|
key 是任意字符串,最多 253 个字符。key 必须以字母或数字开头,可以包含字母、数字、连字符、句点和下划线。
value
value 是任意字符串,最多 63 个字符。value 必须以字母或数字开头,可以包含字母、数字、连字符、句点和下划线。
effect
effect 的值包括:
NoSchedule [1]
与污点不匹配的新 pod 不会调度到该节点上。
该节点上现有的 pod 会保留。
PreferNoSchedule
与污点不匹配的新 pod 可以调度到该节点上,但调度程序会尽量不这样调度。
该节点上现有的 pod 会保留。
NoExecute
与污点不匹配的新 pod 无法调度到该节点上。
节点上没有匹配容限的现有 pod 将被移除。
operator
Equal
key/value/effect 参数必须匹配。这是默认值。
Exists
key/effect 参数必须匹配。您必须保留一个空的 value 参数,这将匹配任何值。
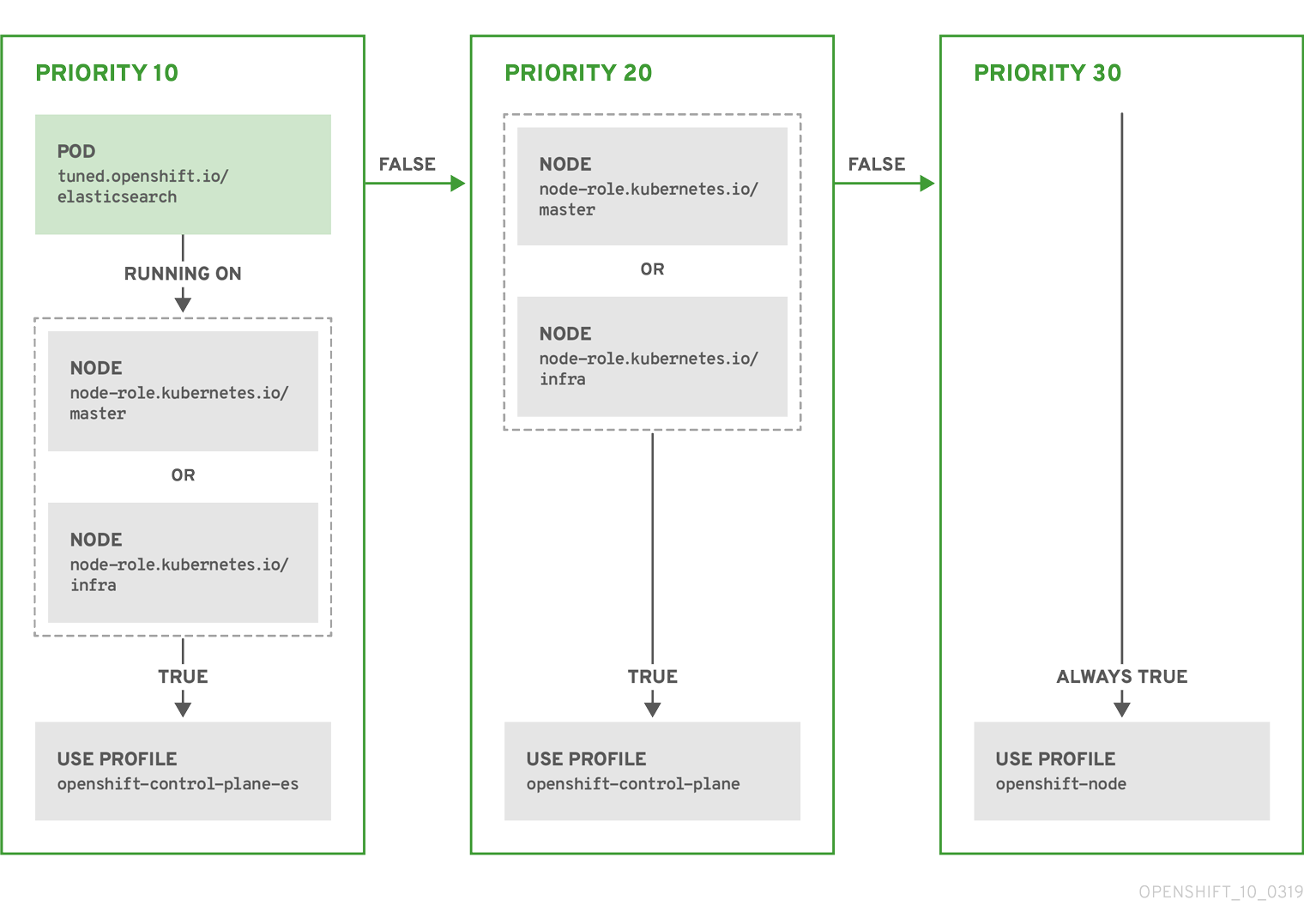
如果向 control plane 节点添加了一个 NoSchedule 污点,节点必须具有 node-role.kubernetes.io/master=:NoSchedule 污点,这默认会添加。
apiVersion: v1
kind: Node
metadata:
annotations:
machine.openshift.io/machine: openshift-machine-api/ci-ln-62s7gtb-f76d1-v8jxv-master-0
machineconfiguration.openshift.io/currentConfig: rendered-master-cdc1ab7da414629332cc4c3926e6e59c
name: my-node
spec:
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
容限与污点匹配:
如果 operator 参数设为 Equal:
key 参数相同;
value 参数相同;
effect 参数相同。
如果 operator 参数设为 Exists:
key 参数相同;
effect 参数相同。
OpenShift Container Platform 中内置了以下污点:
node.kubernetes.io/not-ready:节点未就绪。这与节点状况 Ready=False 对应。
node.kubernetes.io/unreachable:节点无法从节点控制器访问。这与节点状况 Ready=Unknown 对应。
node.kubernetes.io/memory-pressure:节点存在内存压力问题。这与节点状况 MemoryPressure=True 对应。
node.kubernetes.io/disk-pressure:节点存在磁盘压力问题。这与节点状况 DiskPressure=True 对应。
node.kubernetes.io/network-unavailable:节点网络不可用。
node.kubernetes.io/unschedulable:节点不可调度。
node.cloudprovider.kubernetes.io/uninitialized:当节点控制器通过外部云提供商启动时,在节点上设置这个污点来将其标记为不可用。在云控制器管理器中的某个控制器初始化这个节点后,kubelet 会移除此污点。
node.kubernetes.io/pid-pressure :节点具有 pid 压力。这与节点状况 PIDPressure=True 对应。
OpenShift Container Platform 不设置默认的 pid.available evictionHard。
4.6.1.1. 了解如何使用容限秒数来延迟 pod 驱除
您可以通过在 Pod 规格或 MachineSet 对象中指定 tolerationSeconds 参数,指定 pod 在被驱除前可以保持与节点绑定的时长。如果将具有 NoExecute effect 的污点添加到节点,则容限污点(包含 tolerationSeconds 参数)的 pod,在此期限内 pod 不会被驱除。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
在这里,如果此 pod 正在运行但没有匹配的容限,pod 保持与节点绑定 3600 秒,然后被驱除。如果污点在这个时间之前移除,pod 就不会被驱除。
您可以在同一个节点中放入多个污点,并在同一 pod 中放入多个容限。OpenShift Container Platform 按照如下所述处理多个污点和容限:
处理 pod 具有匹配容限的污点。
其余的不匹配污点在 pod 上有指示的 effect:
如果至少有一个不匹配污点具有 NoSchedule effect,则 OpenShift Container Platform 无法将 pod 调度到该节点上。
如果没有不匹配污点具有 NoSchedule effect,但至少有一个不匹配污点具有 PreferNoSchedule effect,则 OpenShift Container Platform 尝试不将 pod 调度到该节点上。
如果至少有一个未匹配污点具有 NoExecute effect,OpenShift Container Platform 会将 pod 从该节点驱除(如果它已在该节点上运行),或者不将 pod 调度到该节点上(如果还没有在该节点上运行)。
不容许污点的 Pod 会立即被驱除。
如果 Pod 容许污点而没有在 Pod 规格中指定 tolerationSeconds,则会永久保持绑定。
如果 Pod 容许污点,且指定了 tolerationSeconds,则会在指定的时间里保持绑定。
向节点添加以下污点:
$ oc adm taint nodes node1 key1=value1:NoSchedule $ oc adm taint nodes node1 key1=value1:NoExecute $ oc adm taint nodes node1 key2=value2:NoSchedule
pod 具有以下容限:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
在本例中,pod 无法调度到节点上,因为没有与第三个污点匹配的容限。如果在添加污点时 pod 已在节点上运行,pod 会继续运行,因为第三个污点是三个污点中 pod 唯一不容许的污点。
4.6.1.3. 了解 pod 调度和节点状况(根据状况保留节点)
Taint Nodes By Condition (默认启用)可自动污点报告状况的节点,如内存压力和磁盘压力。如果某个节点报告一个状况,则添加一个污点,直到状况被清除为止。这些污点具有 NoSchedule effect;即,pod 无法调度到该节点上,除非 pod 有匹配的容限。
在调度 pod 前,调度程序会检查节点上是否有这些污点。如果污点存在,则将 pod 调度到另一个节点。由于调度程序检查的是污点而非实际的节点状况,因此您可以通过添加适当的 pod 容限,将调度程序配置为忽略其中一些节点状况。
为确保向后兼容,守护进程会自动将下列容限添加到所有守护进程中:
node.kubernetes.io/memory-pressure
node.kubernetes.io/disk-pressure
node.kubernetes.io/unschedulable(1.10 或更高版本)
node.kubernetes.io/network-unavailable(仅限主机网络)
您还可以在守护进程集中添加任意容限。
control plane 还会在具有 QoS 类的 pod 中添加 node.kubernetes.io/memory-pressure 容限。这是因为 Kubernetes 在 Guaranteed 或 Burstable QoS 类中管理 pod。新的 BestEffort pod 不会调度到受影响的节点上。
4.6.1.4. 了解根据状况驱除 pod(基于垃圾的驱除)
Taint-Based Evictions 功能默认是启用的,可以从遇到特定状况(如 not-ready 和 unreachable)的节点驱除 pod。当节点遇到其中一个状况时,OpenShift Container Platform 会自动给节点添加污点,并开始驱除 pod 以及将 pod 重新调度到其他节点。
Taint Based Evictions 具有 NoExecute 效果,不容许污点的 pod 都被立即驱除,容许污点的 pod 不会被驱除,除非 pod 使用 tolerationSeconds 参数。
tolerationSeconds 参数允许您指定 pod 保持与具有节点状况的节点绑定的时长。如果在 tolerationSections 到期后状况仍然存在,则污点会保持在节点上,并且具有匹配容限的 pod 将被驱除。如果状况在 tolerationSeconds 到期前清除,则不会删除具有匹配容限的 pod。
如果使用没有值的 tolerationSeconds 参数,则 pod 不会因为未就绪和不可访问的节点状况而被驱除。
OpenShift Container Platform 会以限速方式驱除 pod,从而防止在主控机从节点分离等情形中发生大量 pod 驱除。
默认情况下,如果给定区域中的节点超过 55% 的节点不健康,节点生命周期控制器会将该区域的状态改为 PartialDisruption,并且 pod 驱除率会减少。对于此状态的小型集群(默认为 50 个节点或更少),这个区中的节点不会污点,驱除会被停止。
如需更多信息,请参阅 Kubernetes 文档中的 有关驱除率限制。
OpenShift Container Platform 会自动为 node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 添加容限并设置 tolerationSeconds=300,除非 Pod 配置中指定了其中任一种容限。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
tolerations:
- key: node.kubernetes.io/not-ready
operator: Exists
effect: NoExecute
tolerationSeconds: 300 1
- key: node.kubernetes.io/unreachable
operator: Exists
effect: NoExecute
tolerationSeconds: 300
#...- 1
这些容限确保了在默认情况下,pod 在检测到这些节点条件问题中的任何一个时,会保持绑定五分钟。
您可以根据需要配置这些容限。例如,如果您有一个具有许多本地状态的应用程序,您可能希望在发生网络分区时让 pod 与节点保持绑定更久一些,以等待分区恢复并避免 pod 驱除行为的发生。
由守护进程集生成的 pod 在创建时会带有以下污点的 NoExecute 容限,且没有 tolerationSeconds:
node.kubernetes.io/unreachable
node.kubernetes.io/not-ready
因此,守护进程集 pod 不会被驱除。
您可以通过添加 operator: "Exists" 容限而无需 key 和 values 参数,将 pod 配置为容许所有污点。具有此容限的 Pod 不会从具有污点的节点中删除。
您可以为 pod 和污点添加容限,以便节点能够控制哪些 pod 应该或不应该调度到节点上。对于现有的 pod 和节点,您应首先将容限添加到 pod,然后将污点添加到节点,以避免在添加容限前从节点上移除 pod。
通过编辑 Pod spec 使其包含 tolerations 小节来向 pod 添加容限:
4.6.2.4. 使用污点和容限控制具有特殊硬件的节点
如果集群中有少量节点具有特殊的硬件,您可以使用污点和容限让不需要特殊硬件的 pod 与这些节点保持距离,从而将这些节点保留给那些确实需要特殊硬件的 pod。您还可以要求需要特殊硬件的 pod 使用特定的节点。
您可以将容限添加到需要特殊硬件并污点具有特殊硬件的节点的 pod 中。
确保为特定 pod 保留具有特殊硬件的节点:
为需要特殊硬件的 pod 添加容限。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
tolerations:
- key: "disktype"
value: "ssd"
operator: "Equal"
effect: "NoSchedule"
tolerationSeconds: 3600
使用以下命令之一,给拥有特殊硬件的节点添加污点:
$ oc adm taint nodes <node-name> disktype=ssd:NoSchedule
$ oc adm taint nodes <node-name> disktype=ssd:PreferNoSchedule
您还可以应用以下 YAML 来添加污点:
kind: Node
apiVersion: v1
metadata:
name: my_node
spec:
taints:
- key: disktype
value: ssd
effect: PreferNoSchedule
#...
您可以根据需要,从节点移除污点并从 pod 移除容限。您应首先将容限添加到 pod,然后将污点添加到节点,以避免在添加容限前从节点上移除 pod。
移除污点和容限:
从节点移除污点:
$ oc adm taint nodes <node-name> <key>-
$ oc adm taint nodes ip-10-0-132-248.ec2.internal key1- 4.7. 使用节点选择器将 pod 放置到特定节点
节点选择器指定一个键/值对映射,该映射使用 pod 中指定的自定义标签和选择器定义。
要使 pod 有资格在节点上运行,pod 必须具有与节点上标签相同的键值节点选择器。
您可以使用节点上的 pod 和标签上的节点选择器来控制 pod 的调度位置。使用节点选择器时,OpenShift Container Platform 会将 pod 调度到包含匹配标签的节点。
您可以使用节点选择器将特定的 pod 放置到特定的节点上,集群范围节点选择器将新 pod 放置到集群中的任何特定节点上,以及项目节点选择器,将新 pod 放置到特定的节点上。
例如,作为集群管理员,您可以创建一个基础架构,应用程序开发人员可以通过在创建的每个 pod 中包括节点选择器,将 pod 部署到最接近其地理位置的节点。在本例中,集群由五个数据中心组成,分布在两个区域。在美国,将节点标记为 us-east、us-central 或 us-west。在亚太地区(APAC),将节点标记为 apac-east 或 apac-west。开发人员可在其创建的 pod 中添加节点选择器,以确保 pod 调度到这些节点上。
如果 Pod 对象包含节点选择器,但没有节点具有匹配的标签,则不会调度 pod。
如果您在同一 pod 配置中使用节点选择器和节点关联性,则以下规则控制 pod 放置到节点上:
如果同时配置了 nodeSelector 和 nodeAffinity,则必须满足这两个条件时 pod 才能调度到候选节点。
如果您指定了多个与 nodeAffinity 类型关联的 nodeSelectorTerms,那么其中一个 nodeSelectorTerms 满足时 pod 就能调度到节点上。
如果您指定了多个与 nodeSelectorTerms 关联的 matchExpressions,那么只有所有 matchExpressions 都满足时 pod 才能调度到节点上。
- 特定 pod 和节点上的节点选择器
您可以使用节点选择器和标签控制特定 pod 调度到哪些节点上。
要使用节点选择器和标签,首先标记节点以避免 pod 被取消调度,然后将节点选择器添加到 pod。
您不能直接将节点选择器添加到现有调度的 pod 中。您必须标记控制 pod 的对象,如部署配置。
例如,以下 Node 对象具有 region: east 标签:
- 默认集群范围节点选择器
使用默认集群范围节点选择器时,如果您在集群中创建 pod,OpenShift Container Platform 会将默认节点选择器添加到 pod,并将该 pod 调度到具有匹配标签的节点。
例如,以下 Scheduler 对象具有默认的集群范围的 region=east 和 type=user-node 节点选择器:
- 项目节点选择器
使用项目节点选择器时,如果您在此项目中创建 pod,OpenShift Container Platform 会将节点选择器添加到 pod,并将 pod 调度到具有匹配标签的节点。如果存在集群范围默认节点选择器,则以项目节点选择器为准。
例如,以下项目具有 region=east 节点选择器:
您可以使用节点上的 pod 和标签上的节点选择器来控制 pod 的调度位置。使用节点选择器时,OpenShift Container Platform 会将 pod 调度到包含匹配标签的节点。
您可向节点、计算机器集或机器配置添加标签。将标签添加到计算机器集可确保节点或机器停机时,新节点具有该标签。如果节点或机器停机,添加到节点或机器配置的标签不会保留。
要将节点选择器添加到现有 pod 中,将节点选择器添加到该 pod 的控制对象中,如 ReplicaSet 对象、DaemonSet 对象、StatefulSet 对象、Deployment 对象或 DeploymentConfig 对象。任何属于该控制对象的现有 pod 都会在具有匹配标签的节点上重新创建。如果要创建新 pod,可以将节点选择器直接添加到 pod 规格中。如果 pod 没有控制对象,您必须删除 pod,编辑 pod 规格并重新创建 pod。
您不能直接将节点选择器添加到现有调度的 pod 中。
要将节点选择器添加到现有 pod 中,请确定该 pod 的控制对象。例如, router-default-66d5cf9464-m2g75 pod 由 router-default-66d5cf9464 副本集控制:
$ oc describe pod router-default-66d5cf9464-7pwkc
您可以组合使用 pod 上的默认集群范围节点选择器和节点上的标签,将集群中创建的所有 pod 限制到特定节点。
使用集群范围节点选择器时,如果您在集群中创建 pod,OpenShift Container Platform 会将默认节点选择器添加到 pod,并将该 pod 调度到具有匹配标签的节点。
您可以通过编辑调度程序 Operator 自定义资源(CR)来配置集群范围节点选择器。您可向节点、计算机器集或机器配置添加标签。将标签添加到计算机器集可确保节点或机器停机时,新节点具有该标签。如果节点或机器停机,添加到节点或机器配置的标签不会保留。
您可以向 pod 添加额外的键/值对。但是,您无法为一个默认的键添加不同的值。
添加默认的集群范围节点选择器:
编辑调度程序 Operator CR 以添加默认的集群范围节点选择器:
$ oc edit scheduler cluster
您可以组合使用项目中的节点选择器和节点上的标签,将该项目中创建的所有 pod 限制到标记的节点。
当您在这个项目中创建 pod 时,OpenShift Container Platform 会将节点选择器添加到项目中 pod,并将 pod 调度到项目中具有匹配标签的节点。如果存在集群范围默认节点选择器,则以项目节点选择器为准。
您可以通过编辑 Namespace 对象来向项目添加节点选择器,以添加 openshift.io/node-selector 参数。您可向节点、计算机器集或机器配置添加标签。将标签添加到计算机器集可确保节点或机器停机时,新节点具有该标签。如果节点或机器停机,添加到节点或机器配置的标签不会保留。
如果 Pod 对象包含节点选择器,则不会调度 pod,但没有项目具有匹配的节点选择器。从该 spec 创建 pod 时,您收到类似以下消息的错误:
4.8. 使用 pod 拓扑分布限制控制 pod 放置
您可以使用 pod 拓扑分布约束,提供对 pod 在节点、区、区域或其他用户定义的拓扑域间的放置的精细控制。在故障域间分布 pod 有助于实现高可用性和效率更高的资源利用率。
-
作为管理员,我希望我的工作负载在两个到十五个 pod 之间自动缩放。我希望确保当只有两个 pod 时,它们没有在同一节点上放置,以避免出现单点故障。
作为管理员,我希望在多个基础架构区域间平均分配 pod,以降低延迟和网络成本。如果出现问题,我希望确保我的集群可以自我修复。
-
OpenShift Container Platform 集群中的 Pod 由 工作负载控制器 管理,如部署、有状态集或守护进程集。这些控制器为一组 pod 定义所需状态,包括如何在集群的节点间分布和扩展。您应该对组中的所有 pod 设置相同的 pod 拓扑分布限制,以避免混淆。在使用工作负载控制器(如部署)时,pod 模板通常会为您处理它。
混合不同的 pod 拓扑分布限制可能会导致 OpenShift Container Platform 行为混淆和故障排除。您可以通过确保拓扑域中的所有节点一致标记来避免这种情况。OpenShift Container Platform 会自动填充已知的标签,如
kubernetes.io/hostname。这有助于避免手动标记节点的需求。这些标签提供基本的拓扑信息,确保集群中具有一致的节点标签。
只有同一命名空间中的 pod 在因为约束而分散时才会被匹配和分组。
您可以指定多个 pod 拓扑分散约束,但您必须确保它们不会相互冲突。必须满足所有 pod 拓扑分布约束才能放置 pod。
skew 指的是在不同拓扑域(如区或节点)之间与指定标签选择器匹配的 pod 数量的不同。
skew 是为每个域计算的,在那个域中 pod 数量与调度最小 pod 的 pod 数量之间绝对不同。设置 maxSkew 值会引导调度程序来维护均衡的 pod 发行版。
您有三个区域(A、B 和 C),您希望在这些区间平均分配 pod。如果区域 A 具有 5 个 pod,区域 B 具有 3 个 pod,并且区域 C 具有 2 个 pod,以查找 skew,您可以减去域中当前从每个区域中 pod 数量最低的 pod 数量。这意味着区域 A 的 skew 是 3,区域 B 的 skew 是 1,并且区域 C 的 skew 为 0。
maxSkew 参数定义两个拓扑域之间的 pod 数量的最大允许差异或 skew。如果将 maxSkew 设置为 1,则任何拓扑域中的 pod 数量不应与任何其他域的 1 不同。如果 skew 超过 maxSkew,调度程序会尝试将新 pod 放置到减少 skew, 遵循限制的方式。
使用前面的示例 skew 计算,skew 值超过默认 maxSkew 值 1。调度程序将新 pod 放置到区 B 和 zone C 中,以减少 skew 并实现更平衡的分发,确保没有拓扑域超过偏移 1。
您可以指定哪些 pod 要分组在一起,它们分散到哪些拓扑域以及可以接受的基点。
以下示例演示了 pod 拓扑分散约束配置。
4.9. 使用 descheduler 驱除 pod
调度程序(scheduler)被用来决定最适合托管新 pod 的节点,而 descheduler 可以用来驱除正在运行的 pod,从而使 pod 能够重新调度到更合适的节点上。
您可以使用 descheduler 根据特定策略驱除 pod,以便可将 pod 重新调度到更合适的节点上。
descheduler 适合于在以下情况下 处理运行的 pod:
节点使用不足或过度使用。
Pod 和节点关联性要求(如污点或标签)已更改,并且原始的调度不再适合于某些节点。
节点失败需要移动 pod。
集群中添加了新节点。
Pod 重启的次数太多。
descheduler 不调度被驱除的 pod。调度被驱除 pod 的任务由调度程序(scheduler)执行。
当 descheduler 决定从节点驱除 pod 时,它会使用以下机制:
openshift-* 和 kube-system 命名空间中的 Pod 不会被驱除。
priorityClassName 被设置为 system-cluster-critical 或 system-node-critical 的关键 pod 不会被驱除。
不属于复制控制器、副本集、部署、StatefulSet 或作业一部分的静态、镜像或独立 pod 不会被驱除,因为这些 pod 不会被重新创建。
与守护进程集关联的 pod 不会被驱除。
具有本地存储的 Pod 不会被驱除。
BestEffort pod 会在 Burstable 和 Guaranteed pod 之前被驱除。
具有 descheduler.alpha.kubernetes.io/evict 注解的所有 pod 类型都可以被驱除。此注解用于覆盖防止驱除的检查,用户可以选择驱除哪些 pod。用户应该知道如何创建 pod 以及是否重新创建 pod。
对于受 Pod Disruption Budget (PDB) 限制的 pod,如果进行 deschedule 会违反 Pod disruption budget (PDB),则 pod 不会被驱除。通过使用驱除子资源来处理 PDB 来驱除 pod 。
以下 descheduler 配置集可用:
AffinityAndTaints
此配置集驱除违反了 pod 间的反关联性、节点关联性和节点污点的 pod。
它启用了以下策略:
RemovePodsViolatingInterPodAntiAffinity:删除违反了 pod 间的反关联性的 pod。
RemovePodsViolatingNodeAffinity:移除违反了节点关联性的 pod。
RemovePodsViolatingNodeTaints:移除违反了节点上的 NoSchedule 污点的 pod。
移除具有节点关联性类型 requiredDuringSchedulingIgnoredDuringExecution的 pod。
TopologyAndDuplicates
此配置集会驱除 pod 以努力在节点间平均分配类似的 pod 或相同拓扑域的 pod。
它启用了以下策略:
RemovePodsViolatingTopologySpreadConstraint:找到未平衡的拓扑域,并在 DoNotSchedule 约束被违反时尝试从较大的 pod 驱除 pod。
RemoveDuplicates:确保只有一个 pod 与同一节点上运行的副本集、复制控制器、部署或作业相关联。如果存在多个重复的 pod,则这些重复的 pod 会被驱除以更好地在集群中的 pod 分布。
LifecycleAndUtilization
此配置集驱除长时间运行的 pod,并平衡节点之间的资源使用情况。
它启用了以下策略:
RemovePodsHavingTooManyRestarts :删除容器重启了多次的 pod。
在所有容器(包括初始容器)中被重启的总数超过 100 次的 Pod 。
LowNodeUtilization:查找使用率不足的节点,并在可能的情况下从其他过度使用的节点中驱除 pod,以希望这些被驱除的 pod 可以在使用率低的节点上被重新创建。
如果节点的用量低于 20%(CPU、内存和 pod 的数量),则该节点将被视为使用率不足。
如果节点的用量超过 50%(CPU、内存和 pod 的数量),则该节点将被视为过量使用。
PodLifeTime:驱除太老的 pod。
默认情况下,会删除超过 24 小时的 pod。您可以自定义 pod 生命周期值。
SoftTopologyAndDuplicates
这个配置集与 TopologyAndDuplicates 相同,不同之处在于具有软拓扑约束的 pod(如 whenUnsatisfiable: ScheduleAnyway )也被视为驱除。
不要同时启用 SoftTopologyAndDuplicates 和 TopologyAndDuplicates。启用两者会导致冲突。
EvictPodsWithLocalStorage
此配置集允许具有本地存储的 pod 有资格被驱除。
EvictPodsWithPVC
此配置集允许带有持久性卷声明的 pod 有资格驱除。如果使用 Kubernetes NFS Subdir External Provisioner,您必须为安装置备程序的命名空间添加排除的命名空间。
在默认情况下,不提供 descheduler。要启用 descheduler,您必须从 OperatorHub 安装 Kube Descheduler Operator,并启用一个或多个 descheduler 配置集。
默认情况下,descheduler 以预测模式运行,这意味着它只模拟 pod 驱除。您必须将 descheduler 的模式更改为自动进行 pod 驱除。
如果您在集群中启用了托管的 control plane,设置自定义优先级阈值,以降低托管 control plane 命名空间中的 pod 被驱除。将优先级阈值类名称设置为 hypershift-control-plane,因为它有托管的 control plane 优先级类的最低优先级值(100000000)。
必须具有集群管理员权限。
访问 OpenShift Container Platform Web 控制台。
登陆到 OpenShift Container Platform Web 控制台。
为 Kube Descheduler Operator 创建所需的命名空间。
进行 Administration → Namespaces,点 Create Namespace。
在 Name 字段中输入 openshift-kube-descheduler-operator,在 Labels 字段中输入 openshift.io/cluster-monitoring=true 来启用 descheduler 指标,然后点击 Create。
安装 Kube Descheduler Operator。
进入 Operators → OperatorHub。
在过滤框中输入 Kube Descheduler Operator。
选择 Kube Descheduler Operator 并点 Install。
在 Install Operator 页面中,选择 A specific namespace on the cluster。从下拉菜单中选择 openshift-kube-descheduler-operator 。
将 Update Channel 和 Approval Strategy 的值调整为所需的值。
点击 Install。
创建 descheduler 实例。
在 Operators → Installed Operators 页面中,点 Kube Descheduler Operator。
选择 Kube Descheduler 标签页并点 Create KubeDescheduler。
根据需要编辑设置。
要驱除 pod 而不是模拟驱除,请将 Mode 字段更改为 Automatic。
展开 Profiles 部分,以选择要启用的一个或多个配置集。AffinityAndTaints 配置集默认为启用。点 Add Profile 选择附加配置集。
不要同时启用 TopologyAndDuplicates 和 SoftTopologyAndDuplicates。启用两者会导致冲突。
可选:展开 Profile Customizations 部分,设置 descheduler 的可选配置。
为 LifecycleAndUtilization 配置集设置自定义 pod 生命周期值。使用 podLifetime 字段设置数字值和一个有效单元(s、m 或 h)。默认 pod 生命周期为 24 小时(24h)。
设置自定义优先级阈值,使其仅在优先级低于指定优先级级别时才会考虑 pod 进行驱除。使用 thresholdPriority 字段设置数字优先级阈值,或者使用 thresholdPriorityClassName 字段指定特定的优先级类名称。
不要为 descheduler 指定 thresholdPriority 和 thresholdPriorityClassName。
将特定的命名空间设置为包括在或排除在 descheduler 操作中。展开 namespaces 字段,并将命名空间添加到 excluded 或 included 列表中。您只能设置要排除的命名空间列表或要包含的命名空间列表。请注意,默认排除受保护的命名空间(openshift-*、kube-system、hypershift)。
LowNodeUtilization 策略不支持命名空间排除。如果设置了 LifecycleAndUtilization 配置集,它启用了 LowNodeUtilization 策略,则不会排除任何命名空间,即使受保护的命名空间也是如此。为了避免在启用 LowNodeUtilization 策略时从受保护的命名空间中驱除,请将优先级类名称设置为 system-cluster-critical 或 system-node-critical。
实验性:为 LowNodeUtilization 策略设置利用不足和过度利用的阈值。使用 devLowNodeUtilizationThresholds 字段设置以下值之一:
Low: 10% 低利用,30% 过渡利用
Medium: 20% 低利用,50% 过渡利用(默认)
High: 40% 低利用,70% 过渡利用
这个设置是实验性的,不应在生产环境中使用。
可选: 使用 Descheduling Interval Seconds 字段更改 descheduler 运行间隔的秒数。默认值为 3600 秒。
点 Create。
您还可以稍后使用 OpenShift CLI(oc)为 descheduler 配置配置集和设置。如果您在从 web 控制台创建 descheduler 实例时没有调整配置集,则默认启用 AffinityAndTaints 配置集。
4.9.4. 配置 descheduler 配置集
您可以配置 descheduler 使用哪些配置集来驱除 pod。
集群管理员特权
编辑 KubeDescheduler 对象:
$ oc edit kubedeschedulers.operator.openshift.io cluster -n openshift-kube-descheduler-operator
在 spec.profiles 部分指定一个或多个配置集。
apiVersion: operator.openshift.io/v1
kind: KubeDescheduler
metadata:
name: cluster
namespace: openshift-kube-descheduler-operator
spec:
deschedulingIntervalSeconds: 3600
logLevel: Normal
managementState: Managed
operatorLogLevel: Normal
mode: Predictive 1
profileCustomizations:
namespaces: 2
excluded:
- my-namespace
podLifetime: 48h 3
thresholdPriorityClassName: my-priority-class-name 4
profiles: 5
- AffinityAndTaints
- TopologyAndDuplicates 6
- LifecycleAndUtilization
- EvictPodsWithLocalStorage
- EvictPodsWithPVC- 1
可选:默认情况下,descheduler 不会驱除 pod。要驱除 pod,请将 mode 设置为 Automatic。
可选:设置用户创建命名空间列表,以便从 descheduler 操作中包含或排除。使用 exclude 设置要排除的命名空间列表,或者使用 included 来设置要包含的命名空间列表。请注意,默认排除受保护的命名空间(openshift-*、kube-system、hypershift)。
LowNodeUtilization 策略不支持命名空间排除。如果设置了 LifecycleAndUtilization 配置集,它启用了 LowNodeUtilization 策略,则不会排除任何命名空间,即使受保护的命名空间也是如此。为了避免在启用 LowNodeUtilization 策略时从受保护的命名空间中驱除,请将优先级类名称设置为 system-cluster-critical 或 system-node-critical。
可选:为 LifecycleAndUtilization 配置集启用自定义 pod 生命周期值。有效单位是 s、m 或 h。默认 pod 生命周期为 24 小时。
可选:指定优先级阈值,仅在优先级低于指定级别时才会考虑 pod 进行驱除。使用 thresholdPriority 字段设置数字优先级阈值(如 10000)或者使用 thresholdPriorityClassName 字段指定特定的优先级类名称(如 my-priority-class-name)。如果指定优先级类名称,则必须已存在它,否则 descheduler 会抛出错误。不要同时设置 thresholdPriority 和 thresholdPriorityClassName。
添加一个或多个配置文件以启用。可用配置集:AffinityAndTaints、TopologyAndDuplicates、LifecycleAndUtilization、SoftTopologyAndDuplicates、EvictPodsWithLocalStorage 和 EvictPodsWithPVC。
不要同时启用 TopologyAndDuplicates 和 SoftTopologyAndDuplicates。启用两者会导致冲突。
您可以启用多个配置集 ; 指定配置集的顺序并不重要。
保存文件以使改变生效。
您可以配置 descheduler 运行之间的时间长度。默认为 3600 秒(一小时)。
集群管理员特权
编辑 KubeDescheduler 对象:
$ oc edit kubedeschedulers.operator.openshift.io cluster -n openshift-kube-descheduler-operator
将 deschedulingIntervalSeconds 字段更新为所需的值:
apiVersion: operator.openshift.io/v1
kind: KubeDescheduler
metadata:
name: cluster
namespace: openshift-kube-descheduler-operator
spec:
deschedulingIntervalSeconds: 3600 1
... - 1
设置 descheduler 运行间隔的秒数。如果设为 0,则 descheduler 会运行一次并退出。
保存文件以使改变生效。
您可以通过删除 descheduler 实例并卸载 Kube Descheduler Operator 从集群中移除 descheduler。此流程还会清理 KubeDescheduler CRD 和 openshift-kube-descheduler-operator 命名空间。
必须具有集群管理员权限。
访问 OpenShift Container Platform Web 控制台。
登陆到 OpenShift Container Platform Web 控制台。
删除 descheduler 实例。
在 Operators → Installed Operators 页面中,点 Kube Descheduler Operator。
选择 Kube Descheduler 选项卡。
点 集群 条目旁的 Options 菜单
并选择 Delete KubeDescheduler。
在确认对话框中,点 Delete。
卸载 Kube Descheduler Operator。
导航到 Operators → Installed Operators。
点 Kube Descheduler Operator 条目
旁边的 Options 菜单,然后选择 Uninstall Operator。
在确认对话框中,点 Uninstall。
删除 openshift-kube-descheduler-operator 命名空间。
导航至 Administration → Namespaces。
在过滤器框中输入 openshift-kube-descheduler-operator。
点 openshift-kube-descheduler-operator 条目旁的 Options 菜单
,然后选择 Delete Namespace。
在确认对话框中,输入 openshift-kube-descheduler-operator 并点 Delete。
删除 KubeDescheduler CRD。
进入 Administration → Custom Resource Definitions。
在过滤器框中输入 KubeDescheduler。
点 KubeDescheduler 条目旁的 Options 菜单
,然后选择 Delete CustomResourceDefinition。
在确认对话框中,点 Delete。
您可以安装 Secondary Scheduler Operator 来运行自定义二级调度程序,以及调度 pod 的默认调度程序。
4.10.1.1. 关于 Secondary Scheduler Operator
Red Hat OpenShift 的 Secondary Scheduler Operator 提供了在 OpenShift Container Platform 中部署自定义二级调度程序的方法。二级调度程序与默认调度程序一起运行,以调度 pod。Pod 配置可指定要使用的调度程序。
自定义调度程序必须具有 /bin/kube-scheduler 二进制文件,并基于 Kubernetes 调度框架。
您可以使用 Secondary Scheduler Operator 在 OpenShift Container Platform 中部署自定义二级调度程序,但红帽不直接支持自定义二级调度程序的功能。
Secondary Scheduler Operator 创建二级调度程序所需的默认角色和角色绑定。您可以通过为从属调度程序配置 KubeSchedulerConfiguration 资源,来指定哪些调度插件来启用或禁用。
4.10.2. Secondary Scheduler Operator for Red Hat OpenShift 发行注记
Red Hat OpenShift 的 Secondary Scheduler Operator 允许您在 OpenShift Container Platform 集群中部署自定义二级调度程序。
本发行注记介绍了针对 Red Hat OpenShift 的 Secondary Scheduler Operator 的开发。
如需更多信息,请参阅关于 Secondary Scheduler Operator。
4.10.2.1. Secondary Scheduler Operator for Red Hat OpenShift 1.1.3 发行注记
发布日期:2023 年 10 月 26 日
以下公告对于 Secondary Scheduler Operator for Red Hat OpenShift 1.1.3 可用:
RHSA-2023:5933
-
此 Secondary Scheduler Operator 发行版本解决了 CVE 报告的安全漏洞问题。
-
目前,您无法通过 Secondary Scheduler Operator 部署其他资源,如配置映射、CRD 或 RBAC 策略。自定义二级调度程序所需的角色和角色绑定以外的任何资源都必须外部应用。(WRKLDS-645)
4.10.2.2. Red Hat OpenShift 1.1.2 的 Secondary Scheduler Operator 发行注记
发布日期:2023 年 8 月 23 日
以下公告可用于 Red Hat OpenShift 1.1.2 的 Secondary Scheduler Operator:
RHSA-2023:4657
-
此 Secondary Scheduler Operator 发行版本解决了几个常见漏洞和暴露 (CVE)。
-
目前,您无法通过 Secondary Scheduler Operator 部署其他资源,如配置映射、CRD 或 RBAC 策略。自定义二级调度程序所需的角色和角色绑定以外的任何资源都必须外部应用。(WRKLDS-645
)
4.10.2.3. Red Hat OpenShift 1.1.0 的 Secondary Scheduler Operator 发行注记
发布日期: 2022 年 9 月 1 日
以下公告可用于 Red Hat OpenShift 1.1.0 的 Secondary Scheduler Operator:
RHSA-2022:6152
-
Secondary Scheduler Operator 安全上下文配置已更新,以符合 pod 安全准入强制。
-
目前,您无法通过 Secondary Scheduler Operator 部署其他资源,如配置映射、CRD 或 RBAC 策略。自定义二级调度程序所需的角色和角色绑定以外的任何资源都必须外部应用。(BZ#2071684)
您可以通过安装 Secondary Scheduler Operator、部署二级调度程序,并在 pod 定义中设置二级调度程序,在 OpenShift Container Platform 中运行自定义次要调度程序。
4.10.3.1. 安装 Secondary Scheduler Operator
您可以使用 Web 控制台为 Red Hat OpenShift 安装 Secondary Scheduler Operator。
您可以使用 cluster-admin 权限访问集群。
访问 OpenShift Container Platform web 控制台。
登陆到 OpenShift Container Platform Web 控制台。
为 Red Hat OpenShift 创建 Secondary Scheduler Operator 所需的命名空间。
进行 Administration → Namespaces,点 Create Namespace。
在 Name 字段中输入 openshift-secondary-scheduler-operator,再点 Create。
为 Red Hat OpenShift 安装 Secondary Scheduler Operator。
导航至 Operators → OperatorHub。
在过滤器框中输入 Secondary Scheduler Operator for Red Hat OpenShift。
选择 Secondary Scheduler Operator for Red Hat OpenShift 并点 Install。
在 Install Operator 页面中:
Update channel 设置为 stable,它将为 Red Hat OpenShift 安装 Secondary Scheduler Operator 的最新稳定版本。
选择 A specific namespace on the cluster,并从下拉菜单中选择 openshift-secondary-scheduler-operator。
选择一个 更新批准策略。
Automatic 策略允许 Operator Lifecycle Manager(OLM)在有新版本可用时自动更新 Operator。
Manual 策略需要拥有适当凭证的用户批准 Operator 更新。
点 Install。
导航到 Operators → Installed Operators。
验证 Secondary Scheduler Operator for Red Hat OpenShift 已列出,Status 为 Succeeded。
安装 Secondary Scheduler Operator 后,您可以部署二级调度程序。
您可以使用 cluster-admin 权限访问集群。
访问 OpenShift Container Platform web 控制台。
安装了 Secondary Scheduler Operator for Red Hat OpenShift。
登陆到 OpenShift Container Platform Web 控制台。
创建配置映射来保存二级调度程序的配置。
进入 Workloads → ConfigMaps。
点 Create ConfigMap。
在 YAML 编辑器中,输入包含必要 KubeSchedulerConfiguration 配置的配置映射定义。例如:
apiVersion: v1
kind: ConfigMap
metadata:
name: "secondary-scheduler-config" 1
namespace: "openshift-secondary-scheduler-operator" 2
data:
"config.yaml": |
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration 3
leaderElection:
leaderElect: false
profiles:
- schedulerName: secondary-scheduler 4
plugins: 5
score:
disabled:
- name: NodeResourcesBalancedAllocation
- name: NodeResourcesLeastAllocated- 1
配置映射的名称。这将在创建 SecondaryScheduler CR 时,在 Scheduler Config 字段中使用。
配置映射必须在 openshift-secondary-scheduler-operator 命名空间中创建。
二级调度程序的 KubeSchedulerConfiguration 资源。如需更多信息,请参阅 Kubernetes API 文档中的 KubeSchedulerConfiguration。
二级调度程序的名称。将其 spec.schedulerName 字段设置为此值的 Pod 会使用这个二级调度程序来调度。
为二级调度程序启用或禁用插件。如需列出默认调度插件,请参阅 Kubernetes 文档中的 调度插件。
点 Create。
创建 SecondaryScheduler CR:
导航到 Operators → Installed Operators。
选择 Secondary Scheduler Operator for Red Hat OpenShift。
选择 Secondary Scheduler 选项卡,然后点 Create SecondaryScheduler。
Name 字段默认为 cluster; 不要更改此名称。
Scheduler Config 字段默认为 secondary-scheduler-config。确保这个值与此流程中创建的配置映射的名称匹配。
在 Scheduler Image 字段中,输入自定义调度程序的镜像名称。
红帽不直接支持自定义二级调度程序的功能。
点 Create。
要使用二级调度程序调度 pod,请在 pod 定义中设置 schedulerName 字段。
您可以使用 cluster-admin 权限访问集群。
访问 OpenShift Container Platform web 控制台。
安装了 Secondary Scheduler Operator for Red Hat OpenShift。
配置了二级调度程序。
登陆到 OpenShift Container Platform Web 控制台。
导航到 Workloads → Pods。
点 Create Pod。
在 YAML 编辑器中,输入所需的 pod 配置并添加 schedulerName 字段:
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: default
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
schedulerName: secondary-scheduler 1- 1
在配置二级调度程序时, schedulerName 字段必须与配置映射中定义的名称匹配。
点 Create。
登录到 OpenShift CLI。
使用以下命令描述 pod:
$ oc describe pod nginx -n default
4.10.4. 卸载 Secondary Scheduler Operator
您可以通过卸载 Operator 并删除其相关资源,从 OpenShift Container Platform 中删除 Red Hat OpenShift 的 Secondary Scheduler Operator。
4.10.4.1. 卸载 Secondary Scheduler Operator
您可以使用 Web 控制台为 Red Hat OpenShift 卸载 Secondary Scheduler Operator。
您可以使用 cluster-admin 权限访问集群。
访问 OpenShift Container Platform web 控制台。
安装了 Secondary Scheduler Operator for Red Hat OpenShift。
登陆到 OpenShift Container Platform Web 控制台。
为 Red Hat OpenShift Operator 卸载 Secondary Scheduler Operator。
导航到 Operators → Installed Operators。
点 Secondary Scheduler Operator 条目旁边的 Options 菜单
,并点 Uninstall Operator。
在确认对话框中,点 Uninstall。
4.10.4.2. 删除 Secondary Scheduler Operator 资源
另外,在为 Red Hat OpenShift 卸载 Secondary Scheduler Operator 后,您可以从集群中移除其相关资源。
您可以使用 cluster-admin 权限访问集群。
访问 OpenShift Container Platform web 控制台。
登陆到 OpenShift Container Platform Web 控制台。
删除由 Secondary Scheduler Operator 安装的 CRD:
进入到 Administration → CustomResourceDefinitions。
在 Name 字段中输入 SecondaryScheduler 以过滤 CRD。
点 SecondaryScheduler CRD 旁边的 Options 菜单
并选择 Delete Custom Resource Definition:
删除 openshift-secondary-scheduler-operator 命名空间。
导航至 Administration → Namespaces。
点 openshift-secondary-scheduler-operator 旁边的 Options 菜单
并选择 Delete Namespace。
在确认对话框中,在字段中输入 openshift-secondary-scheduler-operator,再点 Delete。
5.1. 使用 daemonset 在节点上自动运行后台任务
作为管理员,您可以创建并使用守护进程集在 OpenShift Container Platform 集群的特定节点或所有节点上运行 pod 副本。
守护进程集确保所有(或部分)节点都运行 pod 的副本。当节点添加到集群中时,pod 也会添加到集群中。当节点从集群中移除时,这些 pod 也会通过垃圾回收而被移除。删除守护进程集会清理它创建的 pod。
您可以使用 daemonset 创建共享存储,在集群的每一节点上运行日志 pod,或者在每个节点上部署监控代理。
为安全起见,集群管理员和项目管理员可以创建守护进程集。
如需有关守护进程集的更多信息,请参阅 Kubernetes 文档。
守护进程集调度与项目的默认节点选择器不兼容。如果您没有禁用它,守护进程集会与默认节点选择器合并,从而受到限制。这会造成在合并后节点选择器没有选中的节点上频繁地重新创建 pod,进而给集群带来意外的负载。
守护进程集确保所有有资格的节点都运行 pod 的副本。通常,Kubernetes 调度程序会选择要在其上运行 pod 的节点。但是,守护进程集 pod 由守护进程集控制器创建并调度。这会引发以下问题:
pod 行为不一致:等待调度的普通 pod 被创建好并处于待处理状态,但守护进程集 pod 没有以待处理的状态创建。这会给用户造成混淆。
Pod 抢占由默认调度程序处理。启用抢占后,守护进程集控制器将在不考虑 pod 优先级和抢占的前提下做出调度决策。
OpenShift Container Platform 中默认启用 ScheduleDaemonSetPods 功能允许您使用默认调度程序而不是守护进程集控制器来调度守护进程集,具体方法是添加 NodeAffinity 术语到守护进程集 pod,而不是 .spec.nodeName 术语。然后,默认调度程序用于将 pod 绑定到目标主机。如果守护进程集的节点关联性已经存在,它会被替换掉。守护进程设置控制器仅在创建或修改守护进程集 pod 时执行这些操作,且不会对守护进程集的 spec.template 进行任何更改。
kind: Pod
apiVersion: v1
metadata:
name: hello-node-6fbccf8d9-9tmzr
spec:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchFields:
- key: metadata.name
operator: In
values:
- target-host-name
另外,node.kubernetes.io/unschedulable:NoSchedule 容限会自动添加到守护进程设置 Pod 中。在调度守护进程设置 pod 时,默认调度程序会忽略不可调度的节点。
在创建守护进程集时,使用 nodeSelector 字段来指示守护进程集应在其上部署副本的节点。
在开始使用守护进程集之前,通过将命名空间注解 openshift.io/node-selector 设置为空字符串来禁用命名空间中的默认项目范围节点选择器:
$ oc patch namespace myproject -p \
'{"metadata": {"annotations": {"openshift.io/node-selector": ""}}}'
您还可以应用以下 YAML 来为命名空间禁用默认的项目范围节点选择器:
apiVersion: v1
kind: Namespace
metadata:
name: <namespace>
annotations:
openshift.io/node-selector: ''
如果您要创建新项目,请覆盖默认节点选择器:
$ oc adm new-project <name> --node-selector=""
作业(job)在 OpenShift Container Platform 集群中执行某项任务。
作业会跟踪任务的整体进度,并使用活跃、成功和失败 pod 的相关信息来更新其状态。删除作业会清理它创建的所有 pod 副本。作业是 Kubernetes API 的一部分,可以像其他对象类型一样通过 oc 命令进行管理。
作业会跟踪任务的整体进度,并使用活跃、成功和失败 pod 的相关信息来更新其状态。删除作业会清理它创建的所有 pod。作业是 Kubernetes API 的一部分,可以像其他对象类型一样通过 oc 命令进行管理。
OpenShift Container Platform 中有两种资源类型可以创建只运行一次的对象:
常规作业是一种只运行一次的对象,它会创建一个任务并确保作业完成。
有三种适合作为作业运行的任务类型:
非并行作业:
仅启动一个 pod 的作业,除非 pod 失败。
一旦 pod 成功终止,作业就会马上完成。
带有固定完成计数的并行作业:
启动多个 pod 的作业。
Job 代表整个任务,并在 1 到 completions 范围内的每个值都有一个成功 pod 时完成 。
带有工作队列的并行作业:
在一个给定 pod 中具有多个并行 worker 进程的作业。
OpenShift Container Platform 协调 pod,以确定每个 pod 都应该使用什么作业,或使用一个外部队列服务。
每个 pod 都可以独立决定是否所有对等 pod 都已完成(整个作业完成)。
当所有来自作业的 pod 都成功终止时,不会创建新的 pod。
当至少有一个 pod 成功终止并且所有 pod 都终止时,作业成功完成。
当任何 pod 成功退出时,其他 pod 都不应该为这个任务做任何工作或写任何输出。Pod 都应该处于退出过程中。
如需有关如何使用不同类型的作业的更多信息,请参阅 Kubernetes 文档中的作业模式 。
Cron job
通过使用 Cron Job,一个作业可以被调度为运行多次。
Cron Job 基于常规作业构建,允许您指定作业的运行方式。Cron job 是 Kubernetes API 的一部分,可以像其他对象类型一样通过 oc 命令进行管理。
Cron Job 可用于创建周期性和重复执行的任务,如运行备份或发送电子邮件。Cron Job 也可以将个别任务调度到指定时间执行,例如,将一个作业调度到低活动时段执行。一个 cron 作业会创建一个 Job 对象,它基于在运行 cronjob 的 control plane 节点上配置的时区。
Cron Job 大致会在调度的每个执行时间创建一个 Job 对象,但在有些情况下,它可能无法创建作业,或者可能会创建两个作业。因此,作业必须具有幂等性,而且您必须配置历史限制。
两种资源类型都需要一个由以下关键部分组成的作业配置:
pod 模板,用于描述 OpenShift Container Platform 创建的 pod。
parallelism 参数,用于指定在任意时间点上应并行运行多少个 pod 来执行某个作业。
对于非并行作业,请保留未设置。当取消设置时,默认为 1。
completions 参数,用于指定需要成功完成多少个 pod 才能完成某个作业。
对于非并行作业,请保留未设置。当取消设置时,默认为 1。
对于带有固定完成计数的并行作业,请指定一个值。
对于带有工作队列的并行作业,请保留 unset。当取消设置默认为 parallelism 值。
在定义作业时,您可以通过设置 activeDeadlineSeconds 字段来定义其最长持续时间。以秒为单位指定,默认情况下不设置。若未设置,则不强制执行最长持续时间。
最长持续时间从系统中调度第一个 pod 的时间开始计算,并且定义作业在多久时间内处于活跃状态。它将跟踪整个执行时间。达到指定的超时后,OpenShift Container Platform 将终止作业。
5.2.1.3. 了解如何为 pod 失败设置作业避退策略
在因为配置中的逻辑错误或其他类似原因而重试了一定次数后,作业会被视为已经失败。控制器以六分钟为上限,按指数避退延时(10s,20s,40s …)重新创建与作业关联的失败 pod。如果控制器检查之间没有出现新的失败 pod,则重置这个限制。
使用 spec.backoffLimit 参数为作业设置重试次数。
5.2.1.4. 了解如何配置 Cron Job 以移除工件
Cron Job 可能会遗留工件资源,如作业或 pod 等。作为用户,务必要配置一个历史限制,以便能妥善清理旧作业及其 pod。Cron Job 规格内有两个字段负责这一事务:
.spec.successfulJobsHistoryLimit。要保留的成功完成作业数(默认为 3)。
.spec.failedJobsHistoryLimit。要保留的失败完成作业数(默认为 1)。
删除您不再需要的 Cron Job:
$ oc delete cronjob/<cron_job_name>
这样可防止生成不必要的工件。
您可以通过将 spec.suspend 设置为 true 来挂起后续执行。所有后续执行都会挂起,直到重置为 false。
作业规格重启策略只适用于 pod,不适用于作业控制器。不过,作业控制器被硬编码为可以一直重试直到作业完成为止。
因此,restartPolicy: Never 或 --restart=Never 会产生与 restartPolicy: OnFailure 或 --restart=OnFailure 相同的行为。也就是说,作业失败后会自动重启,直到成功(或被手动放弃)为止。策略仅设定由哪一子系统执行重启。
使用 Never 策略时,作业控制器负责执行重启。在每次尝试时,作业控制器会在作业状态中递增失败次数并创建新的 pod。这意味着,每次尝试失败都会增加 pod 的数量。
使用 OnFailure 策略时,kubelet 负责执行重启。每次尝试都不会在作业状态中递增失败次数。另外,kubelet 将通过在相同节点上启动 pod 来重试失败的作业。
您可以通过创建作业对象在 OpenShift Container Platform 中创建作业。
创建作业:
创建一个类似以下示例的 YAML 文件:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 1 1
completions: 1 2
activeDeadlineSeconds: 1800 3
backoffLimit: 6 4
template: 5
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure 6
#...- 1
可选:指定一个作业应并行运行多少个 pod 副本;默认与 1。
对于非并行作业,请保留未设置。当取消设置时,默认为 1。
可选:指定标记作业完成需要成功完成多少个 pod。
对于非并行作业,请保留未设置。当取消设置时,默认为 1。
对于具有固定完成计数的并行作业,请指定完成数。
对于带有工作队列的并行作业,请保留 unset。当取消设置默认为 parallelism 值。
可选:指定作业可以运行的最长持续时间。
可选:指定作业的重试次数。此字段默认值为 6。
指定控制器创建的 Pod 模板。
指定 pod 的重启策略:
Never。不要重启作业。
OnFailure。仅在失败时重启该任务。
Always。总是重启该任务。
如需了解 OpenShift Container Platform 如何使用与失败容器相关的重启策略,请参阅 Kubernetes 文档中的 示例状态。
创建作业:
$ oc create -f <file-name>.yaml
您还可以使用 oc create job,在一个命令中创建并启动作业。以下命令会创建并启动一个与上个示例中指定的相似的作业:
$ oc create job pi --image=perl -- perl -Mbignum=bpi -wle 'print bpi(2000)'
您可以通过创建作业对象在 OpenShift Container Platform 中创建 Cron Job。
创建 Cron Job:
创建一个类似以下示例的 YAML 文件:
apiVersion: batch/v1
kind: CronJob
metadata:
name: pi
spec:
schedule: "*/1 * * * *" 1
timeZone: Etc/UTC 2
concurrencyPolicy: "Replace" 3
startingDeadlineSeconds: 200 4
suspend: true 5
successfulJobsHistoryLimit: 3 6
failedJobsHistoryLimit: 1 7
jobTemplate: 8
spec:
template:
metadata:
labels: 9
parent: "cronjobpi"
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure 10
#...- 1
以 cron 格式指定的作业调度计划。在本例中,作业将每分钟运行一次。
调度的可选时区。有关有效选项,请参阅 tz 数据库时区列表。如果没有指定,Kubernetes 控制器管理器会解释相对于其本地时区的调度。此设置 作为技术预览提供。
可选的并发策略,指定如何对待 Cron Job 中的并发作业。只能指定以下并发策略之一。若未指定,默认为允许并发执行。
Allow,允许 Cron Job 并发运行。
Forbid,禁止并发运行。如果上一运行尚未结束,则跳过下一运行。
Replace,取消当前运行的作业并替换为新作业。
可选期限(秒为单位),如果作业因任何原因而错过预定时间,则在此期限内启动作业。错过的作业执行计为失败的作业。若不指定,则没有期限。
可选标志,允许挂起 Cron Job。若设为 true,则会挂起所有后续执行。
要保留的成功完成作业数(默认为 3)。
要保留的失败完成作业数(默认为 1)。
作业模板。类似于作业示例。
为此 Cron Job 生成的作业设置一个标签。
pod 的重启策略。这不适用于作业控制器。
.spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit 字段是可选的。用于指定应保留的已完成作业和已失败作业的数量。默认情况下,分别设置为 3 和 1。如果将限制设定为 0,则对应种类的作业完成后不予保留。
创建 cron job:
$ oc create -f <file-name>.yaml
您还可以使用 oc create cronjob,在一个命令中创建并启动 Cron Job。以下命令会创建并启动与上一示例中指定的相似的 Cron Job:
$ oc create cronjob pi --image=perl --schedule='*/1 * * * *' -- perl -Mbignum=bpi -wle 'print bpi(2000)'
使用 oc create cronjob 时,--schedule 选项接受采用 cron 格式的调度计划。
6.1. 查看和列出 OpenShift Container Platform 集群中的节点
您可以列出集群中的所有节点,以获取节点的相关信息,如状态、年龄、内存用量和其他详情。
在执行节点管理操作时,CLI 与代表实际节点主机的节点对象交互。主控机(master)使用来自节点对象的信息执行健康检查,以此验证节点。
您可以获取集群中节点的详细信息。
以下命令列出所有节点:
$ oc get nodes
以下示例是具有健康节点的集群:
$ oc get nodes |