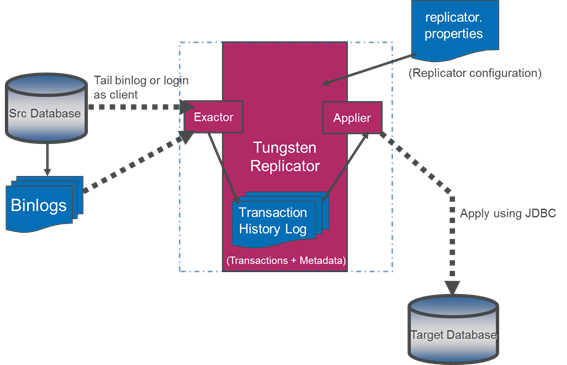
https://code.google.com/p/tungsten-replicator/wiki/Downloads
支持高版本MySQL向低版本复制,如5.1->5.0;
支持跨数据库系统的复制,如MySQL->Oracle,并且所支持的数据库不仅包括MySQL、PostgreSQL和Amazon RDS等传统关系型数据库,还包括MongoDB等NoSQL数据库以及Vertica、InfiniDB、Hadoop和Amazon RedShift等数据仓库;
支持多种复制拓扑结构,如Master-Slave、Multi-Master、Direct、Fan-In和Star等。
数据备份与恢复以及数据库基准测试工具等其他辅助功能点
https://www.cnblogs.com/fernandolee24/p/6259480.html
https://cloud.tencent.com/developer/article/1005413
https://blog.51cto.com/tanzj/595795
http://maxwells-daemon.io/
项目地址:
https://github.com/zendesk/maxwell
支持
SELECT*FROM table
的方式进行全量数据初始化
支持在主库发生failover后,自动恢复binlog位置(GTID)
可以对数据进行分区,解决数据倾斜问题,发送到kafka的数据支持database、table、column等级别的数据分区
工作方式是伪装为Slave,接收binlog events,然后根据schemas信息拼装,可以接受ddl、xid、row等各种event
https://cloud.tencent.com/developer/article/1403999
https://laijianfeng.org/2019/03/MySQL-Binlog-%E8%A7%A3%E6%9E%90%E5%B7%A5%E5%85%B7-Maxwell-%E8%AF%A6%E8%A7%A3/
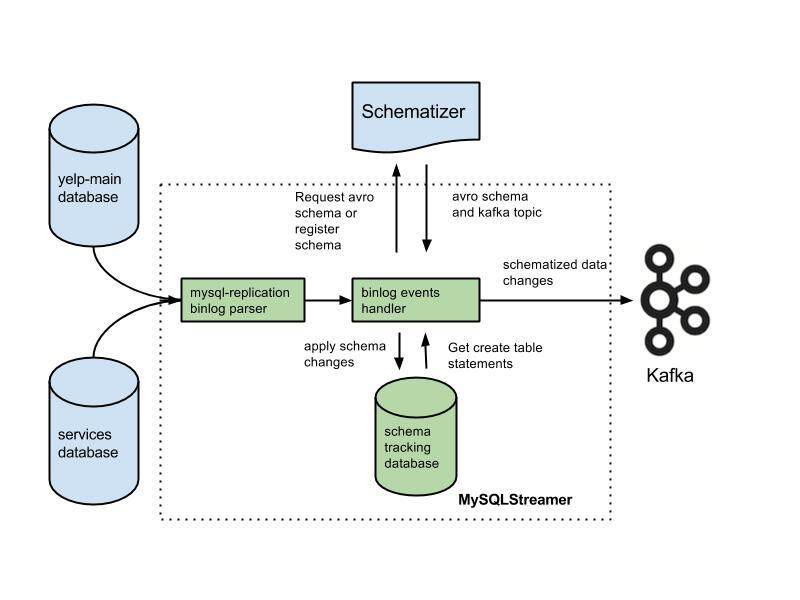
https://github.com/Yelp/mysql_streamer
https://www.infoq.cn/article/yelp-real-time-data-pipeline-part02
https://github.com/linkedin/camus
https://github.com/apache/incubator-gobblin
官网地址:
https://gobblin.readthedocs.io/en/latest/
特点 底层支持三种部署方式,分别是standalone,mapreduce,mapreduce on yarn。可以方便快捷的与Hadoop进行集成,上层有运行时任务调度和状态管理层,可以与Oozie,Azkaban进行整合,同时也支持使用Quartz来调度(standalone模式默认使用Quartz进行调度)。对于失败的任务还拥有多种级别的重试机制,可以充分满足我们的需求。再上层呢就是由6大组件组成的执行单元了。这6大组件的设计也正是Gobblin高度可扩展的原因。
Source:主要负责将源数据整合到一系列workunits中,并指出对应的extractor是什么。这有点类似于Hadoop的InputFormat。
Extractor:则通过workunit指定数据源的信息,例如kafka,指出topic中每个partition的起始offset,用于本次抽取使用。Gobblin使用了watermark的概念,记录每次抽取的数据的起始位置信息。
Converter:顾名思义是转换器的意思,即对抽取的数据进行一些过滤、转换操作,例如将byte arrays 或者JSON格式的数据转换为需要输出的格式。转换操作也可以将一条数据映射成0条或多条数据(类似于flatmap操作)。
Quality Checker:即质量检测器,有2中类型的checker:record-level和task-level的策略。通过手动策略或可选的策略,将被check的数据输出到外部文件或者给出warning。
Writer:就是把导出的数据写出,但是这里并不是直接写出到output file,而是写到一个缓冲路径( staging directory)中。当所有的数据被写完后,才写到输出路径以便被publisher发布。Sink的路径可以包括HDFS或者kafka或者S3中,而格式可以是Avro,Parquet,或者CSV格式。同时Writer也可是根据时间戳,将输出的文件输出到按照“小时”或者“天”命名的目录中。
Publisher:就是根据writer写出的路径,将数据输出到最终的路径。同时其提供2种提交机制:完全提交和部分提交;如果是完全提交,则需要等到task成功后才pub,如果是部分提交模式,则当task失败时,有部分在staging directory的数据已经被pub到输出路径了。
https://cloud.tencent.com/developer/article/1351988
https://github.com/whitesock/open-replicator
项目主页:
https://code.google.com/archive/p/open-replicator/
https://blog.csdn.net/u013256816/article/details/53072560
https://blog.csdn.net/menergy/article/details/17583823
https://galeracluster.com/
何谓Galera Cluster?就是集成了Galera插件的MySQL集群,是一种新型的,数据不共享的,高度冗余的高可用方案,目前Galera Cluster有两个版本,分别是Percona Xtradb Cluster及MariaDB Cluster,都是基于Galera的,所以这里都统称为Galera Cluster了,因为Galera本身是具有多主特性的,所以Galera Cluster也就是multi-master的集群架构,如图1所示:
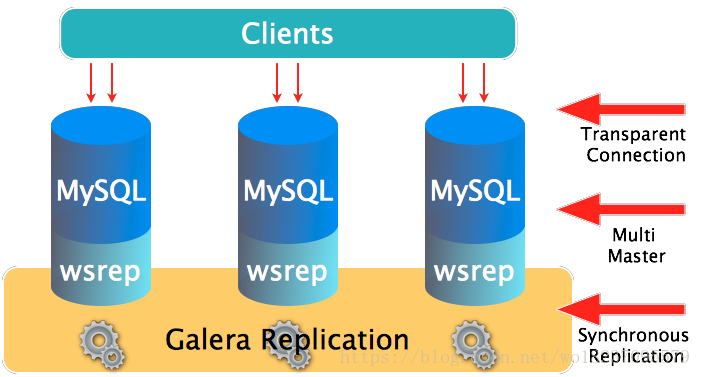 特性
特性
真正的多主集群,Active-Active架构;
同步复制,没有复制延迟;
多线程复制;行级别并行复制
没有主从切换操作,无需使用虚IP;
热备份,单个节点故障期间不会影响数据库业务;
支持节点自动加入,无需手动拷贝数据;
支持InnoDB存储引擎;
对应用程序透明,原生MySQL接口;
无需做读写分离;
部署使用简单。
http://www.yunweipai.com/archives/19574.html
https://juejin.im/post/5d36a4f551882537dc64a734
https://blog.csdn.net/qq_38125183/article/details/80861925
https://blog.csdn.net/wo18237095579/article/details/81270954
http://drmingdrmer.github.io/tech/mysql/2018/08/04/mysql-group-replication.html
https://www.cnblogs.com/kevingrace/p/10260685.html