

AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案

前言 Vision Transformers 中,输入图像的空间维度会出现相当大的冗余,从而导致大量的计算成本。因此,本文中提出了 一种由粗到精的视觉变换器(CF-ViT)来减轻计算负担 ,同时保持性能。CF-ViT 以两阶段的方式实现网络推理。在粗略推理阶段,输入图像被分成一个小长度的补丁序列,用于计算上经济的分类。如果没有被很好地识别,信息块将被识别并进一步以细粒度重新分割。
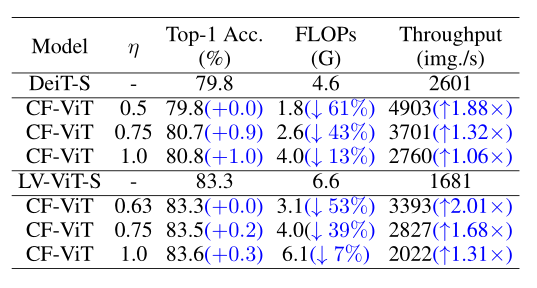
在不影响Top-1 准确率的情况下,该方法在ImageNet-1k上将LV-ViT-S的FLOPs降低53%, GPU上实测推理速度也加快了2倍。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。


论文: https:// arxiv.org/pdf/2203.0382 1.pdf
代码: https:// github.com/ChenMnZ/CF-V iT
论文出发点
ViT 的核心在于self-attention,而 自注意力机制的计算成本与token数量呈二次相关 。但是,图像通常比语言具有更多的空间冗余。因此, 降低ViT 计算成本的思路就是降低token数量(图像划分的patch数目) 。
CF-ViT 的动机是 ViT 模型中的两个重要观察结果 :(1) 粗粒度块分割可以定位输入图像的信息区域。(2) 大多数图像都可以在小长度的标记序列中被 ViT 模型很好地识别。
创新思路
本文提出了 一种新颖的由粗到细的视觉变换器 (CFViT),CF-ViT的推理分为粗推理阶段和精细推理阶段。粗粒度阶段接收粗粒度补丁作为网络输入,然后粗粒度块的积分信息到分割的细粒度块中,以进一步增强了模型性能。
方法
整体架构
模型架构如图3所示,粗推理阶段用小长度的token序列实现图像识别。如果没有很好地识别,信息区域将被进一步分割以进行细粒度识别。
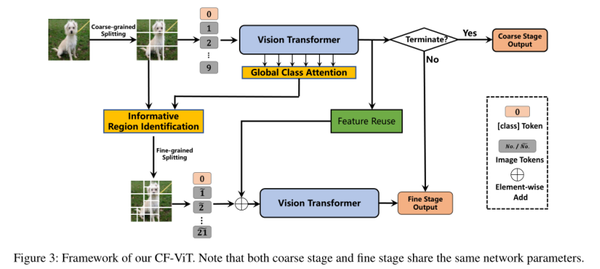
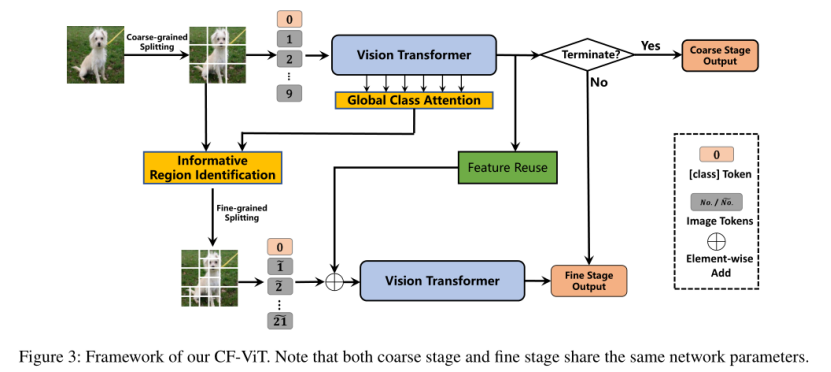
粗推理阶段
首先执行粗分割以识别充满“简单”区域的图像。此外,当遇到“硬”样本时,它会定位信息区域以进行有效推理。同时,将类别的token送到分类器以获得粗阶段类别预测分布 pc:
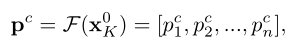
在粗略推理阶段,由于patch数量较小,引入一个阈值权衡性能和计算代价。但是token数量急剧下降会对计算成本带来影响,为了节省预算,建议识别并重新划分这些对性能提升最有利的信息区域。因此,关键在于如何识别patches信息。
精细推理阶段
当粗阶段类别预测分布 pc<阈值η时,对信息块进行细粒度分割,这表明输入图像无法区分。细粒度拆分后的patch number为:
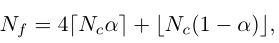
提供更细粒度的同时,切断了局部patch的完整性。为了解决这个问题,设计了一个特征重用模块(如图4),将局部patch的信息注入到四个细粒度的补丁中,将粗阶段的输出token序列作为输入。
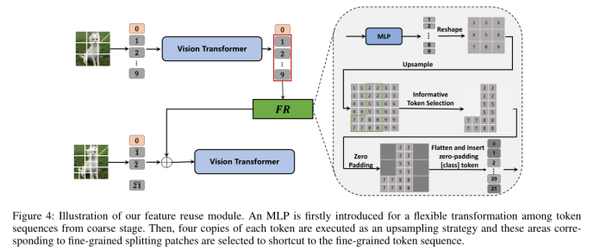
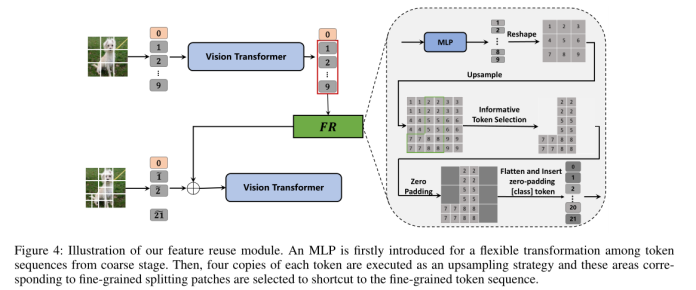
与 FNN 类似,输入将首先由 MLP 层处理以允许灵活的转换。然后,对这些转换后的标记进行重塑,并将它们中的每一个复制 4 倍。此外,这些对应于细粒度分割补丁的标记被拾取作为特征重用模块的输出。
损失函数
设置置信度阈值 η = 1,这意味着将始终对每个输入图像执行精细推理阶段。一方面,期望细粒度的分割能够很好地拟合真实标签 y 以准确预测输入。另一方面,期望粗粒度拆分与细粒度拆分具有相似的输出,这样大多数输入可以在粗推理阶段得到很好的识别,这表明计算成本更低。因此,CF-ViT 的训练损失如下(粗推理阶段c+精细推理阶段f):
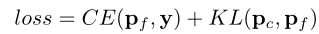
结果
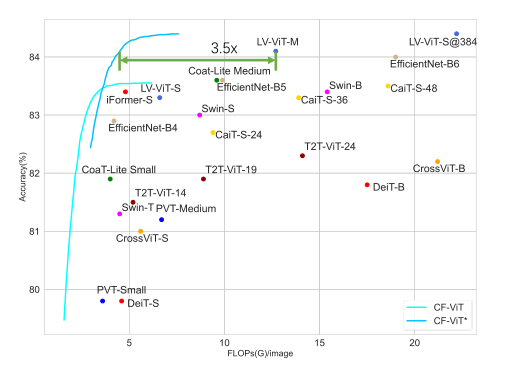
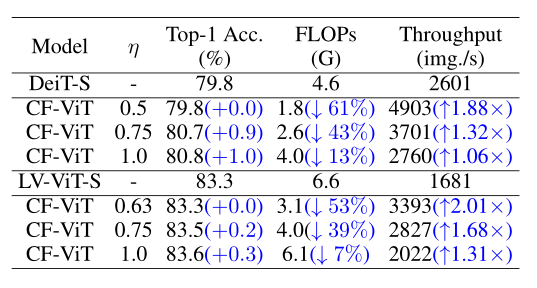
CF-ViT与流行的 ViT 模型的比较:
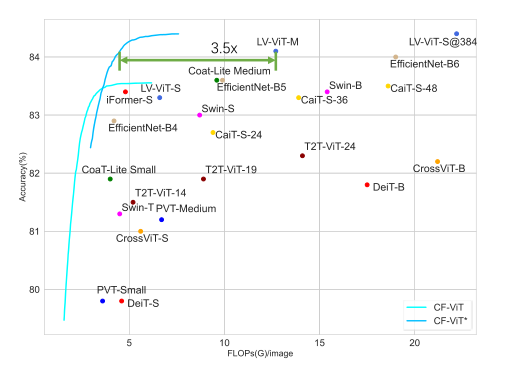
现有基于降低tokens数量的 ViT 压缩方法与本文的 CF-ViT 之间的比较:
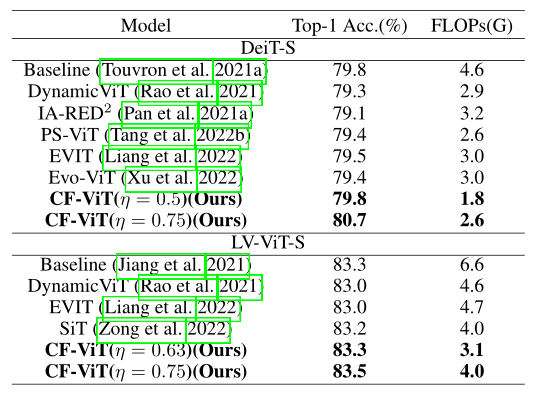
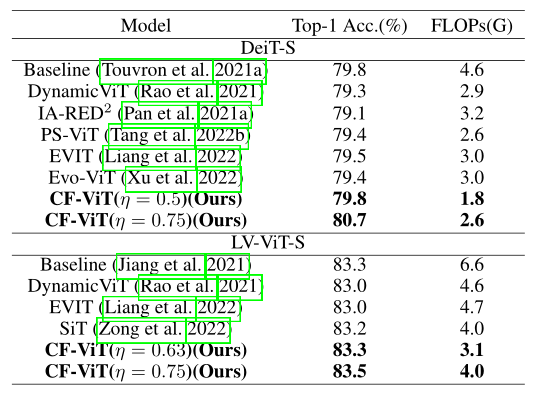
主干网络对比实验:
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效