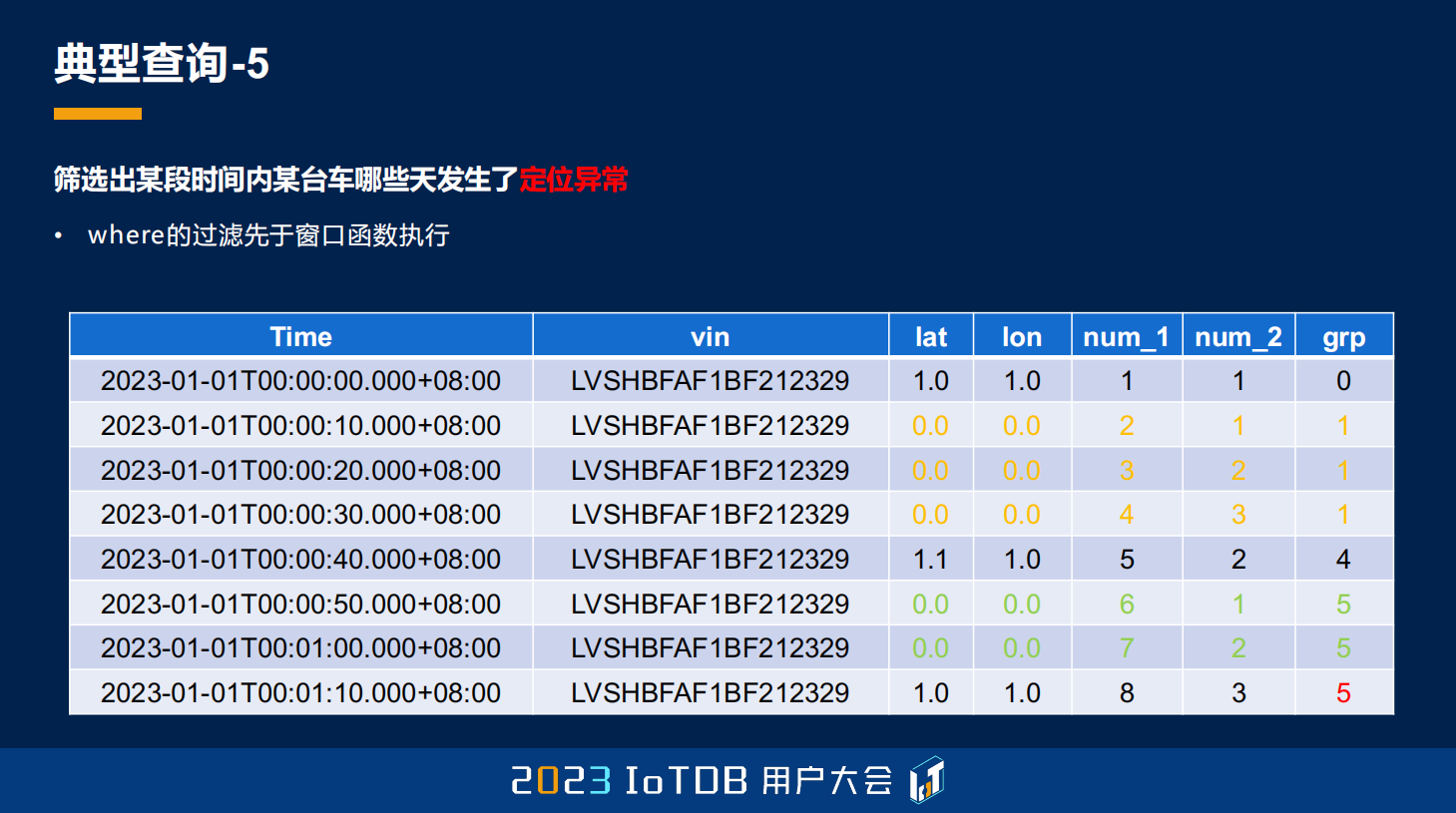
第五个典型的查询还是车联网场景的,需要去知道某台车哪些天发生了定位异常,那定位异常的含义是什么?就是我们定义 GPS 的经纬度坐标都连续为 0 的次数大于 10 的时候,它才算一次定位异常。这里的数据其实都没有定位异常。
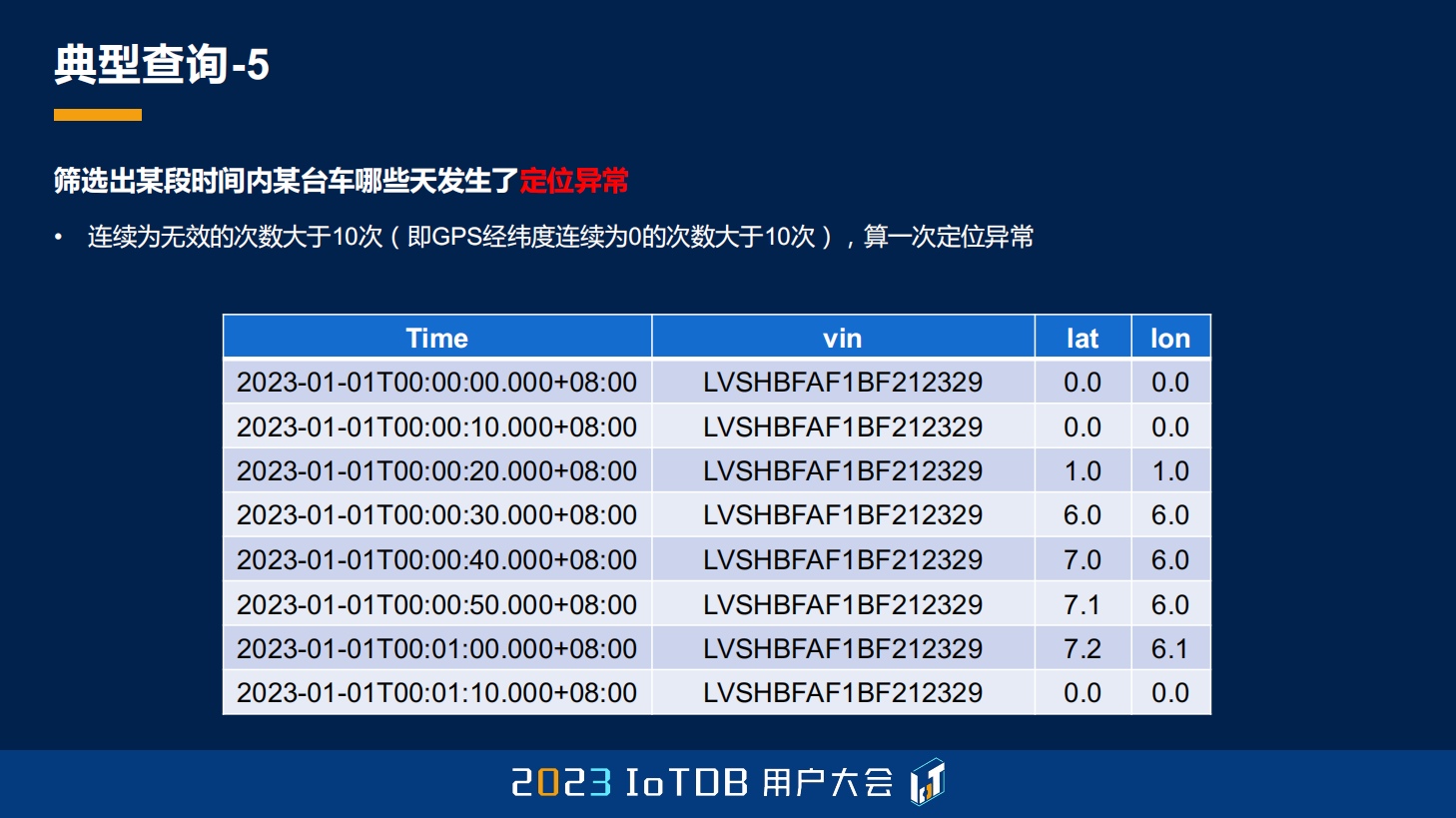
那同样的,我们问问 ChatGPT,上面场景的关系 SQL 该怎么去写?我给它一个建模,它就给出来了这样的查询语句。当然它这个查询语句肯定是错的,因为它并没有考虑到任何连续性的含义,我告诉它要连续超过十天才能是异常。它把这个语句写在 HAVING 里面了,但它这个是不对的,所以它并没有体现我们要求的连续 10 次才算异常的这样一个语句。
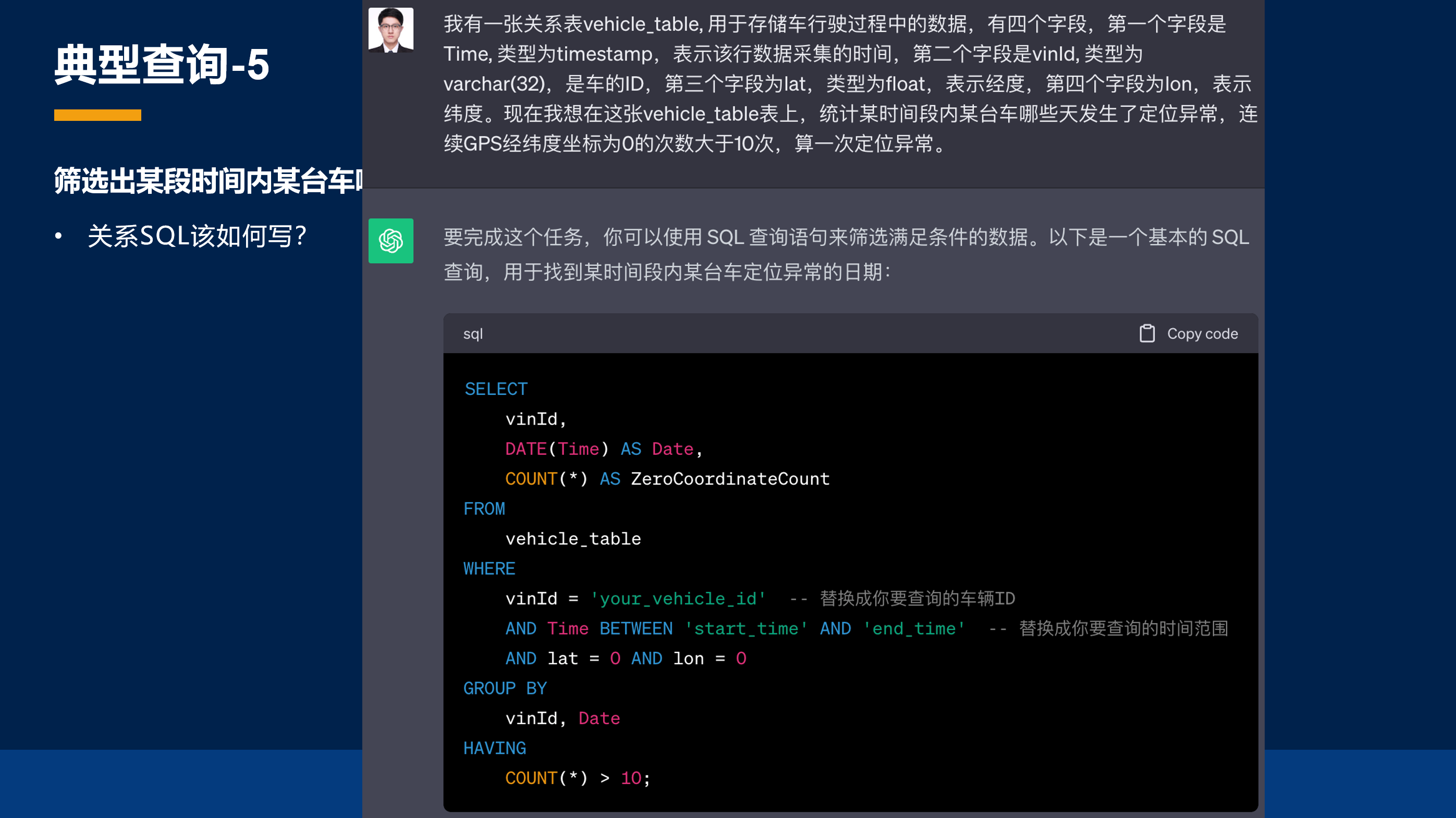
我就再次告诉它需要这样去做,然后它就给出了另外一个更复杂的操作。但它这个操作其实是有它自己的思考的,我们可以看一下它是想怎么去做的。它想要去给每条数据一个标号,首先它列出的 num_1 ,就是对应代码这里的第三行,即 ROW_NUMBER 里面的第一个,被减数。它想去做的就是给每一行标一个顺序,这样一个从 1 到 8 的序号,然后它要根据每一个经纬度坐标做一个分组,每一个分组内去再做一个序号的标定,最后它想通过 num_1 减去 num_2 之后得到的这样一个 group 进行标定。
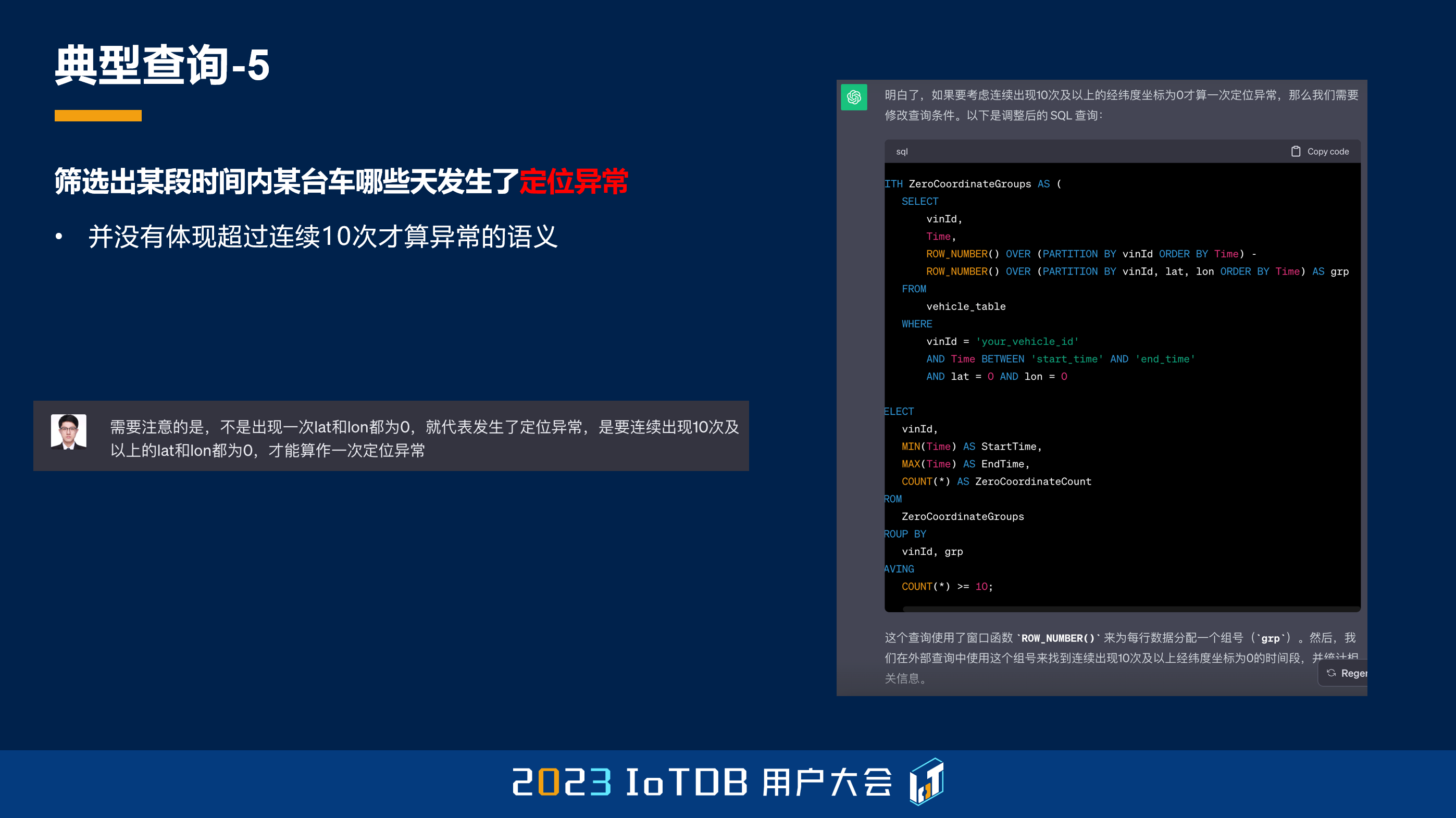
我一开始思考了一下,它为什么要去这么做,大家可以看到,这里很明显,我标黄的这个部分,其实它是一个连续为 0 的分组,2 减 1、3 减 2、4 减 3,得出来都是 1,所以 ChatGPT 想通过这样一种方式,找到这样连续的异常分组。
但是它忽略了一个事情。第一个是 where 的过滤是要优先于窗口函数执行的,所以在它做那个计算的时候,除了我标颜色的这些,其它的行都不会有,所以它从一开始就错了。那即使按照它的这个方法,我把 where 条件过滤,放到后面去做,它也是错的,因为大家可以看到最后一行,8 减 3 结果也是 5,但明显它跟前面标绿的不是一个分组。
所以有时候 ChatGPT 也不是特别可信,如果用它来替代程序员或者 DBA 做一些查询的话,大家目前也不用太担心被取代以致失业的问题。
其实真正去写关系 SQL 的话,可能写出来会非常长。我们会用一些窗口函数去定义,因为要检查 10 行,所以往前倒 10 个,写出来是非常非常长的。
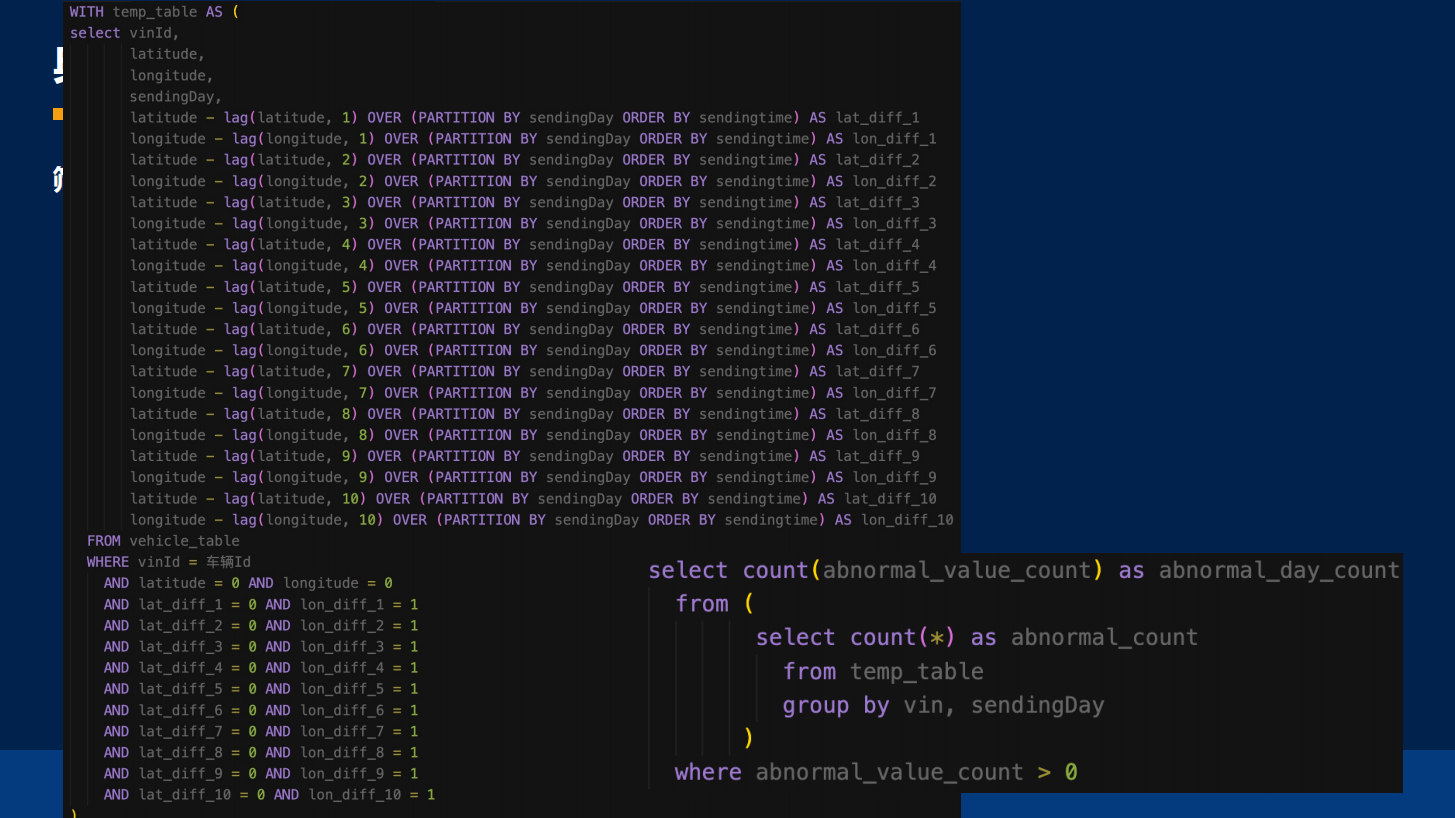
在 IoTDB 中其实是比较简单的,这里就是用了 COUNT_IF 的功能,它主要就是在 COUNT_IF 里面去写。因为 COUNT_IF 就是做了这样一个事情,要数出来有多少个异常点,KEEP 连续大于等于 10 的时候,它才是定位异常点,并且要按天去做分组,去得到具体的日期,因为想知道的是哪一天的定位异常点。

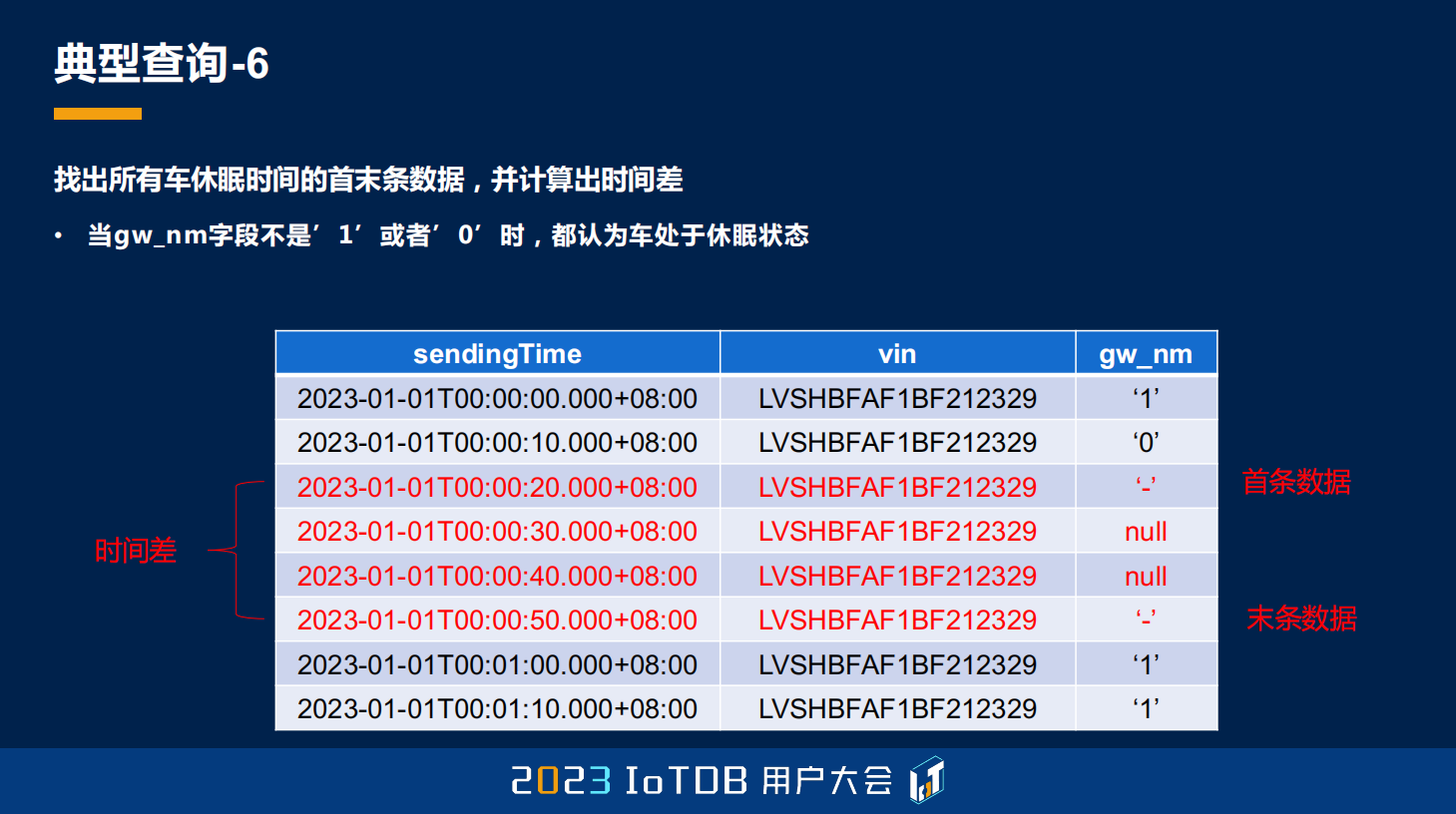
第六个典型查询,想要找出所有的车的休眠时间的首末条数据,并计算出时间差。那什么是休眠呢?就是当 gw_nm 这个字段不是 1 或者 0 的时候,我们都认为这个车处于休眠状态。这边数据标红的就是休眠状态,它有这种不规则的 “-”,或者 null 值,都被我们认为是休眠状态,我们需要找出它的首末条数据,最后再计算出它的时间差。
我同样也去问了一下 ChatGPT,但是大家可以忽略 ChatGPT 做出来的这个结果,因为它已经混乱了,在这种比较复杂语义的情况下,它写出来的语句已经算是牛头不对马嘴了。
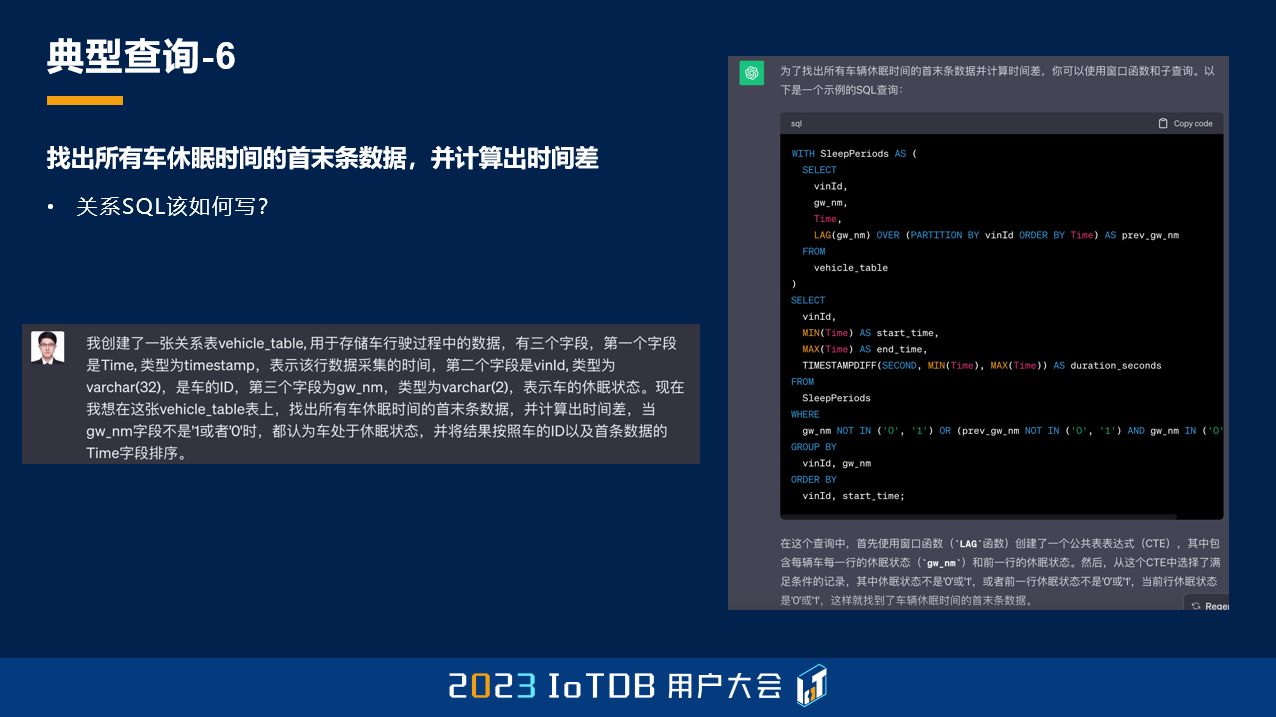
真正的关系型 SQL 写法我也给大家列了一下,写出来大概是这个样子,虽然没有刚刚的长,但它的思考过程可能比刚刚的要更复杂一点。大家可以看一下,在这里我就不跟大家展开介绍了,可以看到其实是比较复杂的,这边只是得到了一张 temp 表,从这张表中,我们要过滤出来它开始的那一行和结束的那一行,这是 temp_a 表。然后 temp_b 表里面还要对它进行分组,得到它的分组 id,最后再根据我们刚刚得到的 id,去做这张表的自 JOIN,把它的首行和末行拼在同一行之后,我们的关系数据库才能做这个时间差的计算。
所以这个关系 SQL 写出来非常长,我这里是 3 页 PPT,通过四张 temp 表才能够去写出来。
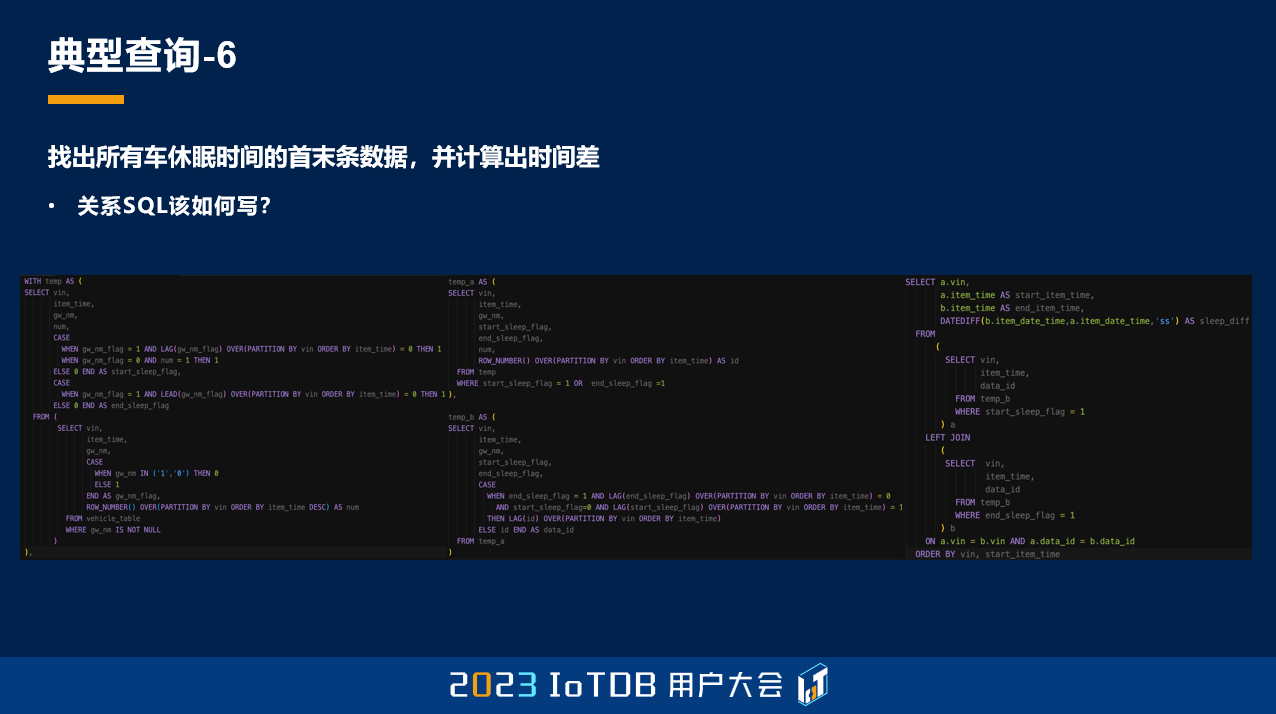
然而在 IoTDB 中依然比较简单,这得益于我们的 GROUP BY CONDITION 函数。使用 GROUP BY CONDITION, gw_nm 这个字段不在 0、1 里面,并且它超过 2 次,我们就认为它是一个休眠分组了。然后只需要取到首条数据、末条数据,用我们的 FIRST_VALUE、LAST_VALUE。最后计算休眠时长,就是最后的时间戳减去第一个时间戳,就能得到我们的休眠时长。

最后一个典型查询场景是要取出 60 秒以上的连续信号的第一条和最后一条数据,那这个连续信号怎么定义呢?就是我们的时间戳排序之后,一台车的前后两条数据的时间差不能够超过 24 秒,其实刚刚讲 GROUP BY SESSION 的时候可能跟大家提过了,这就是用 IoTDB 里面的 GROUP BY SESSION 去做的一个查询。
在 IoTDB 里面很简单,但是在关系型数据库里面,可能它也会比较复杂。当然这里 ChatGPT 写出来还是错的,但是我也没有去费时间给大家把这个关系 SQL 写出来了。
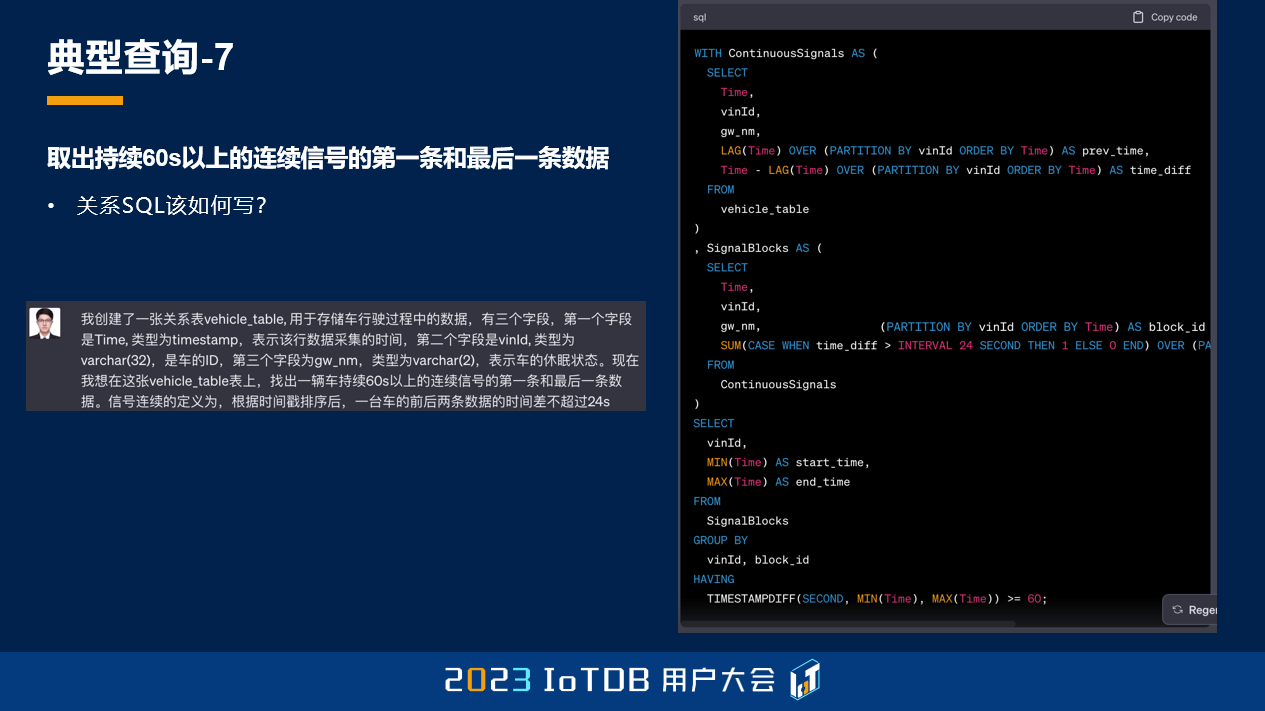
给大家展示一下在 IoTDB 中写出来的,会比较简单,同样的,FIRST_VALUE、LAST_VALUE 来取首末条数据,然后连续信号的时间跨度,使用 GROUP BY SESSION,即刚刚提到的连续信号的分组。并且我们需要持续时间超过 60 秒以上,可以通过 HAVING 的子句去做到。
OK,那我今天的演讲就到这里了,谢谢。

更多内容推荐:
•
回顾
IoTDB 2023 大会全内容
Welcome to our website!
To ensure you have the best possible experience and can easily navigate our content, we recommend that you visit our international website.
Go to International Site
Stay on Chinese Site

