


文本分析|网络舆情之聚类分析
1 个月前

数据分析
前面有两篇文章分别是关于文本处理中的 词频 和 情感 分析,本篇文章进一步深入分析,主要是文本聚类分析。
数据集还是用之前商城网购评论的 数据集 ,利用DBSCAN算法,聚类分析客户评论内容,把杂乱无章的评论分门别类。
一、导入数据
#导入基础包
import pandas as pd
import numpy as np
import os
import jieba
#读取数据集
df = pd.read_csv('C:/Users/dwh/Downloads/评论数据.csv')
df.head(10)

二、分词处理
这里仍利用jieba对评论文本进行分字处理。
#对评论分词处理
data = df['content'].apply(lambda x:' '.join(jieba.lcut(x)) )
data.head(10)

可以看出评论文本内容,已经被拆分为词语。
# 利用TF-IDF,文本向量转化
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(analyzer='word',
token_pattern=r"(?u)\b\w+\b",
min_df = 5,
max_features=100000,
ngram_range=(1,2))
vec_word = vectorizer.fit(data)
#查看词典
vec_word.vocabulary_
TF-IDF 算法通过分配权重来反映每个词的重要程度,根据权重对一篇文本中的所有词语从高到低进行排序,权重越高说明重要性越高,排在前几位的词就可以作为文本的关键词,所以 TF-IDF 算法可以用来提取关键词。
三、聚类分析
这里主要利用DBSCAN算法,它是一个比较有代表性的基于密度的聚类算法。这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定,同一类别的样本,他们之间紧密相连,在该类别任意样本周围不远处一定有同类别的样本存在。
# 利用DBSCAN算法训练模型
from sklearn.cluster import DBSCAN
tfidf_matrix= vec_word.transform(data)
cluster = DBSCAN(eps=0.90, min_samples=5).fit(tfidf_matrix)
#查看群组个数
len(pd.Series(cluster.labels_).value_counts())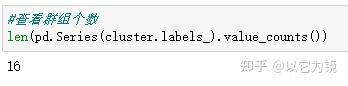
可以看出,模型把评论分为16个群组。
#查看每个群组样本数量
pd.Series(cluster.labels_).value_counts()
# 聚类标签合并到原始数据上
df['labels_'] = cluster.labels_
#查看各评论对应标签
df[['_id', 'content', 'labels_']]

#抽样查看某类标签下评论内容
#查看标签1