NIPS2023 | Towards Generic Semi-Supervised Framework for Volumetric Medical Image Segmentation
#医学图像
 论文:
[2310.11320] Towards Generic Semi-Supervised Framework for Volumetric Medical Image Segmentation (arxiv.org)
论文:
[2310.11320] Towards Generic Semi-Supervised Framework for Volumetric Medical Image Segmentation (arxiv.org)
代码:
https://github.com/xmed-lab/GenericSSL
摘要
在三维医学图像中进行
体积级标注
是一项耗时的任务,需要专业知识。因此,越来越多的人对使用
半监督学习(SSL)
技术来训练有限标记数据的模型产生了兴趣。然而,挑战和实际应用不仅限于SSL,还包括
无监督领域自适应(UDA)
和
半监督领域泛化(SemiDG)
等问题。本文旨在开发一个通用的SSL框架,可以处理所有三种问题。本文在现有的 SSL 框架中确定了实现这一目标的两个主要障碍:
1)捕捉分布不变特征的弱点;2)未标记数据往往被标记数据压倒,导致训练期间过度拟合标记数据
。为了解决这些问题,我们提出了一个
聚合和解耦框架
。聚合部分包括
一个扩散编码器
,通过从多个分布/领域的聚合信息中
提取分布不变特征来构建一个公共知识集
。解耦部分包括
三个解码器
,
将标记和未标记数据的训练过程解耦
,从而避免过度拟合标记数据、特定领域和类别
本文在四个基准数据集上评估提出的框架,包括SSL、类不平衡SSL、UDA和SemiDG。结果显示,在所有四个设置中,与最先进的方法相比,本文的框架都有显着的改进,表明本文的框架有潜力应对更具挑战性的SSL场景
引入
在半监督体积医学图像分割(SSVMIS)领域,已经提出了各种SSL技术,以利用标记和未标记数据。然而,当
前的SSVMIS方法假设标记和未标记数据来自同一领域,即它们共享相同的分布
。实际上,医学图像通常是
使用不同的扫描仪从不同的临床中心收集的,导致显著的领域转移。这些转移是由患者群体、扫描仪和扫描获取设置的差异引起的
。因此,这些SSVMIS方法在实际应用场景中存在局限性,并经常遇到过拟合问题,导致结果不理想
为了解决这一局限性,研究人员越来越多地关注
无监督领域适应(UDA)技术
。这些技术利用标记数据(源域)和未标记数据(目标域)进行训练,但数据来自不同的域。此外,半监督领域泛化(SemiDG),一种更严格的场景,已经引起了人们的极大兴趣。SemiDG 在训练过程中利用来自多个域的标记和未标记数据,并在看不见的域上进行评估。目前,针对这三个场景的方法是单独优化的,目前还没有在统一框架内处理所有三个场景的现有方法。然而,鉴于所有训练阶段都涉及已标记和未标记的数据,探索一个通用的基于SSL的框架是很直观的,该框架可以处理所有问题并消除复杂的特定于任务的设计的需要。因此,本文旨在开发一个能够处理现实世界场景中现有挑战的通用框架,包括:
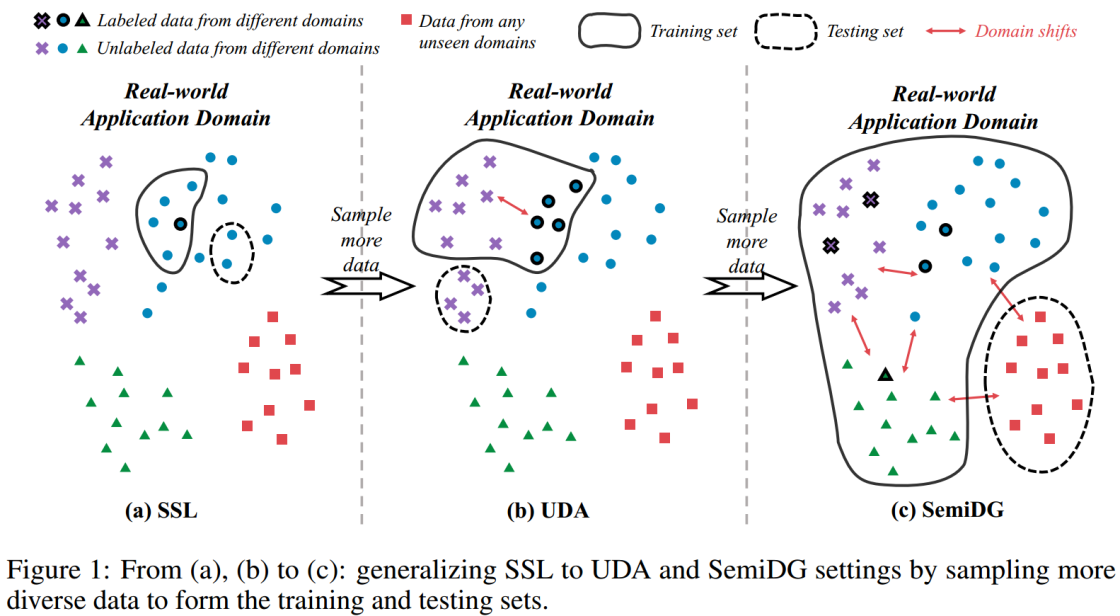
(1)场景一:SSL,用于训练和测试的样本数据来自于相同的域
(2)场景二:UDA,样本数据来自于两个不同的域,目标域的标签不可访问
(3)场景三:SemiDG,样本数据来自于多个域,其中只有有限数量的域被标记
潜在的相似之处可以归纳为:(1)
在训练阶段,既使用有标签的数据,也使用无标签的数据
;(2)在现实应用领域的场景中,无论是SSL域的分布漂移还是UDA和SemiDG的域漂移都可以视为
采样偏差
,即主要的区别在于我们
如何对图1中的数据进行采样
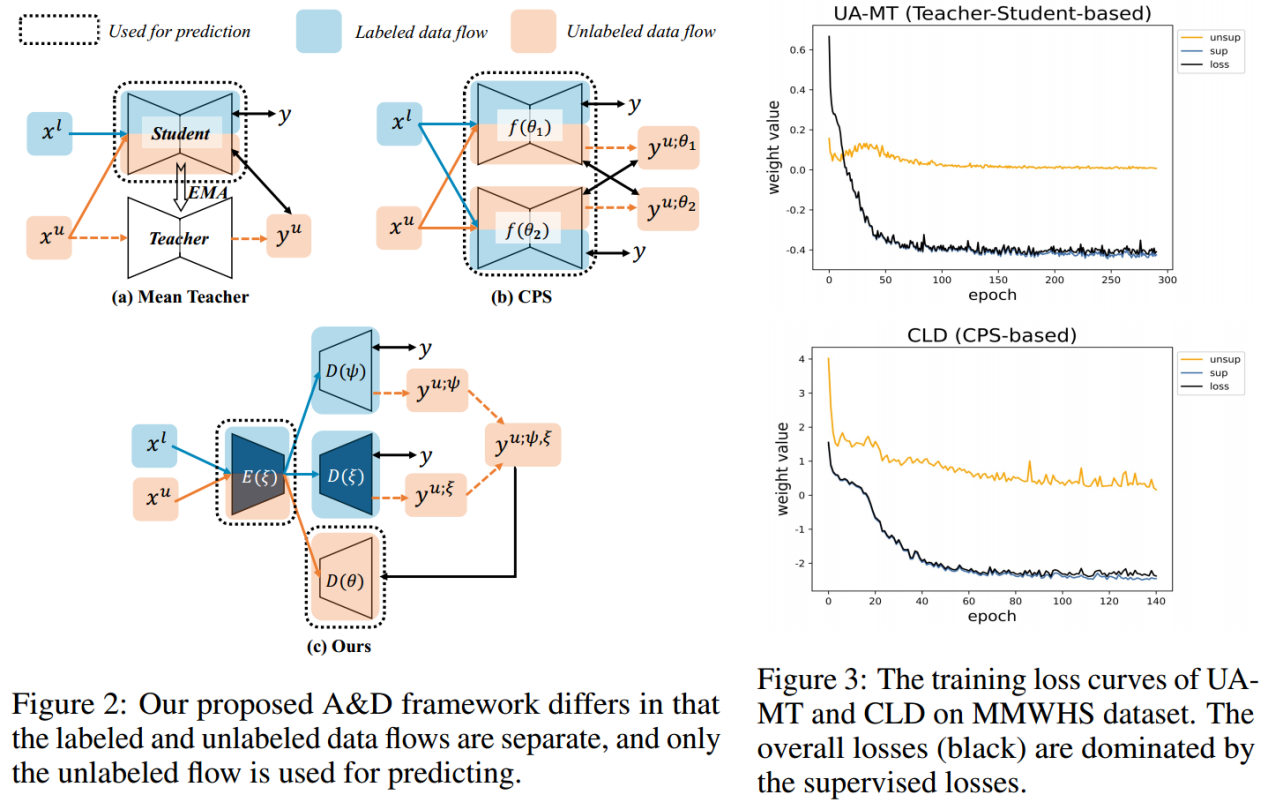
现有的SSL方法在UDA和SemiDG设置下不能很好地工作,反之亦然。主要的障碍之一是
这些模型严重的过拟合,这是由于训练过程中标签数据占主导地位造成的
。具体来说,现有的SSVMIS方法主要基于两个框架:(1)教师-学生框架,其中一个学生模型首先用已标记的数据进行训练,从学生模型的EMA获得的教师模型生成伪标签以使用已标记数据重新训练学生模型(2)CPS(交叉伪监督)框架,其利用两个扰动模型之间的一致性,其中一个网络生成的伪标签将用于训练另一个网络。这两个主要框架中的预测模块都用标记数据和未标记数据进行训练;然而,
以精确的 GroundTruth 为监督的标记数据比未标记数据收敛得更快
。因此,训练过程很容易被监督的训练任务淹没,如图3所示。另一个挑战在于,
现有的SSVMIS方法无法解决分布转移的问题,更不用说域转移了,这导致在捕获与分布变化不变的特征方面受到限制
基于主流SSVMIS方法的相似性和主要缺点,本文认为如果能够
解决过拟合问题
,并设计出
有效的方法来捕捉分布不变的特征
,那么就有可能建立一个通用的框架。本文提出了一种聚合和解耦框架,
在聚合阶段使用扩散模型,提出了一种Diff-vNet,将多个领域的特征聚集到一个共享的编码器中,构造一个共同的知识集,以提高捕获分布不变特征的能力
。为了解决过拟合问题,在解耦阶段,我们将解码过程解耦为(1)标记数据训练流程,主要更
新Diff-vNet解码器
和
难度感知 V-net 解码器
以生成高质量的伪标签;(2)未标记数据训练流程,主要在伪标签的监督下更新另一个
Vanilla V-Net解码器
。Diff-VNet解码器的去噪过程提供了域无偏的伪标签,而难度感知 VNet 解码器的去噪过程提供了类无偏的伪标签。为了进一步提高伪标签的质量,我们还提出了一种重新参数化和平滑相结合的策略
本文的主要工作可以概括如下:(1)将用于体素级医学图像分割的SSL、类不平衡SSL、UDA和SemiDG
统一到一个通用框架中
;(2)阐述了当前SSL方法的过拟合问题,并
提出了一种有效的数据增强策略和分别针对标记数据和未标记数据的解耦器来解决该问题
;(3)引入扩散V-Net来学习来自不同领域的潜在特征分布,从而将 SSL 方法推广到更现实的应用场景;(4)提出的聚合与解耦框架在具有代表性的数据集上实现了 SOTA,包括SSL、类不平衡的SSL、UDA和SemiDG任务。值得注意的是,在 MR 到 CT 设置中,我们的方法在 Synapse 数据集(Dice中为12.3)和MMWHS数据集(Dice中为8.5)上取得了显著的改进。为了验证所提出的方法的有效性,进行了广泛的消融研究
方法
聚合与解耦框架概述
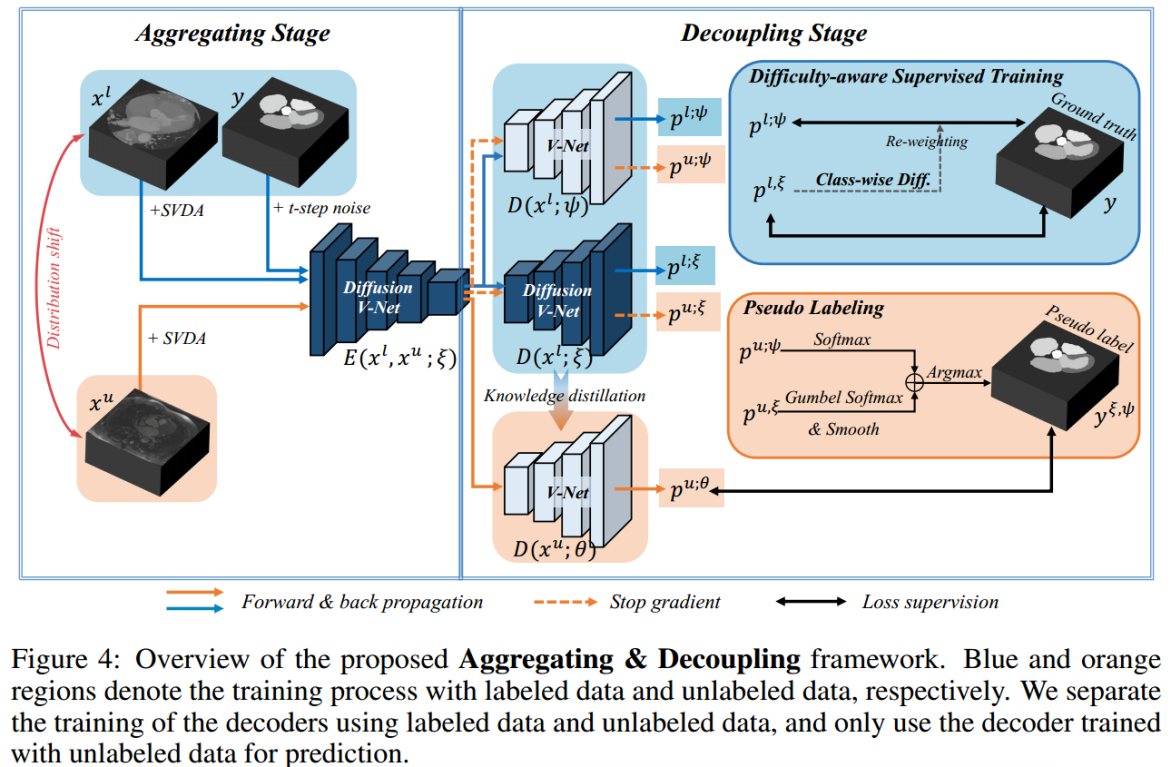
聚合阶段的目标是基于所有的数据共享共同的底层高级知识的思想来构建跨域的公共知识集,例如纹理信息。
通过聚合来自多个领域的信息并进行联合训练,编码器可以捕获潜在的领域不变特征
。为了实现这一点,我们引入了一种强大而高效的基于采样的体积数据增强(SVDA)策略来扩大分布多样性,并利用扩散模型来捕捉多样化数据的不变特征。
在目前的 SSL 解码器中,解码器同时使用有标签和无标签的数据进行训练,这导致了耦合和过拟合问题,进一步阻碍了向通用SSL的扩展。解耦阶段旨在
通过解耦已标记和未标记的数据训练流来解决这些问题
。具体来说,对于带标签的数据流,(1) 扩散译码主要用于引导扩散编码器通过扩散反向过程学习分布不变的表示,从而产生域无偏的伪标签;(2)采用所提出的难度感知重加权策略的Vanilla V-Net译码主要是为了避免模型对容易类和多数类的过度拟合,从而产生类无偏的伪标签。然后,对于未标记的数据流,通过提出的
重新参数化和平滑(RS)策略
对域和类无偏的伪标签进行集成,以生成高质量的伪标签。最后,伪标签被用于监督额外的 V-Net 解码器的训练,仅用于预测
聚合阶段
 解耦阶段
解耦阶段

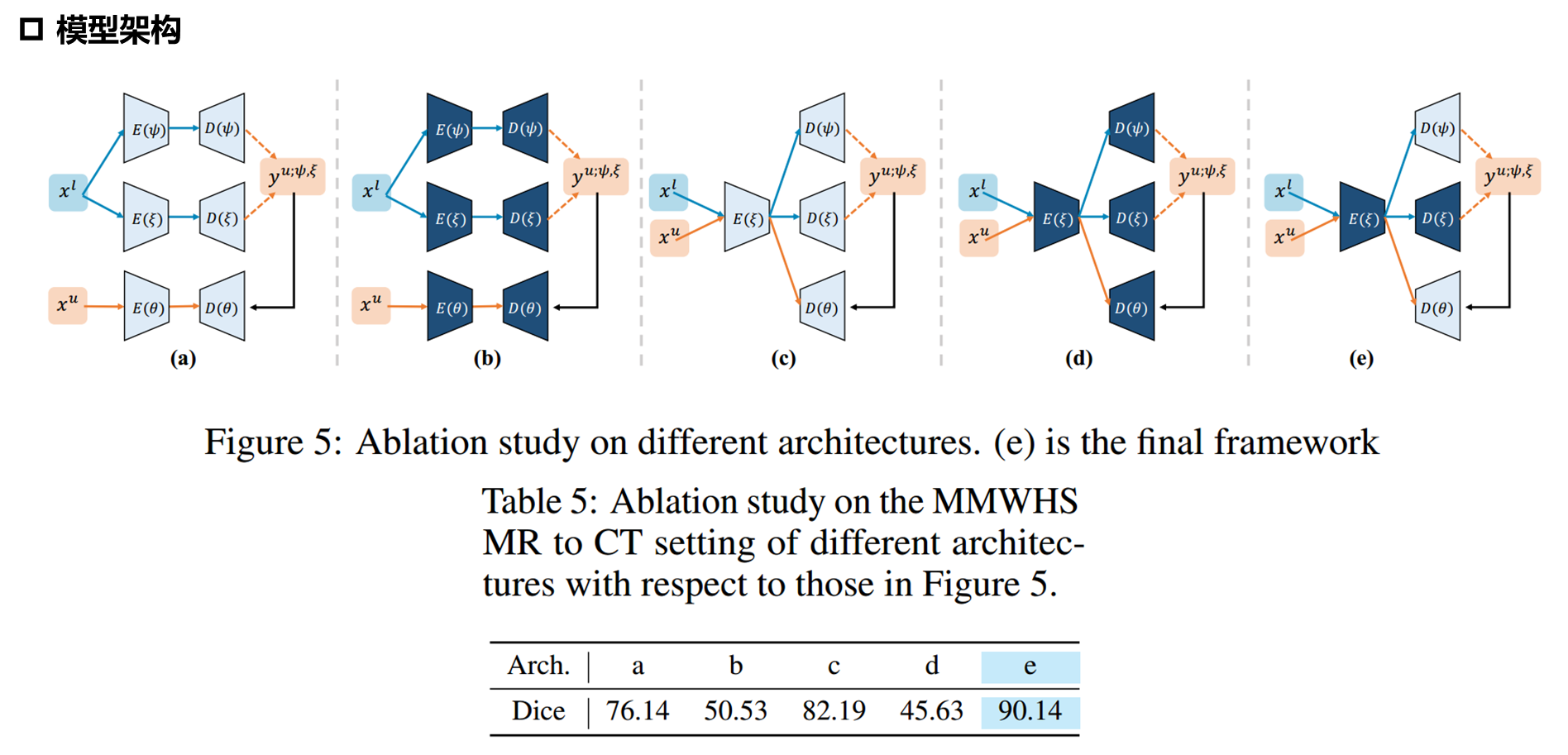
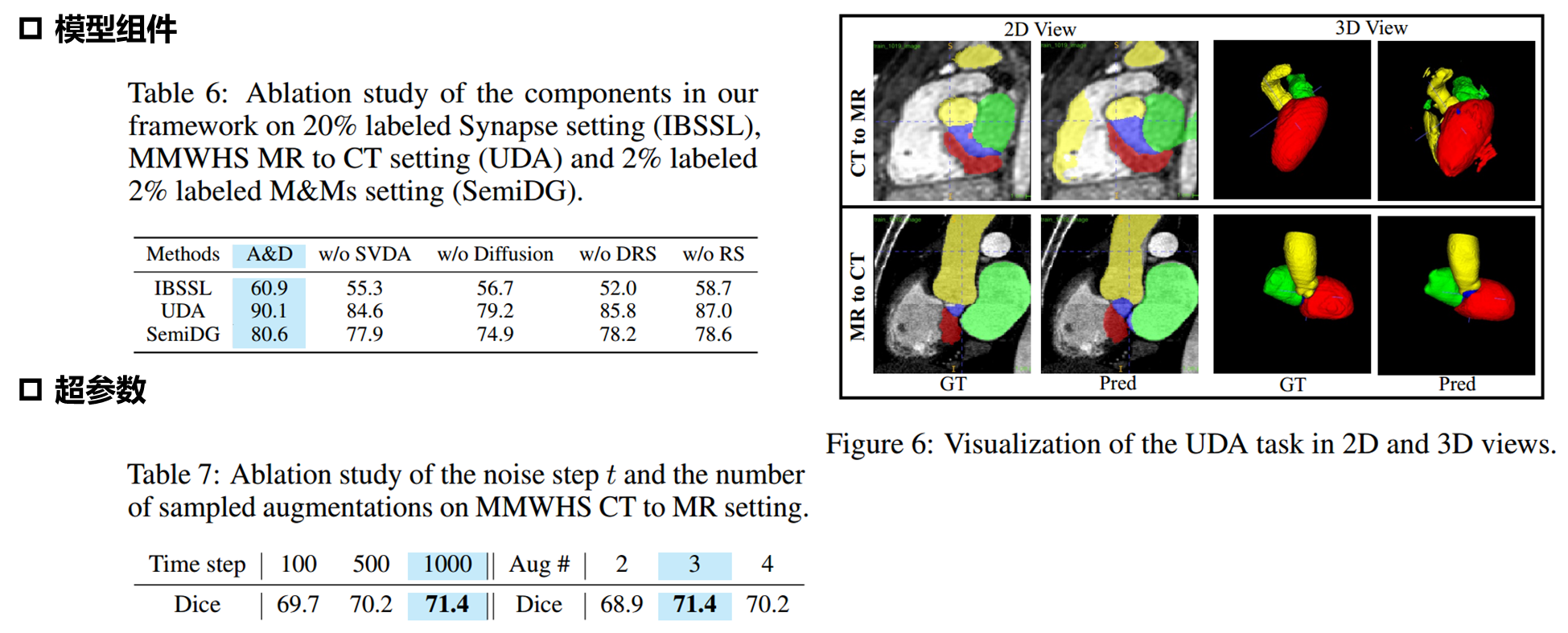
 消融实验
消融实验
模型架构
NeuCom | An image segmentation method of a modified SPCNN based on human visual system in ...
2024-01-23 发布
NIPS2023 | Towards Generic Semi-Supervised Framework for Volumetric Medical Image Segmentation
2023-11-24 发布
Sci Data | A Large-scale Synthetic Pathological Dataset for Deep Learning-enabled Segmentation ...
2023-09-19 发布

