现代应用程序越来越依赖基于容器和无服务器技术的计算平台来提供可扩展性、成本效率和敏捷性。尽管这种向更加分布式架构的转变带来了许多优势,但也增添了应用程序操作的复杂性。过去,调试就像登录服务器和检查日志一样简单直接。现在,需要更多地考虑如何在我们设计的应用程序中实现相同水平的可观察性。
在
结构合理的框架的无服务器剖析
中,我们建议了一些可观察性的最佳实践,例如结构化日志记录、分布式跟踪和指标监控。在本文中,我将演示如何使用新的开源 Lambda Powertools 库来执行其中一些最佳实践,而无需编写大量自定义代码。我将利用从
示例购物车微服务
中提取的实现示例,逐步介绍该库的入门过程:
关于 Lambda Powertools
Lambda Powertools
是一个自行选择的库,它将帮助实现可观察性的最佳实践,而不会造成无差别的繁重工作。它当前支持用 Python 编写的
AWS Lambda
函数,并支持运行时版本 3.6 和更高版本。Lambda Powertools 提供了三个核心实用工具:
Tracer
可提供一种从函数向
AWS X-Ray
发送跟踪的简单方法,以使您了解函数调用、与其他 AWS 服务的交互或外部 HTTP 请求。可将注释轻松添加到跟踪中,以允许基于关键信息筛选跟踪。例如,在使用跟踪器时,会为您创建
ColdStart
批注,以便您可以对存在初始化开销的跟踪轻松分组和分析。
Logger
可提供一个自定义的 Python 记录器类,输出结构化 JSON。它允许您传递字符串或更复杂的对象,并会负责序列化日志输出。可为您处理一些常见用例,例如记录 Lambda 事件有效负载和捕获冷启动信息,包括随时将自定义键添加到记录器。
Metrics
可简化从应用程序收集自定义指标的过程,而无需向外部系统发出同步请求。此功能由
Amazon CloudWatch 嵌入式指标格式 (EMF)
提供支持,该格式允许异步捕获指标。同样,为常见情况提供了便利功能,例如根据 CloudWatch EMF 规范验证指标以及机架冷启动。
以下步骤说明了如何为示例应用程序实现结构化日志记录、添加自定义指标以及启用 X-ray 跟踪。该示例应用程序使用
AWS 无服务器应用程序模型
(AWS SAM) 来管理部署,并由提供购物车功能的 REST API 以及单独的模拟“产品”服务组成。
首先,我们需要添加 Powertools 库作为函数的依赖项。该示例应用程序使用 AWS SAM 来构建函数,因此我们只需要将
aws-lambda-powertools
添加到我们的 requirements.txt 文件,声明 Powertools 库为依赖项:
/aws-serverless-shopping-cart/backend/shopping-cart-service/requirements.txt
boto3==1.10.34
requests==2.22.0
aws-lambda-powertools
我们将在应用程序 SAM 模板的
Globals
部分中使用环境变量,以将
通用配置
传递给 Powertools。还应该为我们的 Lambda 函数和
Amazon API Gateway
阶段启用主动跟踪,以便这些服务能够在上游请求中不存在跟踪时创建跟踪:
/aws-serverless-shopping-cart/backend/shoppingcart-service.yaml
Globals:
Function:
Tracing: Active
Environment:
Variables:
POWERTOOLS_METRICS_NAMESPACE: "ecommerce-app" POWERTOOLS_SERVICE_NAME: "shopping-cart"
TracingEnabled: true
接下来,在需要更新的Lambda 函数的代码中导入并初始化
Metrics
、
Logger
和
Tracer
类:
from aws_lambda_powertools import Metrics, Logger, Tracer
logger = Logger()
tracer = Tracer()
metrics = Metrics()
然后,我们可以通过将消息作为字符串传递,开始使用记录器来输出结构化日志:
logger.info("Initializing DDB Table %s", os.environ["TABLE_NAME"])
table = dynamodb.Table(os.environ["TABLE_NAME"])
输出将以 JSON 格式行写入 CloudWatch Logs:
"timestamp":"2020-06-15 08:27:42,730",
"level":"INFO",
"location":"<module>:17",
"service":"shopping-cart",
"sampling_rate":0,
"cold_start":false,
"function_name":"aws-serverless-shopping-cart-CheckoutCartFunction",
"function_memory_size":"512",
"function_arn":"arn:aws:lambda:us-east-1:123456789012:function:aws-serverless-shopping-cart-CheckoutCartFunction:live",
"function_request_id":"de9aee44-12fc-4e75-bc68-1848fc37ab3b",
"message": "Initializing DDB Table aws-serverless-shopping-cart-DynamoDBShoppingCartTable"
我们还可以将
inject_lambda_context
装饰器与 Lambda 处理程序结合使用,以自动丰富日志条目,包括有关该处理程序中所发出日志行的 Lambda 上下文的信息。另一个常见用例(尤其是在开发新的 Lambda 函数时)是打印处理程序接收到的事件的日志。这可以通过将
log_event
参数传递给装饰器来实现,装饰器默认情况下处于禁用状态,以防止潜在敏感事件数据泄漏到日志中:
@logger.inject_lambda_context(log_event=True)
def lambda_handler(event, context):
通过将日志作为结构化 JSON,我们可以使用 CloudWatch Logs Insights 对结构化数据执行搜索。在此示例中,我们正在搜索 Lambda 冷启动期间输出的所有日志,并在输出中显示关键字段:
通过使用提供的 capture_lambda_handler 装饰器,我们可以指示该库将 Lambda 函数执行时的跟踪和元数据发送到 AWS X-Ray。我们还可以使用 capture_method 捕获处理程序外部执行的其他函数,以为跟踪提供更详细的信息:
@tracer.capture_lambda_handler
def lambda_handler(event, context):
update_item("user1", "item1")
@tracer.capture_method
def update_item(user_id, item):
更新数据库中的项目
通过装饰 Lambda 处理程序,当流量流过时,我们将能够在 AWS X-Ray 控制台中查看生成的服务映射,从而大致了解流经应用程序的所有流量:
我们可以进一步深入了解单个跟踪,在这种情况下,这表示向我们的 API 发送单个 POST 请求,以将商品添加到用户的购物车中。在跟踪图之后,我们可以看到我们的请求触及了 API 网关,这又触发了添加到购物车 Lambda 函数。然后,该函数将数据写入 Amazon DynamoDB,并向产品服务发出请求,该产品服务本身由 API Gateway 和 Lambda 组成。
我们还可以查看生成的单个跟踪,以及组成跟踪的分段和子分段的瀑布视图。如果我们想查明应用程序中操作缓慢或错误的根本原因时,这些数据将非常宝贵:
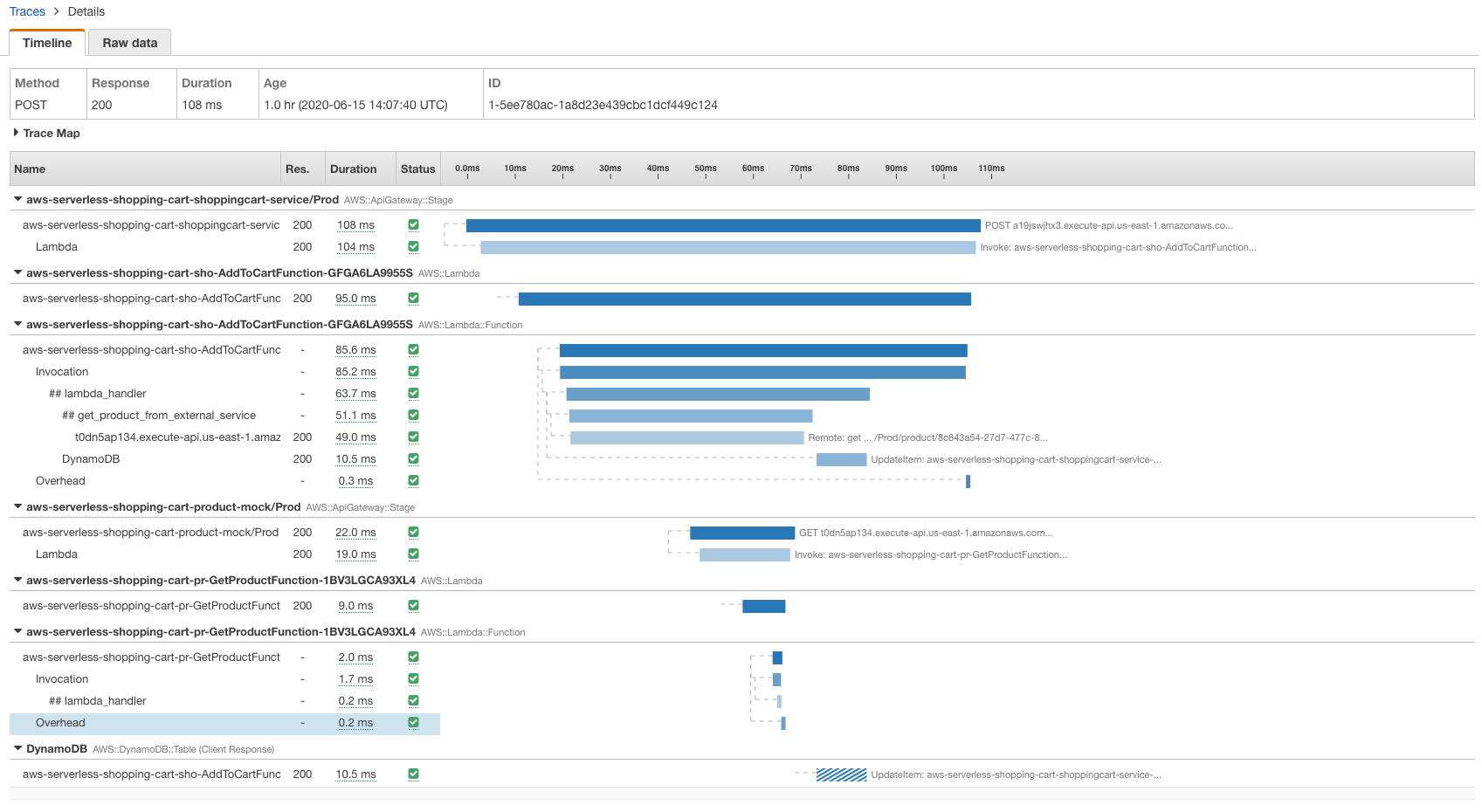
如果需要,我还可以通过注释筛选跟踪,并使用 X-Ray 跟踪组创建自定义服务图。在本例中,我可以使用筛选器表达式 annotation.ColdStart = true 基于 ColdStart 注释筛选跟踪,PowerTools 会自动添加该注释:
最后,让我们向应用程序添加自定义指标。借助 CloudWatch,许多现成的可用指标可以帮助回答有关应用程序的吞吐量、错误率、资源利用率等一般性问题。但是,为了更好地了解应用程序和最终客户的行为,我们还需要收集与业务相关的自定义指标。在我们的购物车服务中,我们想了解客户向购物车添加商品的频率,或者用户成功购买购物车中商品的频率。
使用 Powertools 组织指标时,我们需要考虑指标名称空间、维度和指标名称。命名空间是最高级别的容器,可以包含多个服务,而服务又可以包含多个指标。维度是指标元数据,可帮助切片和分割指标可视化,例如服务名称,我们之前将其设置为环境变量,并通过 Powertools 自动为您添加。
要创建自定义指标,我们首先使用 log_metrics 装饰 Lambda 函数。这将确保函数执行完毕后,所有指标均已正确序列化并刷新到日志中。然后,我们可以通过调用 add_metrics 发出自定义指标。我们还可以选择将 capture_cold_start_metric 参数传递给 log_metrics 装饰器,以自动创建冷启动指标:
@metrics.log_metrics(capture_cold_start_metric=True)
def lambda_handler(event, context):
check_out_cart() # Function to process the checkout
metrics.add_metric(name="CartCheckedOut", unit="Count", value=1)
CloudWatch Metrics 使我们可以为这些指标构建可视化;在本例中,我们可以看到购物车已更新、检查或迁移了多少次(从匿名用户重新分配给经过身份验证的用户):
汇集分析所有指标
在许多情况下,我们希望将日志记录、指标和跟踪功能一起用于 Lambda 函数。我们可以将装饰器堆叠在一起,但是为了确保正确刷新指标,我们应该将 log_metrics 装饰器放在顶部:
/aws-serverless-shopping-cart/backend/checkout_cart.py
import json
import logging
import os
import boto3
from aws_lambda_powertools import Logger, Tracer, Metrics
from boto3.dynamodb.conditions import Key
from shared import get_headers, generate_ttl, handle_decimal_type, get_cart_id
logger = Logger() tracer = Tracer() metrics = Metrics()
dynamodb = boto3.resource("dynamodb")
logger.info("Initializing DDB Table %s", os.environ["TABLE_NAME"])
table = dynamodb.Table(os.environ["TABLE_NAME"])
@metrics.log_metrics(capture_cold_start_metric=True) @logger.inject_lambda_context(log_event=True) @tracer.capture_lambda_handler
def lambda_handler(event, context):
更新购物车表,以使用用户标识符而不是匿名 cookie 值作为键。用户登录时将调用
logger.debug(event)
cart_id, _ = get_cart_id(event["headers"])
# 由于此方法是在 API 网关层授权的,因此我们无需在此处验证 JWT 声明
user_id = event["requestContext"]["authorizer"]["claims"]["sub"]
except KeyError:
logger.warn("Invalid user tried to check out cart")
return {
"statusCode": 400,
"headers": get_headers(cart_id),
"body": json.dumps({"message": "Invalid user"}),
# Get all cart items belonging to the user's identity
response = table.query(
KeyConditionExpression=Key("pk").eq(f"user#{user_id}")
& Key("sk").begins_with("product#"),
ConsistentRead=True, # Perform a strongly consistent read here to ensure we get correct and up to date cart
cart_items = response.get("Items")
#batch_writer 将用于更新属于该用户的购物车条目的状态
with table.batch_writer() as batch:
for item in cart_items:
# Delete ordered items
batch.delete_item(Key={"pk": item["pk"], "sk": item["sk"]})
metrics.add_metric(name="CartCheckedOut", unit="Count", value=1) logger.info({"action": "CartCheckedOut", "cartItems": cart_items})
return {
"statusCode": 200,
"headers": get_headers(cart_id),
"body": json.dumps(
{"products": response.get("Items")}, default=handle_decimal_type
奖励:自带中间件实用工具
在上述核心实用工具之上,该库提供了一个名为 lambda_handler_decorator 的中间件工厂实用工具。这提供了一种将自定义逻辑连接到 Lambda 请求生命周期,在处理程序之前和之后执行代码的简单方法。您的中间件可以从处理程序访问事件、上下文和响应:
from aws_lambda_powertools.middleware_factory import lambda_handler_decorator
@lambda_handler_decorator
def middleware_before_after(handler, event, context):
# logic_before_handler_execution()
def lambda_handler(event, context):
# logic_after_handler_execution()
return response;
# @middleware_before_after(trace_execution=True) Optionally trace your middleware execution
@middleware_before_after
def lambda_handler(event, context):
您可能想要为事件有效负载添加自定义验证,或为响应添加自定义序列化。从头开始执行此操作可能很耗时且容易出错,因此,使用中间件工厂来消除复杂性。
Amazon CloudWatch 和 AWS X-Ray 提供了许多功能,可用于为您的应用程序提供全面的可观察性。如果您使用 AWS Lambda 运行 Python 函数,则 Lambda Powertools 库可以帮助您从这些服务中获得最大价值,同时最大程度地减少需要编写的自定义代码量。如果您想扩展本文提供的示例,则可以在 GitHub 上的示例购物车应用程序 中看到我为开始使用 Powertools 库所做的更改。
Lambda Powertools现已正式发布,我们很乐意听到您对使用它进行构建的反馈。
您可以在 Github 中找到 Lambda Powertools 的完整文档 和源代码。欢迎通过 Pull 请求捐款,如果您对项目有任何反馈,建议您创建问题。

