思考因果关系
你有没有注意到 YouTube 视频中的那些厨师是如何出色地描述食物的? “减少酱汁,直到达到天鹅绒般的稠度”。如果您刚刚开始学习如何烹饪,您甚至可能都不知道这意味着什么。给我点时间让我娓娓道来!对于因果关系,这是一回事。如果你走进一家酒吧,听到人们讨论因果关系(可能是经济系旁边的一家酒吧),你会听到他们讨论在确认移民对一个社区的影响的时候,收入这个混淆因子如何使得分析变得困难,所以他们不得不使用工具变量。到现在为止,您可能不明白他们在说什么。不过,我现在会开始试图解决一部分问题。
图形模型是因果关系的语言。它们不仅是您用来与其他勇敢而真实的因果关系爱好者交谈的工具,也是您用来使自己的想法更清晰的工具。
让我们以潜在结果的条件独立性为第一个例子来展开讲解。这个条件是我们在进行
因果推断时需要为真的主要假设之一:
条件独立性使我们有可能衡量完全由于干预对结果产生的影响,而不是任何其他潜伏在周围的变量。
一个典型的例子是药物对病人的影响。如果只有重病患者才能服用这种药物,那么服用这种药物甚至可能会降低患者的健康。那是因为严重程度的影响与药物的影响混淆了。但是,如果我们将患者按重症和非重症病例分类,并分析每个子分类小组中的药物影响,我们将更清楚地了解真正的效果是什么。这种按特征拆解样本的方法就是我们所说的对 X 的控制或调节。通过对严重病例进行调节,治疗机制变得和随机一样好。严重组中的患者可能会或可能不会仅仅因为偶然而接受药物,而不是因为高严重性,因为所有患者在这个维度上都是相同的。如果治疗就像在组内随机分配一样,则治疗有条件地独立于潜在结果。
独立性和条件独立性是因果推理的核心。然而,仅仅围绕这些概念展开会让学习很困难。另一方面,如果我们使用正确的语言来描述这个问题,会让困难减轻一点。这就是
因果图模型
的用武之地。因果图模型是一种表示因果关系如何起作用的方式,即是什么导致了什么。
图模型如下所示
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import graphviz as gr
from matplotlib import style
import seaborn as sns
from matplotlib import pyplot as plt
style.use("fivethirtyeight")
g = gr.Digraph()
g.edge("Z", "X")
g.edge("U", "X")
g.edge("U", "Y")
g.edge('Y', 'A')
g.edge('U', 'A')
g.edge("药物", "存活")
g.edge("严重程度", "存活")
g.edge("严重程度", "药物")
每个节点都是一个随机变量。我们使用箭头或边来显示一个变量是否会导致另一个变量的变化。在上面的第一个图形模型中,我们说 Z 导致 X,U 导致 X 和 Y。举一个更具体的例子,我们可以将药物对患者生存影响的想法转化为上面的第二个图形。疾病严重程度会同时导致服药的干预和病人的存活,服药本身也带来病人的存活。正如我们将看到的,这种因果图模型语言将帮助我们更清晰地思考因果关系,因为它明确了我们对世界如何运作的信念。
图模型快速入门
图模型本身可能需要一整个学期的课程。但是,就我们的目的而言,了解图模型需要什么样的独立性和条件独立性假设是(非常)重要的。正如我们将看到的,独立性通过图形模型展开,就像水流过溪流一样。我们可以停止这个流程,也可以启用它,这取决于我们如何处理其中的变量。为了理解这一点,让我们检查一些常见的图形结构和示例。它们非常简单,但这些基本模块足以帮助我们理解图模型上有关独立性和条件独立性的所有内容。
首先,看看这个非常简单的图。 A导致B,B导致C。或者X导致Y导致Z。
g = gr.Digraph()
g.edge("A", "B")
g.edge("B", "C")
g.edge("X", "Y")
g.edge("Y", "Z")
g.node("Y", "Y", color="red")
g.edge("因果推断知识", "解决业务问题")
g.edge("解决业务问题", "职位晋升")
在第一个图中,依赖性沿箭头方向流动。举一个更具体的例子,假设懂得因果推断的知识是解决业务问题的唯一途径,而解决这些问题是获得工作晋升的唯一途径。因此,因果知识导致问题解决,从而导致工作晋升。在这里我们可以说职位晋升依赖于因果知识。因果知识越多,获得晋升的机会就越大。请注意,依赖性是对称的,尽管它不太直观。你升职的机会越大,反过来说明你有因果推断知识的概率就越大,否则就很难升职。
现在,假设我以中间变量为条件。在这种情况下,依赖被阻塞。因此,给定 Y,X 和 Z 是独立的。在上图中,红色表示 Y 是一个条件变量。出于同样的原因,在我们的示例中,如果我知道您擅长解决问题,那么知道您知道因果推理并不会提供有关您获得工作晋升机会的任何进一步信息。在数学上,![E[Promotion|Solve\textit{ questions},Causal\textit{ knowledge}]=E[Promotion|Solve\textit{ questions}]](https://latex.csdn.net/eq?E%5BPromotion%7CSolve%5Ctextit%7B%20questions%7D%2CCausal%5Ctextit%7B%20knowledge%7D%5D%3DE%5BPromotion%7CSolve%5Ctextit%7B%20questions%7D%5D) 。反之亦然,一旦我知道你在解决问题方面有多擅长,了解你的工作晋升状态不会让我进一步了解你知道因果推断的可能性。
。反之亦然,一旦我知道你在解决问题方面有多擅长,了解你的工作晋升状态不会让我进一步了解你知道因果推断的可能性。
作为一般规则,当我们以中间变量 B 为条件时,从 A 到 C 的直接路径中的依赖流被阻塞。或者,
现在,让我们考虑一个分叉结构。在这种情况下,同一个变量会导致图中的其他两个变量。在这种情况下,依赖关系通过箭头向后流动,我们有所谓的后门路径。我们可以通过以共同原因为条件来关闭后门路径并关闭依赖。
g = gr.Digraph()
g.edge("C", "A")
g.edge("C", "B")
g.edge("X", "Y")
g.edge("X", "Z")
g.node("X", "X", color="red")
g.edge("统计学", "因果推断")
g.edge("统计学", "机器学习")
看下面这个例子。假设您对统计学的了解使您对因果推理和机器学习都有了更多的了解。在我不知道你的统计知识水平的情况下,如果知道你擅长因果推理,就能推断更有可能你也擅长机器学习。这是因为,即使我不知道你的统计知识水平,我也可以从你的因果推理知识中推断出来:如果你擅长因果推理,你可能擅长统计学,这也让你更有可能擅长在机器学习方面。
现在,如果我以你对统计学的知识为已知条件,那么你对机器学习的了解程度将与你对因果推理的了解程度无关。你看,知道你的统计水平已经为我提供了推断你的机器学习技能水平所需的所有信息。在这种情况下,了解您的因果推理水平不会提供更多的信息。
作为一般规则,共享一个同一个原因的两个变量是相关的,但当我们以共同原因为条件时它们则是独立的。数学上可以表示为: 和
和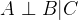
唯一缺少的结构是受冲突因子(collider,有部分中文资料将其直接翻译为对撞机,感觉比较生硬)。当两个箭头在单个变量上相遇,我们就称这种现象为冲突。我们可以说,在这种情况下,两个变量共享一个共同的效果。
g = gr.Digraph()
g.edge("B", "C")
g.edge("A", "C")
g.edge("Y", "X")
g.edge("Z", "X")
g.node("X", "X", color="red")
g.edge("statistics", "job promotion")
g.edge("flatter", "job promotion")
例如,考虑有两种方法可以得到工作晋升。你要么擅长统计,要么奉承你的老板。如果我不以你的职位晋升为条件,也就是说,我不知道你是否会得到或不会得到,那么你的统计和奉承水平是独立的。换句话说,知道你在统计方面有多好,我无法说明你在奉承老板方面有多好。另一方面,如果您确实获得了工作晋升,那么突然之间,了解您的统计数据水平会告诉我您的奉承程度。如果你不擅长统计并且确实得到了晋升,那么你更有可能知道如何奉承,否则你就不会得到晋升。相反,如果你不擅长奉承,那一定是你擅长统计。这种现象有时被称为 explaining away,因为一个原因已经解释了结果,使另一个原因不太可能。
作为一般规则,对碰撞器的调节会打开依赖路径。不调节它会使其关闭。或者 和
和
知道了这三种结构,我们可以推导出更一般的规则。一条路径被阻塞当且仅当:
- 它包含一个被条件化的非冲突因子
- 它包含一个没有被条件化的冲突因子并且没有被条件化的后代。
这是一个关于依赖如何在图中流动的备忘单。我摘自 Mark Paskin 的 斯坦福演讲。尖端带线的箭头表示独立,尖端不带线的箭头表示依赖。
电子邮件:[email protected]
最后更新日期:2020 年 8 月 15 日
这本书是使用 Python 进行因果推断的实用指南。我解释了出现在经济学最负盛名的期刊,如《美丨国经济评论》和《计量经济学》中的方法和技术。
我不假设任何技术背景,但我建议您熟悉我之前的书中的概念:P
主题状态最新版本
Python Version master分支构建生成分支生成文档生成主题状态最新版本
Python Version master分支构建分支生成文档生成什么是CausalNex?
“使用贝叶斯网络进行
因果推理的工具包。”
CausalNex旨在成为使用贝叶斯网络进行
因果推理和“假设分析”的领先库之一。
它有助于简化步骤:学习
因果结构,允许领域专家扩大关系,估计潜在影响
结构因果模型
一个实现结构因果模型(SCM)的Python包。
该软件包使从结构因果模型到图形的转换成为可能。 也可以直接从系数矩阵(即图的加权邻接矩阵)生成线性结构因果模型。
“图形”对象是通过提供一个邻接矩阵(和一个名称,可选)来定义的。 它们包含并维护图形的不同表示形式,视情况而定,这些表示形式可能会很有用,并且提供了从任何一种表示形式转换为任何其他表示形式的工具。
当前实现的表示为:
通过邻接矩阵,
通过邻接表,
通过边缘(“类型化”边缘:无边缘,向前,向后或无向边缘)。
Python中有几种方法可以进行因果推断。以下是其中的一些方法:
1. 回归分析:使用回归模型来估计因果关系。通过建立一个因变量和一个或多个自变量之间的回归模型,可以分析它们之间的因果关系。
2. 实验设计:通过随机分配实验组和对照组,控制其他变量的影响,来观察因果关系。Python中可以使用statsmodels或scikit-learn库来进行实验设计和分析。
3. 因果推断库:一些Python库专门用于因果推断分析,例如CausalImpact和DoWhy。这些库提供了因果推断方法的实现,可以帮助用户评估因果关系。
4. 因果图模型:使用因果图模型来表示和推断变量之间的因果关系。Python中的pgmpy库提供了用于构建和分析因果图模型的工具。
这些方法都可以在Python中进行实现,并根据具体问题选择合适的方法来进行因果推断分析。

