Python Socket 编程详细介绍
Socket Programming in Python (Guide)
Socket
是计算机之间进行通信的一种协议,通过
Socket
开发者可以在无需关心底层是如何实现的情况下在不同的计算机进行端到端之间的通信,
Socket
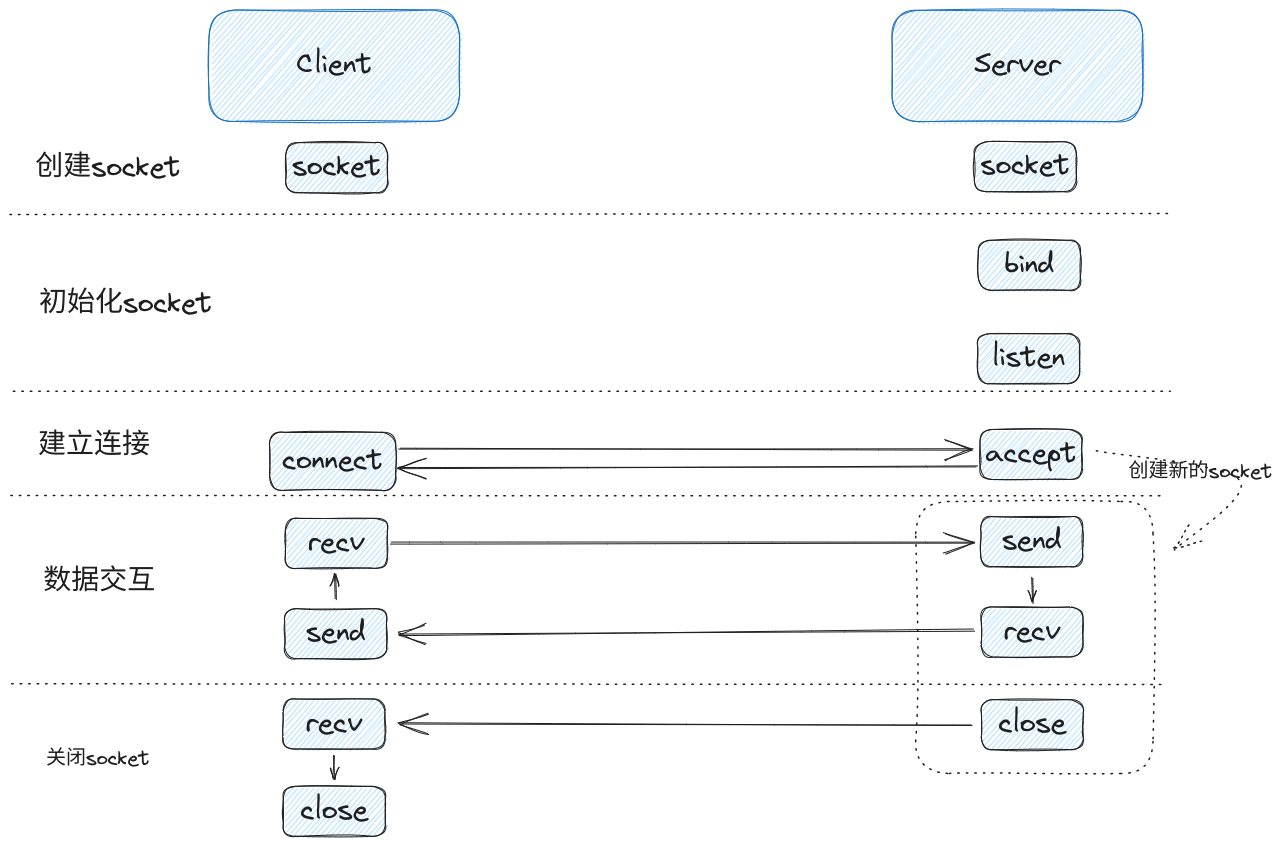
常见的交互流程如下图:
1692807503149asyncio网络编程-socket.png
在交互的流程的示例图中,
Socket
分为五个交互阶段,每个阶段的作用如下:
创建
Socket
: 初始化一个
Socket
对象。
初始化
Socket
: 客户端无需任何操作,而服务端的
Socket
在初始化时比客户端的
Socket
多了两个方法–
bind
和
listen
,它们的作用分别是绑定一个端口,以及监听这个端口建立的新连接。
建立连接: 客户端
Socket
的专属方法为
connect
,这个方法会直接与服务端建立连接。而服务端的专属方法为
accept
,
accept
这个方法比较特殊,因为其他
socket
的方法都是针对于
socket
进行操作,而
accept
方法除了针对
socket
进行操作外还会额外返回一个新的
socket
。
socket
只携带服务端的IP和地址信息,而新的
socket
携带的是客户端与服务端两个端点的四元组信息(客户端IP,客户端端口,服务端IP,服务端端口)。
socket
对应的文件描述符是不一样的,它们的责任也是不一样的,
socket
只用于跟客户端建立新的连接,而新的
socket
用于客户端与服务端进行数据交互,这意味着服务端的事件循环在处理的时候,对两个
socket
的读事件的触发时机也是不一样的。其中服务端原先
socket
的读事件被触发时意味着有新的连接可以被
accept
,而新
socket
的读事件被触发则是代表当前连接有新的数据可以被接收,这与客户端的
Socket
读事件的一样的,这意味着在
Socket
建立成功后,客户端和服务端的连接的读写逻辑都可以统一,不用进行区分了。
数据交互阶段:由于服务端
accept
方法返回的
Socket
与客户端的类似,所以这个阶段的客户端与服务端的逻辑是类似的,不过双端程序的数据只是与各自的
Socket
进行交互,而不是直接进行交互的。因为每个
Socket
都维护着读和写两个缓冲区,缓冲区的底层数据结构与队列类似,创建
Socket
的程序只能把数据投递到缓冲区或者从缓冲区获取数据,而无法触碰到网卡发送/接收数据的领域。
Socket
设置为非阻塞的情况下,当
Socket
的写缓冲区不满时,
Socket
的写操作是不会阻塞的,同样当
Socket
的读缓冲区拥有的量大于
Socket
读方法需要的量时,读操作也是不会阻塞的。
关闭阶段:由于
Socket
有两个缓冲区,所以关闭阶段分为
close
和
shutdowm
两个方法,其中
close
为关闭两个缓冲区,而
shuwdown
可以关闭指定的缓冲区(详细的流程见后文)。示例中的例子是服务端先调用了
close
方法,然后服务端会发送一个
EOF
事件给客户端,客户端从读缓冲区读到
EOF
事件后发现读通道已经关闭了,才调用
close
方法把整个
socket
一起关闭。
《初识Python协程的实现》
中介绍了如何把同步请求通过
selector
库和
yield
语法改造成一个简单的基于协程的异步请求,但是改造后的代码增加了很多监听和移除文件描述符的回调代码,编写起来比较麻烦,很不易懂。
不过在采用了
Asyncio
的思想并引入了
Task
和
Future
后,异步回调的代码都被消除了,但是大量的监听和移除文件描述符的代码还是存在,而
Asyncio.Socket
则封装了大量的读写事件的监听和移除的操作,只暴露了与
Socket
类似的方法,开发者通过这些方法可以简单快速的把同步请求改为基于协程的异步请求,比如
《初识Python协程的实现》
中的同步请求,它的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import socketdef request (host: str ) -> None :str = f"http://{host} " 80 ))f"GET {url} HTTP/1.0\r\nHost: {host} \r\n\r\n" .encode("ascii" ))bytes = b"" bytes = sock.recv(4096 )while chunk:4096 )"\n" .join([i for i in response_bytes.decode().split("\r\n" )]))if __name__ == "__main__" :"so1n.me" )
这份代码只对
Socket
进行简单的调用,其中涉及到
Socket
的调用方法有:
是否涉及到IO
socket.socket
初始化socket
socket.connect
socket.send
socket.recv
在把它改为
Asyncio.Socket
时,只需要把涉及到IO的
Socket
方法以
loop.sock_xxx(sock, *param)
的形式进行修改,其中
xxx
是原来的方法名,
sock
则是通过
socket.socket
实例化的一个
sock
对象,而
param
则保持跟之前的一样的参数,更改后的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
import asyncioimport socketasync def request (host: str ) -> None :str = f"http://{host} " await loop.sock_connect(sock, (host, 80 ))await loop.sock_sendall(sock, f"GET {url} HTTP/1.0\r\nHost: {host} \r\n\r\n" .encode("ascii" ))bytes = b"" bytes = await loop.sock_recv(sock, 4096 )while chunk:await loop.sock_recv(sock, 4096 )"\n" .join([i for i in response_bytes.decode().split("\r\n" )]))if __name__ == "__main__" :"so1n.me" ))
Asyncio Socket
没有提供
send
方法,这里需要改为
sendall
。
可以看到,代码的改动并没有很大,除了传染性的
async
和
await
语法外,其它逻辑并没有什么明显的变化,在运行代码之后可以看到程序运行成功,并输出如下响应结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
HTTP/1.1 301 Moved Permanently
可以看到程序是正常运行的,为了了解
Asyncio.Socket
做了什么工作,接下来会翻阅源码,探究它的处理方法,首先是
loop.sock_connect
,它的源码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
async def sock_connect (self, sock, address ):if self._debug and sock.gettimeout() != 0 :raise ValueError("the socket must be non-blocking" )if sock.family == socket.AF_INET or (and sock.family == socket.AF_INET6):await self._ensure_resolved(type =sock.type , proto=sock.proto,0 ]return
await fut
这个方法分为三部分,首先是检查
Socket
的ssl并进行一些参数校验,然后通过
self._ensure_resolved
方法进行dns解析,最后才通过
self._sock_connect
方法进行真正建立连接。其中,dns解析方法
self._ensure_resolved
是
sock_connect
方法与其他
Socket
方法的不同点,它的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
async def _ensure_resolved (self, address, *, family=0 , type =socket.SOCK_STREAM, proto=0 , flags=0 , loop ):2 ]type , proto, *address[2 :])if info is not None :return [info]else :return await loop.getaddrinfo(host, port, family=family, type =type , proto=proto, flags=flags)async def getaddrinfo (self, host, port, *, family=0 , type =0 , proto=0 , flags=0 ):if self._debug:else :return await self.run_in_executor(None , getaddr_func, host, port, family, type , proto, flags)
通过源码发现,dns解析的逻辑中涉及到了
run_in_executor
方法,这个方法是把任务交给线程池进行处理。
run_in_executor
方法的原因是
POSIX
的DNS解析API是阻塞的,且没有提供异步选项,如果直接执行这个方法会卡住整个
Asyncio Event Loop
的运行,所以只能通过线程去调用这个API完成DNS解析,
Asyncio
的默认线程池数量很小,如果是做爬虫类等需要频繁的进行DNS解析的项目,需要把默认的线程池改大一些。
uvloop使用的libuv也选择了POSIX API,它的工作原理也是通过线程去执行DNS解析,详情见
why libuv do DNS request by multiple thread
在通过DNS进行地址解析后就拿到了真正的地址,这时可以开始进行真正的连接了,此时会调用
_sock_connect
方法去建立连接,它的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
def _sock_connect (self, fut, sock, address ):try :except (BlockingIOError, InterruptedError):except (SystemExit, KeyboardInterrupt):raise except BaseException as exc:else :None )def _sock_write_done (self, fd, fut, handle=None ):if handle is None or not handle.cancelled():def _sock_connect_cb (self, fut, sock, address ):if fut.done():return try :if err != 0 :raise OSError(err, f'Connect call failed {address} ' )except (BlockingIOError, InterruptedError):pass except (SystemExit, KeyboardInterrupt):raise except BaseException as exc:else :None )
这个方法的执行逻辑与其他的
Socket
方法的执行逻辑是类似,它们都会先尝试去执行
Socket
原先的方法,这时候如果操作系统准备就绪,那么意味着可以无阻塞的执行了
Socket
方法,否则是操作系统尚未准备好,需要捕获异常并对异常进行处理。
在捕获到异常后,会通过
_add_writer
添加了一个写事件的回调
_sock_connect_cb
,再通过fut添加一个fut完成时的
_sock_write_done
回调,然后就会把控制权交给了事件循环。
_sock_connect_cb
获取建立连接的结果,如果结果有异常,则把异常添加到fut中,否则就把结果放置到fut中,这样fut都会从
peding
状态变为
done
,fut也就会触发
_sock_write_done
移除掉事件循环对文件描述符的监听。
_add_reader
,
_remove_reader
,
_add_writer
与
_remove_writer
是
Asyncio
为
socket
与
selector
直接交互封装的方法,可以通过文章
《Python Asyncio调度原理》
进行了解。
除了
Socket.connect
方法外,与
Asyncio.Socket
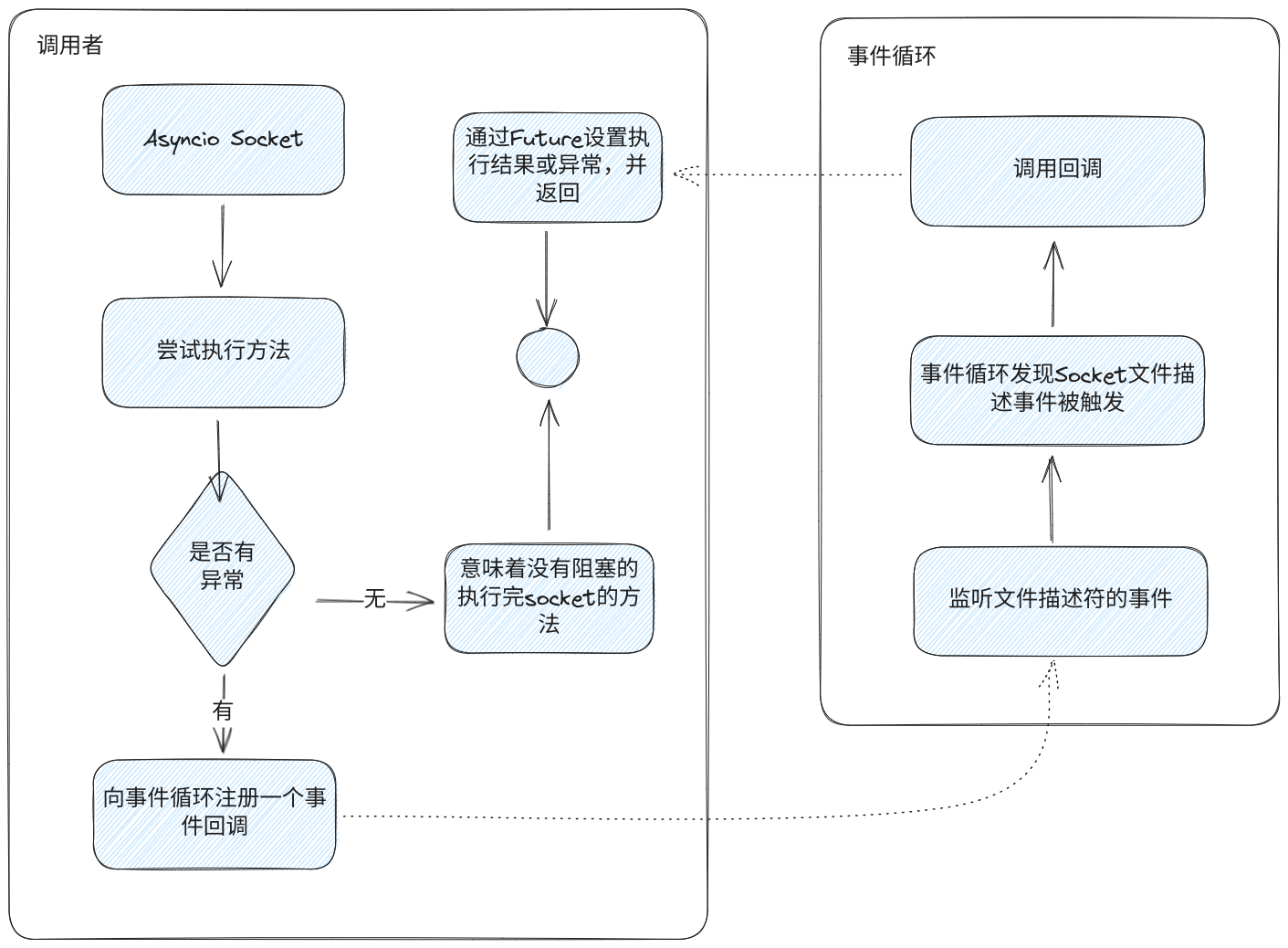
相关的方法还有很多,不过原理是一样的,它们的流程都可以简化为下图:
asyncio网络编程-asycnio-socket的执行逻辑.png
该图展示的是每个
Asyncio.Socket
方法的核心逻辑,各个方法具体的执行逻辑可以通过
源码
进行详细的了解,常见的
socket
方法与
Asyncio Socket
方法对照表如下:
sock方法
Asyncio Sock方法
listen
accept
sock_accept
connect
sock_connect
connect_ex
sock_recv
recv_info
sock_recv_into
recvfrom
sock_recvfrom
sendto
sock_sendto
Happy Eyeballs
create_connection
的源码比较简单,具体见:
https://github.com/python/cpython/blob/677320348728ce058fa3579017e985af74a236d4/Lib/asyncio/base_events.py#L976
对于服务端的
create_server
方法,它的处理逻辑一开始也是跟
create_connection
方法类似,也是先对
socket
和其他参数进行校验,然后再把参数和
Socket
放到
Server
实例中,接着再调用
Server
实例的
serve_forever
方法启动服务,而
serve_forever
的主要方法会调用到
_start_serving
方法(asyncio/base_events.py),如下:
1 2 3 4 5 6 7 8 9 10 11
def _start_serving (self ):if self._serving:return True for sock in self._sockets:
该方法会对所有托管的
socket
进行
listen
操作,并调用事件循环的
_start_serving
方法(asyncio/selector_events.py)为
Socket
向事件循环注册对应的可读事件回调,源码如下:
1 2 3 4 5 6 7 8
def _start_serving (self, protocol_factory, sock, sslcontext=None , server=None , backlog=100 , ssl_handshake_timeout=constants.SSL_HANDSHAKE_TIMEOUT, ssl_shutdown_timeout=constants.SSL_SHUTDOWN_TIMEOUT ):
通过源码可以看到这个方法是添加
Socket
文件描述符的可读事件回调,在添加之后每当
Socket
与客户端建立连接时,事件循环就会发现并调用
_accept_connection
方法,
_accept_connection
方法的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
def _accept_connection ( self, protocol_factory, sock, sslcontext=None , server=None , backlog=100 , ssl_handshake_timeout=constants.SSL_HANDSHAKE_TIMEOUT, ssl_shutdown_timeout=constants.SSL_SHUTDOWN_TIMEOUT ):for _ in range (backlog):try :False )except (BlockingIOError, InterruptedError, ConnectionAbortedError):return None except OSError as exc:if exc.errno in (errno.EMFILE, errno.ENFILE,'message' : 'socket.accept() out of system resource' ,'exception' : exc,'socket' : trsock.TransportSocket(sock),else :raise else :'peername' : addr}
通过源码可以发现
_accept_connection
方法的主要作用就是同时处理backlog个
socket
的
accept
方法。
Socket
在接收到新的请求后会马上通知给事件循环,然后等待事件循环去调用事件对应的回调,虽然
epoll
的处理速度很快了,但是
Socket
收到新的请求与回调的执行仍有一定的延迟。
accept
,那么处理整个程序
accept
的效率会降低,但是同时处理
Socket
的多个
accept
则可能会使系统的瞬间负载提高,所以这个方法会提供一个
backlog
参数供开发者选择
backlog
的大小以决定每次收到事件后执行多少次
accept
方法。
那么
backlog
的大小要怎么定义呢,其实这里的
backlog
与
_start_serving
方法(asyncio/base_events.py)中
listen
用到的
backlog
是一样的,而对于
listen
的backlog大小是需要根据场景来进行选择的,在Linux中,默认的backlog为128,而常见的后端服务的应用
Nginx
与
Redis
的默认值为511,这里不对
backlog
进行详细介绍,有兴趣的可以通过以下文章了解:
再聊 TCP backlog
What is “backlog” in TCP connections?
当
accept
成功后,则会调用
_accept_connection2
方法,
_accept_connection2
与客户端的
_create_connection_transport
一样,它创建了
Transport
实例和
Protocol
实例。不过在服务端中为了提高性能,通常都是一个协程对应一个
Protocol
&
Transport
,所以是通过
create_task
来执行
_accept_connection2
方法。
Nagle算法(英)
关于讨论Asyncio是否默认禁用Nagle算法的Issue(英)
在
Socket
创建完毕后,
Transport
会调用
Protocol
的
connection_made
表示
transport
创建完毕,然后再调用
_add_reader
方法向
socket
文件描述符注册了可读事件的回调函数
self._read_ready
。
__init__
方法无法被标记为
async
函数,所以这里使用了一个
waiter
用于标识
__init__
方法何时执行完毕,使其达到类似
async
函数的实现。
在
Transport
创建完毕后,每当
socket
收到一条消息,就会触发一个可读事件,然后事件循环就会执行
self._read_ready
去处理消息。
self._read_ready_cb
为
self._read_ready__data_received
,它对应的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
class _SelectorSocketTransport (_SelectorTransport ):def _read_ready__data_received (self ):if self._conn_lost:return try :except BaseException as exc:'Fatal read error on socket transport' )return if not data:return try :except BaseException as exc:'Fatal error: protocol.data_received() call failed.' )def _read_ready__on_eof (self ):try :except BaseException as exc:'Fatal error: protocol.eof_received() call failed.' )return if keep_open:else :
在去掉其中的异常处理后可以发现,实际上它的工作原理就是通过
sock.recv
接收数据,当收到的数据不为空时就调用
Protocol
的
data_received
把数据传递给开发者定义的方法中,为空时就调用
self._read_ready__on_eof
。
_read_ready__on_eof
的逻辑也是很简单的,它会调用
Protocol
的
eof_received
方法获取返回结果,这个结果是开发者定义的,开发者可以定义它返回的是
True
还是
False
,如果是返回
True
则只移除读监听事件,这样方便在关闭连接之前
Socket
还能继续发送消息,如果返回
False
则是直接关闭连接
Socket
,使
Socket
既不能读也不能写。
此外,还可以从源码看到在执行读事件的回调时如果有异常发生就会调用
_fatal_error
方法进行处理,这个方法除了报告异常外,还会关闭
Socket
。
Socket
是拥有读写两个缓冲区,也介绍了
Socket
支持只关闭一个缓冲区,另外一个缓冲区还能继续工作的情况,而在
Transport
中,只关闭写缓冲区称为普通关闭,两个缓冲区都关闭称为强制关闭,它们对应的方法为
close
和
abort
,其中
abort
方法与
_fatal_error
的功能是类似的,它们对应的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61
class _SelectorTransport (transports._FlowControlMixin, transports.Transport ):def abort (self ):None )def is_closing (self ):return self._closingdef close (self ):if self._closing:return True if not self._buffer:1 None )def __del__ (self, _warn=warnings.warn ):if self._sock is not None :f"unclosed transport {self!r} " , ResourceWarning, source=self)def _fatal_error (self, exc, message='Fatal error on transport' ):def _force_close (self, exc ):if self._conn_lost:return if self._buffer:if not self._closing:True def _call_connection_lost (self, exc ):try :if self._protocol_connected:finally :None None None if server is not None :None
通过源码可以发现
abort
与
_fatal_error
方法的唯一区别是
_fatal_error
方法会携带异常参数,
abort
的异常参数为空,而它们的执行逻辑都是调用
_force_close
方法对
Socket
进行强制关闭。
_force_close
方法被调用后,它会移除对应的事件监听,并把关闭连接的方法
_call_connection_lost
安排到
Asyncio Event Loop
中,交给
Asyncio Event Loop
调用。
Asyncio Event Loop
执行,这时如果强制关闭
Socket
会导致这些事件被调用时由于
Socket
已经关闭而无法发送或获取数据,所以需要把
_call_connection_lost
的调用安排在读/写事件之后被运行。(asyncio的调度是按照先进先出为原则)
通过源码也可以发现
close
方法相对
_force_close
方法的唯一的区别是在buffer缓冲不为空时不会移除写事件监听也不会调用
_call_connection_lost
方法,从而确保所有在buffer缓冲区的消息都能正常发送。另外
Transport
还有一个方法–
__del__
,它是确保
Transport
被回收时,
Socket
会被完全关闭,不然可能造成内存溢出。
关于
Python Socket
的内存溢出困扰了多个开源项目多年后才被解决,具体可以通过文章
《Fixing Memory Leaks In Popular Python Libraries》
了解。
最后,只剩下一个写数据的方法尚未窥探,它的相关源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
class _SelectorSocketTransport (_SelectorTransport ):def write (self, data ):if self._eof:raise RuntimeError('Cannot call write() after write_eof()' )if not self._buffer:try :except (BlockingIOError, InterruptedError):pass except BaseException as exc:'Fatal write error on socket transport' )return else :if not data:return def _write_ready (self ):if self._conn_lost:return try :except BaseException as exc:'Fatal write error on socket transport' )else :if n:del self._buffer[:n]if not self._buffer:if self._closing:None )elif self._eof:
这里比较特别的是写数据的方法
write
是一个普通的函数,这是因为
socket
底层有缓冲区,所以写入数据是非常方便的,且在设置不阻塞后,只要调用
socket.send
就可以把数据投递到缓冲区并马上返回,这个方法不涉及任何IO。
然而缓冲区也有满的情况,于是
Transport
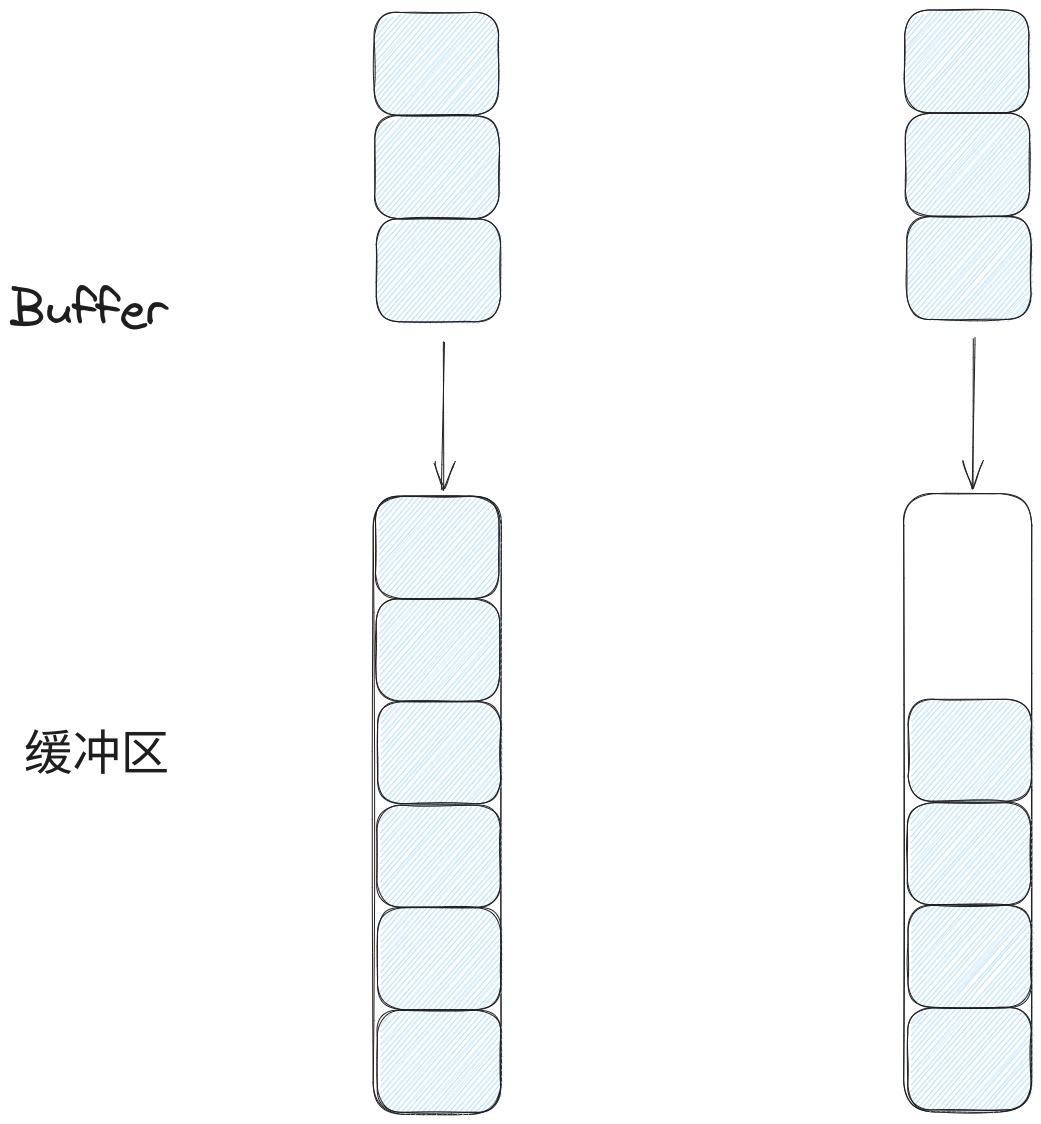
对缓冲区满的情况做一些处理,正常情况下缓冲区的满有两种情况,如下图:
asyncio网络编程-socket写缓冲区满的情况.png
图中假设缓冲区的大小为5,而投递数据的大小为3,对于图的左边,在投递数据的时候会发现缓冲区已经满,这时候操作系统会返回一个错误;而右边是投递时还没满的情况,这种情况下只能投递前面两个消息,此时
Transport
在执行
socket.send
方法后会获得到返回值为2,接着就删除
buffer
中前面的两个消息,只留下一个消息等待缓冲区可投递时再进行投递。
在后续如果缓冲区还不可投递时且仍有数据通过
write
方法被发送过来,
Transport
会把数据添加到
buffer
中,再监听可写事件,当
socket
可写时,才会调用
_write_ready
方法把
buffer
中的数据发送,这一个过程会随着可读事件的监听移除才结束,而只有
buffer
为空或者发送异常时,才会移除可读事件的监听。
在
write
源码中还可以看到
_maybe_resume_protocol
和
_maybe_pause_protocol
方法的相关调用,这两个方法都是为了控制写入速度的,毕竟
buffer
的长度是无限的,如果一些恶意客户端与服务端建立请求后,客户端选择拒收消息从而导致
buffer
会堆积一堆数据,而这些数据也是无意义同时在积累过多后可能导致服务端崩溃,所以需要根据
buffer
的积累数据的量决定暂停写入还是恢复写入。
除此之外,在
_ready_write
方法中还涉及到了
eof
机制,
eof
是
end of file
的缩写,它是表示流的结尾的标志。由于TCP是双工的协议,如果其中一端想关闭连接时,另一端可能正在发送数据,虽然程序不需要再写数据了,但不能直接关闭
Socket
,需要获取对方发送过来的所有数据后才能关闭。
socket
的
eof
机制就是用于告诉对位的读端在收到这个标记后就不需要再接收数据,且后续的数据发送完后也请尽快的关闭。
Transport
中通过
write_eof
方法提供了一个主动标记写通道为
eof
的功能,使用者也通过
can_write_eof
判断当前
Transport
是否可以使用
eof
机制,它们对应的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12
class _SelectorSocketTransport (_SelectorTransport ):def write_eof (self ):if self._closing or self._eof:return True if not self._buffer:def can_write_eof (self ):return True
可以看到
Transport
中与
eof
相关的源码很简单,它主要是先标记
_eof
为True,然后再判断当前的
buffer
是否为空,是的话就通过
sock.shutdown(socket.SHUT_WR)
关闭
Socket
中的写缓冲区。如果
buffer
不为空,则不做任何处理,在
_write_ready
发送完
buffer
的所有数据后再调用
sock.shutdown(socket.SHUT_WR)
关闭。
当服务端调用
sock.shutdown(socket.SHUT_WR)
后,客户端会通过
socket.recv
收到一条空消息,客户端会通过空消息判定是服务端到发送端已经
eof
了。
shutdown
与
close
的区别:
socket
对应的是操作系统的一个资源,多个进程可以拥有同一个
socket
的句柄,当调用
close
时,会把句柄的计数减为1,当句柄技计数为0的时候,
socket
才会真正的关闭并释放资源。而
shutdown
则是会关闭底层的连接,比如它可以关闭读端,写端或者同时关闭读写端,并等待对方发送FIN/EOF,但是它不会释放
socket
占用的资源,调用者仍然需要调用
shutdown
。
FlowControlMixin的源码
了解。