

本文为您介绍如何使用MySQL连接器。
背景信息
MySQL连接器支持所有兼容MySQL协议的数据库,包括RDS MySQL、PolarDB for MySQL、OceanBase(MySQL模式)或者自建MySQL。
重要
-
建议使用本连接器,而不要采用RDS MySQL连接器,后续我们将下线连接器中的云数据库RDS MySQL版文档。
-
支持使用MySQL连接器读取OceanBase。使用MySQL连接器读取OceanBase时,请确保OceanBase Binlog已开启且被正确设置,详情请参见 Binlog 相关操作 。使用MySQL连接器读取OceanBase Binlog目前处于公测阶段,请在使用前充分评估并谨慎使用。
MySQL连接器支持的信息如下。
|
类别 |
详情 |
|
支持类型 |
源表、维表和结果表,数据摄入数据源 |
|
运行模式 |
仅支持流模式 |
|
数据格式 |
暂不适用 |
|
特有监控指标 |
说明
指标含义详情,请参见 监控指标说明 。 |
|
API种类 |
Datastream,SQL和数据摄入YAML |
|
是否支持更新或删除结果表数据 |
是 |
特色功能
MySQL的CDC源表,即MySQL的流式源表,会先读取数据库的历史全量数据,并平滑切换到Binlog读取上,保证不多读一条也不少读一条数据。即使发生故障,也能保证通过Exactly Once语义处理数据。MySQL CDC源表支持并发地读取全量数据,通过增量快照算法实现了全程无锁和断点续传,详情可参见 关于MySQL CDC源表 。
作为源表,支持以下功能特性。
-
流批一体,支持读取全量和增量数据,无需维护两套流程。
-
支持并发读取全量数据,性能水平扩展。
-
全量读取无缝切换增量读取,自动缩容,节省计算资源。
-
全量阶段读取支持断点续传,更稳定。
-
无锁读取全量数据,不影响在线业务。
-
支持读取RDS MySQL的备份日志。
-
并行解析Binlog文件,读取延迟更低。
前提条件
-
CDC源表和数据摄入数据源
在使用MySQL CDC源表前,必须先按照 配置MySQL 进行操作,这些操作主要为了满足使用MySQL CDC源表的前提条件:
-
MySQL和VVP的网络连通。
-
MySQL服务器配置要求:
-
MySQL版本为5.6,5.7或8.0.x。
-
已开启了Binlog。
-
Binlog格式已设置为ROW。
-
binlog_row_image已设置为FULL。
-
-
已在MySQL配置文件中配置了交互超时或等待超时参数。
-
已创建MySQL用户,并授予了SELECT、SHOW DATABASES、REPLICATION SLAVE和REPLICATION CLIENT权限。
-
-
维表和结果表
-
已创建MySQL数据库和表,详情请参见 RDS MySQL创建数据库和账号 、 PolarDB MySQL创建数据库和账号 或 自建MySQL创建数据库和账号 。
-
已设置IP白名单,详情请参见 RDS MySQL白名单设置 、 PolarDB MySQL白名单设置 或 自建MySQL白名单设置 。
-
使用限制
-
CDC源表和数据摄入数据源
-
仅VVR 4.0.8及以上引擎版本支持无锁读取和并发读取功能。
-
请根据MySQL版本选择合适的引擎版本,MySQL版本支持情况如下表所示。
您可以通过执行 select version() 命令来查看MySQL的版本。
VVR版本
支持的MySQL版本
VVR 4.0.8 ~ VVR 4.0.10
5.7
8.0.x
VVR 4.0.11及以上版本
5.6.x
5.7.x
8.0.x
重要为了确保RDS MySQL 5.6.x版本的正常运行,默认已开启增量快照功能(即scan.incremental.snapshot.enabled=true),且不支持关闭增量快照功能,而RDS MySQL 6.0.8和8.0.1版本的数据库已解除该限制,即支持关闭增量快照功能。建议您不要关闭增量快照功能,因为关闭增量快照功能会锁定MySQL数据库,可能会对线上业务处理性能产生影响。
-
MySQL CDC源表暂不支持定义Watermark。
-
MySQL的CDC源表需要一个有特定权限(包括SELECT、SHOW DATABASES、REPLICATION SLAVE和REPLICATION CLIENT)的MySQL用户,才能读取全量和增量数据。
-
当结合CTAS和CDAS整库同步语法使用时,MySQL CDC源表可以同步部分Schema变更,支持的变更类型详情请参见 表结构变更同步策略 。在其他使用场景下,MySQL CDC源表无法同步Schema变更操作。
-
MySQL CDC源表无法同步Truncate操作。
-
对于RDS MySQL,不建议通过备库或只读从库读取数据。因为RDS MySQL的备库和只读从库Binlog保留时间默认很短,可能由于Binlog过期清理,导致作业无法消费Binlog数据而报错。
-
MySQL CDC源表不支持读取PolarDB MySQL版1.0.19及以前版本的多主架构集群( 什么是多主集群? )。PolarDB MySQL版1.0.19及以前版本的多主架构集群产生的Binlog可能出现重复Table id,导致CDC源表Schema映射错误,从而解析Binlog数据报错。PolarDB MySQL版在高于1.0.19的版本进行适配,保证Binlog内Table id不会出现重复,从而避免解析报错。
-
-
维表和结果表
-
Flink计算引擎VVR 4.0.11及以上版本支持MySQL连接器。
-
语义上可以保证At-Least-Once,在结果表有主键的情况下,幂等可以保证数据的正确性。
-
注意事项
-
CDC源表和数据摄入数据源
-
每个MySQL CDC数据源需显式配置不同的Server ID。
-
Server ID作用
每个同步数据库数据的客户端,都会有一个唯一ID,即Server ID。MySQL SERVER会根据该ID来维护网络连接以及Binlog位点。因此如果有大量不同的Server ID的客户端一起连接MySQL SERVER,可能导致MySQL SERVER的CPU陡增,影响线上业务稳定性。
此外,如果多个MySQL CDC数据源共享相同的Server ID,且数据源之间无法复用时,会导致Binlog位点错乱,多读或少读数据。还可能出现Server ID冲突的报错,详情请参见 上下游存储 。因此建议每个MySQL CDC数据源都配置不同的Server ID。
-
Server ID配置方式
Server ID可以在DDL中指定,也可以通过动态Hints配置。
建议通过动态Hints来配置Server ID,而不是在DDL参数中配置Server ID。动态Hints详情请参见 动态Hints 。
-
不同场景下Server ID的配置
-
未开启增量快照框架或并行度为1
当未开启增量快照框架或并行度为1时,可以指定一个特定的Server ID。
SELECT * FROM source_table /*+ OPTIONS('server-id'='123456') */ ; -
开启增量快照框架且并行度大于1
当开启增量快照框架且并行度大于1时,需要指定Server ID范围,要保证范围内可用的Server ID数量不小于并行度。假设并行度为3,可以如下配置:
SELECT * FROM source_table /*+ OPTIONS('server-id'='123456-123458') */ ; -
结合CTAS进行数据同步
当结合CTAS进行数据同步时,如果CDC数据源配置相同,会自动对数据源进行复用,此时可以为多个CDC数据源配置相同的Server ID。详情请参见 代码示例四:多CTAS语句 。
-
同一作业包含多个MySQL CDC源表(非CTAS)
当作业中包含多个MySQL CDC源表,且不是使用CTAS语句同步时,数据源无法进行复用,需要为每一个CDC源表提供不同的Server ID。同理,如果开启增量快照框架且并行度大于1,需要指定Server ID范围。
select * from source_table1 /*+ OPTIONS('server-id'='123456-123457') */ left join source_table2 /*+ OPTIONS('server-id'='123458-123459') */ on source_table1.id=source_table2.id;
-
-
-
仅VVR 4.0.8及以上版本支持全量阶段的无锁读取、并发读取、断点续传等功能。
如果您使用的是VVR 4.0.8以下版本,需要对MySQL用户授予RELOAD权限用来获取全局读锁,保证数据读取的一致性。全局读锁会阻塞写入操作,持锁时间可能达到秒级,因此可能对线上业务造成影响。
此外,VVR 4.0.8以下版本在全量读取阶段无法执行Checkpoint,全量阶段的作业失败会导致作业重新读取全量数据,稳定性不佳。因此建议您将作业升级到VVR 4.0.8及以上版本。
-
-
结果表
-
RDS MySQL数据库支持自增主键,因此在结果表的DDL中不声明该自增字段。例如ID是自增字段,Flink DDL不声明该自增字段,则数据库在一行数据写入过程中会自动填补相关自增字段。
-
结果表的DDL声明的字段必须至少存在一个非主键的字段,否则产生报错。
-
结果表的DDL中NOT ENFORCED表示Flink自身对主键不做强制校验,需要您自行保证主键的正确性和完整性。
Flink并不充分支持强制校验,Flink将假设列的可为空性与主键中的列是对齐的,从而认为主键是正确的,详情请参见 Validity Check 。
-
-
维表
如果做维表时希望使用索引查询,请按照MySQL最左前缀原则排列JOIN指定的数据列。但这并无法保证使用索引,由于SQL优化,某些条件可能会被优化导致连接器得到的过滤条件无法命中索引。要确定连接器是否真正使用了索引进行查询,可以在数据库侧查看具体执行的Select语句。
SQL
MySQL连接器可以在SQL作业中使用,作为源表,维表或者结果表。
语法结构
CREATE TABLE mysqlcdc_source (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '<yourHostname>',
'port' = '3306',
'username' = '<yourUsername>',
'password' = '<yourPassword>',
'database-name' = '<yourDatabaseName>',
'table-name' = '<yourTableName>'
);
说明
-
连接器写入结果表原理:写入结果表时,会将接收到的每条数据拼接成一条SQL去执行。具体执行的SQL情况如下:
-
对于没有主键的结果表,会拼接执行
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);语句。 -
对于包含主键的结果表,会拼接执行
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...) ON DUPLICATE KEY UPDATE column1 = VALUES(column1), column2 = VALUES(column2), ...;语句。请注意:如果物理表存在除主键外的唯一索引约束,当插入两条主键不同但唯一索引相同的记录时,下游数据会因为唯一索引冲突导致数据覆盖引发数据丢失。
-
-
如果在MySQL数据库定义了自增主键,在Flink DDL中不应该声明该自增字段。数据写入过程中,数据库会自动填补该自增字段。连接器仅支持写入和删除带自增字段的数据,不支持更新。
WITH参数
-
通用
参数
说明
是否必填
数据类型
默认值
备注
connector
表类型。
是
STRING
无
作为源表时,可以填写为
mysql-cdc或者mysql,二者等价。作为维表或结果表时,固定值为mysql。hostname
MySQL数据库的IP地址或者Hostname。
是
STRING
无
建议填写专有网络VPC地址。
说明如果MySQL与Flink全托管不在同一VPC,需要先打通跨VPC的网络或者使用公网的形式访问,详情请参见 如何访问跨VPC的其他服务? 和 Flink全托管集群如何访问公网? 。
username
MySQL数据库服务的用户名。
是
STRING
无
无。
password
MySQL数据库服务的密码。
是
STRING
无
无。
database-name
MySQL数据库名称。
是
STRING
无
-
作为源表时,数据库名称支持正则表达式以读取多个数据库的数据。
-
使用正则表达式时,尽量不要使用 ^ 和 $ 符号匹配开头和结尾。具体原因详见 table-name 备注的说明。
table-name
MySQL表名。
是
STRING
无
-
作为源表时,表名支持正则表达式以读取多个表的数据。
在读取多个MySQL表时,将多个CTAS语句作为一个作业提交,可以避免启用多个Binlog监听,提高性能和效率。详情请参见 示例四:多个CTAS语句作为一个作业提交 。
-
使用正则表达式时,尽量不要使用 ^ 和 $ 符号匹配开头和结尾。具体原因详见以下说明。
说明MySQL CDC源表在正则匹配表名时,会将您填写的 database-name , table-name 通过字符串 \\. (VVR 8.0.1前使用字符 . )连接成为一个全路径的正则表达式,然后使用该正则表达式和MySQL数据库中表的全限定名进行正则匹配。
例如:当配置'database-name'='db_.*'且'table-name'='tb_.+'时,连接器将会使用正则表达式 db_.*\\.tb_.+ (8.0.1版本前为 db_.*.tb_.+ )去匹配表的全限定名来确定需要读取的表。
port
MySQL数据库服务的端口号。
否
INTEGER
3306
无。
-
-
源表独有
参数
说明
是否必填
数据类型
默认值
备注
server-id
数据库客户端的一个数字ID。
否
STRING
默认会随机生成一个5400~6400的值。
该ID必须是MySQL集群中全局唯一的。建议针对同一个数据库的每个作业都设置一个不同的ID。
该参数也支持ID范围的格式,例如5400-5408。在开启增量读取模式时支持多并发读取,此时推荐设定为ID范围,使得每个并发使用不同的ID。
scan.incremental.snapshot.enabled
是否开启增量快照。
否
BOOLEAN
true
默认开启增量快照。增量快照是一种读取全量数据快照的新机制。与旧的快照读取相比,增量快照有很多优点,包括:
-
读取全量数据时,Source可以是并行读取。
-
读取全量数据时,Source支持chunk粒度的检查点。
-
读取全量数据时,Source不需要获取全局读锁(FLUSH TABLES WITH read lock)。
如果您希望Source支持并发读取,每个并发的Reader需要有一个唯一的服务器ID,因此server-id必须是5400-6400这样的范围,并且范围必须大于等于并发数。
scan.incremental.snapshot.chunk.size
每个chunk的大小(包含的行数)。
否
INTEGER
8096
当开启增量快照读取时,表会被切分成多个chunk读取。在读完chunk的数据之前,chunk的数据会先缓存在内存中。
每个chunk包含的行数越少,则表中的chunk的总数量越大,尽管这会降低故障恢复的粒度,但可能导致内存OOM和整体的吞吐量降低。因此,您需要进行权衡,并设置合理的chunk大小。
scan.snapshot.fetch.size
当读取表的全量数据时,每次最多拉取的记录数。
否
INTEGER
1024
无。
scan.startup.mode
消费数据时的启动模式。
否
STRING
initial
参数取值如下:
-
initial (默认):在第一次启动时,会先扫描历史全量数据,然后读取最新的Binlog数据。
-
latest-offset :在第一次启动时,不会扫描历史全量数据,直接从Binlog的末尾(最新的Binlog处)开始读取,即只读取该连接器启动以后的最新变更。
-
earliest-offset :不扫描历史全量数据,直接从可读取的最早Binlog开始读取。
-
specific-offset :不扫描历史全量数据,从您指定的Binlog位点启动,位点可通过同时配置 scan.startup.specific-offset.file 和 scan.startup.specific-offset.pos 参数来指定从特定Binlog文件名和偏移量启动,也可以只配置 scan.startup.specific-offset.gtid-set 来指定从某个GTID集合启动。
-
timestamp :不扫描历史全量数据,从指定的时间戳开始读取Binlog。时间戳通过 scan.startup.timestamp-millis 指定,单位为毫秒。
重要-
earliest-offset , specific-offset 和 timestamp 启动模式在Flink计算引擎VVR 6.0.4及以上的版本支持使用。
-
对于 earliest-offset , specific-offset 和 timestamp 启动模式,如果启动时刻和指定的启动位点时刻的表结构不同,作业会因为表结构不同而报错。换一句话说,使用这三种启动模式,需要保证在指定的Binlog消费位置到作业启动的时间之间,对应表不能发生表结构变更。
scan.startup.specific-offset.file
使用指定位点模式启动时,启动位点的Binlog文件名。
否
STRING
无
使用该配置时, scan.startup.mode 必须配置为 specific-offset 。文件名格式例如
mysql-bin.000003。scan.startup.specific-offset.pos
使用指定位点模式启动时,启动位点在指定Binlog文件中的偏移量。
否
INTEGER
无
使用该配置时, scan.startup.mode 必须配置为 specific-offset 。
scan.startup.specific-offset.gtid-set
使用指定位点模式启动时,启动位点的GTID集合。
否
STRING
无
使用该配置时, scan.startup.mode 必须配置为 specific-offset 。GTID集合格式例如
24DA167-0C0C-11E8-8442-00059A3C7B00:1-19。scan.startup.timestamp-millis
使用指定时间模式启动时,启动位点的毫秒时间戳。
否
LONG
无
使用该配置时, scan.startup.mode 必须配置为 timestamp 。时间戳单位为毫秒。
重要在使用指定时间时,MySQL CDC会尝试读取每个Binlog文件的初始事件以确定其时间戳,最终定位至指定时间对应的Binlog文件。请保证指定的时间戳对应的Binlog文件在数据库上没有被清理且可以被读取到。
server-time-zone
数据库在使用的会话时区。
VVR-6.0.2以下版本必填,其他版本选填
STRING
如果您没有指定该参数,则系统默认使用Flink作业运行时的环境时区作为数据库服务器时区,即您选择的可用区所在的时区。
例如Asia/Shanghai,该参数控制了MySQL中的TIMESTAMP类型如何转成STRING类型。更多信息请参见 Debezium时间类型 。
debezium.min.row.count.to.stream.results
当表的条数大于该值时,会使用分批读取模式。
否
INTEGER
1000
Flink采用以下方式读取MySQL源表数据:
-
全量读取:直接将整个表的数据读取到内存里。优点是速度快,缺点是会消耗对应大小的内存,如果源表数据量非常大,可能会有OOM风险。
-
分批读取:分多次读取,每次读取一定数量的行数,直到读取完所有数据。优点是读取数据量比较大的表没有OOM风险,缺点是读取速度相对较慢。
connect.timeout
连接MySQL数据库服务器超时时,重试连接之前等待超时的最长时间。
否
DURATION
30s
无。
connect.max-retries
连接MySQL数据库服务时,连接失败后重试的最大次数。
否
INTEGER
3
无。
connection.pool.size
数据库连接池大小。
否
INTEGER
20
数据库连接池用于复用连接,可以降低数据库连接数量。
jdbc.properties.*
JDBC URL中的自定义连接参数。
否
STRING
无
您可以传递自定义的连接参数,例如不使用SSL协议,则可配置为 'jdbc.properties.useSSL' = 'false' 。
支持的连接参数请参见 MySQL Configuration Properties 。
debezium.*
Debezium读取Binlog的自定义参数。
否
STRING
无
您可以传递自定义的Debezium参数,例如使用'debezium.event.deserialization.failure.handling.mode'='ignore'来指定解析错误时的处理逻辑。
heartbeat.interval
Source通过心跳事件推动Binlog位点前进的时间间隔。
否
DURATION
30s
心跳事件用于推动Source中的Binlog位点前进,这对MySQL中更新缓慢的表非常有用。对于更新缓慢的表,Binlog位点无法自动前进,通过够心跳事件可以推到Binlog位点前进,可以避免Binlog位点不前进引起Binlog位点过期问题,Binlog位点过期会导致作业失败无法恢复,只能无状态重启。
scan.incremental.snapshot.chunk.key-column
可以指定某一列作为快照阶段切分分片的切分列。
见备注列。
STRING
无
-
无主键表必填,选择的列必须是非空类型(NOT NULL)。
-
有主键的表为选填,仅支持从主键中选择一列。
说明仅Flink计算引擎VVR 6.0.7及以上版本支持。
rds.region-id
阿里云RDS MySQL实例所在的地域ID。
使用读取OSS归档日志功能时必填。
STRING
无
-
仅Flink计算引擎VVR 6.0.7及以上版本支持。
-
地域ID请参见 地域和可用区 。
rds.access-key-id
阿里云RDS MySQL账号Access Key ID。
使用读取OSS归档日志功能时必填。
STRING
无
详情请参见 如何查看AccessKey ID和AccessKey Secret信息?
重要-
仅Flink计算引擎VVR 6.0.7及以上版本支持。
-
为了避免您的AK信息泄露,建议您通过密钥管理的方式填写AccessKey ID取值,详情请参见 变量管理 。
rds.access-key-secret
阿里云RDS MySQL账号Access Key Secret。
使用读取OSS归档日志功能时必填。
STRING
无
详情请参见 如何查看AccessKey ID和AccessKey Secret信息?
重要-
仅Flink计算引擎VVR 6.0.7及以上版本支持。
-
为了避免您的AK信息泄露,建议您通过密钥管理的方式填写AccessKey Secret取值,详情请参见 变量管理 。
rds.db-instance-id
阿里云RDS MySQL实例ID。
使用读取OSS归档日志功能时必填。
STRING
无
仅Flink计算引擎VVR 6.0.7及以上版本支持。
rds.main-db-id
阿里云RDS MySQL实例主库编号。
否
STRING
无
-
获取主库编号详情请参见 RDS MySQL日志备份 。
-
仅Flink计算引擎VVR 8.0.7及以上版本支持。
rds.download.timeout
从OSS下载单个归档日志的超时时间。
否
DURATION
60s
仅Flink计算引擎VVR 6.0.7及以上版本支持。
rds.endpoint
获取OSS Binlog信息的服务接入点。
否
STRING
无
-
可选值详情请参见 服务接入点 。
-
仅Flink计算引擎VVR 8.0.8及以上版本支持。
scan.incremental.close-idle-reader.enabled
是否在快照结束后关闭空闲的 Reader。
否
BOOLEAN
false
-
仅Flink计算引擎VVR 8.0.1及以上版本支持。
-
该配置生效需要设置execution.checkpointing.checkpoints-after-tasks-finish.enabled为true。
scan.read-changelog-as-append-only.enabled
是否将changelog数据流转换为append-only数据流。
否
BOOLEAN
false
参数取值如下:
-
true :所有类型的消息(包括INSERT、DELETE、UPDATE_BEFORE、UPDATE_AFTER)都会转换成INSERT类型的消息。仅在需要保存上游表删除消息等特殊场景下开启使用。
-
false (默认):所有类型的消息都保持原样下发。
说明仅Flink计算引擎VVR 8.0.8及以上版本支持。
scan.only.deserialize.captured.tables.changelog.enabled
在增量阶段,是否仅对指定表的变更事件进行反序列化。
否
BOOLEAN
false
参数取值如下:
-
true :仅对目标表的变更数据进行反序列化,加快Binlog读取速度。
-
false (默认):对所有表的变更数据进行反序列化。
说明-
仅Flink计算引擎VVR 8.0.7及以上版本支持。
-
在Flink计算引擎VVR 8.0.8及以下版本使用时,参数名需要修改为 debezium.scan.only.deserialize.captured.tables.changelog.enable 。
scan.parallel-deserialize-changelog.enabled
在增量阶段,是否使用多线程对变更事件进行解析。
否
BOOLEAN
false
参数取值如下:
-
true :在变更事件的反序列化阶段采用多线程处理,同时保证Binlog事件顺序不变,从而加快读取速度。
-
false (默认):在事件的反序列化阶段使用单线程处理。
说明仅Flink计算引擎VVR 8.0.7及以上版本支持。
-
-
维表独有
参数
说明
是否必填
数据类型
默认值
备注
url
MySQL JDBC URL
否
STRING
无
URL的格式为:
jdbc:mysql://<连接地址>:<端口号>/<数据库名称>。lookup.max-retries
读取数据失败后,重试读取的最大次数。
否
INTEGER
3
仅Flink计算引擎VVR 6.0.7及以上版本支持。
lookup.cache.strategy
缓存策略。
否
STRING
None
支持None、LRU和ALL三种缓存策略,取值含义详情请参见 背景信息 。
说明使用LRU缓存策略时,还必须配置 lookup.cache.max-rows 参数。
lookup.cache.max-rows
最大缓存条数。
否
INTEGER
100000
-
当选择LRU缓存策略后,必须设置缓存大小。
-
当选择ALL缓存策略后,可以不设置缓存大小。
lookup.cache.ttl
缓存超时时间。
否
DURATION
10 s
lookup.cache.ttl 的配置和 lookup.cache.strategy 有关,详情如下:
-
如果 lookup.cache.strategy 配置为 None ,则 lookup.cache.ttl 可以不配置,表示缓存不超时。
-
如果 lookup.cache.strategy 配置为 LRU ,则 lookup.cache.ttl 为缓存超时时间。默认不过期。
-
如果 lookup.cache.strategy 配置为 ALL ,则 lookup.cache.ttl 为缓存加载时间。默认不重新加载。
填写时请使用时间格式,例如1min或10s。
lookup.max-join-rows
主表中每一条数据查询维表时,匹配后最多返回的结果数。
否
INTEGER
1024
在Flink计算引擎VVR 6.0.7及以上版本支持。
lookup.filter-push-down.enabled
是否开启维表Filter下推。
否
BOOLEAN
false
参数取值如下:
-
true :开启维表Filter下推,在加载MySQL数据库表的数据时,维表会根据SQL作业中设置的条件提前过滤数据。
-
false (默认):不开启维表Filter下推,在加载MySQL数据库表的数据时,维表会加载全量数据。
说明仅Flink计算引擎VVR 8.0.7及以上版本支持。
重要维表下推应该仅在Flink表用作维表时开启。MySQL源表暂不支持开启Filter下推,如果一张Flink表同时被作为源表和维表,且维表开启了Filter下推,则在使用源表处需要通过 SQL Hints 的方式将该配置项显式设为false,否则可能导致作业运行异常。
-
-
结果表独有
参数
说明
是否必填
数据类型
默认值
备注
url
MySQL JDBC URL
否
STRING
无
URL的格式为:
jdbc:mysql://<连接地址>:<端口号>/<数据库名称>。sink.max-retries
写入数据失败后,重试写入的最大次数。
否
INTEGER
3
无。
sink.buffer-flush.batch-size
一次批量写入的条数。
否
INTEGER
4096
在Flink计算引擎VVR 6.0.7及以上版本支持。
sink.buffer-flush.max-rows
内存中缓存的数据条数。
否
INTEGER
-
在Flink计算引擎VVR 6.0.7版本以下,该参数默认值为100。
-
在Flink计算引擎VVR 6.0.7版本及以上版本,该参数默认值为10000。
需指定主键后,该参数才生效。
sink.buffer-flush.interval
清空缓存的时间间隔。表示如果缓存中的数据在等待指定时间后,依然没有达到输出条件,系统会自动输出缓存中的所有数据。
否
DURATION
1s
无。
sink.ignore-delete
是否忽略数据Delete操作。
否
BOOLEAN
false
-
在Flink计算引擎VVR 6.0.7及以上版本支持。
-
Flink SQL可能会生成数据Delete操作,在多个输出节点根据主键同时更新同一张结果表的不同字段的场景下,可能导致数据结果不正确。
例如一个任务在删除了一条数据后,另一个任务又只更新了这条数据的部分字段,其余未被更新的字段由于被删除,其值会变成null或默认值。通过将sink.ignore-delete设置为true,可以避免数据删除操作。
sink.ignore-null-when-update
更新数据时,如果传入的数据字段值为null,是更新对应字段为null,还是跳过该字段的更新。
否
BOOLEAN
false
参数取值如下:
-
true:不更新该字段。但是当Flink表设置主键时,才支持配置该参数为true。配置为true时:
-
如果是8.0.6及以下的版本,结果表写入数据不支持攒批执行。
-
如果是8.0.7及以上的版本,结果表写入数据支持攒批执行。
攒批写入虽然可以明显增强写入效率和整体吞吐量,但是会带来数据延迟问题和内存溢出风险。因此请您根据实际业务场景做好权衡。
-
-
false:更新该字段为null。
说明仅实时计算引擎VVR 8.0.5及以上版本支持该参数。
-
类型映射
-
CDC源表
MySQL CDC字段类型
Flink字段类型
TINYINT
TINYINT
SMALLINT
SMALLINT
TINYINT UNSIGNED
TINYINT UNSIGNED ZEROFILL
INT
INT
MEDIUMINT
SMALLINT UNSIGNED
SMALLINT UNSIGNED ZEROFILL
BIGINT
BIGINT
INT UNSIGNED
INT UNSIGNED ZEROFILL
MEDIUMINT UNSIGNED
MEDIUMINT UNSIGNED ZEROFILL
BIGINT UNSIGNED
DECIMAL(20, 0)
BIGINT UNSIGNED ZEROFILL
SERIAL
FLOAT [UNSIGNED] [ZEROFILL]
FLOAT
DOUBLE [UNSIGNED] [ZEROFILL]
DOUBLE
DOUBLE PRECISION [UNSIGNED] [ZEROFILL]
REAL [UNSIGNED] [ZEROFILL]
NUMERIC(p, s) [UNSIGNED] [ZEROFILL]
DECIMAL(p, s)
DECIMAL(p, s) [UNSIGNED] [ZEROFILL]
BOOLEAN
BOOLEAN
TINYINT(1)
DATE
DATE
TIME [(p)]
TIME [(p)] [WITHOUT TIME ZONE]
DATETIME [(p)]
TIMESTAMP [(p)] [WITHOUT TIME ZONE]
TIMESTAMP [(p)]
TIMESTAMP [(p)]
TIMESTAMP [(p)] WITH LOCAL TIME ZONE
CHAR(n)
STRING
VARCHAR(n)
TEXT
BINARY
BYTES
VARBINARY
BLOB
重要建议MySQL不要使用TINYINT(1)类型存储0和1以外的数值,当 property-version =0时,默认MySQL CDC源表会将TINYINT(1)映射到Flink的BOOLEAN上,造成数据不准确。如果需要使用TINYINT(1)类型存储0和1以外的数值,请参见 MySQL Catalog参数配置 。
-
维表和结果表
MySQL字段类型
Flink字段类型
TINYINT
TINYINT
SMALLINT
SMALLINT
TINYINT UNSIGNED
INT
INT
MEDIUMINT
SMALLINT UNSIGNED
BIGINT
BIGINT
INT UNSIGNED
BIGINT UNSIGNED
DECIMAL(20, 0)
FLOAT
FLOAT
DOUBLE
DOUBLE
DOUBLE PRECISION
NUMERIC(p, s)
DECIMAL(p, s)
说明其中p <= 38。
DECIMAL(p, s)
BOOLEAN
BOOLEAN
TINYINT(1)
DATE
DATE
TIME [(p)]
TIME [(p)] [WITHOUT TIME ZONE]
DATETIME [(p)]
TIMESTAMP [(p)] [WITHOUT TIME ZONE]
TIMESTAMP [(p)]
CHAR(n)
CHAR(n)
VARCHAR(n)
VARCHAR(n)
BIT(n)
BINARY(⌈n/8⌉)
BINARY(n)
BINARY(n)
VARBINARY(N)
VARBINARY(N)
TINYTEXT
STRING
TEXT
MEDIUMTEXT
LONGTEXT
TINYBLOB
BYTES
重要Flink仅支持小于等于2,147,483,647(2^31 - 1)的MySQL BLOB类型的记录。
BLOB
MEDIUMBLOB
LONGBLOB
数据摄入
MySQL连接器作为数据源可以在数据摄入YAML作业中使用。
语法结构
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: <username>
password: <password>
tables: adb.\.*, bdb.user_table_[0-9]+, [app|web].order_\.*
server-id: 5401-5404
sink:
type: xxx配置项
|
参数 |
说明 |
是否必填 |
数据类型 |
默认值 |
备注 |
|
type |
数据源类型。 |
是 |
STRING |
无 |
固定值为mysql。 |
|
name |
数据源名称。 |
否 |
STRING |
无 |
无。 |
|
hostname |
MySQL数据库的IP地址或者Hostname。 |
是 |
STRING |
无 |
建议填写专有网络VPC地址。
说明
如果MySQL与Flink全托管不在同一VPC,需要先打通跨VPC的网络或者使用公网的形式访问,详情请参见 如何访问跨VPC的其他服务? 和 Flink全托管集群如何访问公网? 。 |
|
username |
MySQL数据库服务的用户名。 |
是 |
STRING |
无 |
无。 |
|
password |
MySQL数据库服务的密码。 |
是 |
STRING |
无 |
无。 |
|
tables |
需要同步的MySQL数据表。 |
是 |
STRING |
无 |
说明
点号用于分割数据库名和表名,如果需要用点号匹配任意字符,需要对点号使用反斜杠进行转译。如:db0.\.*, db1.user_table_[0-9]+, db[1-2].[app|web]order_\.*。 |
|
tables.exclude |
需要在同步的表中排除的表。 |
否 |
STRING |
无 |
说明
点号用于分割数据库名和表名,如果需要用点号匹配任意字符,需要对点号使用反斜杠进行转译。如:db0.\.*, db1.user_table_[0-9]+, db[1-2].[app|web]order_\.*。 |
|
port |
MySQL数据库服务的端口号。 |
否 |
INTEGER |
3306 |
无。 |
|
schema-change.enabled |
是否发送Schame变更事件。 |
否 |
BOOLEAN |
true |
无。 |
|
server-id |
数据库客户端的用于同步的数字ID或范围。 |
否 |
STRING |
默认会随机生成一个5400~6400的值。 |
该ID必须是MySQL集群中全局唯一的。建议针对同一个数据库的每个作业都设置一个不同的ID。 该参数也支持ID范围的格式,例如5400-5408。在开启增量读取模式时支持多并发读取,此时推荐设定为ID范围,使得每个并发使用不同的ID。 |
|
jdbc.properties.* |
JDBC URL中的自定义连接参数。 |
否 |
STRING |
无 |
您可以传递自定义的连接参数,例如不使用SSL协议,则可配置为 'jdbc.properties.useSSL' = 'false' 。 支持的连接参数请参见 MySQL Configuration Properties 。 |
|
debezium.* |
Debezium读取Binlog的自定义参数。 |
否 |
STRING |
无 |
您可以传递自定义的Debezium参数,例如使用'debezium.event.deserialization.failure.handling.mode'='ignore'来指定解析错误时的处理逻辑。 |
|
scan.incremental.snapshot.chunk.size |
每个chunk的大小(包含的行数)。 |
否 |
INTEGER |
8096 |
MySQL表会被切分成多个chunk读取。在读完chunk的数据之前,chunk的数据会先缓存在内存中。 每个chunk包含的行数越少,则表中的chunk的总数量越大,尽管这会降低故障恢复的粒度,但可能导致内存OOM和整体的吞吐量降低。因此,您需要进行权衡,并设置合理的chunk大小。 |
|
scan.snapshot.fetch.size |
当读取表的全量数据时,每次最多拉取的记录数。 |
否 |
INTEGER |
1024 |
无。 |
|
scan.startup.mode |
消费数据时的启动模式。 |
否 |
STRING |
initial |
参数取值如下:
重要
对于 earliest-offset , specific-offset 和 timestamp 启动模式,如果启动时刻和指定的启动位点时刻的表结构不同,作业会因为表结构不同而报错。换一句话说,使用这三种启动模式,需要保证在指定的Binlog消费位置到作业启动的时间之间,对应表不能发生表结构变更。 |
|
scan.startup.specific-offset.file |
使用指定位点模式启动时,启动位点的Binlog文件名。 |
否 |
STRING |
无 |
使用该配置时,
scan.startup.mode
必须配置为
specific-offset
。文件名格式例如
|
|
scan.startup.specific-offset.pos |
使用指定位点模式启动时,启动位点在指定Binlog文件中的偏移量。 |
否 |
INTEGER |
无 |
使用该配置时, scan.startup.mode 必须配置为 specific-offset 。 |
|
scan.startup.specific-offset.gtid-set |
使用指定位点模式启动时,启动位点的GTID集合。 |
否 |
STRING |
无 |
使用该配置时,
scan.startup.mode
必须配置为
specific-offset
。GTID集合格式例如
|
|
scan.startup.timestamp-millis |
使用指定时间模式启动时,启动位点的毫秒时间戳。 |
否 |
LONG |
无 |
使用该配置时, scan.startup.mode 必须配置为 timestamp 。时间戳单位为毫秒。
重要
在使用指定时间时,MySQL CDC会尝试读取每个Binlog文件的初始事件以确定其时间戳,最终定位至指定时间对应的Binlog文件。请保证指定的时间戳对应的Binlog文件在数据库上没有被清理且可以被读取到。 |
|
server-time-zone |
数据库在使用的会话时区。 |
否 |
STRING |
如果您没有指定该参数,则系统默认使用Flink作业运行时的环境时区作为数据库服务器时区,即您选择的可用区所在的时区。 |
例如Asia/Shanghai,该参数控制了MySQL中的TIMESTAMP类型如何转成STRING类型。更多信息请参见 Debezium时间类型 。 |
|
scan.startup.specific-offset.skip-events |
从指定的位点读取时,跳过多少Binlog事件。 |
否 |
INTEGER |
无 |
使用该配置时, scan.startup.mode 必须配置为 specific-offset 。 |
|
scan.startup.specific-offset.skip-rows |
从指定的位点读取时,跳过多少行变更(一个Binlog事件可能对应多行变更)。 |
否 |
INTEGER |
无 |
使用该配置时, scan.startup.mode 必须配置为 specific-offset 。 |
|
connect.timeout |
连接MySQL数据库服务器超时时,重试连接之前等待超时的最长时间。 |
否 |
DURATION |
30s |
无。 |
|
connect.max-retries |
连接MySQL数据库服务时,连接失败后重试的最大次数。 |
否 |
INTEGER |
3 |
无。 |
|
connection.pool.size |
数据库连接池大小。 |
否 |
INTEGER |
20 |
数据库连接池用于复用连接,可以降低数据库连接数量。 |
|
heartbeat.interval |
Source通过心跳事件推动Binlog位点前进的时间间隔。 |
否 |
DURATION |
30s |
心跳事件用于推动Source中的Binlog位点前进,这对MySQL中更新缓慢的表非常有用。对于更新缓慢的表,Binlog位点无法自动前进,通过够心跳事件可以推到Binlog位点前进,可以避免Binlog位点不前进引起Binlog位点过期问题,Binlog位点过期会导致作业失败无法恢复,只能无状态重启。 |
|
scan.incremental.snapshot.chunk.key-column |
可以指定某一列作为快照阶段切分分片的切分列。 |
否。 |
STRING |
无 |
仅支持从主键中选择一列。 |
|
rds.region-id |
阿里云RDS MySQL实例所在的地域ID。 |
使用读取OSS归档日志功能时必填。 |
STRING |
无 |
地域ID请参见 地域和可用区 。 |
|
rds.access-key-id |
阿里云RDS MySQL账号Access Key ID。 |
使用读取OSS归档日志功能时必填。 |
STRING |
无 |
详情请参见 如何查看AccessKey ID和AccessKey Secret信息?
重要
为了避免您的AK信息泄露,建议您通过密钥管理的方式填写AccessKey ID取值,详情请参见 变量管理 。
|
|
rds.access-key-secret |
阿里云RDS MySQL账号Access Key Secret。 |
使用读取OSS归档日志功能时必填。 |
STRING |
无 |
详情请参见 如何查看AccessKey ID和AccessKey Secret信息?
重要
为了避免您的AK信息泄露,建议您通过密钥管理的方式填写AccessKey Secret取值,详情请参见 变量管理 。 |
|
rds.db-instance-id |
阿里云RDS MySQL实例ID。 |
使用读取OSS归档日志功能时必填。 |
STRING |
无 |
无。 |
|
rds.main-db-id |
阿里云RDS MySQL实例主库编号。 |
否 |
STRING |
无 |
获取主库编号详情请参见 RDS MySQL日志备份 。 |
|
rds.download.timeout |
从OSS下载单个归档日志的超时时间。 |
否 |
DURATION |
60s |
无。 |
|
rds.endpoint |
获取OSS Binlog信息的服务接入点。 |
否 |
STRING |
无 |
可选值详情请参见 服务接入点 。 |
|
rds.binlog-directory-prefix |
保存Binlog文件的目录前缀。 |
否 |
STRING |
rds-binlog- |
无。 |
|
rds.use-intranet-link |
是否使用内网下载Binlog文件。 |
否 |
BOOLEAN |
true |
无。 |
|
rds.binlog-directories-parent-path |
保存Binlog文件的父目录的绝对路径。 |
否 |
STRING |
无 |
无。 |
|
chunk-meta.group.size |
chunk元信息的大小。 |
否 |
INTEGER |
1000 |
如果元信息大于该值,元信息会分为多份传递。 |
|
chunk-key.even-distribution.factor.lower-bound |
是否可以均匀分片的chunk分布因子的下限。 |
否 |
DOUBLE |
0.05 |
分布因子小于该值会使用非均匀分片。 chunk分布因子 = (MAX(chunk-key) - MIN(chunk-key) + 1) / 总数据行数。 |
|
chunk-key.even-distribution.factor.upper-bound |
是否可以均匀分片的chunk分布因子的上限。 |
否 |
DOUBLE |
1000.0 |
分布因子大于该值会使用非均匀分片。 chunk分布因子 = (MAX(chunk-key) - MIN(chunk-key) + 1) / 总数据行数。 |
|
scan.incremental.close-idle-reader.enabled |
是否在快照结束后关闭空闲的Reader。 |
否 |
BOOLEAN |
false |
该配置生效,需要设置
|
|
scan.only.deserialize.captured.tables.changelog.enabled |
在增量阶段,是否仅对指定表的变更事件进行反序列化。 |
否 |
BOOLEAN |
false |
参数取值如下:
|
|
scan.parallel-deserialize-changelog.enabled |
在增量阶段,是否使用多线程对变更事件进行解析。 |
否 |
BOOLEAN |
false |
参数取值如下:
|
|
scan.parallel-deserialize-changelog.handler.size |
多线程对变更事件进行解析时,事件处理器的数量。 |
否 |
INTEGER |
2 |
无。 |
|
metadata-column.include-list |
需要传给下游的元数据列。 |
否 |
STRING |
无 |
可用的元数据包括
|
|
scan.newly-added-table.enabled |
从Checkpoint重启时,是否同步上一次启动时未匹配到的新增表。 |
否 |
BOOLEAN |
false |
从Checkpoint或Savepoint重启时生效。 |
|
scan.binlog.newly-added-table.enabled |
在增量阶段,是否发送匹配到的新增表的数据。 |
否 |
BOOLEAN |
false |
不能与
|
类型映射
数据摄入类型映射如下表所示。
|
MySQL CDC字段类型 |
CDC字段类型 |
|
TINYINT(n) |
TINYINT |
|
SMALLINT |
SMALLINT |
|
TINYINT UNSIGNED |
|
|
TINYINT UNSIGNED ZEROFILL |
|
|
YEAR |
|
|
INT |
INT |
|
MEDIUMINT |
|
|
MEDIUMINT UNSIGNED |
|
|
MEDIUMINT UNSIGNED ZEROFILL |
|
|
SMALLINT UNSIGNED |
|
|
SMALLINT UNSIGNED ZEROFILL |
|
|
BIGINT |
BIGINT |
|
INT UNSIGNED |
|
|
INT UNSIGNED ZEROFILL |
|
|
BIGINT UNSIGNED |
DECIMAL(20, 0) |
|
BIGINT UNSIGNED ZEROFILL |
|
|
SERIAL |
|
|
FLOAT [UNSIGNED] [ZEROFILL] |
FLOAT |
|
DOUBLE [UNSIGNED] [ZEROFILL] |
DOUBLE |
|
DOUBLE PRECISION [UNSIGNED] [ZEROFILL] |
|
|
REAL [UNSIGNED] [ZEROFILL] |
|
|
NUMERIC(p, s) [UNSIGNED] [ZEROFILL]且p <= 38 |
DECIMAL(p, s) |
|
DECIMAL(p, s) [UNSIGNED] [ZEROFILL]且p <= 38 |
|
|
FIXED(p, s) [UNSIGNED] [ZEROFILL]且p <= 38 |
|
|
BOOLEAN |
BOOLEAN |
|
BIT(1) |
|
|
TINYINT(1) |
|
|
DATE |
DATE |
|
TIME [(p)] |
TIME [(p)] |
|
DATETIME [(p)] |
TIMESTAMP [(p)] |
|
TIMESTAMP [(p)] |
TIMESTAMP_LTZ [(p)] |
|
CHAR(n) |
CHAR(n) |
|
VARCHAR(n) |
VARCHAR(n) |
|
BIT(n) |
BINARY(⌈(n + 7) / 8⌉) |
|
BINARY(n) |
BINARY(n) |
|
VARBINARY(N) |
VARBINARY(N) |
|
NUMERIC(p, s) [UNSIGNED] [ZEROFILL]且38 < p <= 65 |
STRING
说明
在MySQL中,十进制数据类型的精度高达 65,但在Flink中,十进制数据类型的精度仅限于38。所以,如果定义精度大于38的十进制列,则应将其映射到字符串以避免精度损失。 |
|
DECIMAL(p, s) [UNSIGNED] [ZEROFILL]且38 < p <= 65 |
|
|
FIXED(p, s) [UNSIGNED] [ZEROFILL]且38 < p <= 65 |
|
|
TINYTEXT |
STRING
|
|
TEXT |
|
|
MEDIUMTEXT |
|
|
LONGTEXT |
|
|
ENUM |
|
|
JSON |
STRING
说明
JSON数据类型将在Flink中转换为JSON格式的字符串。 |
|
GEOMETRY |
STRING
说明
MySQL中的空间数据类型将转换为具有固定JSON格式的字符串,详情请参见MySQL 空间数据类型映射 。 |
|
POINT |
|
|
LINESTRING |
|
|
POLYGON |
|
|
MULTIPOINT |
|
|
MULTILINESTRING |
|
|
MULTIPOLYGON |
|
|
GEOMETRYCOLLECTION |
|
|
TINYBLOB |
BYTES
说明
对于MySQL中的BLOB数据类型,仅支持长度不大于2147483647(2**31-1)的 blob。 |
|
BLOB |
|
|
MEDIUMBLOB |
|
|
LONGBLOB |
使用示例
-
CDC源表
CREATE TEMPORARY TABLE mysqlcdc_source ( order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql', 'hostname' = '<yourHostname>', 'port' = '3306', 'username' = '<yourUsername>', 'password' = '<yourPassword>', 'database-name' = '<yourDatabaseName>', 'table-name' = '<yourTableName>' CREATE TEMPORARY TABLE blackhole_sink( order_id INT, customer_name STRING ) WITH ( 'connector' = 'blackhole' INSERT INTO blackhole_sink SELECT order_id, customer_name FROM mysqlcdc_source; -
维表
CREATE TEMPORARY TABLE datagen_source( a INT, b BIGINT, c STRING, `proctime` AS PROCTIME() ) WITH ( 'connector' = 'datagen' CREATE TEMPORARY TABLE mysql_dim ( a INT, b VARCHAR, c VARCHAR ) WITH ( 'connector' = 'mysql', 'hostname' = '<yourHostname>', 'port' = '3306', 'username' = '<yourUsername>', 'password' = '<yourPassword>', 'database-name' = '<yourDatabaseName>', 'table-name' = '<yourTableName>' CREATE TEMPORARY TABLE blackhole_sink( a INT, b STRING ) WITH ( 'connector' = 'blackhole' INSERT INTO blackhole_sink SELECT T.a, H.b FROM datagen_source AS T JOIN mysql_dim FOR SYSTEM_TIME AS OF T.`proctime` AS H ON T.a = H.a; -
结果表
CREATE TEMPORARY TABLE datagen_source ( `name` VARCHAR, `age` INT ) WITH ( 'connector' = 'datagen' CREATE TEMPORARY TABLE mysql_sink ( `name` VARCHAR, `age` INT ) WITH ( 'connector' = 'mysql', 'hostname' = '<yourHostname>', 'port' = '3306', 'username' = '<yourUsername>', 'password' = '<yourPassword>', 'database-name' = '<yourDatabaseName>', 'table-name' = '<yourTableName>' INSERT INTO mysql_sink SELECT * FROM datagen_source; -
数据摄入数据源
source: type: mysql name: MySQL Source hostname: ${mysql.hostname} port: ${mysql.port} username: ${mysql.username} password: ${mysql.password} tables: ${mysql.source.table} server-id: 7601-7604 sink: type: values name: Values Sink print.enabled: true sink.print.logger: true
关于MySQL CDC源表
-
实现原理
MySQL CDC源表在启动时扫描全表,将表按照主键分成多个分片(chunk),记录下此时的Binlog位点。并使用增量快照算法通过select语句,逐个读取每个分片的数据。作业会周期性执行Checkpoint,记录下已经完成的分片。当发生Failover时,只需要继续读取未完成的分片。当分片全部读取完后,会从之前获取的Binlog位点读取增量的变更记录。Flink作业会继续周期性执行Checkpoint,记录下Binlog位点,当作业发生Failover,便会从之前记录的Binlog位点继续处理,从而实现Exactly Once语义。
更详细的增量快照算法,请参见 MySQL CDC Connector 。
-
元数据
元数据在分库分表合并同步场景非常实用,因为分库分表合并后,一般业务还是希望区分每条数据的库名和表名来源,而 元数据列 可以访问源表的库名和表名信息。因此通过元数据列可以非常方便地将多张分表合并到一张目的表。
自vvr-4.0.11-flink-1.13版本开始,MySQL CDC Source支持元数据列语法,您可以通过元数据列访问以下元数据。
元数据key
元数据类型
描述
database_name
STRING NOT NULL
包含该行记录的库名。
table_name
STRING NOT NULL
包含该行记录的表名。
op_ts
TIMESTAMP_LTZ(3) NOT NULL
该行记录在数据库中的变更时间,如果该记录来自表的存量历史数据而不是Binlog中获取,则该值总是0。
op_type
STRING NOT NULL
该行记录的变更类型。
-
+I:表示INSERT消息
-
-D:表示DELETE消息
-
-U:表示UPDATE_BEFORE消息
-
+U:表示UPDATE_AFTER消息
说明仅实时计算引擎VVR 8.0.7及以上版本支持。
将MySQL实例中多个分库下的多张orders表,合并同步到下游Hologres的holo_orders表中,代码示例如下所示。
CREATE TABLE mysql_orders ( db_name STRING METADATA FROM 'database_name' VIRTUAL, -- 读取库名。 table_name STRING METADATA FROM 'table_name' VIRTUAL, -- 读取表名。 operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL, -- 读取变更时间。 op_type STRING METADATA FROM 'op_type' VIRTUAL, -- 读取变更类型。 order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'flinkuser', 'password' = 'flinkpw', 'database-name' = 'mydb_.*', -- 正则匹配多个分库。 'table-name' = 'orders_.*' -- 正则匹配多张分表。 INSERT INTO holo_orders SELECT * FROM mysql_orders;在上面代码的基础上,WITH参数里配置scan.read-changelog-as-append-only.enabled参数为true时,输出结果根据下游表主键设置情况有不同的表现:
-
下游表主键为order_id时,输出结果仅包含上游表每个主键的最后一次变更。即对于某个主键最后一次变更为删除操作的数据,在下游表可以看到一条相同主键的、op_type为-D的数据。
-
下游表主键为order_id、operation_ts、op_type时,输出结果包含上游表每个主键的完整变更。
-
-
支持正则表达式
MySQL CDC源表支持在表名或者库名中使用正则表达式匹配多个表或者多个库。通过正则表达式指定多张表的代码示例如下。
CREATE TABLE products ( db_name STRING METADATA FROM 'database_name' VIRTUAL, table_name STRING METADATA FROM 'table_name' VIRTUAL, operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL, order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = '(^(test).*|^(tpc).*|txc|.*[p$]|t{2})', -- 正则表达式匹配多个库。 'table-name' = '(t[5-8]|tt)' -- 正则表达式匹配多张表。 );上述例子中的正则表达式解释:
-
^(test).* 是前缀匹配示例,这个表达式可以匹配以test开头的库名,例如test1或test2。
-
.*[p$] 是后缀匹配示例, 这个表达式可以匹配以p结尾的库名,例如cdcp或edcp。
-
txc是指定匹配, 可以匹配指定名称的数据库名,例如txc。
MySQL CDC在匹配全路径表名时,会通过库名和表名来唯一确定一张表,即使用database-name.table-name作为匹配表的模式,例如匹配模式 (^(test).*|^(tpc).*|txc|.*[p$]|t{2}).(t[ 5-8]|tt) 就可以匹配到数据库中的表txc.tt和test2.test5。
重要在SQL作业的配置中,table-name和database-name不支持使用逗号(,)分隔形式指定多张表或多个库。
-
如果需要匹配多个表或使用多个正则表达式,可以用竖线(|)连接并用小括号包围,例如需要读取表user和product,table-name可以配置为
(user|product)。 -
如果正则表达式包含逗号,需要用竖线(|)运算符进行改写,例如正则表达式
mytable_\d{1, 2)需要改写成等价的(mytable_\d{1}|mytable_\d{2}),来避免使用逗号。
-
-
并发控制
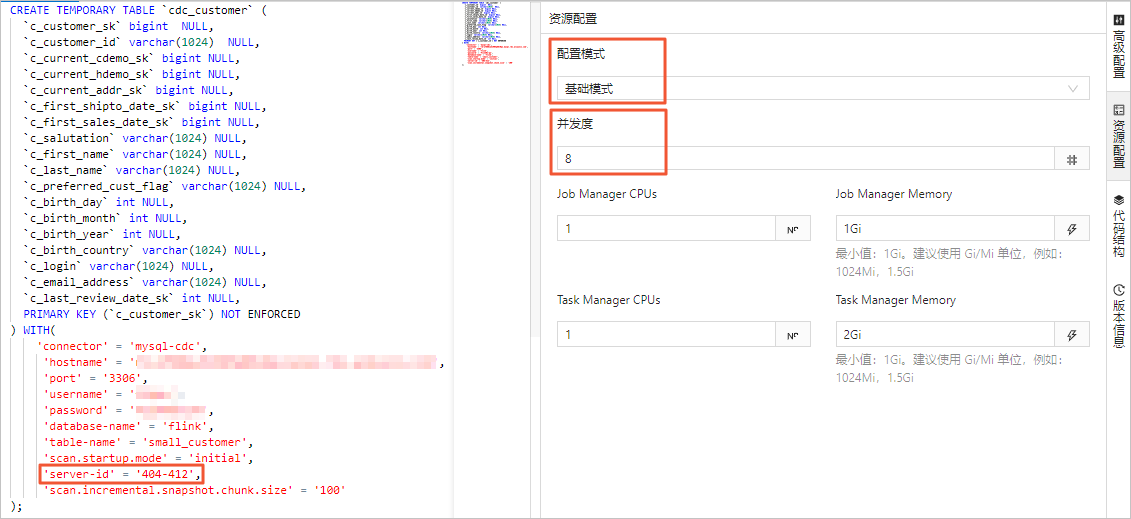
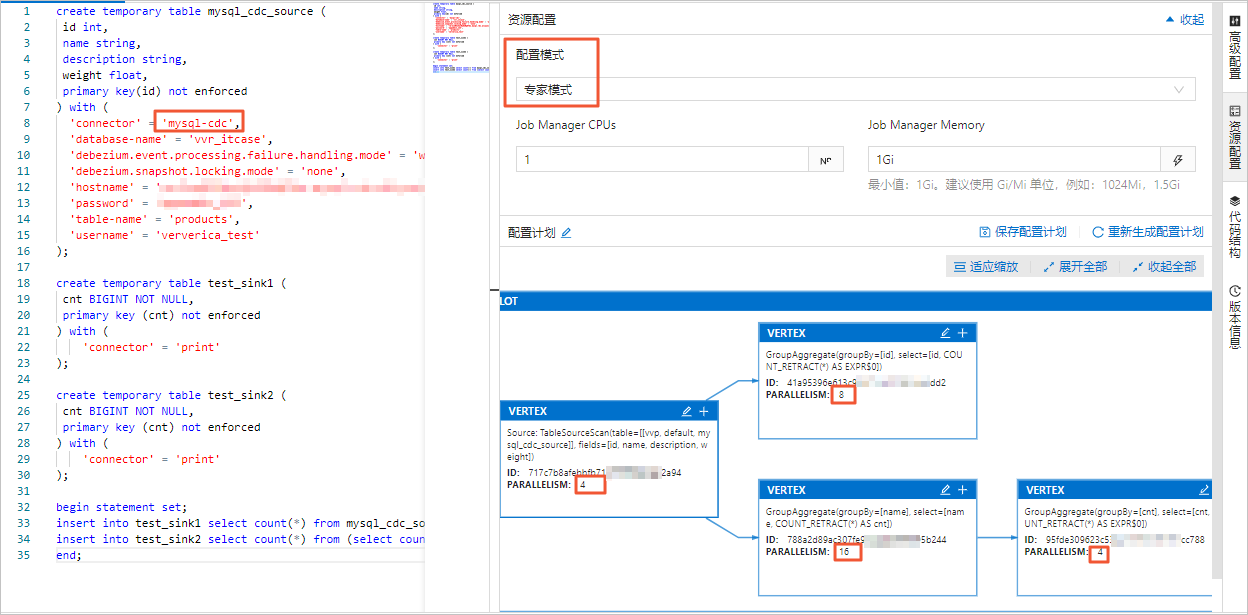
MySQL连接器支持多并发读取全量数据,能够提高数据加载效率。同时配合Flink实时计算控制台的Autopilot自动调优功能,在多并发读取完成后增量阶段,能够自动缩容,节约计算资源。
在Flink全托管控制台,您可以在资源配置页面的基础模式或专家模式中设置作业的并发数。设置并发的区别如下:
-
基础模式设置的并发数为整个作业的全局并发数。
-
专家模式支持按需为某个VERTEX设置并发数。
资源配置详情请参见 配置作业部署信息 。
重要无论是基础模式还是专家模式,在设置并发时,表中声明的server-id范围必须大于等于作业的并发数。例如server-id的范围为5404-5412,则共有8个唯一的server-id,因此作业最多可以设置8个并发,且不同的作业对于同一个MySQL实例的server-id范围不能有重叠,即每个作业需显式配置不同的server-id。
-
-
Autopilot自动缩容
全量阶段积累了大量历史数据,为了提高读取效率,通常采用并发的方式读取历史数据。而在Binlog增量阶段,因为Binlog数据量少且为了保证全局有序,通常只需要单并发读取。全量阶段和增量阶段对资源的不同需求,可以通过自动调优功能自动帮您实现性能和资源的平衡。
自动调优会监控MySQL CDC Source的每个task的流量。当进入Binlog阶段,如果只有一个task在负责Binlog读取,其他task均空闲时,自动调优便会自动缩小Source的CU数和并发。开启自动调优只需要在作业运维页面,将自动调优的模式设置为Active模式。
说明默认调低并发度的最小触发时间间隔为24小时。更多自动调优的参数和细节,请参见 配置自动调优 。
-
启动模式
使用配置项scan.startup.mode可以指定MySQL CDC源表的启动模式。可选值包括:
-
initial (默认):在第一次启动时对数据库表进行全量读取,完成后切换至增量模式读取Binlog。
-
earliest-offset:跳过快照阶段,从可读取的最早Binlog位点开始读取。
-
latest-offset:跳过快照阶段,从Binlog的结尾处开始读取。该模式下源表只能读取在作业启动之后的数据变更。
-
specific-offset:跳过快照阶段,从指定的Binlog位点开始读取。位点可通过Binlog文件名和位置指定,或者使用GTID集合指定。
-
timestamp:跳过快照阶段,从指定的时间戳开始读取Binlog事件。
使用示例:
CREATE TABLE mysql_source (...) WITH ( 'connector' = 'mysql-cdc', 'scan.startup.mode' = 'earliest-offset', -- 从最早位点启动。 'scan.startup.mode' = 'latest-offset', -- 从最晚位点启动。 'scan.startup.mode' = 'specific-offset', -- 从特定位点启动。 'scan.startup.mode' = 'timestamp', -- 从特定位点启动。 'scan.startup.specific-offset.file' = 'mysql-bin.000003', -- 在特定位点启动模式下指定Binlog文件名。 'scan.startup.specific-offset.pos' = '4', -- 在特定位点启动模式下指定Binlog位置。 'scan.startup.specific-offset.gtid-set' = '24DA167-0C0C-11E8-8442-00059A3C7B00:1-19', -- 在特定位点启动模式下指定GTID集合。 'scan.startup.timestamp-millis' = '1667232000000' -- 在时间戳启动模式下指定启动时间戳。 )重要-
MySQL source会在Checkpoint时将当前位点以INFO级别打印到日志中,日志前缀为
Binlog offset on checkpoint {checkpoint-id},该日志可以帮助您将作业从某个Checkpoint位点开始启动作业。 -
如果读取的表曾经发生过表结构变化,从最早位点(earliest-offset)、特定位点(specific-offset)或时间戳(timestamp)启动可能会发生错误。因为Debezium读取器会在内部保存当前的最新表结构,结构不匹配的早期数据无法被正确解析。
-
-
关于无主键CDC源表
-
在Flink计算引擎VVR 6.0.7及以上版本支持使用MySQL CDC无主键源表,使用无主键表要求必须设置 scan.incremental.snapshot.chunk.key-column ,且只能选择非空类型的字段。
-
无主键CDC源表的处理语义由 scan.incremental.snapshot.chunk.key-column 指定的列的行为决定:
-
如果指定的列不存在更新操作,此时可以保证Exactly once语义。
-
如果指定的列发生更新操作,此时只能保证At least once语义。但可以结合下游,通过指定下游主键,结合幂等性操作来保证数据的正确性。
-
-
-
读取阿里云RDS MySQL备份日志
MySQL CDC源表支持读取阿里云RDS MySQL的备份日志。这在全量阶段执行时间较长,本地Binlog文件已经被自动清理,而自动或者手动上传的备份文件依然存在的场景下非常适用。
使用示例:
CREATE TABLE mysql_source (...) WITH ( 'connector' = 'mysql-cdc', 'rds.region-id' = 'cn-beijing', 'rds.access-key-id' = 'xxxxxxxxx', 'rds.access-key-secret' = 'xxxxxxxxx', 'rds.db-instance-id' = 'rm-xxxxxxxxxxxxxxxxx', 'rds.main-db-id' = '12345678', 'rds.download.timeout' = '60s' ) -
开启CDC Source复用
当同一个作业中有多个MySQL CDC源表时,每个源表都会启动对应的Binlog Client,如果源表数量较多并且读取的MySQL表都在同一个实例中时,会对数据库造成较大压力,详情请参见 MySQL CDC常见问题 。
实时计算引擎VVR 8.0.7及以上版本支持MySQL CDC Source复用,当不同的CDC源表配置项除了数据库、表名和server-id外的其他配置项均相同时,可以进行合并。开启Source复用后,实时计算引擎会尽可能将同一个作业中能够合并的MySQL CDC源表进行合并。
您可以在SQL作业中使用SET命令开启source复用功能:
SET 'table.optimizer.source-merge.enabled' = 'true';对已有作业启用 Source 复用后,需要无状态启动。原因是 Source 复用会导致作业拓扑改变,从原有作业状态可能无法启动或者丢失数据。
重要-
VVR 8.0.8及8.0.9版本,在开启CDC Source复用时,还需要额外设置
SET 'sql-gateway.exec-plan.enabled' = 'false'。 -
在开启CDC Source复用后,不建议将作业配置项
pipeline.operator-chaining设为false,因为将算子链断开后,Source发送给下游算子的数据会增加序列化和反序列的开销,当合并的Source越多时,开销会越大。 -
在实时计算引擎VVR 8.0.7版本,将
pipeline.operator-chaining设为false时会出现序列化的问题。
-
加速Binlog读取
MySQL连接器作为源表或数据摄入数据源使用时,在增量阶段会解析Binlog文件生成各种变更消息,Binlog文件使用二进制记录着所有表的变更,可以通过以下方式加速Binlog文件解析。
-
开启并行解析和解析过滤配置
-
使用配置项
scan.only.deserialize.captured.tables.changelog.enabled:仅对指定表的变更事件进行解析。 -
使用配置项
scan.parallel-deserialize-changelog.enabled:采用多线程对Binlog文件进行解析、并按顺序投放到消费队列。
-
-
优化Debezium参数
debezium.max.queue.size: 162580 debezium.max.batch.size: 40960 debezium.poll.interval.ms: 50-
debezium.max.queue.size:阻塞队列可以容纳的记录的最大数量。当Debezium从数据库读取事件流时,它会在将事件写入下游之前将它们放入阻塞队列。默认值为8192。 -
debezium.max.batch.size:该连接器每次迭代处理的事件条数最大值。默认值为2048。 -
debezium.poll.interval.ms:连接器应该在请求新的变更事件前等待多少毫秒。默认值为1000毫秒,即1秒。
-
使用示例:
CREATE TABLE mysql_source (...) WITH (
'connector' = 'mysql-cdc',
-- Debezium配置
'debezium.max.queue.size' = '162580',
'debezium.max.batch.size' = '40960',
'debezium.poll.interval.ms' = '50',
-- 开启并行解析和解析过滤
'scan.only.deserialize.captured.tables.changelog.enabled' = 'true', -- 仅对指定表的变更事件进行解析。
'scan.parallel-deserialize-changelog.enabled' = 'true' -- 使用多线程对Binlog进行解析。
)source:
type: mysql
name: MySQL Source
hostname: ${mysql.hostname}
port: ${mysql.port}
username: ${mysql.username}
password: ${mysql.password}
tables: ${mysql.source.table}
server-id: 7601-7604
# Debezium配置
debezium.max.queue.size: 162580
debezium.max.batch.size: 40960
debezium.poll.interval.ms: 50
# 开启并行解析和解析过滤
scan.only.deserialize.captured.tables.changelog.enabled: true
scan.parallel-deserialize-changelog.enabled: trueMySQL CDC 企业版本binlog消费能力为85MB/s,约为开源社区的2倍,当Binlog文件产生速度大于 85MB/s 时(即每6s一个512MB大小的文件),Flink 作业的延迟会持续上升,在Binlog文件产生速度降低后处理延迟会逐步下降。在Binlog文件包含大事务时,可能会导致处理延迟短暂上升,读取完该事务的日志后处理延迟会下降。
MySQL CDC DataStream API
重要
通过DataStream的方式读写数据时,则需要使用对应的DataStream连接器连接Flink全托管,DataStream连接器设置方法请参见 DataStream连接器使用方法 。
创建DataStream API程序并使用MySqlSource。代码及pom依赖项示例如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // set captured database
.tableList("yourDatabaseName.yourTableName") // set captured table
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enable checkpoint
env.enableCheckpointing(3000);
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>ververica-connector-mysql</artifactId>
<version>${vvr.version}</version>
</dependency>在构建MySqlSource时,代码中必须指定以下参数:
|
参数 |
说明 |
|
hostname |
MySQL数据库的IP地址或者Hostname。 |
|
port |
MySQL数据库服务的端口号。 |
|
databaseList |
MySQL数据库名称。
说明
数据库名称支持正则表达式以读取多个数据库的数据,您可以使用
|
|
username |
MySQL数据库服务的用户名。 |
|
password |
MySQL数据库服务的密码。 |
|
deserializer |
反序列化器,将SourceRecord类型记录反序列化到指定类型。参数取值如下:
|
pom依赖项必须指定以下参数:
|
${vvr.version} |
阿里云实时计算Flink版的引擎版本,例如:
|
|
${flink.version} |
Apache Flink版本,例如:
重要
请使用阿里云实时计算Flink版的引擎版本对应的Apache Flink版本,避免在作业运行时出现不兼容的问题。版本对应关系详情,请参见 引擎 。 |
常见问题
CDC源表使用中可能遇到的问题,详情请参见 CDC问题 。