

13 个开源 CHATGPT 模型:完整指南

在本文中,我们将解释开源 ChatGPT 模型的工作原理以及如何运行它们。我们将涵盖十三种不同的开源模型,即 LLaMA、Alpaca、GPT4All、GPT4All-J、Dolly 2、Cerebras-GPT、GPT-J 6B、Vicuna、Alpaca GPT-4、OpenChatKit、ChatRWKV、Flan-T5 和 OPT。到本文结束时,您应该对这些模型有很好的理解,并且您应该能够在 Python 中运行它们。
ChatGPT 不是开源的。它有两个最近流行的版本 GPT-3.5 和 GPT-4。GPT-4 对 GPT-3.5 进行了重大改进,并且在生成响应方面更加准确。ChatGPT 不允许您查看或修改源代码,因为它不是公开的。因此,需要开源且免费提供的模型。通过使用这些开源模型,您无需为 OpenAI API 付费即可访问它们。
开源 ChatGPT 模型的好处
使用作为 ChatGPT 替代品的开源大型语言模型有很多好处。下面列出了其中一些。
- 数据隐私 :许多公司希望控制数据。这对他们来说很重要,因为他们不希望任何第三方访问他们的数据。
- 定制化 :它允许开发人员使用自己的数据训练大型语言模型,如果他们想应用,可以对某些主题进行一些过滤
- 负担能力 :开源 GPT 模型让您可以训练复杂的大型语言模型,而无需担心昂贵的硬件。
- 人工智能民主化 :它为进一步研究开辟了空间,可用于解决现实世界的问题。
您必须知道的开源聊天 GPT 模型
LLaMA骆驼
LLaMA简介 :
LLaMA 代表大型语言模型元 AI。它包括从 70 亿到 650 亿个参数的一系列模型大小。Meta AI 研究人员专注于通过增加训练数据量而不是参数数量来扩展模型的性能。他们声称 130 亿参数模型优于 GPT-3 模型的 1750 亿参数。它使用 transformer 架构,并接受了通过网络抓取维基百科、GitHub、Stack Exchange、古腾堡计划的书籍以及 ArXiv 上的科学论文提取的 1.4 万亿个令牌的训练。
# Install Package
pip install llama-cpp-python
from llama_cpp import Llama
llm = Llama(model_path="./models/7B/ggml-model.bin")
output = llm("Q: Name the planets in the solar system? A: ", max_tokens=128, stop=["Q:", "\n"], echo=True)
print(output)
在模型路径中,您需要具有 GGML 格式的 LLaMA 权重,然后将它们存储到模型文件夹中。您可以在 Hugging Face 网站上搜索它。
在这里
看到其中一个
Alpaca羊驼
LLaMA
简介 :
斯坦福大学的一组研究人员开发了一种名为
Alpaca
. 它基于 Meta 的大规模语言模型
LLaMA
。该团队使用 OpenAI 的 GPT API (text-davinci-003) 微调 LLaMA 70 亿 (7B) 参数大小的模型。该团队的目标是让每个人都可以免费使用 AI,这样院士们就可以进行进一步的研究,而不必担心昂贵的硬件来执行这些内存密集型算法。尽管这些开源模型不可用于商业用途,但小型企业仍然可以利用它来构建自己的聊天机器人。
羊驼是如何工作的
斯坦福团队从 LLaMA 模型中最小的语言模型 LLaMA 7B 模型开始他们的研究,并用 1 万亿个令牌对其进行预训练。他们从自我指导种子集中的 175 个人工编写的指令输出对开始。然后,他们使用 OpenAI API 要求 ChatGPT 使用种子集生成更多指令。这是为了获得大约 52,000 个示例对话,团队使用这些对话进一步微调使用 Hugging Face 训练框架的 LLaMA 模型。
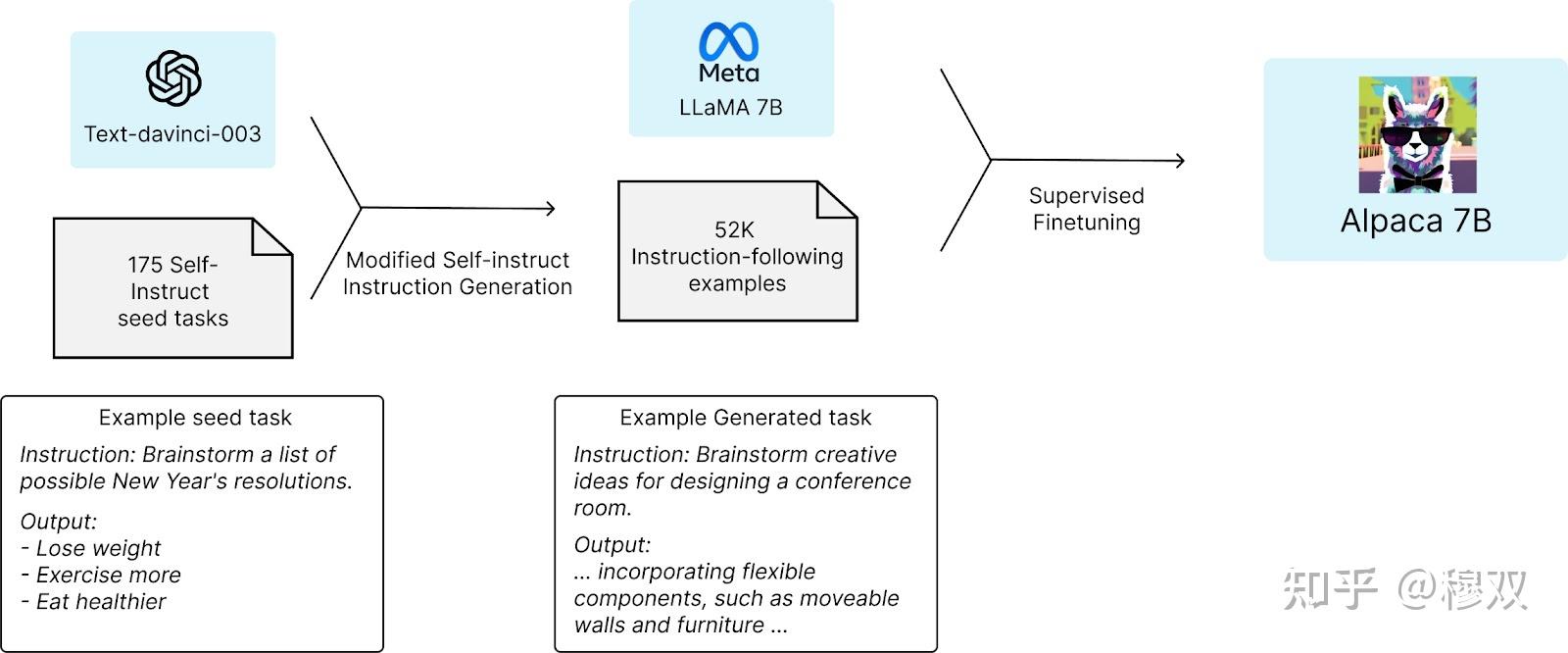
LLaMA 有多种尺寸 - 7B、13B、30B 和 65B 参数。Alpaca 也扩展到 13B、30B 和 65B 型号。
Alpaca 性能
Alpaca 模型在电子邮件创建、社交媒体和生产力工具等任务中针对 ChatGPT 进行了测试,Alpaca 赢了 90 次,而 ChatGPT 赢了 89 次。该模型可以在现实世界中用于各种目的。这将对研究人员进行道德人工智能和网络安全活动(如检测诈骗和网络钓鱼)有很大帮助。
Alpaca 局限性
与商业版的 ChatGPT 一样,Alpaca 也有类似的局限性,即遭受幻觉、毒性和刻板印象。换句话说,它可以用来生成散布错误信息、种族主义和对社会弱势群体的仇恨的文本。
内存要求:羊驼
它不能在 CPU 上运行,需要 GPU。对于 7B 和 13B 型号,它需要一个 GPU 和 12GB 内存。对于 30B 型号,您需要更多系统资源。
Python代码:羊驼
我已经创建了
Colab 代码
。您可以使用它作为参考。因为我使用的是免费版的 Colab,所以我运行的是最小的 7B 型。您可以将其更改为 13B 和 30B。
与 ChatGPT 的商业界面类似,代码的输出结果是在 Gradio 中创建的 Web 界面。此外,您可以将此界面用于演示目的,并与同事或客户共享。
使用 Python 3.9 创建环境
import sys
sys.path.append("/usr/local/lib/python3.9/site-packages")
下面的命令
nvidia-smi
是显示有关 GPU 使用情况和性能的信息的命令。
!nvidia-smi
下载 Git 存储库
!git clone https://github.com/deepanshu88/Alpaca-LoRA-Serve.git
安装所需的包
%cd Alpaca-LoRA-Serve
!python3.9 -m pip install -r requirements.txt
选择模型尺寸
base_model = 'decapoda-research/llama-7b-hf'
finetuned_model = 'tloen/alpaca-lora-7b'
运行应用程序
!python3.9 app.py --base_url $base_model --ft_ckpt_url $finetuned_model --share
完整代码
import sys
sys.path.append("/usr/local/lib/python3.9/site-packages")
!nvidia-smi
!git clone https://github.com/deepanshu88/Alpaca-LoRA-Serve.git
%cd Alpaca-LoRA-Serve
!python3.9 -m pip install -r requirements.txt
base_model = 'decapoda-research/llama-7b-hf'
finetuned_model = 'tloen/alpaca-lora-7b'
!python3.9 app.py --base_url $base_model --ft_ckpt_url $finetuned_model --share
上面的代码支持比 7B 更大的语言模型。请参阅下面的参考资料。7B 和 13B 可以在免费版本的 colab 中使用。对于 30B,您需要购买高级版的 colab。
--base_url
的可能值
- decapoda-research/llama-7b-hf
- decapoda-research/llama-13b-hf
- decapoda-research/llama-30b-hf
--ft_ckpt_url
的可能值
- tloen/alpaca-lora-7b
- chansung/alpaca-lora-13b
- chansung/alpaca-lora-30b
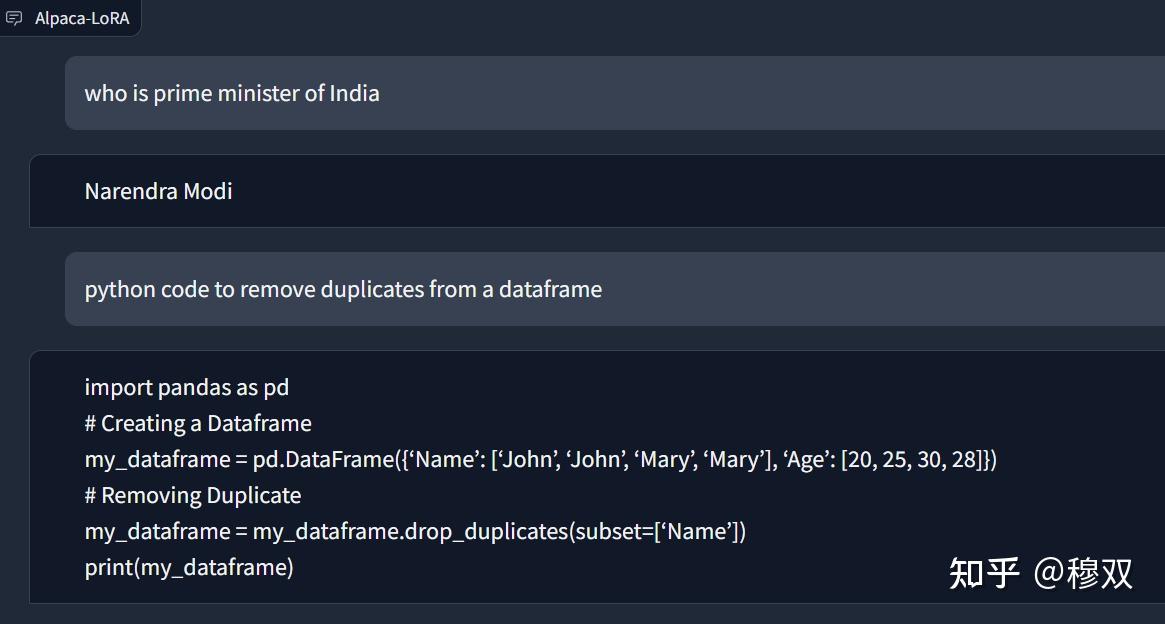
Alpaca输出:
请参阅下面的输出,其中我问了两个相对简单的问题。一个与通用主题相关,另一个与编码相关。它正确地回答了这两个问题。
GPT4All
简介:GPT4All
Nomic AI Team 从 Alpaca 获得灵感,使用 GPT-3.5-Turbo OpenAI API 收集了大约 800,000 个提示-响应对,创建了 430,000 个助手式提示和生成训练对,包括代码、对话和叙述。80 万对大约是羊驼的 16 倍。该模型最好的部分是它可以在 CPU 上运行,不需要 GPU。与 Alpaca 一样,它也是一个开源软件,可以帮助个人进行进一步的研究,而无需花费在商业解决方案上。
GPT4All 是如何工作的
它的工作原理类似于
羊驼
,基于 LLaMA 7B 模型。LLaMA 7B 和最终模型的微调模型在 437,605 个后处理助手式提示上进行了训练。
性能:GPT4All
在自然语言处理中,困惑度用于评估语言模型的质量。它衡量语言模型根据其训练数据看到以前从未遇到过的新单词序列时会有多惊讶。较低的困惑值表示语言模型更擅长预测序列中的下一个单词,因此更准确。Nomic AI 团队声称他们的模型比 Alpaca 具有更低的困惑度。真正的准确性取决于您的提示类型。在某些情况下,Alpaca 可能具有更好的准确性。
内存要求:GPT4All
它可以在具有 8GB RAM 的 CPU 上运行。如果你有一台 4GB RAM 的笔记本电脑,可能是时候升级到至少 8G 了
Python代码:GPT4All
Colab 代码
可供您使用。您可以将其用作参考,根据需要进行修改,甚至按原样运行。完全由您决定如何使用代码来最好地满足您的要求。
克隆 Git 存储库
!git clone --recurse-submodules https://github.com/nomic-ai/gpt4all.git
安装所需的包
cd /content/gpt4all
!python -m pip install -r requirements.txt
cd transformers
!pip install -e .
cd ../peft
!pip install -e .训练
!accelerate launch --dynamo_backend=inductor --num_processes=8 --num_machines=1 --machine_rank=0 --deepspeed_multinode_launcher standard --mixed_precision=bf16 --use_deepspeed --deepspeed_config_file=configs/deepspeed/ds_config.json train.py --config configs/train/finetune.yaml下载 CPU 量化的 gpt4all 模型检查点
cd /content/gpt4all/chat
!wget https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin
运行会话系统
!./gpt4all-lora-quantized-linux-x86
如果您在运行除linux
以外的任何其他操作系统的本地计算机上运行它,请使用下面的命令代替:
Windows (PowerShell): ./gpt4all-lora-quantized-win64.exe
Mac (M1): ./gpt4all-lora-quantized-OSX-m1
Mac (Intel): ./gpt4all-lora-quantized-OSX-intel
完整代码
!git clone --recurse-submodules https://github.com/nomic-ai/gpt4all.git
cd /content/gpt4all
!python -m pip install -r requirements.txt
cd transformers
!pip install -e .
cd ../peft
!pip install -e .
!accelerate launch --dynamo_backend=inductor --num_processes=8 --num_machines=1 --machine_rank=0 --deepspeed_multinode_launcher standard --mixed_precision=bf16 --use_deepspeed --deepspeed_config_file=configs/deepspeed/ds_config.json train.py --config configs/train/finetune.yaml
cd /content/gpt4all/chat
!wget https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin
!./gpt4all-lora-quantized-linux-x86
输出:GPT4All
GPT4All 无法正确回答与编码相关的问题。这只是一个例子,不能据此判断准确性。它可能在其他提示中运行良好,因此模型的准确性取决于您的使用情况。此外,当我在 2 天后再次运行它时,它适用于与编码相关的问题。看来他们进一步完善了模型。

错误调试
Distributed package doesn't have NCCL - 如果您在Mac 操作系统上遇到此问题,那是因为您的计算机上未安装 CUDA。
Issues on Windows 10/11 - 一些用户报告说他们在 Windows 平台上遇到了一些奇怪的错误。作为最后的手段,您可以安装适用于 Linux 的 Windows 子系统,它允许您在 Windows 机器上安装 Linux 发行版,然后可以按照上面的代码进行操作。
GPT4All-J
您一定想知道这个模型如何与前一个名称相似,只是后缀为“J”。这是因为这两个模型都来自 Nomic AI 的同一个团队。唯一的区别是它现在是在 GPT-J 上而不是在 LLaMa 上训练的。在 GPT-J 上训练它的好处是 GPT4All-J 现在是 Apache-2 许可的,这意味着您可以将它用于商业目的,也可以轻松地在您的机器上运行。
下载安装文件
根据您的操作系统下载以下安装程序文件。安装完成后,您需要导航到安装文件夹中的“bin”目录。要启动 GPT4All Chat 应用程序,请执行“bin”文件夹中的“chat”文件。该文件将在 Linux 上命名为“chat”,在 Windows 上命名为“chat.exe”,在 macOS 上命名为“chat.app”
dolly 2 -- 多莉 2
Databricks 团队基于 EleutherAI 的 Pythia 模型创建了大型语言模型,随后他们在大约 15,000 条记录指令语料库上进行了微调。它遵循 Apache 2 许可,这意味着训练它的模型、训练代码、数据集和模型权重都可以作为开源使用,这样您就可以将它用于商业用途来创建您自己的自定义大型语言模型。
它具有三种尺寸 - 12B、7B 和 3B 参数。
databricks/dolly-v2-12b on pythia-12b
databricks/dolly-v2-7b on pythia-6.9b
databricks/dolly-v2-3b on pythia-2.8b
内存要求:多莉 2
对于具有 8 位量化的 7B 模型,它需要一个具有大约 10GB RAM 的 GPU。对于 12B 型号,它至少需要 18GB GPU vRAM。
Python代码:多莉2
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
baseModel = "databricks/dolly-v2-12b"
load_8bit = True
tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-12b")
model = AutoModelForCausalLM.from_pretrained(baseModel, load_in_8bit=load_8bit, torch_dtype=torch.float16, device_map="auto")
generator = pipeline(task='text-generation', model=model, tokenizer=tokenizer)
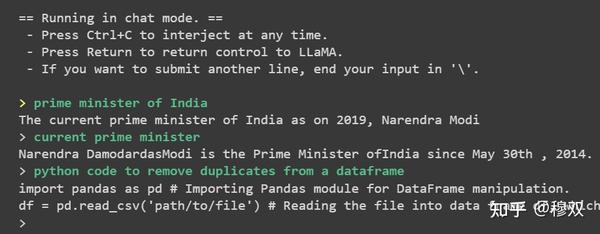
print(generator("Python code to remove duplicates from dataframe"))
Vicuna - 骆马
简介:骆马
来自加州大学伯克利分校、卡内基梅隆大学、斯坦福大学和加州大学圣地亚哥分校的研究人员团队开发了这个模型。它使用从 ShareGPT 网站提取的聊天数据集在 LLaMA 上进行了微调。研究人员声称该模型的
质量得分超过 OpenAI ChatGPT-4 的 90%
。值得注意的是,它的性能几乎与Bard持平。他们使用了羊驼的训练程序,并在多轮对话和长序列两个方面进行了进一步改进。
Python代码:Vicuna
您可以参考这篇文章——Vicuna
详细指南
来访问 python 代码和 Vicuna 模型的详细描述。
Alpaca GPT-4 Model ( 羊驼 GPT-4 模型)
简介:羊驼GPT-4
您已经在本文的前一部分了解了 Alpaca。在这里,一些研究人员通过在 GPT-4 数据集上训练来改进原始的羊驼模型。请记住,斯坦福大学研究人员最初的羊驼模型是基于 GPT-3 模型的。这个 GPT-4 模型是在 LLaMA 130 亿 (13B) 参数大小的模型上训练的。
Python代码:羊驼GPT-4
Alpaca GPT-4 模型的 Python 程序在这里解释 -
Alpaca GPT-4 详细指南
。
Cerebras-GPT( 大脑-GPT )
简介:Cerebras-GPT
你们中的一些人可能以前没有听说过
Cerebras Systems
。他们不像以制造GPU而闻名的NVIDIA那样知名,但他们也是一家专门制造高性能计算系统的科技公司。他们最近发布了开源项目,其中包含七个基于 GPT 的语言模型,参数大小分别为 1.11 亿、2.56 亿、5.9 亿、13 亿、27 亿、67 亿和 130 亿。
这些模型最好的部分是它们是免费提供的,并且
可以用于商业目的
,因为它符合 Apache 2.0 许可,而 LLaMA 带有“非商业”许可,这意味着它们是免费的但只能用于研究目的。
此外,它们还有 7 种不同尺寸的型号可供选择,这意味着您可以根据硬件配置选择多种型号。如果您的硬件不允许试验大型模型,请选择较小的模型。
内存要求:Cerebras-GPT
它需要具有 12GB RAM 的 GPU 才能运行 1.3B 参数大小的 Cerebras-GPT 模型。
Python 代码:Cerebras-GPT
在下面的程序中,我们使用了由
Stochastic Inc
xTuring
团队开发的名为 python 包。它允许开发人员有效地微调不同的大型语言模型。它们还使语法非常易读且易于遵循。
在这里,我们使用微调 Cerebras-GPT 模型
Alpaca dataset
可参考此
Colab 代码进行测试。
在下面的代码中,我们使用 Cerebras-GPT 1.3B 模型
安装 xTuring 库
!pip install xturing --upgrade
生成数据集
!wget https://d33tr4pxdm6e2j.cloudfront.net/public_content/tutorials/datasets/alpaca_data.zip
!unzip alpaca_data.zip
加载数据集并初始化模型
from xturing.datasets.instruction_dataset import InstructionDataset
from xturing.models.base import BaseModel
instruction_dataset = InstructionDataset("/content/alpaca_data")
# Initializes the model
model = BaseModel.create("cerebras_lora_int8")
微调模型
model.finetune(dataset=instruction_dataset)
构建聊天机器人
output = model.generate(texts=["prime minister of India?"])
print("Generated output by the model: {}".format(output))微调模型需要大量处理时间,因此必须非常耐心。微调完成后,您可以保存模型以备将来参考。
# Save Model
model.save("/path_directory")
# Load a fine-tuned model
finetuned_model = BaseModel.load("/path_directory")
In case the loading model returns error AssertionError: We were not able to find the xturing.json file in this directory, use the code below.
model = BaseModel.create("cerebras",weights_path="/path_directory")
GPT-J 6B
简介 : GPT-J 6B
GPT-J 6B 由 EleutherAI 的研究人员开发。它不是新模型,因为它是在 2021 年下半年发布的。它有 60 亿个参数。它不像 Meta 的 LLaMA 那么大,但它在聊天、摘要和问答等各种自然语言处理任务上表现出色。模型的大尺寸并不一定意味着更准确。它在 TPU v3-256 pod 上接受了 4020 亿个令牌的训练。
与 Cerebras-GPT 一样,GPT-J 6B 也获得了 Apache 2.0 许可,允许您将其用于商业目的。
Python代码:GPT-J 6B
您可以参考
colab notebook
进行试用。GPT-J 6B 的 Python 代码类似于
Cerebras-GPT
的代码。唯一的变化是基础模型的初始化
BaseModel.create("gptj_lora_int8")
而不是
BaseModel.create("cerebras_lora_int8")
OpenChatKit 模型
简介:OpenChatKit
OpenChatKit 是一种用于创建聊天机器人的开源大型语言模型,由 Together 开发。他们与 LAION 和 Ontocord 合作创建了训练数据集。它采用 Apache-2.0 许可,可以完全访问源代码、模型权重和训练数据集。该项目的目的是促进开源基础模型的包容性、透明度和稳健性。它擅长执行各种任务,包括上下文中的摘要和问答、信息提取和文本分类。
它在 4300 万条指令大小的训练数据集上训练了 200 亿个参数。它被称为
GPT-NeoXT-Chat-Base-20B
它还有一个基于 ElutherAI 的 Pythia-7B 模型的模型,称为
Pythia-Chat-Base-7B
7B 参数语言模型。
演示:OpenChatKit
您可以在Hugging Face
网站上查看该模型的演示
内存要求:OpenChatKit
Pythia-Chat-Base-7B 可以在具有 12GB RAM 的单个 GPU 上运行。
Python 代码:Pythia-Chat-Base-7B
您可以将 colab notebook 用于
Pythia-Chat-Base-7B
。
# GPU Configuration
!nvidia-smi
# Install conda
!wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && chmod +x Miniconda3-latest-Linux-x86_64.sh && ./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
# Setting up conda environment
!conda install mamba -n base -c conda-forge -y