在huggingface上传数据集后,Dataset Viewer无法显示,报错:
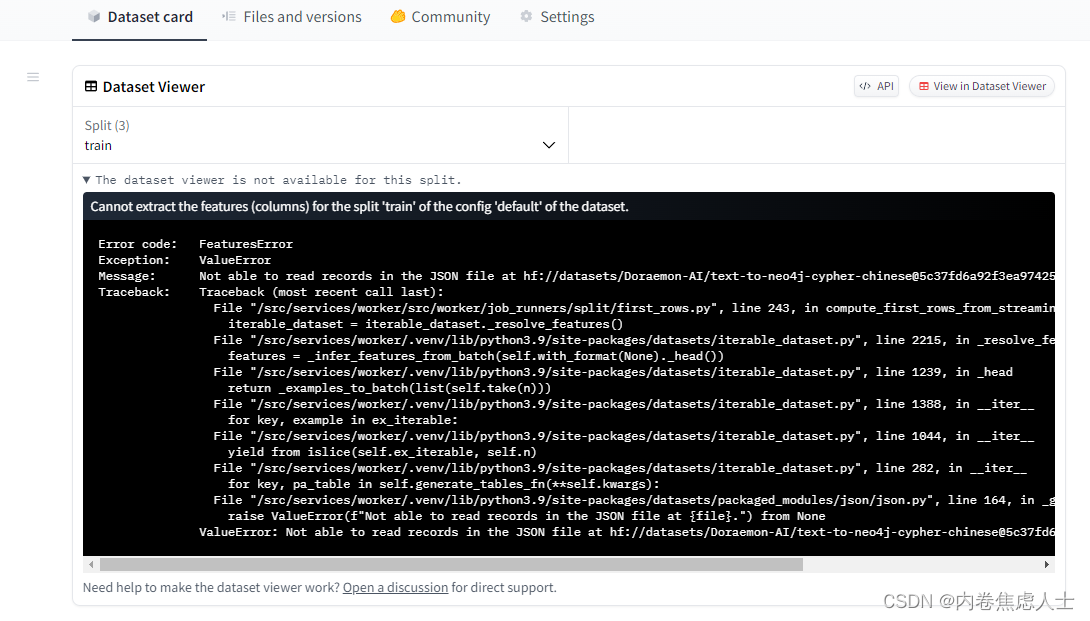
The dataset viewer is not available for this split.
Cannot extract the features (columns) for the split 'train' of the config 'default' of the dataset.
Error code: FeaturesError
Exception: ValueError
Message: Not able to read records in the JSON file at hf://datasets/xxx/train.json.
Traceback: Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/split/first_rows.py", line 243, in compute_first_rows_from_streaming_response
iterable_dataset = iterable_dataset._resolve_features()
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 2215, in _resolve_features
features = _infer_features_from_batch(self.with_format(None)._head())
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 1239, in _head
return _examples_to_batch(list(self.take(n)))
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 1388, in __iter__
for key, example in ex_iterable:
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 1044, in __iter__
yield from islice(self.ex_iterable, self.n)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 282, in __iter__
for key, pa_table in self.generate_tables_fn(**self.kwargs):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py", line 164, in _generate_tables
raise ValueError(f"Not able to read records in the JSON file at {file}.") from None
ValueError: Not able to read records in the JSON file at hf://datasets/xxx/train.json.
查看了别人展示的数据展示都好好的,就下载了一个看一下
发现别人的json文件都是一行一个字典
而我的是一个列表包含了很多字典
所以我就开始想办法转换成他们那样
import json
with open('train.json', 'r', encoding='utf-8') as f:
data = json.load(f)
with open('train_new.json', 'w', encoding='utf-8') as f:
for item in data:
json_string = json.dumps(item, ensure_ascii=False)
f.write(json_string + '\n')
print("处理完成")
然后我就在VSCode打开我的新文件,就出现了报错预期为文件结尾。json [行2,列1]
很低级的错误,我问了chatgtp4和claude都没有回答上来,百度搜索也搜不到
其实就是保存文件时应该是jsonl
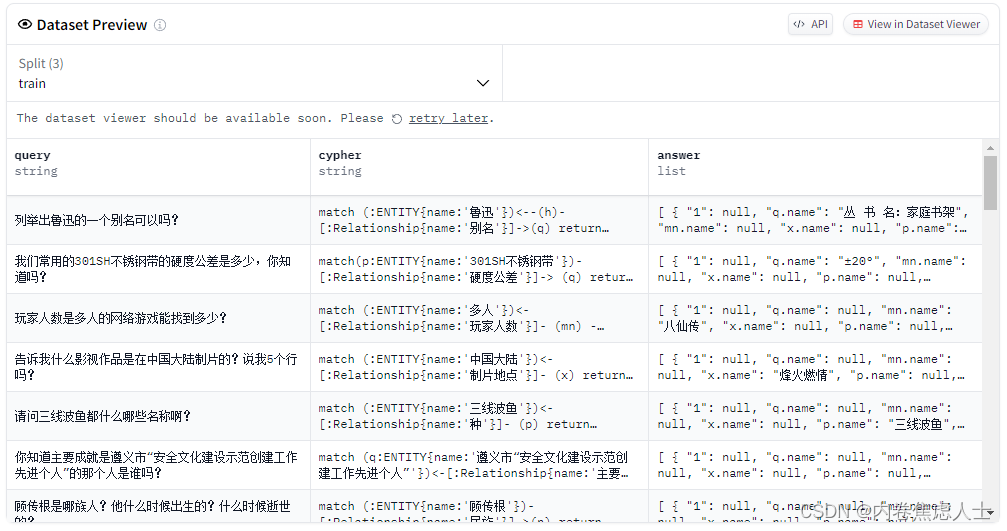
最后dataset viewer 正常展示了
1,json要解析的文件
{"data":[{"name":"sam","age":18},{"name":"leo","age":19},{"name":"sky","age":20}]};
将该文件可放在raw中文件名是以json 结尾
2,在MainActivity中进行解析
3,新建一个类,用于存放解析后的数据
package com.example.pulljiexi;
语法错误: 未预期的文件结尾。
出现了此错误提示,进行了如下的检查:1、检查Shell脚本的语法错误,更正之后再上传Linux系统下运行,错误提示依旧;2、文件结尾删除空行、添加空行;错误提示依旧。3、把shell脚本中的内容直接在命令行中执行,没有问题。
最后的解决方法(简单有效):
从Linux环境下找了一个可以成功执行的Shell脚本,下载到Windows环境下,更改文件名后直接在此
根据你提供的信息,可能是因为你指定的路径下确实没有以 .json 结尾的文件。在 launch.json 或 tasks.json 中,你需要确保指定的文件名以 .json 结尾,并且该文件存在于指定的路径下。你可以检查一下文件名和路径是否正确,并确保文件存在于指定的位置。如果文件名或路径不正确,你需要更新配置文件中的相应字段,以指向正确的文件。
#### 引用[.reference_title]
- *1* *2* *3* [cpp vocode launch.json 和 tasks.json](https://blog.csdn.net/MakeYouClimax/article/details/131197708)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v91^insert_down1,239^v3^insert_chatgpt"}} ] [.reference_item]
[ .reference_list ]
Authorization not available. Check if polkit service is running or see debug message for more inform
【新方案】RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`

