link管理
链接快照平台
- 输入网页链接,自动生成快照
- 标签化管理网页链接
相关文章推荐

|
暗恋学妹的领带 · python如何判断txt为空 | ...· 3 月前 · |
|
|
刀枪不入的啄木鸟 · “职通车”求职经验分享会第六期——国企专场_ ...· 3 月前 · |
|
|
活泼的水煮肉 · win10虚拟机怎么连接本机蓝牙 ...· 4 月前 · |
|
|
聪明的电影票 · PS怎么把一个图片放到另一个图片里?-即时设计· 9 月前 · |
|
|
文雅的领带 · Split Your Dataset ...· 10 月前 · |

之前开发了一个工具包 GerapyPyppeteer,GitHub 地址为 https://github.com/Gerapy/GerapyPyppeteer,这个包实现了 Scrapy 和 Pyppeteer 的对接,利用它我们就可以方便地实现 Scrapy 使用 Pyppeteer 爬取动态渲染的页面了。 另外,很多朋友在运行爬虫的时候可能会使用到 Docker,想把 Scrapy 和 Pyppeteer 打包成 Docker 运行,但是这个打包和测试过程中大家可能会遇到一些问题,在这里对 Pyppeteer 打包 Docker 的坑简单做一下总结。
Pyppeteer 打包 Docker 主要是有这么几个坑点:
下面我们分别对三个问题做下简单的 Troubleshooting。
首先说第一个,安装依赖。 因为 Docker 大部分都是基于 Linux 系统的,比如我常用的基础镜像就是
python:3.7
,剩余 Debian 系列,当然还有很多其他的版本,具体可以查看
https://hub.docker.com/_/python
了解下。 但是对于 Pyppeteer 来说,
python:3.7
内置的依赖库并不够,我们还需要额外进行安装,安装完毕之后还需要清空下 apt list,一句 Dockerfile 命令如下:
RUN apt-get update &&
apt-get -y install libnss3 xvfb gconf-service libasound2 libatk1.0-0 libc6 libcairo2 libcups2
libdbus-1-3 libexpat1 libfontconfig1 libgbm1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0
libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1
libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1
libxtst6 ca-certificates fonts-liberation libappindicator1 libnss3 lsb-release xdg-utils wget &&
rm -rf /var/lib/apt/lists/*
这里是提前安装了一下 Pyppteer 这个 Python 库,然后利用 Python 库提供的 pyppeteer-install 命令提前下载了 Chromium 浏览器。 这样后面启动的时候就可以直接唤起 Chromium 浏览器进行爬取了。
最后看下完整 Dockerfile,内容如下:
FROM python:3.7
RUN apt-get update &&
apt-get -y install libnss3 xvfb gconf-service libasound2 libatk1.0-0 libc6 libcairo2 libcups2
libdbus-1-3 libexpat1 libfontconfig1 libgbm1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0
libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1
libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1
libxtst6 ca-certificates fonts-liberation libappindicator1 libnss3 lsb-release xdg-utils wget &&
rm -rf /var/lib/apt/lists/*
RUN pip install -U pip && pip install pyppeteer && pyppeteer-install
WORKDIR /code
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD python3 run.py
解析页面是做爬虫的过程中的重要环节,而且如果站点多了,解析也会变得非常复杂,所以智能化解析就可能是一个不错的解决方案。如果我们能够容忍一定的错误率,那么我们可以利用智能化解析算法帮我们提取一些内容,简单高效。 那有没有办法做到一个网站的全自动化解析呢? 比如来了一个博客网站,我能首先识别出来这是一个列表页还是文章(详情)页,然后提取列表页的每篇文章的链接,然后跳转到每篇文章(详情)页再提取文章相关信息。 那么这里面可能就有四个关键部分:
如果我们能把这四步都用算法实现出来,那么我们只需要一个网站的主站链接就能轻松地把内容规整地爬取下来了。 那么这篇文章我们就来简单说下第一步,如何判断当前所在的页面的列表页还是文章(详情)页。
注:后文中文章页统一称之为详情页。
列表页和详情页不知道大家有没有基本的概念了,列表页就是导航页,里面带有好多文章或新闻或详情链接,我们选一个链接点进去就是详情页。 比如说这里拿新浪体育来说,首页如图所示:
 看到这里面有很多链接,就是一些页面导航集合,这个页面就是列表页。 然后我们随便点开一篇新闻报道,如图所示:
看到这里面有很多链接,就是一些页面导航集合,这个页面就是列表页。 然后我们随便点开一篇新闻报道,如图所示:
 这里就是一篇新闻报道,带有醒目的标题、发布时间、正文等内容,这就是详情页。 现在我们要做的就是用一个算法来凭借 HTML 代码区分出来哪个是列表页,哪个是详情页。 最后的输入输出如下:
这里就是一篇新闻报道,带有醒目的标题、发布时间、正文等内容,这就是详情页。 现在我们要做的就是用一个算法来凭借 HTML 代码区分出来哪个是列表页,哪个是详情页。 最后的输入输出如下:
首先我们确认下这个问题是个什么问题。 很明显,结果要么是列表页,要么是详情页,就是个二分类问题。 那二分类问题怎么解决呢?实现一个基本的分类模型就好了。大范围就是传统机器学习和现在比较流行的深度学习。总体上来说,深度学习的精度和处理能力会强一点,但是想想我们现在的应用场景,后者要追求精度的话可能需要更多的标注数据,而前者也有比较不错的易用的模型了,比如 SVM。 所以,我们不妨先选用 SVM 模型来实现一个基本的二分类模型来试试看,效果如果已经很好了或者提升空间不大了,那就直接用就好了,如果效果比较差,那我们再选用其他模型来优化。 好,那就定下来了,我们用 SVM 模型来实现一下试试。
既然要做分类模型,那么最重要的当然就是数据标注了,我们分两组就好了,一组是列表页,一组是详情页,我们先用手工配合爬虫找一些列表页和详情页的 HTML 代码,然后将其保存下来。 结果类似如下:
 每个文件夹几百个就行了,数量不用太多,五花八门的页面混起来更好。
每个文件夹几百个就行了,数量不用太多,五花八门的页面混起来更好。
既然要做 SVM,那么我们得想清楚要分清两个类别需要哪些特征。既然是特征,那我们就要选出二者不同的特征,这样更加有区分度。 比如这里我大体总结了有这么几个特征:
以上便是我简单列的几个特征,还有很多其他的特征也可以来挖掘,比如视觉特征等等。
真正代码实现的过程就是将现有的 HTML 文本进行预处理,把上面的一些特征提取出来,然后直接声明一个 SVM 分类模型即可。 这里声明了一个 feature 名字和对应的处理方法:
self.feature_funcs = {
'number_of_a_char': number_of_a_char,
'number_of_a_char_log10': self._number_of_a_char_log10,
'number_of_char': number_of_char,
'number_of_char_log10': self._number_of_char_log10,
'rate_of_a_char': self._rate_of_a_char,
'number_of_p_descendants': number_of_p_descendants,
'number_of_a_descendants': number_of_a_descendants,
'number_of_punctuation': number_of_punctuation,
'density_of_punctuation': density_of_punctuation,
'number_of_clusters': self._number_of_clusters,
'density_of_text': density_of_text,
'max_density_of_text': self._max_density_of_text,
'max_number_of_p_children': self._max_number_of_p_children,
'has_datetime_meta': self._has_datetime_mata,
'similarity_of_title': self._similarity_of_title,
}
self.feature_names = self.feature_funcs.keys()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
list_file_paths = list(glob(f'{DATASETS_LIST_DIR}/*.html'))
detail_file_paths = list(glob(f'{DATASETS_DETAIL_DIR}/*.html'))
x_data, y_data = [], []
for index, list_file_path in enumerate(list_file_paths):
logger.log('inspect', f'list_file_path {list_file_path}')
element = file2element(list_file_path)
if element is None:
continue
preprocess4list_classifier(element)
x = self.features_to_list(self.features(element))
x_data.append(x)
y_data.append(1)
for index, detail_file_path in enumerate(detail_file_paths):
logger.log('inspect', f'detail_file_path {detail_file_path}')
element = file2element(detail_file_path)
if element is None:
continue
preprocess4list_classifier(element)
x = self.features_to_list(self.features(element))
x_data.append(x)
y_data.append(0)
# preprocess data
ss = StandardScaler()
x_data = ss.fit_transform(x_data)
joblib.dump(ss, self.scaler_path)
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2, random_state=5)
# set up grid search
c_range = np.logspace(-5, 20, 5, base=2)
gamma_range = np.logspace(-9, 10, 5, base=2)
param_grid = [
{'kernel': ['rbf'], 'C': c_range, 'gamma': gamma_range},
{'kernel': ['linear'], 'C': c_range},
]
grid = GridSearchCV(SVC(probability=True), param_grid, cv=5, verbose=10, n_jobs=-1)
clf = grid.fit(x_train, y_train)
y_true, y_pred = y_test, clf.predict(x_test)
logger.log('inspect', f'n{classification_report(y_true, y_pred)}')
score = grid.score(x_test, y_test)
logger.log('inspect', f'test accuracy {score}')
# save model
joblib.dump(grid.best_estimator_, self.model_path)
这里首先对数据进行预处理,然后将每个 feature 存 存到 x_data 中,标注结果存到 y_data 中。接着我们使用 StandardScaler 对数据进行标准化处理,然后进行随机切分。最后使用 GridSearch 训练了一个 SVM 模型然后保存了下来。 以上便是基本的模型训练过程,具体的代码可以再完善一下。
以上的流程我已经实现了,并且发布了一个开源 Python 包,名字叫做 Gerapy AutoExtractor,GitHub 地址为 https://github.com/Gerapy/GerapyAutoExtractor 。 大家如需使用可以使用 pip 安装:
from gerapy_auto_extractor import is_detail, is_list, probability_of_detail, probability_of_list
from gerapy_auto_extractor.helpers import content, jsonify
html = content('detail.html')
print(probability_of_detail(html), probability_of_list(html))
print(is_detail(html), is_list(html))
html = content('list.html')
print(probability_of_detail(html), probability_of_list(html))
print(is_detail(html), is_list(html))
def init_device(platform="Android", uuid=None, **kwargs):
"""
Initialize device if not yet, and set as current device.
:param platform: Android, IOS or Windows
:param uuid: uuid for target device, e.g. serialno for Android, handle for Windows, uuid for iOS
:param kwargs: Optional platform specific keyword args, e.g. `cap_method=JAVACAP` for Android
:return: device instance
"""
可以发现它返回的是一个 Android 对象。 这个 Android 对象实际上属于
airtest.core.android
这个包,继承自
airtest.core.device.Device
这个类,与之并列的还有
airtest.core.ios.ios.IOS
、
airtest.core.linux.linux.Linux
、
airtest.core.win.win.Windows
等。这些都有一些针对 Device 操作的 API,下面我们以
airtest.core.android.android.Android
为例来总结一下。
了解了上面的方法之后,我们可以用一个实例来感受下它们的用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
from airtest.core.android import Android
from airtest.core.api import *
import logging
logging.getLogger("airtest").setLevel(logging.WARNING)
device: Android = init_device('Android')
is_locked = device.is_locked()
print(f'is_locked: {is_locked}')
if is_locked:
device.unlock()
device.wake()
app_list = device.list_app()
print(f'app list {app_list}')
uuid = device.uuid
print(f'uuid {uuid}')
display_info = device.get_display_info()
print(f'display info {display_info}')
resolution = device.get_render_resolution()
print(f'resolution {resolution}')
ip_address = device.get_ip_address()
print(f'ip address {ip_address}')
top_activity = device.get_top_activity()
print(f'top activity {top_activity}')
is_keyboard_shown = device.is_keyboard_shown()
print(f'is keyboard shown {is_keyboard_shown}')
is_locked: False
app list ['com.kimcy929.screenrecorder', 'com.android.providers.telephony', 'io.appium.settings', 'com.android.providers.calendar', 'com.android.providers.media', 'com.goldze.mvvmhabit', 'com.android.wallpapercropper', 'com.android.documentsui', 'com.android.galaxy4', 'com.android.externalstorage', 'com.android.htmlviewer', 'com.android.quicksearchbox', 'com.android.mms.service', 'com.android.providers.downloads', 'mark.qrcode', ..., 'com.google.android.play.games', 'io.kkzs', 'tv.danmaku.bili', 'com.android.captiveportallogin']
uuid emulator-5554
display info {'id': 0, 'width': 1080, 'height': 1920, 'xdpi': 320.0, 'ydpi': 320.0, 'size': 6.88, 'density': 2.0, 'fps': 60.0, 'secure': True, 'rotation': 0, 'orientation': 0.0, 'physical_width': 1080, 'physical_height': 1920}
resolution (0.0, 0.0, 1080.0, 1920.0)
ip address 10.0.2.15
top activity ('com.microsoft.launcher.dev', 'com.microsoft.launcher.Launcher', '16040')
is keyboard shown False
def connect_device(uri):
"""
Initialize device with uri, and set as current device.
:param uri: an URI where to connect to device, e.g. `android://adbhost:adbport/serialno?param=value¶m2=value2`
:return: device instance
:Example:
* ``android:///`` # local adb device using default params
* ``android://adbhost:adbport/1234566?cap_method=javacap&touch_method=adb`` # remote device using custom params
* ``windows:///`` # local Windows application
* ``ios:///`` # iOS device
"""
这里需要注意的是,在最开始没有调用 connect_device 方法之前,DEVICE_LIST 是空的,在调用之后 DEVICE_LIST 会自动添加已经连接的 device,DEVICE_LIST 就是已经连接的 device 列表
切换 device
我们可以使用 set_current 方法切换当前连接的 device,传入的是 index,定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
MemTotal: 3627908 kB
MemFree: 2655560 kB
MemAvailable: 2725928 kB
Buffers: 3496 kB
Cached: 147472 kB
SwapCached: 0 kB
Active: 744592 kB
Inactive: 126332 kB
Active(anon): 723292 kB
Inactive(anon): 16344 kB
Active(file): 21300 kB
Inactive(file): 109988 kB
Unevictable: 0 kB
Mlocked: 0 kB
HighTotal: 2760648 kB
HighFree: 2073440 kB
LowTotal: 867260 kB
LowFree: 582120 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 0 kB
Writeback: 0 kB
AnonPages: 720100 kB
Mapped: 127720 kB
Shmem: 19428 kB
Slab: 76196 kB
SReclaimable: 7392 kB
SUnreclaim: 68804 kB
KernelStack: 7896 kB
PageTables: 8544 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 1813952 kB
Committed_AS: 21521776 kB
VmallocTotal: 122880 kB
VmallocUsed: 38876 kB
VmallocChunk: 15068 kB
DirectMap4k: 16376 kB
DirectMap4M: 892928 kB
@logwrap
def start_app(package, activity=None):
"""
Start the target application on device
:param package: name of the package to be started, e.g. "com.netease.my"
:param activity: the activity to start, default is None which means the main activity
:return: None
:platforms: Android, iOS
"""
G.DEVICE.start_app(package, activity)
@logwrap
def stop_app(package):
"""
Stop the target application on device
:param package: name of the package to stop, see also `start_app`
:return: None
:platforms: Android, iOS
"""
G.DEVICE.stop_app(package)
@logwrap
def install(filepath, **kwargs):
"""
Install application on device
:param filepath: the path to file to be installed on target device
:param kwargs: platform specific `kwargs`, please refer to corresponding docs
:return: None
:platforms: Android
"""
return G.DEVICE.install_app(filepath, **kwargs)
@logwrap
def uninstall(package):
"""
Uninstall application on device
:param package: name of the package, see also `start_app`
:return: None
:platforms: Android
"""
return G.DEVICE.uninstall_app(package)
def snapshot(filename=None, msg="", quality=ST.SNAPSHOT_QUALITY):
"""
Take the screenshot of the target device and save it to the file.
:param filename: name of the file where to save the screenshot. If the relative path is provided, the default
location is ``ST.LOG_DIR``
:param msg: short description for screenshot, it will be recorded in the report
:param quality: The image quality, integer in range [1, 99]
:return: absolute path of the screenshot
:platforms: Android, iOS, Windows
"""
@logwrap
def touch(v, times=1, **kwargs):
"""
Perform the touch action on the device screen
:param v: target to touch, either a Template instance or absolute coordinates (x, y)
:param times: how many touches to be performed
:param kwargs: platform specific `kwargs`, please refer to corresponding docs
:return: finial position to be clicked
:platforms: Android, Windows, iOS
"""
另外上述的 touch 方法还可以完全等同于 click 方法。 如果要双击的话,还可以使用调用 double_click 方法,传入参数也可以是 Template 或者绝对位置。
滑动可以使用 swipe 方法,可以传入起始和终止位置,两个位置都可以传入绝对位置或者 Template,定义如下:
@logwrap
def swipe(v1, v2=None, vector=None, **kwargs):
"""
Perform the swipe action on the device screen.
There are two ways of assigning the parameters
* ``swipe(v1, v2=Template(...))`` # swipe from v1 to v2
* ``swipe(v1, vector=(x, y))`` # swipe starts at v1 and moves along the vector.
:param v1: the start point of swipe,
either a Template instance or absolute coordinates (x, y)
:param v2: the end point of swipe,
either a Template instance or absolute coordinates (x, y)
:param vector: a vector coordinates of swipe action, either absolute coordinates (x, y) or percentage of
screen e.g.(0.5, 0.5)
:param **kwargs: platform specific `kwargs`, please refer to corresponding docs
:raise Exception: general exception when not enough parameters to perform swap action have been provided
:return: Origin position and target position
:platforms: Android, Windows, iOS
"""
@logwrap
def pinch(in_or_out='in', center=None, percent=0.5):
"""
Perform the pinch action on the device screen
:param in_or_out: pinch in or pinch out, enum in ["in", "out"]
:param center: center of pinch action, default as None which is the center of the screen
:param percent: percentage of the screen of pinch action, default is 0.5
:return: None
:platforms: Android
"""
@logwrap
def text(text, enter=True, **kwargs):
"""
Input text on the target device. Text input widget must be active first.
:param text: text to input, unicode is supported
:param enter: input `Enter` keyevent after text input, default is True
:return: None
:platforms: Android, Windows, iOS
"""
@logwrap
def wait(v, timeout=None, interval=0.5, intervalfunc=None):
"""
Wait to match the Template on the device screen
:param v: target object to wait for, Template instance
:param timeout: time interval to wait for the match, default is None which is ``ST.FIND_TIMEOUT``
:param interval: time interval in seconds to attempt to find a match
:param intervalfunc: called after each unsuccessful attempt to find the corresponding match
:raise TargetNotFoundError: raised if target is not found after the time limit expired
:return: coordinates of the matched target
:platforms: Android, Windows, iOS
"""
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
@logwrap
def assert_exists(v, msg=""):
"""
Assert target exists on device screen
:param v: target to be checked
:param msg: short description of assertion, it will be recorded in the report
:raise AssertionError: if assertion fails
:return: coordinates of the target
:platforms: Android, Windows, iOS
"""
try:
pos = loop_find(v, timeout=ST.FIND_TIMEOUT, threshold=ST.THRESHOLD_STRICT)
return pos
except TargetNotFoundError:
raise AssertionError("%s does not exist in screen, message: %s" % (v, msg))
@logwrap
def assert_not_exists(v, msg=""):
"""
Assert target does not exist on device screen
:param v: target to be checked
:param msg: short description of assertion, it will be recorded in the report
:raise AssertionError: if assertion fails
:return: None.
:platforms: Android, Windows, iOS
"""
try:
pos = loop_find(v, timeout=ST.FIND_TIMEOUT_TMP)
raise AssertionError("%s exists unexpectedly at pos: %s, message: %s" % (v, pos, msg))
except TargetNotFoundError:
pass
@logwrap
def assert_equal(first, second, msg=""):
"""
Assert two values are equal
:param first: first value
:param second: second value
:param msg: short description of assertion, it will be recorded in the report
:raise AssertionError: if assertion fails
:return: None
:platforms: Android, Windows, iOS
"""
if first != second:
raise AssertionError("%s and %s are not equal, message: %s" % (first, second, msg))
@logwrap
def assert_not_equal(first, second, msg=""):
"""
Assert two values are not equal
:param first: first value
:param second: second value
:param msg: short description of assertion, it will be recorded in the report
:raise AssertionError: if assertion
:return: None
:platforms: Android, Windows, iOS
"""
if first == second:
raise AssertionError("%s and %s are equal, message: %s" % (first, second, msg))
这几个断言比较常用的就是 assert_exists 和 assert_not_exists 判断某个目标是否存在于屏幕上,同时还可以传入 msg,它可以被记录到 report 里面。 以上就是 Airtest 的 API 的用法,它提供了一些便捷的方法封装,同时还对接了图像识别等技术。 但 Airtest 也有一定的局限性,比如不能根据 DOM 树来选择对应的节点,依靠图像识别也有一定的不精确之处,所以还需要另外一个库 —— Poco。
利用 Poco 我们可以支持 DOM 选择,例如编写 XPath 等来定位某一个节点。 首先需要安装 Poco,使用 pip3 即可:
from airtest.core.api import *
from poco.drivers.android.uiautomation import AndroidUiautomationPoco
from poco.proxy import UIObjectProxy
poco = AndroidUiautomationPoco()
uri = 'Android://127.0.0.1:5037/emulator-5554'
connect_device(uri)
home()
object: UIObjectProxy = poco("com.microsoft.launcher.dev:id/workspace")
print(object)
poco 返回的是 UIObjectProxy 对象,它提供了其他的操作 API,例如选取子节点,兄弟节点,父节点等等,同时可以调用各个操作方法,如 click、pinch、scroll 等等。 具体的操作文档可以参见: https://poco.readthedocs.io/en/latest/source/poco.proxy.html 下面简单总结:
以上的这些方法混用的话就可以执行各种节点的选择和相应的操作。
最近遇到一个问题,那就是需要给别人共享一下 Kubernetes 的某个资源的使用和访问权限,这个仅仅存在于某个 namespace 下,但是我又不能把管理员权限全都给它,我想只给他授予这一个 Namespace 下的权限,那应该怎么办呢? 比如我这边是需要只想授予 postgresql 这个 Namespace 的权限,这里我就需要利用到 Kubernetes 里面的 RBAC 机制来实现了,下面记录了我的操作流程。
创建 Namespace
这里由于 Role 是 Namespace 级别的,所以只能在特定 Namespace 下生效,这里我要让授予本 Namespace 下的所有权限,这里 rules 就添加了所有的 API类型、资源类型和操作类型。
创建 RoleBinding
最后需要将 Role 和 ServiceAccount 绑定起来,yaml 如下:
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"ServiceAccount","metadata":{"annotations":{},"name":"postgresql","namespace":"postgresql"}}
creationTimestamp: "2020-07-30T16:10:38Z"
name: postgresql
namespace: postgresql
resourceVersion: "17800240"
selfLink: /api/v1/namespaces/postgresql/serviceaccounts/postgresql
uid: 6327db1f-6a93-4f1e-b988-31842989bbbc
secrets:
- name: postgresql-token-v26k7
server=https://your-server:443
name=postgresql-token-v26k7
namespace=postgresql
ca=$(kubectl get secret/$name -n $namespace -o jsonpath='{.data.ca.crt}')
token=$(kubectl get secret/$name -n $namespace -o jsonpath='{.data.token}' | base64 --decode)
echo "apiVersion: v1
kind: Config
clusters:
- name: test
cluster:
certificate-authority-data: ${ca}
server: ${server}
contexts:
- name: test
context:
cluster: test
user: postgresql
current-context: test
users:
- name: postgresql
user:
token: ${token}
" > postgresql.kubeconfig
运行之后就会生成一个 portgresql.kubeconfig 文件。
那么怎么使用呢?很简单,设置下环境变量切换下就好了。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
postgresql ClusterIP 10.0.193.137 <none> 5432/TCP 9d
postgresql-headless ClusterIP None <none> 5432/TCP 9d
postgresql-metrics ClusterIP 10.0.60.88 <none> 9187/TCP 9d
postgresql-read ClusterIP 10.0.236.184 <none> 5432/TCP 9d
之前也写过不少关于爬虫的博客了,比如我拿一个案例来写了一篇博客,当时写的时候好好的,结果过了一段时间这个页面改版了,甚至直接下线了,那这篇案例就废掉了。 另外如果拿别人的站或者 App 来做案例的话,比较容易触犯到对方的利益,风险比较高,比如把某个站的 JavaScript 逆向方案公布出来,比如把某个 App 的逆向方案公布出来。如果此时此刻没有对方联系你的话,一个很大原因可能是规模太小了别人没注意到,但不代表以后不会。我还是选择爱护自己的羽毛,关于逆向实际网站和 App 的案例我都不会发的。在这种情况下比较理想的方案是自建案例,只用这个案例讲明白对应的知识点就可以了。 所以,为此,这段时间我也在写一些爬虫相关的案例,比如:
今天发布一下。
本案例平台自爬数据、自建页面、自接反爬,案例稳定后永不过期,适合教学与练习。
SSR 网站
SPA 网站
验证码网站
模拟登录网站
反爬型网站
暂且是这么多,后续还会继续增加,大家可以试着爬爬看。
为了方便,我专门申请了一个域名,scrape.center,意思名为「爬取中心」,似乎听起来意义上还说的过去? 案例平台首页 URL:
https://scrape.center
,截图如下:
 大家可以点击任意一个网站来爬取练习。
大家可以点击任意一个网站来爬取练习。
下面是一些部分案例的截图:



 上面是一些案例的效果,基本上是使用 Django + Vue.js 开发的,主题使用了红色调,整个案例平台风格比较统一。另外还有一些 App 也是类似的风格,大家可以自行下载体验试试。 当然这里面最主要的还是案例的功能,比如各种加密、反爬、检测等等。
上面是一些案例的效果,基本上是使用 Django + Vue.js 开发的,主题使用了红色调,整个案例平台风格比较统一。另外还有一些 App 也是类似的风格,大家可以自行下载体验试试。 当然这里面最主要的还是案例的功能,比如各种加密、反爬、检测等等。
有朋友可能会问这个案例平台的源代码在哪里。 这里解释一下,由于这个案例平台以后会用于案例的讲解,并且可能会出现在课程、书本中,所以为了避免盗版和抄袭的问题,这里我选择了闭源,也算是对自己的知识成果的另一种保护吧。 不过这并不意味着爬取代码是闭源的,这块还是会开源出来的。
还有朋友会问,这一个个网站这么多类型和反爬,到底怎么爬呢? 其实现在针对这个练习平台一些案例讲解我已经做好了,课程也基本 OK 了,如果感兴趣大家可以点击看看。 https://t.lagou.com/cRC3RGRjSu706 谢谢大家。
将时间段间隔内的内存数据以快照的形式写入磁盘,它恢复时是将快照文件直接读到内存里(snapshot)
Redis 会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,在用这个临时文件替换上次持久化号的文件。 主进程是不进行任何的IO操作,确保了极高的性能 。如果需要进行大规模的数据恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能会 丢失
Fork:
作用:创建一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)都与原进程一致。但为一个全新的进程,并作为原进程的子进程
RDB保存的是dump.rdb文件
配置位置:
在redis.conf 中的snapshoting
save,save只管保存,其他不管全部阻塞 bgsave:redis会在后台异步进行快照操作 快照同时还可以响应客户端请求,可以通过lastsave命令获取最后一次成功执行快照的时间 执行flush命令也会产生dump.rdb文件,但里面是空的,无意义
如何恢复:
将备份文件(dump.rdb)移动到redis安装目录,并启动服务即可 在连接完成之后的终端 使用 config get dir 获取目录 异常恢复: redis-check-rdb —fix {}
适合大规模的数据备份 对数据完整性和一致性要求不高
在一定时间间隔内做一次备份,所以如果redis意外down了就会丢失最后一次快照后的所有更改 Fork的时候,内存中的数据被克隆了一份,内存等将会2倍膨胀性,需考虑!!!
如何停止:
动态所有停止rdb保存规则方法:redis-cli config set save “”
AOF:(Append only File):
为什么还会出现AOF?(新技术的出现必定弥补老技术的不足,新技术一定会借鉴老技术,是老技术的子类) 如果一个系统里面同时存在RDB是冲突呢还是协作? 为什么AOF会在RDB之后产生 AOF它会有什么优缺点?
原理: 以日志的形式来记录每个写操作 ,将Redis执行过的所有写 指令记录下来 (读操作不记录),只需追加文件但不可改写文件,Redis启动之初会读取该文件重新构建数据, 换言之,redis重启就根据日志文件的内容将写指令从前到后执行一次以完成数据恢复工作 配置位置: redis.conf中的APPEND ONLY MODE 配置说明: Appendfsunc:
always: 同步持久化,每次发生更改立即记录到磁盘,性能差但数据完整性比较好 everysec:出厂默认推荐,异步操作,每秒记录,如果一秒内宕机,有数据丢失 No
No-appendfsy-on-rewrite:重写时是否可以运用Appendfsync,默认no即可,保障数据安全 Auto-aof-rewrite-min-size :设定重写基准值 Auto-aof-rewrite-percentage : 设定重写基准值
探讨dump.rdb,与aof的二者是否能共存及选择顺序
当aof损坏时,rdb完全,二者可以和平共存 二者先选择aof
AOF启动/修复/恢复:
正常恢复:
启动:将redis.conf中APPEND ONLY MODE 下appendonly no改为yes 将有数据的aof文件复制一份保存到对于目录(config get dir) 恢复: 重启redis然后重新加载即可
异常恢复:
备份被写坏的AOF文件, 修复: Redistribution-check-aof —fix 进行修复 重启redis,重新加载即可
Rewrite:重写
AOF采用文件追加的方式,文件会越来越大为避免出现此种情况,新增了重写机制, 当AOF文件的大小超过所设定的阈值时,Redis会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用命令bgrewriteaof
重新原理:
AOF文件持续增长而过大时,会fork出一条新进程来讲文件重写(也是先写零食文件最后在rename),遍历新进程的内存数据,每条记录有一条的set语句.重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件.和快照有点类似
触发机制: REDIS会记录上次重写时的AOF大小,默认配置时当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发 优势:
每秒同步:appendfsync always 同步持久化 每次发送数据变更会被立即记录到磁盘,性能较差完整性比较友好 每修改同步: appendfsync everysec 异步操作,每秒记录,如果一秒内宕机,有数据丢失 不同步:appendfsync no 从不同步
劣势: 相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb AOF运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
Which one?:
RDB持久化方式:能够在指定的时间间隔内对数据进行快照存储 AOF持久化方式:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以Redis协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重新,使得AOF文件的体积不至于过大 只做缓存:
如果希望数据在服务器运行的时候存在,也可以不使用热河持久化方式.
同时开启两种持久化方式:
当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比rdb文件保存的数据集更完整 RDB的数据不实时,同时使用两者时服务器重启也指挥找AOF文件 那干脆直接使用AOF?不建议 因为RDB更适合用于数据库(AOF在不断变化不好备份),快速重启,而且不担保有AOF可能潜在的BUG,留着作为一个万一的手段
浅谈排序算法与优化(仅部分,Updating)
欢迎查阅与star的源码 写在最前面,此文章少了各排序算法的对比,但多了一份由浅入深的个人理解,以及代码、及算法的优化的思路 阅读文章约 需 5min
将一组“无序”的记录序列调整为“有序”的记录序列
将无序的列表变为有序列表 输入:列表; 输出:有序列表
升序与降序 内置排序函数:sort(),基于timsort排序算法
Timsort是一种混合稳定排序算法,源自归并排序(merge sort)和插入排序(insertion sort)
有兴趣的伙计可以看看这两篇文章
sort算法运用原理1
sort算法运用原理2
常见排序算法
列表每两个相邻的数,如果前面比后面大,则交换这两个数 一趟排序完成后,则无序区减少一个数,有序区增加一个数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
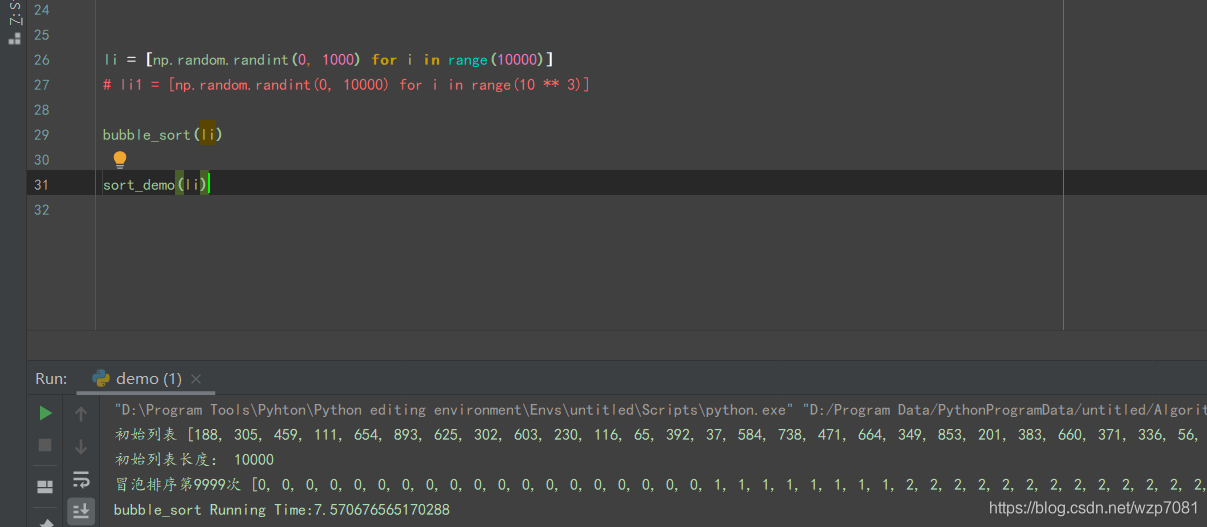
@cal_time
def bubble_sort(li: List[List]) -> List:
print('初始列表', li)
print('初始列表长度:', len(li))
for i in range(len(li) - 1): # 第i躺,总次数
i += 1
for j in range(len(li) - i - 1): # 指针
if li[j] > li[j + 1]: # 如果指针所对应的值大于对比的值,则二者交换位置
li[j], li[j + 1] = li[j + 1], li[j]
else:
break
print(f'冒泡排序第{i}次', li)
li = [np.random.randint(0, 1000) for i in range(5)]
bubble_sort(li)
数据来源于numpy.randmo.randint()随机取数,运行流程:
冒泡排序第1次 [257, 620, 136, 379, 392, 118, 312, 892, 647, 655]
冒泡排序第2次 [257, 620, 136, 379, 392, 118, 312, 892, 647, 655]
冒泡排序第3次 [257, 620, 136, 379, 392, 118, 312, 892, 647, 655]
冒泡排序第4次 [257, 620, 136, 379, 392, 118, 312, 892, 647, 655]
冒泡排序第5次 [257, 620, 136, 379, 392, 118, 312, 892, 647, 655]
冒泡排序第6次 [257, 620, 136, 379, 392, 118, 312, 892, 647, 655]
冒泡排序第7次 [257, 620, 136, 379, 392, 118, 312, 892, 647, 655]
冒泡排序第8次 [257, 620, 136, 379, 392, 118, 312, 892, 647, 655]
冒泡排序第9次 [257, 620, 136, 379, 392, 118, 312, 892, 647, 655]
# 排序次数:列表长度-1,
# 缘由将无序区转化为有序区:(再看一遍以下这段代码, 如果li[j]>li[j+1],则二者交换位置)
if li[j] > li[j + 1]:
li[j], li[j + 1] = li[j + 1], li[j]
# 当一维数组长度为10000的时候所需时间为:
 优化:
在一次回头看看冒泡排序具体实现思路,将
列表每两个相邻的数,如果前面比后面大,则交换这两个数
,
一趟排序完成后,则无序区减少一个数,有序区增加一个数
。 如果无序区已经是有序的呢?按照代码执行流程可知, 如果前者比后者大,那么则两个交换位置。(假设为降序,前面为无序区,后面为有序区) 否则不执行任何交换操作,但
会执行便利
(也可以理解为此运算”不执行任何交换操作,无实际意义”) 优化目标:(将“不执行任何交换的操作去掉”),咱们在回头看看,具体实际的运算是在第二层for循环里面的,也就说所谓的“无用功”也是在这里产生的 无用功体现为:无论是否进行了位置交换,都会在往有序区在遍历检查一遍 思路如下: 主要优化的地方在跳出循环,在它不交换位置的时候,直接跳出此次的循环 假设它全部都是有序的,并设个标记True, 当如果循环内发生了位置交换,则改变标记为False。 流程控制,if。当if True的时则会执行if内部代码(设立return,或者break)主要跳出循环。避免对有序区进行有一次的排序操作 具体代码实现如下:
优化:
在一次回头看看冒泡排序具体实现思路,将
列表每两个相邻的数,如果前面比后面大,则交换这两个数
,
一趟排序完成后,则无序区减少一个数,有序区增加一个数
。 如果无序区已经是有序的呢?按照代码执行流程可知, 如果前者比后者大,那么则两个交换位置。(假设为降序,前面为无序区,后面为有序区) 否则不执行任何交换操作,但
会执行便利
(也可以理解为此运算”不执行任何交换操作,无实际意义”) 优化目标:(将“不执行任何交换的操作去掉”),咱们在回头看看,具体实际的运算是在第二层for循环里面的,也就说所谓的“无用功”也是在这里产生的 无用功体现为:无论是否进行了位置交换,都会在往有序区在遍历检查一遍 思路如下: 主要优化的地方在跳出循环,在它不交换位置的时候,直接跳出此次的循环 假设它全部都是有序的,并设个标记True, 当如果循环内发生了位置交换,则改变标记为False。 流程控制,if。当if True的时则会执行if内部代码(设立return,或者break)主要跳出循环。避免对有序区进行有一次的排序操作 具体代码实现如下:
def bubble_sort(li: List):
print("The len of List:", len(li)) # 输入数组长度
for i in range(len(li) - 1): # 保证输入的数组在计算范围类,此处的“-1”是因为索引=长度-1
flag = True
for j in range(len(li) - i - 1):
if li[j] > li[j + 1]:
li[j + 1], li[j] = li[j], li[j + 1]
flag = False
print("Sorting times:%d, Status:%s" % (i + 1, li))
if flag:
break
视频都有一个唯一区分视频:BV 号 那么视频的 URL 规则为:’
https://wwww.bilibili.com/video/BV{BVID
}’ 找一下弹幕的地址,直接 search,即可!如下

由以上抓包可知,弹幕的 URL:’
https://api.bilibili.com/x/v1/dm/list.so?oid=oid
‘, 我们获取到 oid 那么这一步就完成了 来,回头去找一下 oid 从何而来呢? 据老夫多年经验指引,他一定在视频 URL 里面。(其实当时也找了挺久的,甚至逆向那一手,断点调试、调用堆栈等等什么都用出来了。最终还是功夫不负有心人,找到了) 其实回头看,oid 是等于 video_URL 页面里面的 cid 参数的(验证了 Payne 式猜想)。过程是难受的

URL,其参数规则也找到了,那么还不就随我为所欲为了。只要拿到视频地址,那不就可以直接拿到弹幕了么。of course!
此处省略 3 万字(请求,解析,网络原理。。。)
其实当时知道两个方法都去试了,JS 那个就不说了,有兴趣的盆友,可以去搞一下 说说这个提取 cid 参数吧,我用的是正则,这种情况最好是用正则,不过也看个人喜好吧。 可以回头看第二张图,初一乍看我好像不会,啊哈哈~
经过优化后(主要是看了其他视频的那啥之后):写出这个神奇的正则
补充知识:
迭代、递归与循环:迭代与递归都是循环的子集,一个是取值推算,一个是不断的调用自己。 相同点:迭代、递归、循环都是“重复” 相似点:调用逻辑相似 不同点:我简单理解为迭代是根据自身的上一个值推算下一个值,而递归则是由上一个值与“己身”直接运算。循环是自身与外界计算 堆栈关系调用不同 当然也不能说谁好谁坏,只能说三者主针对不同
来,来,来,翠花上栗子:
递归,归去来兮 :
算法是对特定问题求解 步骤 的一种描述,如果将问题看作函数,那么算法是吧输入转化为输出
是对特定问题求解步骤的一种描述,是为了解决一个或者一类问题给出的 一个确定的、有限长的操作序列。 算法的设计依赖于数据的存储结构,因此对确定的问题,应该需求子啊适宜的存储结构上设计出一种效率较高的算法
算法的重要特性:
对于任何一组合法的输入值,在执行有穷步骤之后一定能结束,即算法中的操作步骤为有限个,并且每个步骤都能在有限的时间内完成
对于每种情况下所应该执行的路径的操作,在算法中都有确切的规定,使算法的执行者或阅读者都能明确其含义及如何执行;并且在确切的条件下只有唯一一条执行流程路径
算法中的所有操作都必须足够基本,都可以通过已经实现的基本运算执行有限次实现
作为算法加工对象的量值,通常体现为算法中的一组变量。有些输入量需要在算法的执行过程中输入,而有些算法表面上没有输入,但实际上已被嵌入算法之中
它是一组与“输入”有确定关系的量值,是算法进行信息加工够得到的结果。这种确定关系即为算法的功能
算法设计目标:
算法应满足具体问题的需求,正确反映求解问题对输入、输出加工处理等方面的需求
算法处理用于编写程序子啊计算机上执行之外,另一个重要用处是阅读和交流。 算法中加入适当的注释,介绍算法的设计思路、各个模块的功能等一些必要性的说明文字来帮助读者理解算法。 要求: 算法中加入适当的注释,介绍算法的设计思路、各个模块的功能等一些必要性的说明文字来帮助读者理解算法 对算法中出现的各种自定义变量和类型能做到“见名知义”,即读者一看到某个变量(或类型名)就能知道其功能
当输入数据非法时,算法能够适当地做出反应或进行处理,输出表示错误性质的信息并终止执行,而不会产生莫名其妙的输出结果。
时间效率与存储占用量:
一般来说,求解同一个问题若有多种算法,则 执行时间短的算法效率高 占用存储空间少的算法较好 算法的执行时间开销和存储空间开销往往相互制约,对高时间效率和低存储占用的要求只能根据问题的性质折中处理
算法复杂度
算法的时间复杂度:
算法的效率指的是算法的执行时间随问题“规模”(通常用整型量 n 表示)的增长而增长的趋势 “规模”在此指的是输入量的数目,比如在排序问题中,问题的规模可以是被排序的元素数目 假如随着问题规模 n 的增长,算法执行时间的增长率和问题规模的增长率相同则可记为: T(n) = O(f(n))
f(n) 为问题规模 n 的某个函数; T(n)被称为算法的(渐进)时间复杂度(Time Complexity) O 表示法不需要给出运行时间的精确值; 选择 f(n),通常选择比较简单的函数形式,并忽略低次项和系数 常用的有 O(1)、O(logn)、O(n)、O(nlogn)、O(n*n)等等 多项式时间复杂度的关系为: O(1) < O(logn) < O(n) < O(N logn) < O(n²) < O(n³) 指数时间算法的关系为: O(2(n 方))< O(n!) <O(n(n 方))
由于估算算法时间复杂度关心的只是算法执行时间的增长率而不是绝对时间,因此可以忽略一些因素。 方法:从算法中选取一种对于所研究的问题来说是“ 基本操作” 的原操作,以该“基本操作”在算法中重复执行的次数作为算法时间复杂度的依据。 EG:
两个 n x n 的矩阵相乘,求其时间复杂度
为了降低复杂度,一个直观的思路是:梳理程序,看其流程中是否有无效的计算或者无效的存储。我们需要从时间复杂度和空间复杂度两个维度来考虑。 常用的降低时间复杂度的方法有递归、二分法、排序算法、动态规划等, 降低空间复杂度的方法,就要围绕数据结构做文章了。 降低空间复杂度的核心思路就是,能用低复杂度的数据结构能解决问题,就千万不要用高复杂度的数据结构。
如何评定一个程序算法的好坏?
简而言之:在符合算法设计标准的前提下,运行的更快、所用计算资源更少。即是更好的算法
请注意这里的比较级别词 更 !!!,对于算法,个人认为就是获得同一结果的同时探究 最优 解决之道
探究算法优化(自我一点点小体悟-个人能力有限)
抽象化:将 不必要 的计算过程去掉
利用高斯算法解决累计求和问题
慎选各 数据结构 ,善用 第三方 算法
去重: 善用迭代什么的等等 使用字典的特性-不可重复性 布隆过滤器去重(源于哈希算法)
时空转换:将 昂贵的 时间转化为 廉价的 空间
当‘优无可优时’,取贵舍廉 空间是可以用 钱 买的,加个什么 内存 啊,加个 处理器 等等什么的 时间是逝去就不在了
以上仅仅个人的一点点小灵感,望大家不喜勿喷
说了这么多,来道简单的算法题目导入(同一计算机,i5, python)
 需求如下:累计求和 1-n 的值(1. 为防止误差,验证 10 次; 2. 验证每次计算次数)
需求如下:累计求和 1-n 的值(1. 为防止误差,验证 10 次; 2. 验证每次计算次数)
# 在同一空间复杂下(也就是说没有迭代,探究暴力解法与高斯算法)
# n = 100000
# Method one 代码如下
def func(n):
start = time.time()
count = 0
theSum = 0
for i in range(n + 1):
theSum = theSum + n
count += 1
end = time.time()
return theSum, end - start, count
for i in range(10):
print(f"Sum is %d Required %10.10f seconds count = %d" % func(10000))
# %10.10f 表示取10位小数,运行结果如下
Sum is 100010000 Required 0.0010061264 seconds count = 10001 Sum is 100010000 Required 0.0009891987 seconds count = 10001 Sum is 100010000 Required 0.0000000000 seconds count = 10001 Sum is 100010000 Required 0.0010235310 seconds count = 10001 Sum is 100010000 Required 0.0009710789 seconds count = 10001 Sum is 100010000 Required 0.0000000000 seconds count = 10001 Sum is 100010000 Required 0.0009973049 seconds count = 10001 Sum is 100010000 Required 0.0010013580 seconds count = 10001 Sum is 100010000 Required 0.0000000000 seconds count = 10001 Sum is 100010000 Required 0.0019786358 seconds count = 10001 探究可知:n 扩大 10 倍,运算时间也会扩大 10 倍 高斯算法,从 1 累加至 n,等于(首项+尾项) 项数/2 直接引用结论: 1+2+3+…+(n-1) +n={(1+n)+(2+(n-1))…}/2 = (n (n + 1))/2
计算结果如下: 循环计算 10000 次,出去 I/O 所需时间几乎可以不计。 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.0000000000000000000000000000000000000000000000000123123000000000000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.000000000000000000000000000000000000000000000000012332100000000000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.00000000000000000000000000000000000000000000000000000002310000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.000000000000000000000000000000000000000000000000000000000000120000000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.000000000000000000000000000000000000000000000000000000010032000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.0000000000000000000000000000000000000000000000012231300000000000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552 Sum is 49999999999999998486656110625518082973725163772751181324120875475173424217777037767098169202353125934013756207986941204091067867184139242319692520523619938935511795533394990905590906653083564427444224 Required 0.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 seconds count = 5000000000000000079514455548799590234180404281972640694890663778873919386085190530406734992928407552
class Singleton(object):
# def __new__(slef):类方法
# pass
# 当我们没写时默认调用object__new__方法
# 然后在执行类的实例化对象:__init__
def __init__(self): # 实例方法
pass
@classmethod
def instance(cls, *args,**kwargs):
if not has attr(Singleton,"_instance"):
Singleton._instance = Singleton(*args,**kwargs)
return Singleton._intance
class Singleton(object):
def __init__(self):
pass
@classmethod
def instance(cls, *args, **kwargs):
if not hasattr(Singleton, "_instance"):
Singleton._instance = Singleton(*args, **kwargs)
return Singleton._instance
import threading
def task(arg):
obj = Singleton.instance()
print(obj)
for i in range(10):
t = threading.Thread(target=task,args=[i,])
t.start()
当然此时也并没有什么问题,BUT在’ init ‘方法中加入I/O(input/output)操作就凉凉了 问题出现了,按照以上方式创建的单例无法支持 多线程 缘由:Python中实例化对象与初始化对象是分开执行的,又由于多线程之间是通信共享的,故出现线程安全问题。主要体现为,create一个之后kill一个,create一个又被kill一个。所以就。。。 解决思路一:相互独立,分而治之。加锁独立 也就是咱们所了解、知道的线程锁的概念,使得其无序变为相对有序。具体代码便不在此赘述 在看看思路一(相互独立,分而治之。加锁独立) 解决思路二:‘反’实例化,加锁保护独立,确保通用性 在Python3中,调用父类方法是为super(),那么是否可以增加判断: 当类属性不为空时,我们便不在实例化且返回一个 已实例化 的类属性。这样还是不太完美,带有局限性。进一步加锁保护优化以保障多线程情况下只有一个线程同时访问。这样就保障了单例的安全 基于 new 方法实现!!!
// from * import singleton 需使用时,直接在其他文件中导入此文件中的对象,那么这个对象即是单例模式对象 还有个基于元类的就没书写了具体请看: https://blog.csdn.net/weixin_44239343/article/details/89376796
面试题之二:Redis有几种数据类型?
如果是单单是Redis那么 常用数据类型为五种 他们分别是:String,List,hash,set,zset String:字符串,一个字符串Value最多可以是512M Hash:哈希,是一个String类型的field和Value的映射表 List:列表,时间是链表 Set:集合是一个String类型无序无重复集合,其通过Hash Table实现 Zset(sorted):有序集合 那么应聘时,请注意这个小坑,你 Python 使用Redis又几种数据类型? 这个是基于语言来回答的,所用语言+Redis数据类型杂糅 Number,String,list,tuple(这个不确定),dict,aggregate 同时又涉语言所拥有的数据类型与redis,一样的就 ‘合二为一’ 嘛 以Python为例,稍后继续探究这(6+5)之间的杂糅,dict与aggregate其二者区别为主(其实我也不晓得更深的了)。以及1对1,1对多,多对1。数据结构搞起来,然后哼哼~。
面试题之三:Scrapy框架的运行流程及各模块的作用
如果简历里面写了分布式会拓展scrapy-Redis架构以及其作用。 CAP理论,估计会扯到数据这块。拓展database什么特性啊,之类的。谈优化,谈数据结构。反正数据结构与算法这块,基于此,难于此,也凉于此
面试题之四:scrapy去重所用的几种机制
谨记:先从scrapy本身的去重原理及机制说起来,最基础,优缺点,去重原理等等。一步步来,一上来就BloonFilter,风险不小啊 对于此,自我总结如下:
1、scrapy 基于内存
之前我写过几篇文章介绍过有关爬虫的智能解析算法,包括商业化应用 Diffbot、Readability、Newspaper 这些库,另外我有一位朋友之前还专门针对新闻正文的提取算法 GeneralNewsExtractor,这段时间我也参考和研究了一下这些库的算法,同时参考一些论文,也写了一个智能解析库,在这里就做一个非正式的介绍。
那首先说说我想做的是什么。 比如这里有一个网站,网易新闻,
https://news.163.com/rank/,这里有个新闻列表,预览图如下
:
 任意点开一篇新闻,看到的结果如下:
任意点开一篇新闻,看到的结果如下:
 我现在需要做到的是在不编写任何 XPath、Selector 的情况下实现下面信息的提取: 对于列表页来说,我要提取新闻的所有标题列表和对应的链接,它们就是图中的红色区域:
我现在需要做到的是在不编写任何 XPath、Selector 的情况下实现下面信息的提取: 对于列表页来说,我要提取新闻的所有标题列表和对应的链接,它们就是图中的红色区域:
 这里红色区域分了多个区块,比如这里一共就是 40 个链接,我都需要提取出来,包括标题的名称,标题的 URL。 我们看到页面里面还有很多无用的链接,如上图绿色区域,包括分类、内部导航等,这些需要排除掉。 对于详情页,我主要关心的内容有标题、发布时间、正文内容,它们就是图中红色区域:
这里红色区域分了多个区块,比如这里一共就是 40 个链接,我都需要提取出来,包括标题的名称,标题的 URL。 我们看到页面里面还有很多无用的链接,如上图绿色区域,包括分类、内部导航等,这些需要排除掉。 对于详情页,我主要关心的内容有标题、发布时间、正文内容,它们就是图中红色区域:
 其中这里也带有一些干扰项,比如绿色区域的侧边栏的内容,无用的分享链接等。 总之,我想实现某种算法,实现如上两大部分的智能化提取。
其中这里也带有一些干扰项,比如绿色区域的侧边栏的内容,无用的分享链接等。 总之,我想实现某种算法,实现如上两大部分的智能化提取。
之前我开发了一个叫做 Gerapy https://github.com/Gerapy/Gerapy 的框架,是一个基于 Scrapy、Scrapyd 的分布式爬虫管理框架,属 1.x 版本。现在正在开发 Gerapy 2.x 版本,其定位转向了 Scrapy 的可视化配置和调试、智能化解析方向,放弃支持 Scraypd,转而支持 Docker、Kubernetes 的部署和监控。 对于智能解析来说,就像刚才说的,我期望的就是上述的功能,在不编写任何 XPath 和 Selector 的情况下实现页面关键内容的提取。 框架现在发布了第一个初步版本,名称叫做 Gerapy Auto Extractor,名字 Gerapy 相关,也会作为 Gerapy 的其中一个模块。 GitHub 链接: https://github.com/Gerapy/GerapyAutoExtractor 现在已经发布了 PyPi, https://pypi.org/project/gerapy-auto-extractor/,可以使用 pip3 来安装,安装方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
[
{
"title": "1家6口5年"结离婚"10次:儿媳"嫁"公公岳",
"url": "https://news.163.com/20/0705/05/FGOFE1HJ0001875P.html"
},
{
"title": ""港独"议员泼水阻碍教科书议题林郑月娥深夜斥责",
"url": "https://news.163.com/20/0705/02/FGO66FU90001899O.html"
},
{
"title": "感动中国致敬留德女学生:街头怒怼"港独"有理有",
"url": "https://news.163.com/20/0705/08/FGOPG3AM0001899O.html"
},
{
"title": "香港名医讽刺港警流血少过月经受访时辩称遭盗号",
"url": "https://news.163.com/20/0705/01/FGO42EK90001875O.html"
},
{
"title": "李晨独居北京复式豪宅没想到肌肉男喜欢小花椅子",
"url": "https://home.163.com/20/0705/07/FGOLER1200108GL2.html"
},
{
"title": "不战东京!林丹官宣退役正式结束20年职业生涯",
"url": "https://sports.163.com/20/0704/12/FGML920300058782.html"
},
{
"title": "香港美女搬运工月薪1.6万每月花6千租5平出租",
"url": "https://home.163.com/20/0705/07/FGOLEL1100108GL2.html"
},
{
"title": "杭州第一大P2P"凉了":近百亿未还!被警方立案",
"url": "https://money.163.com/20/0705/07/FGON5T7B00259DLP.html"
},
...
]
{
"title": "内蒙古巴彦淖尔发布鼠疫疫情Ⅲ级预警",
"datetime": "2020-07-05 18:54:15",
"content": "2020年7月4日,乌拉特中旗人民医院报告了1例疑似腺鼠疫病例,根据《内蒙古自治区鼠疫疫情预警实施方案》(内鼠防应急发﹝2020﹞7号)和《自治区鼠疫控制应急预案(2020年版)》(内政办发﹝2020﹞17号)的要求,经研究决定,于7月5日发布鼠疫防控Ⅲ级预警信息如下:n一、预警级别及起始时间n预警级别:Ⅲ级。n2020年7月5日起进入预警期,预警时间从本预警通告发布之日持续到2020年底。n二、注意事项n当前我市存在人间鼠疫疫情传播的风险,请广大公众严格按照鼠疫防控“三不三报”的要求,切实做好个人防护,提高自我防护意识和能力。不私自捕猎疫源动物、不剥食疫源动物、不私自携带疫源动物及其产品出疫区;发现病(死)旱獭及其他动物要报告、发现疑似鼠疫病人要报告、发现不明原因的高热病人和急死病人要报告。要谨慎进入鼠疫疫源地,如有鼠疫疫源地的旅居史,出现发热等不适症状时及时赴定点医院就诊。n按照国家、自治区鼠疫控制应急预案的要求,市卫生健康委将根据鼠疫疫情预警的分级,及时发布和调整预警信息。n巴彦淖尔市卫生健康委员会n2020年7月5日n来源:巴彦淖尔市卫生健康委员会"
}
成功输出了标题、正文、发布时间等内容。 这里就演示了基本的列表页、详情页的提取操作。
整个算法的实现比较杂,我看了几篇论文和几个项目的源码,然后经过一些修改实现的。 其中列表页解析的参考论文:
详情页解析的参考论文和项目:
这些都是不完全参考,然后加上自己的一些修改最终才形成了现在的结果。 算法在这里就几句话描述一下思路,暂时先不展开讲了。 列表页解析:
详情页解析:
后面等完善了之后再详细介绍算法的具体实现,现在如感兴趣可以去看源码。
本框架仅仅发布了最初测试版本,测试覆盖度比较少,目前仅仅测试了有限的几个网站,尚未大规模测试和添加对比实验,因此准确率现在还没有标准的保证。 参考:关于详情页正文的提取我主要参考了
GeneralNewsExtractor
这个项目,原项目据测试可以达到 90% 以上的准确率。 列表页我测试了腾讯、网易、知乎等都是可以顺利提取的,如:


 后面会有大规模测试和修正。 项目初版,肯定存在很多不足,希望大家可以多发 Issue 和提 PR。 另外这里建立了一个 Gerapy 开发交流群,之前在 QQ 群的也欢迎加入,以后交流就在微信群了,大家在使用过程遇到关于 Gerapy、Gerapy Auto Extractor 的问题欢迎交流。 这里放一个临时二维码,后期可能会失效,失效后大家可以到公众号「进击的 Coder」获取加群方式。
后面会有大规模测试和修正。 项目初版,肯定存在很多不足,希望大家可以多发 Issue 和提 PR。 另外这里建立了一个 Gerapy 开发交流群,之前在 QQ 群的也欢迎加入,以后交流就在微信群了,大家在使用过程遇到关于 Gerapy、Gerapy Auto Extractor 的问题欢迎交流。 这里放一个临时二维码,后期可能会失效,失效后大家可以到公众号「进击的 Coder」获取加群方式。

待开发功能
最后感谢大家的支持!
主要亮点为配置和密码找回,安装什么的就。。。
MySQL 基本配置
官网地址:www.mysql.com 安装可参考: https://cuiqingcai.com/5200.html
window:
[gallery columns=”1” size=”full” ids=”9457”] 注意终端 mysqld 开启的不能关闭!
MySQL 密码找回:
密码验证思路:mysql 必定将管理员账号密码存储在某个文件夹内,使用时与输入密码验证,成功则能够连接,否则连接失败。 密码找回思路: 跳过 MySQL 密码的验证直接进入
停止 mysql 服务(注:需要终端的管理员权限运行)
// windows:
查询进程,并找到 PID:
tasklist | findsrt mysqld
1
2
3
4
2. kill 掉 mysql 进程,否则是停止不了服务的,无论如何都需要 kill 掉:

#此处的为上面查询到的PID,每次都是不一样的,所以就不写具体值了 taskkill /F /PID PID
git remote add [origin] [Warehouse URI] 创建别名为 origin,github 仓库地址为。。。的 git remote -v 查看相关信息
推送操作:
git fetch [远程库中简称(origin)] [远程库分支名(master)]
git merge [远程库中简称/远程库分支名(origin/master)]
fetch:
首先是查看了 remote
然后使用 git fetch 命令下载了远程库内容
查看本地库中的 project.txt 内容
切换到新下载的 master 目录(可使用 git reflog 查看分支状态)
查看远程库中 project.txt 内容
merge:将远程库下载的内容与本地库合并
缘由:如果不是基于远程库的最新版本进行修改的
解决:不能推送,必须先拉,拉下来进入冲突状态,进行对内容的修改,删除不相关内容,重新处理即可。更详情请查看前面的 push 冲突解决。
团队外协作:
首先使用 vim 命令新建了一个名为 hard.txt,并在里面写入项目数据‘aaa、bbb’
使用 git add hard.txt 命令将 hard.txt 添加到暂存区
使用 git commit hard.txt 命令将 hard.txt 添加到 本地库
使用命令 git reflog 查看相关的将要操作的参考
给‘项目’版本进行更新:
基本的已完成了,让我们来试试版本的前进与后退,并查看相对应的内容
git reset —hard [索引值] //前进与后退索引命令
版本后退:
基于符号的版本控制
合并分支注意:首先对其他分支进行编辑更新添加新功能,然后需切换到主分支 master 上,执行 merge 命令,完成合并。便可更新增的功能
// 解决冲突(手动),当不能直接使用 merge 合并时,则需要
在不同分支出现出现相对应的更改时,自动合并不知道以何更新为主,合并将产生冲突;
重新 add,commit 注意 commit 不能带文件名
编辑文件,删除特殊符号
把文件修改至满意,保存并退出
git add 【file name】
此处的 commit 不能带 file name
简介:了解过 git 来源的朋友,应该会晓得 git 与 Linux 系统是同一作者,所以在此操作 Linux 的基础命令几乎都能运行,在此便不在过多赘述: 列举几个在此常用的命令:
ls -lA:查看所有的目录(包含隐藏文件夹)
ls -l|less 分屏的去查看
安装好了之后如果是默认安装,git 会添加到鼠标右击的快捷栏中(如下所示): 
Git 使用前许初始化本地库,具体操作如下:
本地库初始化:(命令行:Git Bash Here)
命令:git add(使用 git bash here)
首先是使用了’ll‘,命令查看当前前目录先文件夹及权限
使用 mkdir anothergit 命令在当前目录下创建了一个名为 anothergit 的文件夹
使用 git init ,初始化本地库
ll -lA // 显示该目录下全部的文件夹(注:如果使用’ll‘是不能显示出’.git/‘的)
ll .git/ // 查看.git/文件夹下的可显示的文件夹
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注:.git 目录中存放的是本地库相关的配置文件,请勿随意删除及修改。(这里凉了就凉凉了,git 的命令也帮不了你)
## 设置签名:
主要用于区分开发者身份,并非会验证验证其邮箱真实性,
- 形式:
- 用户名:Payne
- Email 地址:[email protected]
- 这里设置的前和登录远程库的账号密码无任何关系
- 签名:如果都有的话会以项目级别仓库签名为使用,否则会以系统用户级别为使用
- 项目级别(仓库级别):仅在此库有效
- 命令:
//主要用的命令 git config // 实际用的 git config user.name Payne_project git config user.eamil [email protected]
1
2
3
- 实际操作:
- 使用命令,查看项目级别签名设置结果:
cat ./git/config
1
2
3
- 系统用户级别:登录当前操作系统的用户范围(包含多个项目级别,仓库级别)
- 命令:
//主要用的命令 git config --global // 实际用的 git config --global user.name Payne_global git config --global user.eamil [email protected]
实际操作 系统用户级别的 config 是在系统目录下,如果不想太麻烦的去找直接 cat ~/.git config 即可
系统用户级别的 config 是在系统目录下,如果不想太麻烦的去找直接 cat ~/.git config 即可
这篇文章是我近日学习 git 的笔记,单纯想做个“云备份什么的”,所以的话侧重点就有点偏。
Git 的来源、用处相信大家都或多或少的了解,如果真的想知道的话请自行百度哈~
Git 的安装:
推荐镜像安装:https://npm.taobao.org/mirrors/git-for-windows/ Git 官网地址
Git 安装相关简介>):
各系统的安装(并非唯一方式!)
https://git-scm.com/download/win

 选择相对应的版本下载即可,下载完成后打开相对应的安装执行,有选项的选择的建议点击第一个默认配置,就不在此过多赘述啦。
选择相对应的版本下载即可,下载完成后打开相对应的安装执行,有选项的选择的建议点击第一个默认配置,就不在此过多赘述啦。
MacOS:在命令行中输入以下命令即可
 以上的网页地址为: https://git-scm.com/download/mac
以上的网页地址为: https://git-scm.com/download/mac
Linux:(sudo:以管理员权限运行相关的命令,中间的‘-y’:默认同意安装)
apt-get install git apt-get -y install git sudo apt-get install git sudo apt-get -y install git
https://git-scm.com/download/linux
Git 和代码托管中心
局域网环境下:
可搭建 GitLab 服务器
外网环境下:
Github
并发与并行:(偏向于多线/进程方面的原理)
并发: 指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行
并行: 指在同一时刻,有多条指令在多个处理器上同时执行。所以无论从微观还是从宏观来看,二者都是一起执行的
阻塞与非阻塞:(偏向于协程/异步的原理)
阻塞:阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续处理其他的事情,则称该程序在该操作上是阻塞的。
非阻塞:程序在等待某操作过程中,自身不被阻塞,可以继续处理其他的事情,则称该程序在该操作上是非阻塞的
同步与异步:
同步:不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,我们称这些程序单元是同步执行的。
异步:为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式,不相关的程序单元之间可以是异步的。
说了这么多,咱们列举一些他们相关的特点吧:
多线程(英语:multithreading):指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理(Chip-level multithreading)或同时多线程(Simultaneous multithreading)处理器。在一个程序中,这些独立运行的程序片段叫作“线程”(Thread),利用它编程的概念就叫作“多线程处理(Multithreading)”
多进程(Multiprocessing):每个正在系统上运行的程序都是一个进程。每个进程包含一到多个线程。进程也可能是整个程序或者是部分程序的动态执行。线程是一组指令的集合,或者是程序的特殊段,它可以在程序里独立执行。也可以把它理解为代码运行的上下文。所以线程基本上是轻量级的进程,它负责在单个程序里执行多任务。通常由操作系统负责多个线程的调度和执行。线程是程序中一个单一的顺序控制流程.在单个程序中同时运行多个线程完成不同的工作,称为多线程.
二者的区别:线程和进程的区别在于,子进程和父进程有不同的代码和数据空间,而多个线程则共享数据空间,每个线程有自己的执行堆栈和程序计数器为其执行上下文.多线程主要是为了节约 CPU 时间,发挥利用,根据具体情况而定. 线程的运行中需要使用计算机的内存资源和 CPU。
协程(Coroutine):又称微线程、纤程,协程是一种用户态的轻量级线程。 协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
基本的原理都已经了解了 ,那咱们不整一下,咋行?光说不练假把式,走起!!! 本节源码:仓库地址>) 首先先说一下基本的思路:
确定 URL
发起请求,得到响应
解析响应,提取数据、
确定 URL:
本次请求的 URL(先放地址了!) https://www.guazi.com/cs/buy/o2/#bread 
async def parse(self, html):
with open('car.csv', 'a+', encoding='utf-8') as f:
doc = pq(html)
for message in doc('body > div.list-wrap.js-post > ul > li > a').items():
# 汽车简介
car_name = message('h2.t').text()
# 汽车详情(年限、里程、服务)
car_info = message('div.t-i').text()
year = car_info[:5]
mileage = car_info[6:-5]
service = car_info[13:].replace('|', '')
# 价格
try:
price = message('div.t-price > p').text()
except AttributeError:
price = message('em.line-through').text()
car_pic = message('img').attr('src')
data = f'{car_name}, {year},{mileage}, {service}, {price}n'
logging.info(data)
f.write(data)
加密:数据加密的基本过程,将原为明文的文件或数据经过某种算法进行一次或多次处理。得到的结果常称之为密文的东东。
解密:加密的逆过程,找到加密相同的方式,对其逆向处理,得到原本文件或数据的过程
常用的加密方式:
加密算法分 对称加密 和 非对称加密 其中对称加密算法的加密与解密 密钥相同,非对称加密算法的加密密钥与解密 密钥不同,此外,还有一类 不需要密钥 的 散列算法。
本节所涉及的方式:MD5
MD5 用的是 哈希函数,它的典型应用是对一段信息产生 信息摘要,以 防止被篡改。严格来说,MD5 不是一种 加密算法 而是 摘要算法。无论是多长的输入,MD5 都会输出长度为 128bits 的一个串 (通常用 16 进制 表示为 32 个字符)。 更多相关详情请点击此处>)
二 造!点击进入本节源码
这段内容图会比较多,文字叙述会比较少.
确定 URL:
Basic URL : http://fanyi.youdao.com/ 结论缘由,在不刷新全局页面的情况下,在输入框中输入,翻译动态刷新.可知此链接为 Ajax.  经过一系列测试发现,其实际需操作的 URL 为 http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule 在开发者工具中具体观察以下.
经过一系列测试发现,其实际需操作的 URL 为 http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule 在开发者工具中具体观察以下.  基本网站的分析就分析完毕了 注意此处为 POST 请求!!!
基本网站的分析就分析完毕了 注意此处为 POST 请求!!!
仔细观察红色方框中,重点观察随着时间改变而改变的参数(图中红色箭头所指之处)
分析加密:
断点一打,debug 一下,啥都出来了.
e 为输入所翻译的内容
ts 为七位整数的时间戳
salt 为时间戳后加上一位,大于 0 小于 9 的数字
bv 为 User-Agent 的值经过md5 加密的 密文
sign 为(“fanyideskweb” + e + salt + “Nw(nmmbP%A-r6U3EUn]Aj”)经过 md5 加密的 密文
看到这里,转而看一下源码。对着上面的注释,仔细看看,相信你一定会有所收获的。
其实这篇完全就是用来找感觉的,真正的 JS 难度系数成几何倍增长,所以...
什么是虚拟环境?
由百度百科>)得知: 以专利的实时动态程序行为修饰与模拟算法,直接利用本机的 OS,模拟出自带与本机相容 OS 的虚拟机(Vista 下可模拟 Vista、XP,Windows 7 下则可模拟 Windows 7、Vista、XP),也称为“虚拟环境”
功能: 每一个环境都相当于一个新的 Python 环境。你可以在这个新的环境里安装库,运行代码等
为什么需要使用虚拟环境?
众所周知 Python 的强大在于其兼容性,其强大的社区等。同时缺也由些许库并不兼容
真实环境与虚拟环境二者相对关联,并非绝对关联,可以在环境里面随便造。
什么时候需要使用虚拟环境?
需要探究不同版本的 Django 等相互之间的异同
各模块产生冲突时1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
 
- 命令行解析:首先创建了一个名为 Virtual environment 的文件夹并且进入(至于为何创建,是因为便于多虚拟环境包管理,这个也是一个 **virtualenv** 的一个缺陷。自己思考后想到较为妥善的解决方法,稍后会阐述明白)
- 1、 使用 Virtualenv Test 命令创建了一个名为 Test 的虚拟环境包
- 2、 进入 Test 虚拟文件夹中的 Scripts
- 3、此时已经进入且使用虚拟环境,后又运行了 deactivate.bat 命令退出了虚拟环境
- 4、 此时为系统环境(或者说没有使用任何虚拟环境)区分是否为虚拟环境以路径开头是否有“(Virtual environment name)”
- 删除虚拟环境包
- 直接删除所对应的文件夹即可
- 注意点:
- 需进入 Scripts 目录才可运行
- 需添加名为. bat 后缀才可运行
- 阐述一下 Virtualenv 缺陷(不是这个库,而是这个方法!!!),
- Virtualenv 这个方法是直接在当前目录下创建一个虚拟环境,如果没有单独建立类似于名为 Virtual environment 的文件夹难于管理虚拟环境包,一个两个还好,如果多了的话是十分头疼的。个人建议,如果使用此方法,
- Virtualenv 这个方法需要进入虚拟环境包中的 Scripts 文件夹才可运行相关的命令,如进入及退出虚拟环境的命令。(当然也可用创建环境变量的方法来解决此缺陷,但如果是单文件还好,那如果是多个虚拟环境包,反倒给自己填麻烦)
## 二、 搭建 Python virtualenvwrapper-win
### 引言:
经过上述的缺陷分析似乎并没有那么方便,就算创建了相关文件夹来放虚拟环境包,但似乎管理起来,却并没有那么简单。(一两个的还好,但是到了三四个,上十个,百个绝对是一件伤脑筋的事情),那么是否有方法能有弥补相关的缺陷呢?答案肯定是有的。Ta 就是 **virtualenvwrapper-win**
---
## virtualenvwrapper-win:
- 介绍: Virtaulenvwrapper 是基于 virtualenv 的扩展包
- 功能: 更方便管理虚拟环境
- 实现: 它可以将所有虚拟环境整合在一个目录下 ,统一管理(新增,删除,修改,复制,检查),也能够快速在各个虚拟环境间自由切换。
###### 提前准备:
- 请确保 Python 已安装至使用的电脑中(最好已经配置好了环境变量)
- 请确保 pip 命令能够正常使用,且能正常安装库
###### 安装:
pip install virtualenvwrapper-win
为了便于使用个人建议,配置系统环境变量,配置如下: 找到我的电脑(此电脑),右击属性,点击高级系统设置,后点击环境变量在系统环境变量中添加以下信息,后确认退出 
virtualenvwrapper-win 常用命令如下:
创建虚拟环境: mkvirtualenv (Virtual environment name)
进入虚拟环境:workon (Virtual environment name)
退出当前虚拟环境: deactivate
删除虚拟环境:rmvirtualenv (Virtual environment name)
演示如下(此时的 Virtual environment name = Test)箭头代表输入的步骤:
使用 mkvirtualenv Test 命令创建一个名为 Test 的虚拟环境包(并且创建完成后自动进入此虚拟环境)
使用 deactivate 命令退出当前虚拟环境
使用 workon 命令列出虚拟环境表
使用 workon Test 命令 进入名为 Test 的虚拟环境列表
使用 rmvirtualenv Test 命令删除了名为 Test 的虚拟环境列表
再次使用使用 workon Test 命令 进入名为 Test 的虚拟环境列表
Mac \Linux 同理,就不再这里一一赘述了
写在最后:
本人 Payen 为本文原著,转载请注明出处,谢谢 ——Payne
定时测试和监控服务器每个接口是否是可用的,包括返回的数据、状态码是不是正确的。
我可以随时查看到每个接口的响应时间、可用率等信息,最好是有可视化的图表呈现,一目了然。
如果接口的错误率超过某一阈值一段时间,及时通知我,包括电话、短信或邮件。
需要主动去监测接口的可用性,注意这里是主动监测而不是被动监测,不是等用户用的时候报错才提醒我。比如在没有用户用的时候,我也能及时知道每个接口的可用性。
其实,国内的一些服务商已经提供了这些功能,即主动型服务监控,比如「监控宝」,但我并不想用这些服务,一是需要额外花钱,二是数据上并不安全,三是我需要把我的服务集成到公司内部的监控体系下。
首先关于第四个需求比较特殊,现有的监控体系其实已经可以做到服务的被动监测,比如某个 Service 的 API 被调用了,那么相应的调用数据都会被汇总到 Prometheus 上面,Prometheus 里面会计算接口调用的可用率,如果一段时间内如果错误率超过一定阈值,那就报警,追错误的时候去查下 log 就好了。但其实这个不能做到主动监测,比如在凌晨三四点,当没有用户使用的时候,如果这时候服务器出现问题了,我也需要第一时间能知道,所以我需要有一个定时的主动监测程序来实时监测我的所有接口是否是可用的。要做到主动监控,那我一定需要一个接口监测程序定时运行并校验每个接口的结果,这里我选用的就是开源的 JMeter,它大多数情况下是被用来做压测的,但绝对能满足接口调用和检测的需求,只要我定时跑 JMeter 来检测就好了。
关于第一个需求,我需要监测我的每个接口都是可用的,包括返回的数据也需要是想要的结果。这时候我们可能想到直接跑一些 test case 之类的,但这些其实大多数都是在部署或运行时校验的,如果我要实时跑或者 test case 有 update 了,也不太方便。另外为了写接口测试的时候,如果没有现成的工具,我们可能得写一堆代码,每个接口都写一个,包括 GET 请求的 URL 参数、POST 请求的 Body 信息等等,然后校验接口的返回结果是不是对的,也太麻烦了。所以我们需要找到一个可用的工具来帮助我们快速地完成这些功能。所以,我选择的 JMeter 也提供了可视化界面,我只需要配置一些接口和参数即可,另外它还带有定时器、断言、动态参数、多线程等功能,这样我们也可以做到并发测试、随机等待、动态构造请求参数、返回结果判断等功能了。
其次再说第二个和第三个需求,其实用现有的 Prometheus + Grafana 就能解决了,这里最关键的则是我的接口监控结果能发给 Prometheus 才行。既然我选用了 JMeter,那么我怎样把 JMeter 的数据发送给 Prometheus 呢?这里需要借助于 JMeter 的一个插件 jmeter-prometheus-plugin,https://github.com/johrstrom/jmeter-prometheus-plugin,利用它就能将 JMeter 变成一个 Data Exporter,Prometheus 来抓取就好了。
所以,综上所述,我利用的一套服务监控体系就是 JMeter + Kubernetes + Prometheus + Grafana + Alert Manager,那么就开干吧。 这里先放一张图,看下最终的监控 Grafana 面板吧:  这里一些接口的名称和 URL 我就打码了,这里我可以在 Grafana 中每时每刻都看到每个接口的可用率、响应(包括平均、最快、最慢)时间、状态码等信息,这些信息就是 JMeter 定时检测得到的结果,监控数据转到 Prometheus 里面然后经过 Grafana 可视化出来,并能通过一些指标来实现报警机制。 感兴趣的话,可以继续往下看哈。 为了达成这些功能,我需要解决如下问题:
这里一些接口的名称和 URL 我就打码了,这里我可以在 Grafana 中每时每刻都看到每个接口的可用率、响应(包括平均、最快、最慢)时间、状态码等信息,这些信息就是 JMeter 定时检测得到的结果,监控数据转到 Prometheus 里面然后经过 Grafana 可视化出来,并能通过一些指标来实现报警机制。 感兴趣的话,可以继续往下看哈。 为了达成这些功能,我需要解决如下问题:
如何使用 JMeter 来测试每个接口的使用情况。
JMeter 如何和 Prometheus 对接起来,即如何集成 jmeter-prometheus-plugin 到 JMeter。
JMeter 怎样去部署,部署到哪里。
可视化数据怎样来呈现。
错误状态怎样来快速查看。
出错通知如何实现,比如打电话、发邮件等等。
下面我们就来一个个总结说一下。
由于内容比较多,整个流程我实践下来然后测试通总共花了两天左右的时间,在这里就不完全展开说了,只提关键点了。
JMeter 测试
动态参数,JMeter 里面是支持动态参数设置的,比如循环测试 id 从 1 到 100,或者动态 POST 的数据替换,都是可以做到的,这个可以满足你花样测试接口的需求。
定时器,JMeter 里面有很多 Timer,可以设置各种各样的延时操作,比如每 3 分钟测一次,随机等待多少秒测一次都行。
断言,测试了接口之后,我们不仅要知道是否是可用的,同时也要判断其结果是不是正确的,如果返回状态码是正确的但是结果不对,那也白搭,所以可以使用断言来检查返回结果。
关于 JMeter 的功能这里就不再展开讲了,反正几乎你想实现的任何测试功能都可以实现,具体的用法可以参考 JMeter 的官方文档:https://jmeter.apache.org/usermanual/get-started.html。 嗯,写好了之后,可以用 JMeter 在本地进行测试,测试好了时候,可以把 JMeter 的这个 Test Plan 存成一个 jmx 文件,留作后面备用。
对接 Prometheus
接下来就是如何把数据对接到 Prometheus 里面了。 默认情况下,JMeter 是能导出数据到诸如 InfluxDB 这样的数据库的,借助于它自带的 Listener 即可实现。它并不带导出到 Prometheus 的功能。 这里我们就需要借助于 jmeter-prometheus-plugin 这个插件了,其 GitHub 地址是 https://github.com/johrstrom/jmeter-prometheus-plugin,具体的用法可以参考其官方说明。 这里提示几点:
jmeter-prometheus-plugin 安装的时候把 jar 文件放到 JMeter 目录下就好了,jar 文件可以直接看这里下载:https://github.com/johrstrom/jmeter-prometheus-plugin#programatically。
安装好这个插件之后,需要增加一个 Listener,然后配置各种导出字段和参数,可以参考这个 jmx 文件的配置:https://github.com/johrstrom/jmeter-prometheus-plugin/blob/master/docs/examples/simple_prometheus_example.jmx,可以把这个 jmx 打开,然后把 Listener 拷贝到你的 Test Plan 即可。
jmeter-prometheus-plugin 这个插件会把 JMeter 变成一个 Data Exporter,而不是通过 Prometheus Push Gateway 来主动推送监控信息,所以它会在本地启动一个端口,默认是 9270。
Listener 的配置示例如图所示:  这里字段名如 jsr223_rt_as_summary 可以自行修改,比如这里我就统一修改为了 jmeter_test_xxx 这样的字段。 配置完成之后,运行 JMeter 之后,我们就能在 http://localhost:9270 上看到 Exporter 的信息,如图所示:
这里字段名如 jsr223_rt_as_summary 可以自行修改,比如这里我就统一修改为了 jmeter_test_xxx 这样的字段。 配置完成之后,运行 JMeter 之后,我们就能在 http://localhost:9270 上看到 Exporter 的信息,如图所示:  这里面就包含了 JMeter 的一些接口测试结果,包括成功次数、失败次数、状态码等等,另外还有 JVM、处理器等各种环境信息。 部署之后把对应的 URL 交由 Prometheus 就可以把监控数据收集到 Prometheus 里面了。
这里面就包含了 JMeter 的一些接口测试结果,包括成功次数、失败次数、状态码等等,另外还有 JVM、处理器等各种环境信息。 部署之后把对应的 URL 交由 Prometheus 就可以把监控数据收集到 Prometheus 里面了。
部署 JMeter
完成上述两步,我们就能成功测试 Service 的每个接口并能生成测试结果的 Exporter 了。 那么 JMeter 写好了,怎么来部署呢?可以用 crontab,放某台服务器上,不过这里最理想的方式当然是部署到 Kubernetes 里面了。 这里就需要把 JMeter 打包成一个镜像了,GitHub 找来找去没找到几个合适的,另外也没有把 jmeter-prometheus-plugin 包括进去,那只有自己来了。 我基于 https://github.com/justb4/docker-jmeter 进行了二次改写,最后打包了一个镜像,已经开源了,地址为:https://github.com/Germey/JMeterMonitor,镜像名称为 germey/jmeter,这里就不再展开讲细节了,有点复杂。 运行所需要的 docker-compose 文件如下:
这里我把本地的 jmx 文件夹 mount 到了 Docker 的 app 文件夹,所以这里在运行时需要在项目文件夹下新建 jmx 文件夹,用于存放 jmx 文件,把刚才写好的 jmx 文件放过来就好了。 另外 command 就是 jmx 文件的名称,这里需要修改成你的 jmx 文件。 另外部署到 Kubernetes 的话可以参考这里的 yml 文件:https://github.com/Germey/JMeterMonitor/tree/master/kubernetes。
Prometheus 收集数据
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'jmeter-monitor'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['jmeter-monitor.com']
其具体的配置字段可以参见:https://prometheus.io/docs/prometheus/latest/configuration/configuration/。 另外呢,这种方式其实并不怎么好,修改 Prometheus 挺麻烦的,推荐使用 Helm + Prometheus-Operator 来安装 Prometheus,然后修改 values.yml 即可修改配置文件了,比如修改 https://github.com/helm/charts/blob/master/stable/prometheus-operator/values.yaml 里面的 additionalScrapeConfigs 即可。
Grafana 可视化
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: monitor
name: monitor-rules
spec:
groups:
- name: monitor
rules:
- alert: ServiceErroring
labels:
severity: warning
annotations:
message: Service 连续5分钟错误率过高。
expr: |
avg(1- jmeter_test_can_fail_success{job="service-monitor"} / jmeter_test_can_fail_total{job="service-monitor"}) > 0
for: 5m
这样配置好一个 PrometheusRule 之后,Prometheus 会自动应用这个 Rule 然后监控。 报警方式的话可以通过配置 Alert Manger 的 Receiver 来实现,包括打电话、邮件、短信等等,配置规则可以见:https://prometheus.io/docs/alerting/configuration/。 目前我是利用了组内已经提供的报警机制,组内已经对接好了电话、短信、邮件报警,并可以把每个人的信息进行管理和分组,然后应用到某个报警规则里面,这样一旦有问题,就可以实现报警啦。 另外对于一些规则的管理,我们可以使用一些开源的 Dashboard 来管理,如 Krama,https://github.com/prymitive/karma,利用它我们可以方便配置、禁用和筛选一些报警规则,界面如下:  不过公司内部已经实现了一套了,对接了公司的员工账号,更加方便,所以我就没有再用这个了。
不过公司内部已经实现了一套了,对接了公司的员工账号,更加方便,所以我就没有再用这个了。
这里另外遇到了一个问题,就是 JMeter 导出的监控数据是不断累积的,而监控的数据则是需要监控最近几分钟的数据,这样一旦发生了 Error,那么 Error Rate 由于历史数据的原因,在服务恢复之后永远不会降为 0,这就导致一些问题。另外如果 JMeter 如果一直运行,其占用的内存会越来越大。 所以一个最好的方式就是定时将 JMeter 重启,这样可以定时清空历史监控数据,保证在新的一段时间内测试获取到最近的监控数据,而不是混杂历史数据。 这里重启就可以利用 Kubernetes 的 Cronjob,比如我们可以每隔 10 分钟让 JMeter 重启一次,类似配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: jmeter-monitor
spec:
successfulJobsHistoryLimit: 0
failedJobsHistoryLimit: 0
concurrencyPolicy: Replace
schedule: "*/10 * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
service: jmeter-monitor
spec:
containers:
- args:
- jmeter-monitor.jmx
image: germey/jmeter:1
name: jmeter-monitor
volumeMounts:
- mountPath: /app
name: jmeter-storage
ports:
- containerPort: 80
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "4Gi"
cpu: "250m"
limits:
memory: "4Gi"
cpu: "250m"
restartPolicy: OnFailure
volumes:
- name: jmeter-storage
persistentVolumeClaim:
claimName: jmeter
这里有几个地方值得注意:
一个是 concurrencyPolicy,这里配置为 Replace,意思是重启后新建的 Pod 会替换原来的 Pod,保证 JMeter 的 Pod 只有一个。
另外一个是 imagePullPolicy 配置为 IfNotPresent,这样可以每次重启的时候不用重新拉镜像。
这样的话,就能避免发生错误的时候 Error Rate 无法降为 0 的状态了。 好了,到此为止呢,我们就介绍完了使用 JMeter + Kubernetes + Prometheus + Grafana + Alert Manager 进行监控的整体思路了,希望对大家有帮助。 另外由于内容比较多,这里很多地方没有展开讲解,比如 JMeter 的配置、Grafana 的配置、Prometheus-Operator 的配置、Alert Manager 的配置等等,不知道大家敢不敢兴趣,如果感兴趣的话,后面可以继续深入写一个小系列来讲解哈。
刚刚又完成了一项任务。 而这个任务明天就要检查上交了,在这之前,我其实有很多很多的时间去做这件事,而我还是把这个拖到了最后。 怎么说呢?这个就是拖延症,不到最后一刻不去做,总要拖到 Deadline 才去搞。哎,其实吧反思我自己,一直就有这个毛病,不知道大家是不是也有这个毛病,或许大家都有的吧。不然怎么来的 Deadline 是第一生产力的说法呢。 这个毛病体现在太多方面了,比如拿我自己说吧:
快到交稿的时候才去再赶点。
快到明天检查项目的时候才去做点。
快到考前再去复习。
其实也不能说拖延症不好吧,比如拿第三项「快到考前再去复习」,我确实到最后的时候效率会比平时高非常多。我大学和研究生几乎都是翘课翘过来的,除了那些重要的或者老师点名的课会去去,其他的一律翘掉,最后考前突击两星期,然后考个八九十分。悄悄炫耀下吧,当时突击得大学平均绩点最后突击了年级前 5%,最后还保研了,这其实让我有点难以相信的。不过研究生成绩就不行了,因为已经铁了心毕业就工作,所以精力都放在了自己的项目和公司工作上面,所以成绩就没上心了,中游水平吧。 再说回大学吧,由于我平时对考前复习的 “拖延”,我可以平时把精力放在自己更感兴趣的事情上面。比如大学的时候吧,我加了一个实验室,基本上翘课的时间都是泡在实验室里面,我也忘记是在做什么了,也有在摸鱼,反正就是不想上课,当然也有挺多时候在撸代码,学一些技术什么的。所以相比一些「学霸」,我平时还 GET 到了一些编程技能,最后可能绩点还比他们高,而他们可能所有精力都放在功课上了,这可能他们想起来就有点气了哈哈。但其实吧,我虽然当时有点得意,以为自己占到了便宜,但其实当时对某些基础的理解确实不如平时认真学习的同学理解得透彻,比如当时计算机网络、计算机组成原理,当时就是考试突击,考试得了高分,但其实当时对里面的知识理解并不到位,到了真正用的时候,拾起来就没那么容易了。但当然也分科目,比如我到现在工作真的也没有用到计算机组成原理、电子电路的任何一点知识,以后也可能不会用到。所以,如果正在读本文的你,现在如果还在读大学的话,想清楚哪些科目将来对你可能是有用的,好好去学,好好去听讲,不要学我翘这么多课,没准你将来真的可能会用到,到时候就不要后悔自己当时为什么没好好学。 扯远了,这里只是想论证下有些情况拖延症并不一定完全是坏处,也算是给拖延症找了个美丽但似乎不太恰当的借口吧。 不过话说回来,拖延症在多数情况下是不好的,例子就不举了,大家肯定也深有体会。 我曾经也看过关于拖延症的一些科普或 “诊疗” 方案,怎么说呢?每人都会有惰性,每人都喜欢待在自己的 “舒适区”,毕竟躺在被窝里面玩手机多么舒服啊。 还看到一个关于拖延症的解释是说不够热爱,如果你非常热爱你做的事情,你是不会拖延的。我想了想,好像不是这样,比如我热爱 Python、喜欢编程、喜欢去实现某些东西,我想起来为什么有的时候还是不想去做呢?也不是不喜欢不热爱,那就是懒,可能喜欢呆在舒适区就是更合理的解释,因为我也喜欢睡懒觉和躺着玩手机。 所以,有什么方法能缓解我的拖延症呢? 我之前试过一个方法,还是挺有用的。这里分享给大家吧。 比如我现在要写一个过了很久都不维护的项目吧,一想起来要打开它、配置环境、跑起来就各种事,懒得去做。这时候,我通常采取的方法就是强忍着,啥也不管,我就去迎着头皮去做,比如去把项目代码 clone 下来,然后 IDE 打开,然后试着跑起来,出错了稍微调一调,或者试着改几句代码。过这么十几分钟折腾,这时候发现再写,那就能比较顺利地写下去了。 比如我现在要写一篇文章,一想起来我要打开文本编辑器、构思、梳理知识点就又懒得去做。这时候我采取的方案就是强制我自己打开文本编辑器,比如现在写的这篇文章就是这样,我本来并不想写,但是脑子里面又想到了一些事情,还是写写比较好,那我就硬着头皮打开吧,本想写个一两百字就行了,结果你看我现在写到这里了,咦你看我又写了十个字呢,你看我又写了十个字呢,是不是有点文思泉涌啊哈哈哈哈哈。诺,你看到现在,从我写这篇稿子到现在,也就过了不到十分钟吧,我这篇稿子就快收尾了,舒服啊。 俗话说,万事开头难,做事情就是这样,如果大家也遇到了这个问题,不妨也可以试试这个方法,感觉还挺有效的。 但并不是 100% 有效哈,有时候我就是懒到一天啥也不想干也不是没有。 最后再说一个点,那就是其实,你看这件事,你在做之前,你可能觉得这件事好麻烦,不想干,或者好难,我干不了。但在可能大多数情况下,一旦你开始干了,你会发现并没有那么难那么麻烦。 其实,难的就是开始。 好了,我的稿子写完了,你看我在写之前觉得麻烦的一件事,这不就完结了吗。 嗯,就是大晚上随便写写,突然想起来,我似乎今天还有几件觉得比较麻烦的事还没干呢,我去开头去啦,拜拜。
在前面写过一篇文章介绍深度学习识别滑动验证码缺口的文章,在这篇文章里,我们使用华为云 ModelArts 轻松完成了滑动验证码缺口的识别。但是那种实现方案依赖于 ModelArts,是华为云提供的深度学习平台所搭建的识别模型,其实其内部是用的深度学习的某种目标检测算法实现的,如果利用平台的话,我们无需去申请 GPU、无需去了解其内部的基本原理究竟是怎么回事,它提供了一系列标注、训练、部署的流程。 但用上述方法是有一定的弊端的,比如使用会一直收费,另外不好调优、不好更好地定制自己的一些需求等等。所以这里再发一篇文章来介绍一下直接使用 Python 的深度学习模型来实现滑动验证码缺口识别的方法。
目前可以做到只需要几百张缺口标注图片即可训练出精度高的识别模型,并且可扩展修改为其他任何样式的缺口识别,识别效果样例:  只需要给模型输入一张带缺口的验证码图片,模型就能输出缺口的轮廓和边界信息。 感兴趣的可以继续向下看具体的实现流程。
只需要给模型输入一张带缺口的验证码图片,模型就能输出缺口的轮廓和边界信息。 感兴趣的可以继续向下看具体的实现流程。
缺口识别属于目标检测问题,关于什么是目标检测这里就不再赘述了,可以参考之前写的这篇文章。 当前做目标检测的算法主要有两种路子,有一阶段式和两阶段式,英文叫做 One stage 和 Two stage,简述如下:
Two Stage:算法首先生成一系列目标所在位置的候选框,然后再对这些框选出来的结果进行样本分类,即先找出来在哪,然后再分出来是啥,俗话说叫「看两眼」,这种算法有 R-CNN、Fast R-CNN、Faster R-CNN 等,这些算法架构相对复杂,但准确率上有优势。
One Stage:不需要产生候选框,直接将目标定位和分类的问题转化为回归问题,俗话说叫「看一眼」,这种算法有 YOLO、SSD,这些算法虽然准确率上不及 Two stage,但架构相对简单,检测速度更快。
所以这次我们选用 One Stage 的有代表性的目标检测算法 YOLO 来实现滑动验证码缺口的识别。 YOLO,英文全称叫做 You Only Look Once,取了它们的首字母就构成了算法名, 目前 YOLO 算法最新的版本是 V3 版本,这里算法的具体流程我们就不过多介绍了,感兴趣的可以搜一下相关资料了解下,另外也可以了解下 YOLO V1-V3 版本的不同和改进之处,这里列几个参考链接。
YOLO V3 论文:https://pjreddie.com/media/files/papers/YOLOv3.pdf
YOLO V3 介绍:https://zhuanlan.zhihu.com/p/34997279
YOLO V1-V3 对比介绍:https://www.cnblogs.com/makefile/p/yolov3.html
回归我们本节的主题,我们要做的是缺口的位置识别,那么第一步应该做什么呢? 我们的目标是要训练深度学习模型,训练模型,那我们总得需要让模型知道要学点什么东西吧,这次我们做缺口识别,那么我们需要让模型学的就是这个缺口在哪里。由于一张验证码图片只有一个缺口,要分类就是一类,所以我们只需要找到缺口位置就行了。 好,那模型要学缺口在哪里,那我们就得提供点样本数据让模型来学习才行。数据怎样的呢?那数据就得有带缺口的验证码图片以及我们自己标注的缺口位置。只有把这两部分都告诉模型,模型才能去学习。等模型学好了,等我们再给个新的验证码,那就能检测出缺口在哪里了,这就是一个成功的模型。 OK,那我们就开始准备数据和缺口标注结果吧。 数据这里用的是网易盾的验证码,验证码图片可以自行收集,写个脚本批量保存下来就行。标注的工具可以使用 LabelImg,GitHub 链接为:https://github.com/tzutalin/labelImg,利用它我们可以方便地进行检测目标位置的标注和类别的标注,如这里验证码和标注示例如下:  标注完了会生成一系列 xml 文件,你需要解析 xml 文件把位置的坐标和类别等处理一下,转成训练模型需要的数据。 在这里我先把我整理的数据集放出来吧,完整 GitHub 链接为:https://github.com/Python3WebSpider/DeepLearningSlideCaptcha,我标注了 200 多张图片,然后处理了 xml 文件,变成训练 YOLO 模型需要的数据格式,验证码图片和标注结果见 data/captcha 文件夹。 如果要训练自己的数据,数据格式准备见:https://github.com/eriklindernoren/PyTorch-YOLOv3#train-on-custom-dataset。
标注完了会生成一系列 xml 文件,你需要解析 xml 文件把位置的坐标和类别等处理一下,转成训练模型需要的数据。 在这里我先把我整理的数据集放出来吧,完整 GitHub 链接为:https://github.com/Python3WebSpider/DeepLearningSlideCaptcha,我标注了 200 多张图片,然后处理了 xml 文件,变成训练 YOLO 模型需要的数据格式,验证码图片和标注结果见 data/captcha 文件夹。 如果要训练自己的数据,数据格式准备见:https://github.com/eriklindernoren/PyTorch-YOLOv3#train-on-custom-dataset。
上一步我已经把标注好的数据处理好了,可以直接拿来训练了。 由于 YOLO 模型相对比较复杂,所以这个项目我就直接基于开源的 PyTorch-YOLOV3 项目来修改了,模型使用的深度学习框架为 PyTorch,具体的 YOLO V3 模型的实现这里不再阐述了。 另外推荐使用 GPU 训练,不然拿 CPU 直接训练速度很慢。我的 GPU 是 P100,几乎十几秒就训练完一轮。 下面就直接把代码克隆下来吧。 由于本项目我把训练好的模型也放上去了,使用了 Git LFS,所以克隆时间较长,克隆命令如下:
执行这个脚本,就能下载 YOLO V3 模型的一些权重文件,包括 yolov3 和 weights 还有 darknet 的 weights,在训练之前我们需要用这些权重文件初始化 YOLO V3 模型。
注意:Windows 下建议使用 Git Bash 来运行上述命令。
另外还需要安装一些必须的库,如 PyTorch、TensorBoard 等,建议使用 Python 虚拟环境,运行命令如下:
\---- [Epoch 99/100, Batch 27/29] ----
+------------+--------------+--------------+--------------+
| Metrics | YOLO Layer 0 | YOLO Layer 1 | YOLO Layer 2 |
+------------+--------------+--------------+--------------+
| grid_size | 14 | 28 | 56 |
| loss | 0.028268 | 0.046053 | 0.043745 |
| x | 0.002108 | 0.005267 | 0.008111 |
| y | 0.004561 | 0.002016 | 0.009047 |
| w | 0.001284 | 0.004618 | 0.000207 |
| h | 0.000594 | 0.000528 | 0.000946 |
| conf | 0.019700 | 0.033624 | 0.025432 |
| cls | 0.000022 | 0.000001 | 0.000002 |
| cls_acc | 100.00% | 100.00% | 100.00% |
| recall50 | 1.000000 | 1.000000 | 1.000000 |
| recall75 | 1.000000 | 1.000000 | 1.000000 |
| precision | 1.000000 | 0.800000 | 0.666667 |
| conf_obj | 0.994271 | 0.999249 | 0.997762 |
| conf_noobj | 0.000126 | 0.000158 | 0.000140 |
+------------+--------------+--------------+--------------+
Total loss 0.11806630343198776
这里显示了训练过程中各个指标的变化情况,如 loss、recall、precision、confidence 等,分别代表训练过程的损失(越小越好)、召回率(能识别出的结果占应该识别出结果的比例,越高越好)、精确率(识别出的结果中正确的比率,越高越好)、置信度(模型有把握识别对的概率,越高越好),可以作为参考。
训练完毕之后会在 checkpoints 文件夹生成 pth 文件,可直接使用模型来预测生成标注结果。 如果你没有训练自己的模型的话,这里我已经把训练好的模型放上去了,可以直接使用我训练好的模型来测试。如之前跳过了 Git LFS 文件下载,则可以使用如下命令下载 Git LFS 文件:
Performing object detection:
+ Batch 0, Inference Time: 0:00:00.044223
+ Batch 1, Inference Time: 0:00:00.028566
+ Batch 2, Inference Time: 0:00:00.029764
+ Batch 3, Inference Time: 0:00:00.032430
+ Batch 4, Inference Time: 0:00:00.033373
+ Batch 5, Inference Time: 0:00:00.027861
+ Batch 6, Inference Time: 0:00:00.031444
+ Batch 7, Inference Time: 0:00:00.032110
+ Batch 8, Inference Time: 0:00:00.029131
Saving images:
(0) Image: 'data/captcha/test/captcha_4497.png'
+ Label: target, Conf: 0.99999
(1) Image: 'data/captcha/test/captcha_4498.png'
+ Label: target, Conf: 0.99999
(2) Image: 'data/captcha/test/captcha_4499.png'
+ Label: target, Conf: 0.99997
(3) Image: 'data/captcha/test/captcha_4500.png'
+ Label: target, Conf: 0.99999
(4) Image: 'data/captcha/test/captcha_4501.png'
+ Label: target, Conf: 0.99997
(5) Image: 'data/captcha/test/captcha_4502.png'
+ Label: target, Conf: 0.99999
(6) Image: 'data/captcha/test/captcha_4503.png'
+ Label: target, Conf: 0.99997
(7) Image: 'data/captcha/test/captcha_4504.png'
+ Label: target, Conf: 0.99998
(8) Image: 'data/captcha/test/captcha_4505.png'
+ Label: target, Conf: 0.99998
拿几个样例结果看下: 

 这里我们可以看到,利用训练好的模型我们就成功识别出缺口的位置了,另外程序还会打印输出这个边框的中心点和宽高信息。 有了这个边界信息,我们再利用某些手段拖动滑块即可通过验证了。本节不再展开讲解。
这里我们可以看到,利用训练好的模型我们就成功识别出缺口的位置了,另外程序还会打印输出这个边框的中心点和宽高信息。 有了这个边界信息,我们再利用某些手段拖动滑块即可通过验证了。本节不再展开讲解。
本篇文章我们介绍了使用深度学习识别滑动验证码缺口的方法,包括标注、训练、测试等环节都进行了阐述。 GitHub 代码:https://github.com/Python3WebSpider/DeepLearningSlideCaptcha。 欢迎 Star、Folk,如果遇到问题,可以在 GitHub Issue 留言。
声明:本文由一位知名的不知名 Payne 原创,转载请注明出处! 首先说一下这个有啥用?要说有用也没啥用,要说没用吧,既然能拿到这些数据,拿来做数据分析。能有效的得到职位信息,薪资信息等。也能为找工作更加简单吧,且能够比较有选择性的相匹配的职位及公司 本章节源码仓库为:https://github.com/Payne-Wu/PythonScrape 一言不合直接上代码!具体教程及思路总代码后! 所用解释器为 Python3.7.1,编辑器为 Pycharm 2018.3.5. 本着虚心求学,孜孜不倦,逼逼赖赖来这里虚心求学,孜孜不倦,逼逼赖赖,不喜勿喷,嘴下手下脚下都请留情。 本节所涉:Request 基本使用、Request 高级使用-会话维持、Cookies、Ajax、JSON 数据格式 Request 更多详情请参考 Request 官方文档: 轻松入门中文版 高级使用中文版 Cookie:有时也用其复数形式 Cookies。类型为“小型文本文件”,是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息 具体 Cookies 详情请参考:https://baike.baidu.com/item/cookie/1119?fr=aladdin
Ajax 即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指一种创建交互式、快速动态网页应用的网页开发技术,无需重新加载整个网页的情况下,能够更新部分网页的技术。
通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
JSON(JavaScript Object Notation): 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。 它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集。 JSON 采用完全独立于语言的文本格式,但是也使用了类似于 C 语言家族的习惯(包括 C, C++, C#, Java, JavaScript, Perl, Python 等)。 这些特性使 JSON 成为理想的数据交换语言。
首先介绍一下关于本章代码的基本思路: 四步走(发起请求、得到响应、解析响应得到数据、保存数据) 四步中准确来说是三步,(发起请求,得到响应、解析响应,提取数据、保存数据)
请求网页(在搜索框中输入所查询的岗位<例如:Python>,得到BASE_URL,)
BASE_URL:https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=
加入请求头(注意加 Cookies),请求 BASE_URL[gallery columns=”1” size=”full” ids=”9164”]
观察响应信息以及本网页源码观察浏览器网页源码,对比发现其中并没有我们所需要的信息:发现 Ajax 的痕迹。
经过一系列操作发现Ajax 网页地址(在这里直接请求此链接并不能访问):
多次请求过后,发现错误。错误的缘由是由于 Cookies 限制,并且网页以动态检测,且时间间隔小。
经过前言的学习,已经学会了。会话维持。动态得到 Cookies,这样不就可以把这个“反爬”彻底绕过了呢?答案肯定是滴
哪让我们做一下会话维持,并动态提取 Cookies 吧。
易混淆点:cookies 的维持为什么是维持 BASE_URL 的而不是 Ajax_URL?下面按照个人理解对于本 Ajax 给出以下解释:结合 Ajax 原理可知,Ajax 其基本原理就是在网页中插入异步触发的。说到底他还是在这个页面,并没有转到其他页面。只是需要特定条件触发即可插入本网页
```
def Get_cookies(header):
Get cookies
@param header:
@return: cookies
with requests.Session() as s:
s.get(cookies_url, headers=header)
cookies = s.cookies
# cookies = requests.get(cookies_url, headers=header).cookies
return cookies
- 万事俱备、只欠东风:请求 Ajax_URL 即可得到以下
- 得到响应:经过以上操作已经请求完成了。并能够保障请求稳定性。(当然在此并没有做异常捕获,如果加上,将会更稳)
- ## 解析响应:如果上述步骤没有错的话,到此已经能得到网页数据了(如上图):
- - 我用的提取代码如下 :
def parse(message): industryField = message['industryField'] # company_message positionName = message['positionName'] companyFullName = message['companyFullName'] companySize = message['companySize'] financeStage = message['financeStage'] # companyLabelList = message['companyLabelList'] companyLabelList = '|'.join(message['companyLabelList']) Type = "|".join([message['firstType'], message['secondType'], message['thirdType']]) Address = ''.join([message['city'], message['district'], ]) salary = message['salary'] positionAdvantage = message['positionAdvantage'] # limitation factor workYear = message['workYear'] jobNature = message['jobNature'] education = message['education'] items = f"{positionName}, {companyFullName}, {companySize}, {financeStage}, {companyLabelList}, {industryField}, " \ f"{Type}, {salary}, {jobNature}, {education}" # items = "".join(str( # [positionName, companyFullName, companySize, financeStage, companyLabelList, industryField, Type, salary, # jobNature, education])) if items: # print(items) logging.info(items) # return items.replace('[', '').replace(']', '') return items.replace('(', '').replace(')', '')
1
2
3
4
5
- 此时只需提取相关数据,即可。得到:
- ## 保存数据:
- ## 常规保存:(保存到本地)
- ## 数据入库:(保存到数据库)
## 在这里我选择的为 Mongo,接下来,那咱们操作一下吧。Mongo 的安装便不在此处赘述。与 mongo 相关的文章,在这里比较推荐才哥和东哥的几篇文章(以本文来看,比较建议看看这几篇文章。并没说其他不好啊,不,我没有,我没说哦),地址如下:
- ### [如何学好 MongoDB](https://cuiqingcai.com/7121.html)
- ### [[Python3 网络爬虫开发实战] 1.4.2-MongoDB 安装](https://cuiqingcai.com/5205.html)
- ### [[Python3 网络爬虫开发实战] 1.5.2-PyMongo 的安装](https://cuiqingcai.com/5230.html)
## 前方高能预警,造!!!:(此时的你已安装了 Mongo,并能正常使用 mongo。剩下的交给我,我教你好了)
1. ### 安装 pymongo
def main(): p = LaGou() for page in range(1, 31): content = p.scrape(page) data = p.parseResponse(content) download = p.save_data(data) ```
注意:由于 mongo 的存储格式为 key :value 形式,所以咱们提取到的数据返回也必须是 key :value 形式:
左手叉腰,右手摇,Over!
光看文章的话,就算是我自己写的文章单单仅仅看文章也是会云里雾里,建议与源码一起阅读。祝学习进步,心想事成。加油~
写到最后:既然能读到这儿,那么我相信不是白嫖成为习惯的人,说明也或多或少想自己搞一搞。整一整?下次也出来吹吹牛皮,拉钩晓得不,反爬难吧?我会了(虽然对于大佬来说,都可能算不上反扒,和玩似的,这个确实也是的。不过吧,对于新手来说,已经算很难了。)我也是搞过拉勾的男人。找工作就找我,啊哈哈哈。
单一的案例终究只会让你局限于本次案例,如果拉钩反爬又更新了。那么这个就会失效。虽然授之以渔了,但终究是“这条小溪”,更大的海洋还需要更加刻苦努力的学习。个人比较建议学习一下
感谢阅读与支持,谢谢
meizi图会爬么?不会那我教你好了
声明:本文由一位知名的不知名Payne原创,转载请注明出处!后优化代码为52讲轻松搞定网络爬虫第一次实战课程为本节代码思路为基础,后自作聪明,书写。 本章节源码仓库为:https://github.com/Payne-Wu/PythonScrape 写在最前面:本章适用于新手小白,代码规范化思路。 一言不合直接上代码!具体教程及思路总代码后! 所用解释器为Python3.7.1,编辑器为Pycharm 2018.3.5. 本着虚心求学,孜孜不倦,逼逼赖赖来这里虚心求学,孜孜不倦,逼逼赖赖,不喜勿喷,嘴下手下脚下都留情。
基础源码(我刚自学Python时候写的代码)
要爬就爬全站的,一两张一两个还不如另存为来的更加实际。啊哈哈哈
那咱们先来说说Meizitu的基本思路:
个人总结(四步法):发送请求, 得到响应, 解析数据, 保存数据(比较宏观的概念)
众所周知啊(其实是个人理解):爬虫本质为模拟浏览器发送请求 ,倒推过来思考 既然是模拟请求,请求地址(URI)总得晓得吧。那么本次请求的URI为以下(单个图册):
- MAIN_URL:https://www.mzitu.com/
- Atlas URL:https://www.mzitu.com/226469
- Specific URL: https://www.mzitu.com/226469/1
模拟请求,既然是模拟请求怎么也得,模拟一下吧?被站长大大晓得了那不就被关在门外了。(站长“菇凉”说:“我家是给帅气的小哥哥用户访问的,你个程序来凑一凑不太好吧?”在我脑壳后面敲了敲,后就把我拒之门外,头也不会,扬长而去)经过我苦思冥想,仿佛得到了前所未有的启发,要不我们走走后门,让这个程序做个人?如此甚好。妙哉,妙哉。。。
- 请求头一带谁都不爱。大叫一声还有谁,于是我就上啊。然而结果确实如此
```
url = ‘https://www.mzitu.com/‘
header =
{
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0”
}
response = requests.get(url, headers=header) # 请求网页
print(response)
reponse<200>
* 经过我请求,他回应,他回应了爱你你(200),最后咱们握手了。菇凉,咱们还不够了解。需要多了解了解。我还没有成为无敌的男ying,我得多学习学习,争取早日娶你过门。(论一个渣男的锻炼与养成)
* 好不容易进来了,本着虚心求教,好好学习,天天向上,不谈儿女私情的我,怎么也得有所收获吧。这是???渣男的修炼养成计划?这是宝贝啊!!!我得看看,学习学习。
* [gallery size="full" columns="1" ids="9144"]
* 这还上锁啦?,这个可不香了。经过研究,一笑 你有你的的张良计,我有我的万能钥匙,Refer钥匙。配置Refer。走着。还不乖乖的。小意思啦。。。。就这样。
* [gallery size="full" columns="1" ids="9145"]
虽然不是用的同一张图片,BUT,有无图片是这Refer防盗链作祟的。 **ok,nice。** 各位看官,到这儿咱们也得进入真正的 说了这么多,让我们进入造的环节把,基础四步走,发起请求,得到响应,解析数据,保存!打完收工。 首先咱们是定义了一个自定义的用户代理,优点稳定、简单易于操作,但缺点是比较繁琐。 为什么不用from fake_useragent import UserAgent 这个主要还是因为这个模块不大稳定,我用的时候经常出错。不晓得是不是我。。。 至少我用的不太爽。而且既然自己阔以造轮子,为何不试着造一造呢? 说说User-Agent构造思路,首先是定义了一个User-Agent列表,然后从里面随机取一,作为相对本次User—Agent。 优化后的代码是直接定义了一个请求函数,这样如果需要请求是阔以直接调用这个函数,避免代码臃肿。无脑写requests。既不提升效率,也不简洁。还看着懵。有好的自然就要给好的,有时候对自己得好点。 注意请不要忽略异常捕获哦,这样会使咱们的爬虫小伙计更加健壮。爬虫的Strong在于考虑细致,全方面。这样成为一只成年的爬虫,虽然我也不晓得谁说的,我感觉还是蛮有道理的,如果真的没有人说,那就是我吧。。。。 这里是直接定义了一个请求方法,方便需要请求的时候直接调用。即可获得请求的效果
def scrape_page(url):
logging.info(‘scraping %s…’, url)
header = User_Agent(page)
做个简单的小结: ```python def main(page): User_Agent(page) index_html = scrape_index(page) detail_urls = parse_index(index_html) # 循环遍历提取出URI for detail_url in detail_urls: 这样就可以得到所有的URI了: ... 2020-04-10 10:07:42,396 - INFO: scraping https://www.mzitu.com/206355... 2020-04-10 10:07:42,703 - INFO: Got detail_url https://www.mzitu.com/212891 2020-04-10 10:07:42,703 - INFO: scraping https://www.mzitu.com/212891... 2020-04-10 10:07:42,863 - INFO: Got detail_url https://www.mzitu.com/225494 2020-04-10 10:07:42,863 - INFO: scraping https://www.mzitu.com/225494... 2020-04-10 10:07:42,992 - INFO: Got detail_url https://www.mzitu.com/226142 2020-04-10 10:07:42,992 - INFO: scraping https://www.mzitu.com/226142... 2020-04-10 10:07:43,172 - INFO: Got detail_url https://www.mzitu.com/226078 2020-04-10 10:07:43,173 - INFO: scraping https://www.mzitu.com/226078... 2020-04-10 10:07:43,661 - INFO: Got detail_url https://www.mzitu.com/210338 2020-04-10 10:07:43,661 - INFO: scraping https://www.mzitu.com/210338... 2020-04-10 10:07:43,838 - INFO: Got detail_url https://www.mzitu.com/225958 2020-04-10 10:07:43,839 - INFO: scraping https://www.mzitu.com/225958... 2020-04-10 10:07:44,003 - INFO: Got detail_url https://www.mzitu.com/225784 2020-04-10 10:07:44,004 - INFO: scraping https://www.mzitu.com/225784... 2020-04-10 10:07:44,163 - INFO: Got detail_url https://www.mzitu.com/218827 2020-04-10 10:07:44,163 - INFO: scraping https://www.mzitu.com/218827... 2020-04-10 10:07:44,402 - INFO: Got detail_url https://www.mzitu.com/213225 ... 然后就没有然后了呗 经过发现每个图集里面是后面加上page就是第几张图片,并且张数是不一样的,那怎么样解决呢? [gallery columns="1" size="full" ids="9146"] [gallery columns="1" size="full" ids="9147"] 多观察几个发现它只显示8个,第七个就是最大的页码数了, 那咱们把他提取出来,作为图集的page,放入循环不就可以拿到任意图集的所有了嘛!经过验证这是可行的。 既然这些又有了,那咱们请求它,存就好啦
if __name
== ‘__main‘:
for page in range(1, 2):
main(page)
import multiprocessing
TOTAL_PAGE 为所爬取页数
这个实现看起来兼容性会更好一些。 因此我们可以确定,通过一个全局的 CSS 样式就能将整个网站变成灰色效果。
那么这里我们就来详细了解一下这究竟是一个什么样的 CSS 样式。 这个样式名叫做 filter,搜下 MDN 的官方介绍,其链接为:https://developer.mozilla.org/zh-CN/docs/Web/CSS/filter。 官方介绍内容如下:
filter CSS 属性将模糊或颜色偏移等图形效果应用于元素。滤镜通常用于调整图像,背景和边框的渲染。 CSS 标准里包含了一些已实现预定义效果的函数。你也可以参考一个 SVG 滤镜,通过一个 URL 链接到 SVG 滤镜元素 (SVG filter element)。
其实就是一个滤镜的意思。 官方有一个 Demo,可以看下效果,如图所示。  比如这里通过 filter 样式改变了图片、颜色、模糊、对比度等等信息。 其所有用法示例如下:
比如这里通过 filter 样式改变了图片、颜色、模糊、对比度等等信息。 其所有用法示例如下:
/* URL to SVG filter */
filter: url("filters.svg#filter-id");
/* <filter-function> values */
filter: blur(5px);
filter: brightness(0.4);
filter: contrast(200%);
filter: drop-shadow(16px 16px 20px blue);
filter: grayscale(50%);
filter: hue-rotate(90deg);
filter: invert(75%);
filter: opacity(25%);
filter: saturate(30%);
filter: sepia(60%);
/* Multiple filters */
filter: contrast(175%) brightness(3%);
/* Global values */
filter: inherit;
filter: initial;
filter: unset;
这样想要变灰的节点只需要加上 gray 这个 class 就好了,比如加到 html 节点上就可以全站变灰了。 最后呢,看一下浏览器对 filter 这个样式的兼容性怎样,如图所示:  这里我们看到,这里除了 IE,其他的 PC、手机端的浏览器都支持了,Firefox 的 PC、安卓端还单独对 SVG 图像加了支持,可以放心使用。
这里我们看到,这里除了 IE,其他的 PC、手机端的浏览器都支持了,Firefox 的 PC、安卓端还单独对 SVG 图像加了支持,可以放心使用。
本篇文章简单介绍了一下今天观察到的网站变灰的实现,也学习了 filter 的更详细的用法,希望有帮助。
这里我们定义了一个 process 方法,接收三个参数,前两个参数是 num1 和 num2,第三个参数是 file。这个方法会首先将 num1 除以 num2,然后把除法的结果写入到 file 文件里面。 好,就这么一个简单的操作,但是这个实现真的是漏洞百出:
没有判断 num1、num2 的类型,如果不是数字类型,那会抛出 TypeError。
没有判断 num2 是不是 0,如果是 0,那么会抛出 ZeroDivisionError。
没有判断文件路径是否存在,如果是子文件夹下的路径,文件夹不存在的话,会抛出 FileNotFoundError。
一些异常测试用例如下:
def process(num1, num2, file):
try:
result = num1 / num2
with open(file, 'w', encoding='utf-8') as f:
f.write(str(result))
except ZeroDivisionError:
print(f'{num2} can not be zero')
except FileNotFoundError:
print(f'file {file} not found')
except Exception as e:
print(f'exception, {e.args}')
代码一下子臃肿了起来,这里的异常处理都没有实现,仅仅是 print 了一些错误信息,但现在可以看到我们的异常处理代码可能比主逻辑还要多。
主逻辑代码整块被硬生生地缩进进去了,如果主逻辑代码比较多的话,那么会有大片大片的缩进。
如果再有相同的逻辑的代码,难道要再写一次 try except 这一坨代码吗?
可能很多人都在面临这样的困扰,觉得代码很难看但又不知道怎么修改。 当然上面的代码写法本身就不好,有几种改善的方案:
本身这个场景不需要这么多异常处理,使用判断条件把一些意外情况处理掉就好。
异常处理本身就不应该这么写,每个功能区域应该和异常处理单独分开,另外各个逻辑模块建议再分方法解耦。
使用 retrying 模块检测异常并进行重试。
使用上下文管理器 raise_api_error 来声明异常处理。
但上面的一些解决方案其实还不能彻底解决代码复用和美观上的问题,比如某一类的异常处理我就统一在一个地方处理,另外我的任何代码都不想因为异常处理产生缩进。 那对于这样的问题,有没有解决方案呢?有。 下面我们来了解一个库,叫做 Merry。
Merry
Merry,这个库是 Python 的一个第三方库,非常小巧,它实现了几个装饰器。通过使用 Merry 我们可以把异常检查和异常处理的代码分开,并可以通过装饰器来定义异常检查和处理的逻辑。 GitHub 地址:https://github.com/miguelgrinberg/merry,这个库的安装非常简单,使用 pip3 安装即可:
from merry import Merry
merry = Merry()
merry.logger.disabled = True
@merry._try
def process(num1, num2, file):
result = num1 / num2
with open(file, 'w', encoding='utf-8') as f:
f.write(str(result))
@merry._except(ZeroDivisionError)
def process_zero_division_error(e):
print('zero_division_error', e)
@merry._except(FileNotFoundError)
def process_file_not_found_error(e):
print('file_not_found_error', e)
@merry._except(Exception)
def process_exception(e):
print('exception', type(e), e)
if __name__ == '__main__':
process(1, 2, 'result/result.txt')
process(1, 0, 'result.txt')
process(1, 2, 'result.txt')
process(1, [1], 'result.txt')
这里我们可以看到,我们首先声明了一个 Merry 对象,然后 process 方法加上 merry 对象的 _try 方法的装饰器,这样就实现了异常的监听。 有了异常监听之后,怎么来进行异常处理呢?还是通过同一个 merry 对象,使用其 _except 方法作为装饰器即可。比如这里我们将几个异常处理方法分开了,如处理 ZeroDivisionError、FileNotFoundError、Exception 等异常分别都有一个方法的声明,分别加上对应的装饰器即可。 这样的话,我们就轻松实现了异常监听和处理了。 和上面比有什么不同呢?
主逻辑里面不用额外加异常处理代码了,显得简洁。
主逻辑不用因为 try except 而缩进了。
每个异常处理方法单独分开了,可以实现解耦和重用。
整个实现就舒服多了。 运行一下上面的代码,输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import requests
from merry import Merry
from requests import ConnectTimeout
merry = Merry()
merry.logger.disabled = True
catch = merry._try
class BaseClass(object):
@staticmethod
@merry._except(ZeroDivisionError)
def process_zero_division_error(e):
print('zero_division_error', e)
@staticmethod
@merry._except(FileNotFoundError)
def process_file_not_found_error(e):
print('file_not_found_error', e)
@staticmethod
@merry._except(Exception)
def process_exception(e):
print('exception', type(e), e)
@staticmethod
@merry._except(ConnectTimeout)
def process_connect_timeout(e):
print('connect_timeout', e)
class Calculator(BaseClass):
@catch
def process(self, num1, num2, file):
result = num1 / num2
with open(file, 'w', encoding='utf-8') as f:
f.write(str(result))
class Fetcher(BaseClass):
@catch
def process(self, url):
response = requests.get(url, timeout=1)
if response.status_code == 200:
print(response.text)
if __name__ == '__main__':
c = Calculator()
c.process(1, 0, 'result.txt')
f = Fetcher()
f.process('http://notfound.com')
这里我们看到,我们先实现了一个 BaseClass,里面通过 merry 定义了好多个异常处理方法和处理流程,异常处理方法定义成 staticmethod。 接着我们定义了两个类,一个是 Calculator,一个是 Fetcher,分别完成不同的功能,一个是计算,一个是抓取网页。另外 Merry 的 _try 方法我们给它取了个别名,比如叫做 catch,显得更简洁。 在 process 方法中,我们我们想要进行异常处理,那么就加上 @catch 这装饰器就好了,其他的不需要管。 这样,我们在实现子类的时候,只需要集成 BaseClass 然后实现对应的方法就好了,如果想加上异常处理就加个装饰器,也无需再关心 Merry 的具体实现,父类都帮我们实现好了,这样就方便多了。 运行结果如下:
zero_division_error division by zero
connect_timeout HTTPConnectionPool(host='notfound.com', port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x10d5b9310>, 'Connection to notfound.com timed out. (connect timeout=1)'))
@merry._try
def app_logic():
db = open_database()
merry.g.database = db # save it in the error context just in case
# do database stuff here
@merry._except(Exception)
def catch_all():
db = getattr(merry.g, 'database', None)
if db is not None and is_database_open(db):
close_database(db)
print('Unexpected error, quitting')
sys.exit(1)
但我个人觉得这个写法很鸡肋,我个人觉得应该能获取主逻辑方法里面的 context 对象,context 里面包含了主逻辑方法里面的变量状态,然后异常处理的方法的某个参数可以接收到这个 context 对象,就能直接获取变量值了。 不过这只是个个人想法,还没有实现,有兴趣的朋友可以试试。
最后,我们来看看它的源码吧,其实源码就这么多:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
from functools import wraps
import inspect
import logging
getargspec = None
if getattr(inspect, 'getfullargspec', None):
getargspec = inspect.getfullargspec
else:
# this one is deprecated in Python 3, but available in Python 2
getargspec = inspect.getargspec
class _Namespace:
pass
class Merry(object):
def __init__(self, logger_name='merry', debug=False):
self.logger = logging.getLogger(logger_name)
self.g = _Namespace()
self.debug = debug
self.except_ = {}
self.force_debug = []
self.force_handle = []
self.else_ = None
self.finally_ = None
def _try(self, f):
@wraps(f)
def wrapper(*args, **kwargs):
ret = None
try:
ret = f(*args, **kwargs)
# note that if the function returned something, the else clause
# will be skipped. This is a similar behavior to a normal
# try/except/else block.
if ret is not None:
return ret
except Exception as e:
# find the best handler for this exception
handler = None
for c in self.except_.keys():
if isinstance(e, c):
if handler is None or issubclass(c, handler):
handler = c
# if we don't have any handler, we let the exception bubble up
if handler is None:
raise e
# log exception
self.logger.exception('[merry] Exception caught')
# if in debug mode, then bubble up to let a debugger handle
debug = self.debug
if handler in self.force_debug:
debug = True
elif handler in self.force_handle:
debug = False
if debug:
raise e
# invoke handler
if len(getargspec(self.except_[handler])[0]) == 0:
return self.except_[handler]()
else:
return self.except_[handler](e)
else:
# if we have an else handler, call it now
if self.else_ is not None:
return self.else_()
finally:
# if we have a finally handler, call it now
if self.finally_ is not None:
alt_ret = self.finally_()
if alt_ret is not None:
ret = alt_ret
return ret
return wrapper
def _except(self, *args, **kwargs):
def decorator(f):
for e in args:
self.except_[e] = f
d = kwargs.get('debug', None)
if d:
self.force_debug.append(e)
elif d is not None:
self.force_handle.append(e)
return f
return decorator
def _else(self, f):
self.else_ = f
return f
def _finally(self, f):
self.finally_ = f
return f
我们知道在国内使用 Docker,无论是 Pull、Build 还是 Push 镜像都十分慢,因为毕竟很多源都是国外的源,下载和上传慢是必然的现象。 最近我在写的项目都是用 Docker 运行起来的,在测试的时候,我可能需要先 Build 一下然后跑起来测试下逻辑有没有问题。 在我自己本地机器上构建就有这么几个问题,一个问题当然就是速度慢,我用的肯定是国内的上网线路,有时候用个新镜像,半天 Pull 不下来,而且有的镜像是一些私有镜像,不好弄加速器,有的公开镜像试了几个加速器效果也不理想。另外一个问题当 Build 镜像的时候,如果涉及到一些编译的过程,就会占用我的本地机器的 CPU 资源,有时候搞得还挺卡。 所以,我干嘛不把这些 Build 的过程挪到服务器上来搞呢?如果我有一台国外的服务器,还能解决速度问题,另外还不会占用我本地机器的 CPU 资源。 但问题是,我要在自己机器上写代码呀,编译和运行又在远端,那代码怎么同步到远端呢? 那么本节就来介绍下一种本地代码实时同步远程服务器的方法吧。 其实这个功能我用了好久了,但之前一直用起来感觉略鸡肋,因为免不了的还需要在远端配置一下运行环境才能跑,不过后来切到 Docker 运行的话,就舒服多了。如果大家用 Docker 运行项目的话,推荐大家可以试下。
在这开始之前要求有一台远程 Linux 服务器,安装好 Docker 即可。另外当然还需要能 SSH 远程访问,这是必须的。另外如果是海外的服务器是最好的了,构建镜像速度会更快。 另外这里我是用 PyCharm 实现的远程同步功能,如果大家写 Python 多的话当然是推荐 PyCharm。不过其他的 JetBrains IDE 也基本都带着这个功能,所以如果用其他的 JetBrains IDE 也是 OK 的。注意,这里必须要用的是专业版,只有专业版才有这个功能。
好,我们要实现的是本地代码实时同步服务器的功能。利用 PyCharm 自带的组件我们轻松实现这个功能。 PyCharm 有一个 SFTP 部署模块,可以帮助我们把本地的代码实时同步到远端。 好,首先 PyCharm 打开任意一个项目,在这里我就以自己的项目为例了。  接着我们点击 PyCharm 的 Tools -> Deployment -> Configuration,这里我们可以配置远程 SFTP 服务器,如图所示:
接着我们点击 PyCharm 的 Tools -> Deployment -> Configuration,这里我们可以配置远程 SFTP 服务器,如图所示:  打开之后是这样子,这里选择 SFTP,然后填入服务器的连接信息,如图所示:
打开之后是这样子,这里选择 SFTP,然后填入服务器的连接信息,如图所示:  在这里可以点「TEST CONNECTION」测试下是否能够连接成功。 OK,配置完了之后,我们已经成功添加好了一台远程服务器了,比如我这里就添加了一台我自己的服务器,Host 为 vm1.cuiqingcai.com。 既然要实现本地和服务器文件同步,那么当然必须要指定本地项目文件夹和远程哪个文件夹同步吧。在哪里指定呢?切换到第二个选项卡,Mappings,如图所示:
在这里可以点「TEST CONNECTION」测试下是否能够连接成功。 OK,配置完了之后,我们已经成功添加好了一台远程服务器了,比如我这里就添加了一台我自己的服务器,Host 为 vm1.cuiqingcai.com。 既然要实现本地和服务器文件同步,那么当然必须要指定本地项目文件夹和远程哪个文件夹同步吧。在哪里指定呢?切换到第二个选项卡,Mappings,如图所示:  这里我们可以通过选择 LocalPath 和 Deployment Path 分别指定本地和远程的文件夹名称。注意这里后者指的是相对服务器工作目录的路径。 好了,就是这样,基本配置就完成了。如果你还想配置某些路径不同步的话,还可以在第三个选项卡 Excluded Paths 里面配置。 接着,还有一些可以配置的地方,点击 Tools -> Deployment -> Options 我们可以配置更多细节,如图所示:
这里我们可以通过选择 LocalPath 和 Deployment Path 分别指定本地和远程的文件夹名称。注意这里后者指的是相对服务器工作目录的路径。 好了,就是这样,基本配置就完成了。如果你还想配置某些路径不同步的话,还可以在第三个选项卡 Excluded Paths 里面配置。 接着,还有一些可以配置的地方,点击 Tools -> Deployment -> Options 我们可以配置更多细节,如图所示:  比如这里我就配置了下什么时候上传,这里我改成了按 Ctrl + S 保存的时候再上传,这样我可以自由控制上传的时机。 另外这里还需要把自动上传勾选上,如图所示:
比如这里我就配置了下什么时候上传,这里我改成了按 Ctrl + S 保存的时候再上传,这样我可以自由控制上传的时机。 另外这里还需要把自动上传勾选上,如图所示:  好了,整个都配置好啦。
好了,整个都配置好啦。
接下来我们上传下试试吧,可以点菜单里面的 Upload to 选项来上传代码。 点击上传之后,PyCharm 会单独开一个 File Transfer 窗口来显示文件上传的结果,如图所示:  这样就上传完毕了。 接着我们任意修改一个文件,按保存,即 Ctrl + S,这里就出现了自动上传的日志,提示某个文件被上传成功了。
这样就上传完毕了。 接着我们任意修改一个文件,按保存,即 Ctrl + S,这里就出现了自动上传的日志,提示某个文件被上传成功了。  OK,验证没问题。
OK,验证没问题。
远程 SSH
注意:这里记得把服务器的安全组限制打开,以免出现远程端口无法访问的问题。
好,以上就是利用 PyCharm 实现代码实时远程同步的方法,大家也来试试吧。
attrs、cattrs
GitHub:https://github.com/python-attrs/attrs、https://github.com/Tinche/cattrs 简化类的定义、序列化反序列化等操作。 个人写的简介:https://mp.weixin.qq.com/s/oHK-Y4lOeaQCFtDWgqXxFA
loguru
GitHub:https://github.com/Delgan/loguru 可简化日志记录写法。 个人写的简介:https://mp.weixin.qq.com/s/5Ri1WS5cTGCNAQ0I_zYycg
autopep8
GitHub:https://github.com/hhatto/autopep8 把 Python 代码转成符合 PEP8 规范的代码。
psutil
GitHub:https://github.com/giampaolo/psutil Python 实现任务监控的库。
GitHub:https://github.com/gruns/furl 对 url 的处理非常方便,比 urllib 等库好用多。
retrying、tenacity
GitHub:https://github.com/rholder/retrying、https://github.com/jd/tenacity 异常重试库,如出错之后重试多少次,尤其在发起一些 HTTP 请求时非常有用,当然也能用于其他地方。
typing
Docs:https://docs.python.org/zh-cn/3/library/typing.html#module-typing 对 Python 类型的支持,支持多种类型、嵌套类型,也推荐多多使用 Python 的类型注解。
argparse
Docs:https://docs.python.org/zh-cn/3/library/argparse.html 个人曾经使用过几个命令行解析工具,如 docopt,但后来还是转回来了 argparse,功能齐全强大。
absl-py
GitHub:https://github.com/abseil/abseil-py 个人感觉比 argparse 更易用的库,如 TensorFlow 就在使用这个,对于定义一些 Flag 非常方便。
pipenv
GitHub:https://github.com/pypa/pipenv 功能更全的包管理工具,集成虚拟环境、支持 Lock 机制锁定安装包版本和依赖信息。当然也有坑点,可自行搜索。
Docs:https://www.django-rest-framework.org/ 基于 Django 的 REST Framework,快速实现 REST API。
watchdog
GitHub:https://github.com/gorakhargosh/watchdog 方便监视文件系统改动。
Docs:https://docs.python.org/3/library/glob.html 对文件的操作非常方便。
Docs:https://docs.python.org/2/library/2to3.html 把 Python2 代码转成 Python3 代码。
GitHub:https://github.com/mahmoud/glom 对 JSON 嵌套的处理非常方便。
pathlib
Docs:https://docs.python.org/3/library/pathlib.html 更为方便的 Python 路径操作库。
environs
GitHub:https://github.com/sloria/environs 对于环境变量的获取非常方便,支持多种类型,如 int、bool 等。
pysnooper
GitHub:https://github.com/cool-RR/PySnooper 非常方便简单的 Python 调试器,可以追踪到代码每一处细节的执行状态。
GitHub:https://github.com/tqdm/tqdm 进度条控制显示非常方便。
GitHub:https://github.com/amoffat/sh 对 Linux 一些命令的封装,简单好用又高效。
faker
GitHub:https://github.com/joke2k/faker 模拟数据的生成。 个人写的简介:https://mp.weixin.qq.com/s/iLjr95uqgTclxYfWWNxrAA
arrow、dateutil、dateparser、pendulum
GitHub:https://github.com/crsmithdev/arrow、https://github.com/dateutil/dateutil、https://github.com/scrapinghub/dateparser、https://github.com/sdispater/pendulum 时间解析和处理库,非常方便。arrow 目前 Star 最多,好评最多。
yagmail
GitHub:https://github.com/kootenpv/yagmail 方便的发邮件库,替代自带的 smtplib。
chardet
GitHub:https://github.com/chardet/chardet 字符串类型编码检测。
pypinyin
GitHub:https://github.com/mozillazg/python-pinyin 汉字转拼音,在一些中文转化处理上很有用。 个人写的简介:https://mp.weixin.qq.com/s/NvA3j8Ns1-6CFgWpUcWwQw
sphinx
Docs:https://www.sphinx-doc.org/en/master/ 编写文档使用,大多数 Python 库文档都是这个写的,如 Scrapy、requests。 个人 sphinx + markdown 的样例:https://github.com/Gerapy/Docs
jinja2
GitHub:https://github.com/pallets/jinja 一个方便的模板引擎,呈现页面时很方便。
click
GitHub:https://github.com/pallets/click 更方便灵活地实现命令行传递参数。
GitHub:https://github.com/ray-project/ray 分布式多进程管理。
supervisor
GitHub:https://github.com/Supervisor/supervisor 进程管理工具,如实现多任务后台运行,Docker 打包时会经常用到。
apscheduler
GitHub:https://github.com/agronholm/apscheduler Python 定时任务,不过 K8S 也可以实现,个人目前可能更倾向于 K8S。
intelpython
Home:https://software.intel.com/en-us/distribution-for-python 这不是 Python 库,是一个 Intel 开发的基于 Intel 处理器优化的 Python 解释器,对于大规模运算提升很大。 先推荐这么多了,后面还会慢慢积累,大家可以了解下,有不少库还是能极大提高生产力的。 由于这次主要是推荐一些适用范围和方向较广,个人感觉对于一些基础设施的建设比较有用的库,所以一些 Web、爬虫、数据分析、机器学习等库就没有列在这里了。当然也由于个人水平有限,也有很多库没有列全,如果大家有推荐的,欢迎留言分享哈!
当今大数据的时代,网络爬虫已经成为了获取数据的一个重要手段。 但要学习好爬虫并没有那么简单。首先知识点和方向实在是太多了,它关系到了计算机网络、编程基础、前端开发、后端开发、App 开发与逆向、网络安全、数据库、运维、机器学习、数据分析等各个方向的内容,它像一张大网一样把现在一些主流的技术栈都连接在了一起。正因为涵盖的方向多,因此学习的东西也非常零散和杂乱,很多初学者搞不清楚究竟要学习哪些知识,学习过程中遇到反爬也不知道用什么方法来解决,本篇我们来做一些归纳和总结。
一些最基本的网站,往往不带任何反爬措施。比如某个博客站点,我们要爬全站的话就顺着列表页爬到文章页,再把文章的时间、作者、正文等信息爬下来就可以了。 那代码怎么写呢?用 Python 的 requests 等库就够了,写一个基本的逻辑,顺着把一篇篇文章的源码获取下来,解析的话用 XPath、BeautifulSoup、PyQuery 或者正则表达式,或者粗暴的字符串匹配把想要的内容抠出来,再加个文本写入存下来就完事了。 代码很简单,就几个方法调用。逻辑很简单,几个循环加存储。最后就能看到一篇篇文章就被我们存到自己的电脑里面了。当然有的同学可能不太会写代码或者都懒得写,那么利用基本的可视化爬取工具,如某爪鱼、某裔采集器也能通过可视化点选的方式把数据爬下来。 如果存储方面稍微扩展一下的话,可以对接上 MySQL、MongoDB、Elasticsearch、Kafka 等等来保存数据,实现持久化存储。以后查询或者操作会更方便。 反正,不管效率如何,一个完全没有反爬的网站用最最基本的方式就搞定了。 到这里,你就说你会爬虫了吗?不,还差的远呢。
Ajax、动态渲染
多进程、多线程、协程
封 IP 也是个令人头疼的事,行之有效的方法就是换代理了。 代理很多种,市面上免费的,收费的太多太多了。 首先可以把市面上免费的代理用起来,自己搭建一个代理池,收集现在全网所有的免费代理,然后加一个测试器一直不断测试,测试的网址可以改成你要爬的网址。这样测试通过的一般都能直接拿来爬你的目标网站。我自己也搭建过一个代理池,现在对接了一些免费代理,定时爬、定时测,还写了个 API 来取,放在 GitHub 了:https://github.com/Python3WebSpider/ProxyPool,打好了 Docker 镜像,提供了 Kubernetes 脚本,大家可以直接拿来用。 付费代理也是一样,很多商家提供了代理提取接口,请求一下就能获取几十几百个代理,我们可以同样把它们接入到代理池里面。但这个代理也分各种套餐,什么开放代理、独享代理等等的质量和被封的几率也是不一样的。 有的商家还利用隧道技术搭了代理,这样代理的地址和端口我们是不知道的,代理池是由他们来维护的,比如某布云,这样用起来更省心一些,但是可控性就差一些。 还有更稳定的代理,比如拨号代理、蜂窝代理等等,接入成本会高一些,但是一定程度上也能解决一些封 IP 的问题。 不过这些背后也不简单,为啥一个好好的高匿代理就是莫名其妙爬不了,背后的一些事就不多讲了。
有些信息需要模拟登录才能爬嘛,如果爬的过快,人家网站直接把你的账号封禁了,就啥都没得说了。比如爬公众号的,人家把你 WX 号封了,那就全完了。 一种解决方法当然就是放慢频率,控制下节奏。 还有种方法就是看看别的终端,比如手机页、App 页、wap 页,看看有没有能绕过登录的法子。 另外比较好的方法,那就是分流。如果你号足够多,建一个池子,比如 Cookies 池、Token 池、Sign 池反正不管什么池吧,多个账号跑出来的 Cookies、Token 都放到这个池子里面,用的时候随机从里面拿一个。如果你想保证爬取效率不变,那么 100 个账号相比 20 个账号,对于每个账号对应的 Cookies、Token 的取用频率就变成原来的了 1/5,那么被封的概率也就随之降低了。
奇葩的反爬
JavaScript 逆向
设置和获取环境变量
首先,我们先来了解一下在 Python 项目里面怎样设置和获取变量。 首先让我们定义一个最简单的 Python 文件,命名为 main.py,内容如下:
更安全的获取方式
from environs import Env
env = Env()
env.read_env() # read .env file, if it exists
# required variables
gh_user = env("GITHUB_USER") # => 'sloria'
secret = env("SECRET") # => raises error if not set
# casting
max_connections = env.int("MAX_CONNECTIONS") # => 100
ship_date = env.date("SHIP_DATE") # => datetime.date(1984, 6, 25)
ttl = env.timedelta("TTL") # => datetime.timedelta(0, 42)
log_level = env.log_level("LOG_LEVEL") # => logging.DEBUG
# providing a default value
enable_login = env.bool("ENABLE_LOGIN", False) # => True
enable_feature_x = env.bool("ENABLE_FEATURE_X", False) # => False
# parsing lists
gh_repos = env.list("GITHUB_REPOS") # => ['webargs', 'konch', 'ped']
coords = env.list("COORDINATES", subcast=float) # => [23.3, 50.0]
通过 env 可以设置必需定义的变量,如果没有定义,则会报错。
通过 date、timedelta 方法可以对日期或时间进行转化,转成 datetime.date 或 timedelta 类型。
通过 log_level 方法可以对日志级别进行转化,转成 logging 里的日志级别定义。
通过 bool 方法可以对布尔类型变量进行转化。
通过 list 方法可以对逗号分隔的内容进行 list 转化,并可以通过 subcast 方法对 list 的每个元素进行类型转化。
env.strenv.boolenv.intenv.floatenv.decimalenv.list (accepts optional subcast keyword argument)env.dict (accepts optional subcast keyword argument)env.jsonenv.datetimeenv.dateenv.timedelta (assumes value is an integer in seconds)env.urlenv.uuidenv.log_levelenv.path (casts to a pathlib.Path)这里 list、dict、json、date、url、uuid、path 个人认为都还是比较有用的,另外 list、dict 方法还有一个 subcast 方法可以对元素内容进行转化。 对于 dict、url、date、uuid、path 这里我们来补充说明一下。 下面我们定义这些类型的环境变量:
from environs import Env
env = Env()
VAR_DICT = env.dict('VAR_DICT')
print(type(VAR_DICT), VAR_DICT)
VAR_JSON = env.json('VAR_JSON')
print(type(VAR_JSON), VAR_JSON)
VAR_URL = env.url('VAR_URL')
print(type(VAR_URL), VAR_URL)
VAR_UUID = env.uuid('VAR_UUID')
print(type(VAR_UUID), VAR_UUID)
VAR_PATH = env.path('VAR_PATH')
print(type(VAR_PATH), VAR_PATH)
<class 'dict'> {'name': 'germey', 'age': '25'}
<class 'dict'> {'name': 'germey', 'age': 25}
<class 'urllib.parse.ParseResult'> ParseResult(scheme='https', netloc='cuiqingcai.com', path='', params='', query='', fragment='')
<class 'uuid.UUID'> 762c8d53-5860-4d5d-81bc-210bf2663d0e
<class 'pathlib.PosixPath'> /var/py/env
# export MYAPP_HOST=lolcathost
# export MYAPP_PORT=3000
with env.prefixed("MYAPP_"):
host = env("HOST", "localhost") # => 'lolcathost'
port = env.int("PORT", 5000) # => 3000
# nested prefixes are also supported:
# export MYAPP_DB_HOST=lolcathost
# export MYAPP_DB_PORT=10101
with env.prefixed("MYAPP_"):
with env.prefixed("DB_"):
db_host = env("HOST", "lolcathost")
db_port = env.int("PORT", 10101)
# export TTL=-2
# export NODE_ENV='invalid'
# export EMAIL='^_^'
from environs import Env
from marshmallow.validate import OneOf, Length, Email
env = Env()
# simple validator
env.int("TTL", validate=lambda n: n > 0)
# => Environment variable "TTL" invalid: ['Invalid value.']
# using marshmallow validators
env.str(
"NODE_ENV",
validate=OneOf(
["production", "development"], error="NODE_ENV must be one of: {choices}"
),
)
# => Environment variable "NODE_ENV" invalid: ['NODE_ENV must be one of: production, development']
# multiple validators
env.str("EMAIL", validate=[Length(min=4), Email()])
# => Environment variable "EMAIL" invalid: ['Shorter than minimum length 4.', 'Not a valid email address.']
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import platform
from os.path import dirname, abspath, join
from environs import Env
from loguru import logger
env = Env()
env.read_env()
# definition of flags
IS_WINDOWS = platform.system().lower() == 'windows'
# definition of dirs
ROOT_DIR = dirname(dirname(abspath(__file__)))
LOG_DIR = join(ROOT_DIR, env.str('LOG_DIR', 'logs'))
# definition of environments
DEV_MODE, TEST_MODE, PROD_MODE = 'dev', 'test', 'prod'
APP_ENV = env.str('APP_ENV', DEV_MODE).lower()
APP_DEBUG = env.bool('APP_DEBUG', True if APP_ENV == DEV_MODE else False)
APP_DEV = IS_DEV = APP_ENV == DEV_MODE
APP_PROD = IS_PROD = APP_DEV == PROD_MODE
APP_TEST = IS_TEST = APP_ENV = TEST_MODE
# redis host
REDIS_HOST = env.str('REDIS_HOST', '127.0.0.1')
# redis port
REDIS_PORT = env.int('REDIS_PORT', 6379)
# redis password, if no password, set it to None
REDIS_PASSWORD = env.str('REDIS_PASSWORD', None)
# redis connection string, like redis://[password]@host:port or rediss://[password]@host:port
REDIS_CONNECTION_STRING = env.str('REDIS_CONNECTION_STRING', None)
# definition of api
API_HOST = env.str('API_HOST', '0.0.0.0')
API_PORT = env.int('API_PORT', 5555)
API_THREADED = env.bool('API_THREADED', True)
# definition of flags
ENABLE_TESTER = env.bool('ENABLE_TESTER', True)
ENABLE_GETTER = env.bool('ENABLE_GETTER', True)
ENABLE_SERVER = env.bool('ENABLE_SERVER', True)
# logger
logger.add(env.str('LOG_RUNTIME_FILE', 'runtime.log'), level='DEBUG', rotation='1 week', retention='20 days')
logger.add(env.str('LOG_ERROR_FILE', 'error.log'), level='ERROR', rotation='1 week')
你又会怎么操作呢? 另外如果 JSON 数据里面有各种各样的脏数据,你需要在初始化时验证这些字段是否合法,另外 User 这个对象里面 name、age 的数据类型不同,如何针对不同的数据类型进行针对性的类型转换,这个你有更好的实现方案吗?
之前我写过一篇文章介绍过 attrs 和 cattrs 这两个库,它们二者的组合可以非常方便地实现对象的序列化和反序列化。 譬如这样:
好,这里我们通过 attrs 和 cattrs 这两个库来实现了单个对象的转换。 首先我们要肯定一下 attrs 这个库,它可以极大地简化 Python 类的定义,同时每个字段可以定义多种数据类型。 但 cattrs 这个库就相对弱一些了,如果把 data 换成数组,用 cattrs 还是不怎么好转换的,另外它的 structure 和 unstructure 在某些情景下容错能力较差,所以对于上面的需求,用这两个库搭配起来并不是一个最优的解决方案。 另外数据的校验也是一个问题,attrs 虽然提供了 validator 的参数,但对于多种类型的数据处理的支持并没有那么强大。 所以,我们想要寻求一个更优的解决方案。
更优雅的方案
from pprint import pprint
from marshmallow import Schema, fields, validate, ValidationError
class UserSchema(Schema):
name = fields.Str(validate=validate.Length(min=1))
permission = fields.Str(validate=validate.OneOf(['read', 'write', 'admin']))
age = fields.Int(validate=validate.Range(min=18, max=40))
in_data = {'name': '', 'permission': 'invalid', 'age': 71}
try:
UserSchema().load(in_data)
except ValidationError as err:
pprint(err.messages)
from marshmallow import Schema, fields, ValidationError
def validate_quantity(n):
if n < 0:
raise ValidationError('Quantity must be greater than 0.')
if n > 30:
raise ValidationError('Quantity must not be greater than 30.')
class ItemSchema(Schema):
quantity = fields.Integer(validate=validate_quantity)
in_data = {'quantity': 31}
try:
result = ItemSchema().load(in_data)
except ValidationError as err:
print(err.messages)
from marshmallow import fields, Schema, validates, ValidationError
class ItemSchema(Schema):
quantity = fields.Integer()
@validates('quantity')
def validate_quantity(self, value):
if value < 0:
raise ValidationError('Quantity must be greater than 0.')
if value > 30:
raise ValidationError('Quantity must not be greater than 30.')
from pprint import pprint
from marshmallow import Schema, fields, ValidationError
class UserSchema(Schema):
name = fields.String(required=True)
age = fields.Integer(required=True, error_messages={'required': 'Age is required.'})
city = fields.String(
required=True,
error_messages={'required': {'message': 'City required', 'code': 400}},
)
email = fields.Email()
try:
result = UserSchema().load({'email': '[email protected]'})
except ValidationError as err:
pprint(err.messages)
from datetime import date
from marshmallow import Schema, fields, pprint
class ArtistSchema(Schema):
name = fields.Str()
class AlbumSchema(Schema):
title = fields.Str()
release_date = fields.Date()
artist = fields.Nested(ArtistSchema())
bowie = dict(name='David Bowie')
album = dict(artist=bowie, title='Hunky Dory', release_date=date(1971, 12, 17))
schema = AlbumSchema()
result = schema.dump(album)
pprint(result, indent=2)
随着云计算和虚拟技术的发展,主机业务从虚拟主机逐步发展到独享云服务器。我们 IT 人对服务器的需求是很强烈的,无论你是后端研发、前端开发、云计算、大数据、架构、数据存储、运维还是产品经理,每个人手上多多少少都会有几台云服务器。  这些云服务器被用做测试用机、学习用机或者正式生产用机,有些朋友会在上面搭建博客,有些朋友在上面搭建 API。东鸽自己也手握几台服务器:
这些云服务器被用做测试用机、学习用机或者正式生产用机,有些朋友会在上面搭建博客,有些朋友在上面搭建 API。东鸽自己也手握几台服务器:  其中有 3 台用作实际的生产,新书《Python3 反爬虫原理与绕过实战》的在线练习平台、夜幕爬虫安全论坛和我的个人博客。另外几台用来做测试、数据合作和练习。 练习的话,像平时学习 MongoDB 数据库、Redis 数据库和 Mysql 数据库的时候,我会在服务器上安装对应的应用,启动服务后在自己的电脑上连接,这样能得到与生产环境一样的体验。学习 Linux 和 Shell 脚本的时候也会用云服务器进行练习,这样既能够确保练习效果,又避免了对本机电脑的干扰。 你总不能在自己的电脑上折腾来折腾去吧,万一搞坏了,工作咋办? 数据合作,那是个人业务上的事了。数据用云端数据库的方式交付给客户,不需要其他传输媒介,轻便快捷,没有延时风险。我这边把数据存储到服务器,客户从服务器上拉取数据。
其中有 3 台用作实际的生产,新书《Python3 反爬虫原理与绕过实战》的在线练习平台、夜幕爬虫安全论坛和我的个人博客。另外几台用来做测试、数据合作和练习。 练习的话,像平时学习 MongoDB 数据库、Redis 数据库和 Mysql 数据库的时候,我会在服务器上安装对应的应用,启动服务后在自己的电脑上连接,这样能得到与生产环境一样的体验。学习 Linux 和 Shell 脚本的时候也会用云服务器进行练习,这样既能够确保练习效果,又避免了对本机电脑的干扰。 你总不能在自己的电脑上折腾来折腾去吧,万一搞坏了,工作咋办? 数据合作,那是个人业务上的事了。数据用云端数据库的方式交付给客户,不需要其他传输媒介,轻便快捷,没有延时风险。我这边把数据存储到服务器,客户从服务器上拉取数据。  一个普通的生产者消费者模式就诞生了。如果数据业务体量比较大,或者说数据业务的出口比较多,那我可能会借用消息中间件来进行调节。
一个普通的生产者消费者模式就诞生了。如果数据业务体量比较大,或者说数据业务的出口比较多,那我可能会借用消息中间件来进行调节。  为了保证数据的完整性和可用性,我可能会对服务器进行镜像,那么我就需要 2~3 台服务器。假设每台服务器的成本是 300元/年,数据合作业务的收入是 3W/年,那真是四两拨千斤了。 要合理利用资源,让资源为我们生小钱钱! 服务器配置跟具体业务需求有关,用于测试的服务器通常是 1 核 2G 1M;博客和论坛的服务器带宽稍大一些,带宽通常是 3M ;用于数据合作的服务器内存较大,一般需要为 4G~8G; 除了服务器之外,华为云还有很多神奇的业务。我觉得黑科技真的是太多了。
为了保证数据的完整性和可用性,我可能会对服务器进行镜像,那么我就需要 2~3 台服务器。假设每台服务器的成本是 300元/年,数据合作业务的收入是 3W/年,那真是四两拨千斤了。 要合理利用资源,让资源为我们生小钱钱! 服务器配置跟具体业务需求有关,用于测试的服务器通常是 1 核 2G 1M;博客和论坛的服务器带宽稍大一些,带宽通常是 3M ;用于数据合作的服务器内存较大,一般需要为 4G~8G; 除了服务器之外,华为云还有很多神奇的业务。我觉得黑科技真的是太多了。  上次我用华为云的深度学习一体化服务 ModelArts 在线实现了图像深度学习中的图片标注、图片分类预测和模型部署+生成 API,感觉很流畅。
上次我用华为云的深度学习一体化服务 ModelArts 在线实现了图像深度学习中的图片标注、图片分类预测和模型部署+生成 API,感觉很流畅。  鼠标点点点,配置一丢丢参数,也不用自己写代码,也不用弄 Web 框架,唰唰唰地几下,就可以调用了。 崔庆才崔哥用 ModelArts 实现了爬虫工程师常用到的拼图验证码缺口识别 API。
鼠标点点点,配置一丢丢参数,也不用自己写代码,也不用弄 Web 框架,唰唰唰地几下,就可以调用了。 崔庆才崔哥用 ModelArts 实现了爬虫工程师常用到的拼图验证码缺口识别 API。  样本准备了小小几十个,训练完成后的识别准确率很高,这样我们就不用担心缺口位置定位的问题了。
样本准备了小小几十个,训练完成后的识别准确率很高,这样我们就不用担心缺口位置定位的问题了。  服务器数量多,开销自然就大。如无必要,通常我是不会购买服务器的,但每当云服务器厂商有活动时我都会做一些购买计划。例如我今年打算增加数据业务,并且学习架构方面的知识,那我至少得再买 5 台服务器。趁着华为开年采购季活动,购买一台服务器的成本最低 79元/年。除此之外,华为云还有数据库专场活动、域名建站专场活动、云安全专场活动在等着我们,买买买!
服务器数量多,开销自然就大。如无必要,通常我是不会购买服务器的,但每当云服务器厂商有活动时我都会做一些购买计划。例如我今年打算增加数据业务,并且学习架构方面的知识,那我至少得再买 5 台服务器。趁着华为开年采购季活动,购买一台服务器的成本最低 79元/年。除此之外,华为云还有数据库专场活动、域名建站专场活动、云安全专场活动在等着我们,买买买!  大家相识已久,东鸽感谢大家关注和支持,这次华为云开年采购季活动我自掏腰包购买 3 台 1 核 2G 1M 的服务器(1年期)送给各位粉丝。大家扫码即可参与抽奖,到期自动开奖。 参与要求:参与活动时必须转发上方华为云开年采购季海报,领奖时小编会检查的哦。
大家相识已久,东鸽感谢大家关注和支持,这次华为云开年采购季活动我自掏腰包购买 3 台 1 核 2G 1M 的服务器(1年期)送给各位粉丝。大家扫码即可参与抽奖,到期自动开奖。 参与要求:参与活动时必须转发上方华为云开年采购季海报,领奖时小编会检查的哦。 
大家平常遇到不错的网站或文章,会用什么方式收藏?Chrome 书签?
现在你们 Chrome 书签里面啥样子?乱不乱?
如果我让你们快速从书签里面找出一个曾经收藏过网站,你要花多久?
如果你在手机上用其他的浏览器,比如 Safari、微博上看到了一个不错的网站,怎么存?
存到了 Safari 上面,又怎么和电脑上的 Chrome 书签合并?之后还能找到吗?
在这个终身学习的时代,我们需要保存和收藏的东西太多太多了。好的网站,好的博文,好的软件,都需要存下来。那么怎么存?这是个问题。 我最早也用过 Chrome 书签,但是这有个毛病,怎么全平台同步?我想在手机(iPhone)上看我的书签内容,难道我还要专门下个 Chrome?另外书签的整理和搜索也是个问题,实在是让我喜欢不起来。 我在选择软件都会追求全平台云同步。比如时间规划软件,我会用「滴答清单」;SSH 软件,我会用「Termius」;翅膀软件我会用「Surge」,为的都是解决一些跨终端问题,它们都是 iPhone、iPad、Mac、Windows、Web 全部平台同步的,有的甚至还支持浏览器插件或者 Apple Watch 等等,这样我们不论切换到哪个终端,都会非常方便地同步数据。
Pocket
Raindrop.io
所以近期我就一直在找一款能替换掉「Pocket」的纯粹的内容收集软件,这么几个原则吧:
跨平台,必须支持所有终端,包括 Windows、Mac、iPhone、iPad、Android、Web 并提供各个浏览器插件。
功能明确,能方便地管理分类、标签、收藏等内容,且不要有一些其他鸡肋的功能。
好看,好看,好看!我还是很注重界面和美观的,不论是图标还是内页,不优雅的界面会让我觉得很不爽。(之前找软件的时候因为某些软件的图标设计得不好看而被我 Pass 了)。
好了,搜啊搜,找到这么一款软件—— Raindrop.io,感觉不错,看到首页的介绍,被吸引到了!  大家可以看视频来感受一下:https://up.raindrop.io/web/marketing/intro.mp4 可以说首先界面真的吸引到我了,而且左侧的导航分类、收藏夹的管理非常清晰,页面布局也很清晰,甚至支持文件、图片等格式的收藏!另外它同样也支持全平台,完全符合我的需求。 然后我就下载下来了各个平台都试了试,首先试了试它的一些基础功能,比如收藏夹的管理,然后添加上一些不错的内容。 初步整理成下图这么个样子:
大家可以看视频来感受一下:https://up.raindrop.io/web/marketing/intro.mp4 可以说首先界面真的吸引到我了,而且左侧的导航分类、收藏夹的管理非常清晰,页面布局也很清晰,甚至支持文件、图片等格式的收藏!另外它同样也支持全平台,完全符合我的需求。 然后我就下载下来了各个平台都试了试,首先试了试它的一些基础功能,比如收藏夹的管理,然后添加上一些不错的内容。 初步整理成下图这么个样子:  另外内容还支持各种其他的布局,如列表式:
另外内容还支持各种其他的布局,如列表式:  瀑布流式:
瀑布流式:  舒服了。 说回功能,这里我先分了几个分组,为「网站」、「代码」、「图片」,我估计我用到的最多的肯定是「网站」这个分组,用来存各种链接的,「代码」和「图片」是为了测试它的上传文件和图片功能而加的,可以用来存代码文件和图片。 分组建好之后,我们可以在分组里面添加收藏夹,看图里面每行前面有个小图标的就是一个收藏夹。没错,每个收藏夹都可以自定义它的小图标,这个功能真的是增色不少! 它提供了非常多的小图标,看:
舒服了。 说回功能,这里我先分了几个分组,为「网站」、「代码」、「图片」,我估计我用到的最多的肯定是「网站」这个分组,用来存各种链接的,「代码」和「图片」是为了测试它的上传文件和图片功能而加的,可以用来存代码文件和图片。 分组建好之后,我们可以在分组里面添加收藏夹,看图里面每行前面有个小图标的就是一个收藏夹。没错,每个收藏夹都可以自定义它的小图标,这个功能真的是增色不少! 它提供了非常多的小图标,看:  这个功能,我觉得简直不能更赞!另外这些小图标还可以自己上传,所以你看图里面的 GitHub 图标、Python 图标,都是我从 icons8 上面找到并上传的,毫无违和感! 另外每一个收藏它都会自动生成一张封面图,会自动截取网站当前页面的内容,或者也可以自定义上传图片或者自定义截屏,最后每个收藏项都会变成一张张卡片。 当然添加标签页不在话下。
这个功能,我觉得简直不能更赞!另外这些小图标还可以自己上传,所以你看图里面的 GitHub 图标、Python 图标,都是我从 icons8 上面找到并上传的,毫无违和感! 另外每一个收藏它都会自动生成一张封面图,会自动截取网站当前页面的内容,或者也可以自定义上传图片或者自定义截屏,最后每个收藏项都会变成一张张卡片。 当然添加标签页不在话下。  另外浏览器的插件也做的很精致,提供了 Mini Application 和极简模式,收藏一个页面只需要点一下这个图标就收藏好了。如果是高级版的账号,还支持自动分类。
另外浏览器的插件也做的很精致,提供了 Mini Application 和极简模式,收藏一个页面只需要点一下这个图标就收藏好了。如果是高级版的账号,还支持自动分类。  手机和 iPad 上面的软件我也试了,功能基本类似。怎么保存呢?比如我的 iPhone 上可以把这个软件放到分享的 App 列表里面,这样在浏览器里面点击「分享」,然后选「Raindrop.io」就好了,它会自动弹出一个窗口,让我们选择分类或加标签,体验很不错。
手机和 iPad 上面的软件我也试了,功能基本类似。怎么保存呢?比如我的 iPhone 上可以把这个软件放到分享的 App 列表里面,这样在浏览器里面点击「分享」,然后选「Raindrop.io」就好了,它会自动弹出一个窗口,让我们选择分类或加标签,体验很不错。  嗯,总之整体体验下来,非常好用。 另外它还支持自动导入书签或从其他的收藏软件里面迁移,大家如果一些网站保存在书签里面的话,如果用了这个,可以快速导入进来,非常方便!
嗯,总之整体体验下来,非常好用。 另外它还支持自动导入书签或从其他的收藏软件里面迁移,大家如果一些网站保存在书签里面的话,如果用了这个,可以快速导入进来,非常方便!  另外还有一些高级的功能大家再探索吧。怎么感觉越写越像个广告文了,但确实这不是广告文,它确实很好用,在这强推给大家!希望它能帮助大家方便管理各种资源,什么博客、公众号、干货、微博、图片、文件统统可以保存到这里并明确清晰地归类啦!
另外还有一些高级的功能大家再探索吧。怎么感觉越写越像个广告文了,但确实这不是广告文,它确实很好用,在这强推给大家!希望它能帮助大家方便管理各种资源,什么博客、公众号、干货、微博、图片、文件统统可以保存到这里并明确清晰地归类啦!
今天一个偶然的机会,在群里看到了一个推送,是来自一个软件「飞书」的公开课,它讲如何使用飞书,以及如何提高团队的协作效率,我就去听了一下。 头条是飞书开发的,整个 Talk 其实讲了挺多的关于飞书的使用,其实和很多软件的功能大体上是相同的,如文件共享、文档协作、任务分配、聊天沟通等等,像行业内挺多软件,如 Worktile、TAPD、Teambition 等等也都比较完善了,所以一些类似的功能我就不展开说了。 不过其中有一个点,让我听了之后深受启发,那就是如何提高开会效率。 我也参加过很多会议了,包括研究生期间跟着导师出去汇报、开实验室小组会或者公司内部开大会。其中有的内容是讨论具体的实施方案,有的一些时候是单纯的分享或者 sync 进度。对于后者的话,其实没什么问题,就是一个人分享或者快速跟其他人沟通,我想大部分情况下大家都是类似的。但是对于前者,我就觉得一些会议效率太低了,甚至说价值并不高,那么这里就主要说说这种会议。 比如有些会议,尤其是大会,比如十几二十人围在一起开会讨论方案,参与的人很多很杂,有的人甚至还是和会议相关度不高的人或者本身对会议主题完全不了解的人。这时候可能有一个人主持会先说说这个会是干嘛的,开这个会要讨论点什么,说了十分钟之后,一些人才大体上明白这个会在做什么。然后后面就是后面开始讨论方案了,大家也没有整个的时间把控,不知道一共可能讨论多久,大家你一句我一句,有时候扯着扯着扯远了,最后一个会能开上一个半甚至两个多小时,然后会议结束了之后,大家又接着去干活去了。过了一阵子或者几天,想回想一下当时会上到底是怎么说的或者讨论了什么方案,很可能就忘了。如果当时会上有专门做会议纪要的人,那还 OK,如果没有,那这么多人过了一段时间,具体会上说了那些有用的东西或者最后采取了什么方案具体怎么实施呢?很可能就是两个字:忘了。另外,有些人可能整个会上一句话也没说,完全感觉不到任何参与感,所以他也就越来越觉得这个会议没有什么意义,甚至可能就在会上就睡着了。 我想工作的各位难免会遇到这样的问题,或者甚至大家的会议现状就是这样子的。我之前也一直觉得,这种会议模式其实挺病态的,在时间这么宝贵的今天,到底有没有一个比较好的开会方式呢? 今天听了这个分享之后,我确实被其中所讲的一个会议模式吸引到了。 怎么个方式呢?这里我就根据自己的理解大体概括一下。
会议的组织者,在开会之前,根据会议的适用场景,列好这个会议想要讨论的内容,以文档的形式写下来。比如要开发一个软件,那么可能就列出来其中的交互或实现方案。如果是要讨论一个解决方案,那就把已经想到的解决方案写下来。 然后呢,很重要的,在开会之前,把文档都发给大家,比如附在邮件链接里面,大家都可以下载或者在线查看。这样可以让大家提前对会议的内容有所了解,如果是对会议毫不了解的人,也能对会议的主题有个整体的把握。 这样就不会出现这样的情况了: 咦,来了一个会啊,咋叫上我了?这个会到底干嘛的?写的这个主题到底啥意思?我去了能干啥? 这就是其一,提前准备,让所有人都有所了解。 另外,每个人知道主题和讨论内容了,也就知道自己需要准备什么东西,哪些需要演示,哪些需要重点讲解。
阅读及评论
每个人在会前都可以对会议提前了解和准备,每个人的了解和准备都会更充分。
开会前半段每个人都会有单独的时间去理解和思考并做评论。
每个人都会有极强的参与感。
根据大家评论的数量来把握整个开会的节奏,减少了拖延的概率。
会上当场确定好解决方案和人员,自动同步到每个人的 Todo 列表。
会后随时查看,随时复盘。
文档记录,永不丢失遗忘。
一个是现在总的治愈人数已经超过死亡人数接近三倍,而且治愈人数的每日增长速度已经远超过死亡人数,比如今天的治愈人数就已经是死亡人数的大约 10 倍(891:90)。而且现在疫苗已经投入临床试验,相信接下来的治愈数据的增长液会越来越快。
新增的确诊和疑似人数出现缓和和下降迹象,至少从最近四天的数据上来看,能看出新增数量整体呈现下降的态势,今天刚刚也有新闻报道说全国除湖北外其他省份每日报告的确诊病例数从 2 月 3 日 890 例下降到 2 月 8 日的 509 例,下降幅度达到 42.8%,这表明各地联防联控机制以及严格管理等防控措施正在发挥作用。希望前几天数据最高的点,就是那个拐点吧。
波兰、丹麦
法国、西班牙
1 月 19 日,也门西部一个军事训练营遭遇袭击,造成数十名也门政府军士兵死亡,至少 100 人受伤,胡塞武装在马里布市发动了大规模伤亡袭击,命令也门军队必须保持高度戒备,做好战斗准备。 
东非近期爆发蝗灾,这被称为 70 年来最严重的沙漠蝗灾,其中肯尼亚受灾最为严重,数亿只蝗虫在肯尼亚境内肆虐。 据联合国估计此次蝗虫数量达 3600 亿只,且数量可能在数月后暴增 500 倍。非常令人惊恐的是沙漠蝗群一天内可以吃掉能养活 2500 人的粮食,这也令当地出现了严重的粮食危机。蝗群密度一般达到每平方公里 1.5 亿只,蝗群一天可以随风飞行 100 至 150 公里,破坏范围及力量惊人。  联合国粮食及农业组织已经发出警告,蝗灾将会造成近年来罕见的粮食危机,1900 万人将面临危及生命的饥荒。 这个确实非常严重的,一些更详细的报道大家可以了解澎湃新闻报道的视频:https://www.thepaper.cn/newsDetail_forward_5758503,真的难以想象。
联合国粮食及农业组织已经发出警告,蝗灾将会造成近年来罕见的粮食危机,1900 万人将面临危及生命的饥荒。 这个确实非常严重的,一些更详细的报道大家可以了解澎湃新闻报道的视频:https://www.thepaper.cn/newsDetail_forward_5758503,真的难以想象。
总的来说,全世界的 2020 开局的确可以说是不怎么太平。仔细想想,这些现象的发生有天灾,有人祸。除了一些政治上的问题,这些灾难其实来源于人们对大自然的过渡攫取,或者说是对野生动物的滥杀和捕食。 多难兴邦,天灾无情人有情。在大自然的面前,我们显得非常渺小,在灾难的面前,我们都是受害者。这时候就需要我们团结一心,站在一个战线上去把这些困难渡过去,而不是在这个节骨眼上发国难财,造谣传谣。像我们之前非典、汶川地震一样,众志成城,再难我们也能挺过去的。 相信我们的国家,相信世界的人们。 加油武汉,加油中国,加油全世界!
本文选题和主要参考来源:2020 年只过去了一个月,全世界正在发生什么?https://mp.weixin.qq.com/s/V1iioQsuYITpFfRijZkQHw
卫健委:全国除湖北外其他省份确诊病例下降超 40% http://news.sina.com.cn/c/2020-02-09/doc-iimxxstf0048640.shtml
美国 4 个月近 2000 万人感染流感 今年或是 10 年来最严重 https://www.codingsky.com/news/2020-02-08/11567.html
Weekly U.S. Influenza Surveillance Report https://www.cdc.gov/flu/weekly/index.htm#ILIActivityMap
澳洲遭十年最大暴雨,悉尼全力应对洪水爆发 https://new.qq.com/rain/a/20200209A06URA
巴西遭创纪录暴雨肆虐 泥石流冲毁房屋 http://www.chinanews.com/m/tp/hd/2020/0126/134972.shtml
也门政府军遭胡塞武装导弹袭击至少 40 人死亡 http://www.xinhuanet.com/mil/2020-01/19/c_1210444134.htm
苏丹安全部门和军方在喀土穆机场附近激烈对峙 https://news.sina.cn/gj/2020-01-15/detail-iihnzhha2484546.d.html
67 人死亡 1 人失踪 印尼洪水灾情严重 http://news.cri.cn/20200107/235b849d-523f-b512-c6d4-4feacd8347f4.html
东非遭 70 年来最严重蝗灾,情况或将恶化 https://www.thepaper.cn/newsDetail_forward_5758503
做爬虫的小伙伴可能听说过 Splash,它可以提供动态页面渲染服务,如果我们要爬的某些页面是 JavaScript 渲染而成的,此时我们直接用 requests 或 Scrapy 来爬是没法直接爬到的,此时我们可以借助于 Splash 来帮我们把 JavaScript 渲染后的真实页面结果拿下来。 不过 Splash 在大批量爬虫使用的时候坑不少,Splash 可能用着用着可能就内存炸了,如果只是单纯启 Docker 服务又不好 Scale,另外也不方便当前服务的使用状态,比如内存占用、CPU 消耗等等。 最近把 Splash 迁移到了 Kubernetes 上面,正好上面的问题就一带解决了。 我们既可以方便地扩容,又可以设置超额重启,又可以方便地观察到当前服务使用情况。 下面简单记录一下我把 Splash 迁移到 Kubernetes 上面的过程,真的迁移过来之后省了很多麻烦,推荐大家也可以试试。 好,下面正式开始介绍。
首先,我们需要有一个 Kubernetes 集群,可以自己搭建,也可以使用 Minikube 或者用阿里云、腾讯云、Azure 等服务商直接提供的 Kubernetes 服务。 另外我们需要能使用 kubectl 连接和控制当前的集群,同时需要安装好 helm 并配置好 stable 版本的 Charts,在这里我使用的是 Helm 2.x。 在这里列一些参考资料:
搭建 Kubernetes 集群:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
Minikube:https://kubernetes.io/zh/docs/setup/learning-environment/minikube/
Helm V2 安装和使用:https://v2.helm.sh/docs/
Charts:https://github.com/helm/charts
上面的内容准备就绪之后,我们就可以开始 Kubernetes 搭建 Splash 服务的流程了。
创建 NameSpace
创建 Service
创建 Deployment
安装 Ingress Controller
配置域名解析
配置 Authentication
配置 HTTPS
上面就是本节所要介绍的基本内容,下面我们开始吧。
创建 NameSpace
首先我们将 Splash 安装在一个独立的 Namespace 下面,名字就叫做 splash 吧。 yaml 内容如下:
创建 Deployment
接下来,就是最关键的了,我们使用 scrapinghub/splash 这个 Docker 镜像来创建一个 Deployment,yaml 文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: splash
name: splash
namespace: splash
spec:
replicas: 3
selector:
matchLabels:
app: splash
revisionHistoryLimit: 1
strategy: {}
template:
metadata:
labels:
app: splash
spec:
containers:
- image: scrapinghub/splash
name: splash
ports:
- containerPort: 8050
resources:
requests:
memory: "1Gi"
cpu: "1"
limits:
memory: "4Gi"
cpu: "4"
restartPolicy: Always
status: {}
metadata.labels:这里需要和 Service 里面的 selector 对应起来。spec.template.spec.containers[]:这里声明 splash 的镜像,用的是 latest 镜像 scrapinghub/splash;端口地址用的 8050;restartPolicy 使用的是 Always,这样 Splash 如果崩溃了会自动重启;resources 设置了使用的内存和 CPU 的请求和限制值,这里大家可以根据机器和爬取需求自行修改。spec.replicas:运行的实例个数,这里设置为了 3,这样就会启动 3 个 Splash ,Service 会对其负载均衡。好了,写了上面三个 yaml,我们可以将其合并到一个 yaml 文件里面,如 deployment.yml,然后执行:
这里我们将镜像修改了一下,避免国内 Kubernetes 无法拉取镜像的问题。 OK,安装好了之后,可以看到 Ingress Controller 就安装成功了。
域名解析就好配置了,直接将域名配置到 Ingress Controller Service 的 External IP 上面即可。 
配置 Authentication
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: ingress-splash
namespace: splash
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: basic-auth
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required'
spec:
rules:
- host: <domain>
http:
paths:
- backend:
serviceName: splash
servicePort: 8050
path: /
HTTPS
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: ingress-splash
namespace: splash
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: basic-auth
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required'
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
tls:
- hosts:
- <domain>
secretName: tls-splash
rules:
- host: <domain>
http:
paths:
- backend:
serviceName: splash
servicePort: 8050
path: /
2022 2048 ADSL API Ajax Bootstrap Bug CDN CQC CSS CSS 反爬虫 CV ChatGPT Cookie Django Eclipse Elasticsearch FTP Git GitHub HTML5 HTTP Hexo Hook IP IT JSON JSP JavaScript K8s LOGO Linux Luma MIUI Markdown Midjourney MongoDB MySQL Mysql NBA Nexior OCR OpenCV PHP PPT PS Pathlib PhantomJS Playwright Python Python 爬虫 Python3 Python3爬虫教程 Pythonic Python爬虫 Python爬虫书 Python爬虫教程 QQ RabbitMQ ReCAPTCHA Redis SAE SSH SVG Scrapy-redis Scrapy分布式 Selenium Session Shell Suno TKE TXT Terminal Ubuntu VS Code Vercel Vs Code Vue Web Webpack Web网页 Windows Winpcap WordPress XPath Youtube acedata aiohttp android ansible api chatgpt cocos2d-x dummy change e6 fitvids git json js逆向 kubernetes

 具体的流程可以参考上面的流程图:首先是 fork 一个仓库,然后拉去请求 后 clone 到本地,然后编辑更改。后推送到远程仓库(这里的克隆操作就省略了,具体的可以看上面)
具体的流程可以参考上面的流程图:首先是 fork 一个仓库,然后拉去请求 后 clone 到本地,然后编辑更改。后推送到远程仓库(这里的克隆操作就省略了,具体的可以看上面) 

 发送即可完成。 然后接收者根据流程图步骤 6 开始操作即可
发送即可完成。 然后接收者根据流程图步骤 6 开始操作即可


 Ubuntu:
Ubuntu: 仔细经过上述步骤即可进入本次加密的源码详情页
仔细经过上述步骤即可进入本次加密的源码详情页 
 搜索 sign 参数,得知本页面有 15 个 sign,筛选排查过后可得知以下位置为 sign 等参数,赋值加密过程 为什么会大概确定是此处呢? 理由一:var 声明赋值 理由二:md5() 为什么深信此处呢?
搜索 sign 参数,得知本页面有 15 个 sign,筛选排查过后可得知以下位置为 sign 等参数,赋值加密过程 为什么会大概确定是此处呢? 理由一:var 声明赋值 理由二:md5() 为什么深信此处呢? 根据其语法可知,Javascript
根据其语法可知,Javascript 这里提示几点可能用到的东西:
这里提示几点可能用到的东西: 这里就能实时可视化展示出来错误率了,更多的一些配置可以自行修改这些表达式进行定制。 最后我配置成的一些监控面板如下所示:
这里就能实时可视化展示出来错误率了,更多的一些配置可以自行修改这些表达式进行定制。 最后我配置成的一些监控面板如下所示:  这样我要是什么时候想看 Service 接口的情况,随时上来看就好了。
这样我要是什么时候想看 Service 接口的情况,随时上来看就好了。


 大家可以看到全站的内容都变成灰色了,包括按钮、图片等等。这时候我们可能会好奇这是怎么做到的呢? 有人会以为所有的内容都统一换了一个 CSS 样式,图片也全换成灰色的了,按钮等样式也统一换成了灰色样式。但你想想这个成本也太高了,而且万一某个控件忘记加灰色样式了岂不是太突兀了。 其实,解决方案很简单,只需要几行代码就能搞定了。
大家可以看到全站的内容都变成灰色了,包括按钮、图片等等。这时候我们可能会好奇这是怎么做到的呢? 有人会以为所有的内容都统一换了一个 CSS 样式,图片也全换成灰色的了,按钮等样式也统一换成了灰色样式。但你想想这个成本也太高了,而且万一某个控件忘记加灰色样式了岂不是太突兀了。 其实,解决方案很简单,只需要几行代码就能搞定了。 其 CSS 内容为:
其 CSS 内容为: 点了之后就会提示选择哪个远程服务器,选了之后,下方 Terminal 就弹出来了,和普通的 SSH Shell 一模一样。
点了之后就会提示选择哪个远程服务器,选了之后,下方 Terminal 就弹出来了,和普通的 SSH Shell 一模一样。  OK,接下来要构建镜像,我只需要运行对应的 docker-compose 命令就好了,速度瞬间就上来了,我再也不用看着龟速的下拉速度而发愁了,而不用担心本地机器的资源消耗了。
OK,接下来要构建镜像,我只需要运行对应的 docker-compose 命令就好了,速度瞬间就上来了,我再也不用看着龟速的下拉速度而发愁了,而不用担心本地机器的资源消耗了。  OK,美滋滋。 构建完了运行之后,直接远程访问就好了。
OK,美滋滋。 构建完了运行之后,直接远程访问就好了。 「Pocket」这个软件有一个不错的特性,那就是跨平台,我可以在浏览器、Mac、iPhone、iPad 上使用,看到不错的网站,调出插件或者点击「分享到 Pocket」就可以存进去了,这样就解决了多平台同步问题,另外 「Pocket」还能设置一些标签等等,然后每周或定期我再翻出来整理整理。 说实话,我用「Pocket」好几年了,但总觉得一直达不到我心中完美的标准,怎么说呢?下面总结一下:
「Pocket」这个软件有一个不错的特性,那就是跨平台,我可以在浏览器、Mac、iPhone、iPad 上使用,看到不错的网站,调出插件或者点击「分享到 Pocket」就可以存进去了,这样就解决了多平台同步问题,另外 「Pocket」还能设置一些标签等等,然后每周或定期我再翻出来整理整理。 说实话,我用「Pocket」好几年了,但总觉得一直达不到我心中完美的标准,怎么说呢?下面总结一下: 哎,一眼难尽啊,左边浓浓的拟物化风格,右边自作聪明出了个阅读模式,也就是自动提取正文内容,结果把文章格式整的这么乱。
哎,一眼难尽啊,左边浓浓的拟物化风格,右边自作聪明出了个阅读模式,也就是自动提取正文内容,结果把文章格式整的这么乱。 所以说,这软件的界面、操作和功能,只能说我不喜欢。不喜欢就不要将就,我将就了这么久,最后还是要放弃它。
所以说,这软件的界面、操作和功能,只能说我不喜欢。不喜欢就不要将就,我将就了这么久,最后还是要放弃它。 然后 15 分钟过后,大家会针对大家疑虑的点进行讨论。 注意,由于有了 Comments,大家就知道一共有多少需要讨论的点,这个会还剩余多久,每个 Comment 可以讨论多长时间,这样又避免了开会时间无节制的问题。 然后还有一个重要的点,就是每讨论完一个 Comment,就在对应的地方写上解决方案或者附上 Todo List,即具体的实施措施,做到当场讨论问题、当场提出解决方案、当场分配任务计划。 OK,然后整个会就很有目标地开完了,很有侧重点,而且大家都清除的就不需要讨论了。 另外还有一个优点就是,每个人都可以提 Comments,这样每个人都会感到极强的参与感,再也不会出现会上一言不发事不关己高高挂起的状态了。
然后 15 分钟过后,大家会针对大家疑虑的点进行讨论。 注意,由于有了 Comments,大家就知道一共有多少需要讨论的点,这个会还剩余多久,每个 Comment 可以讨论多长时间,这样又避免了开会时间无节制的问题。 然后还有一个重要的点,就是每讨论完一个 Comment,就在对应的地方写上解决方案或者附上 Todo List,即具体的实施措施,做到当场讨论问题、当场提出解决方案、当场分配任务计划。 OK,然后整个会就很有目标地开完了,很有侧重点,而且大家都清除的就不需要讨论了。 另外还有一个优点就是,每个人都可以提 Comments,这样每个人都会感到极强的参与感,再也不会出现会上一言不发事不关己高高挂起的状态了。 截止今天(2 月 9 日)晚上 9 点,全国确诊病例达到 37289 例,疑似病例 28942 例,每天还以好几千的数量增加,估计明天早上能突破 4 万。 全国 31 个省区均早已经启动了一级响应,这在过去是从未有过的,随着病毒的传播蔓延,事态的严重性远远超出人们最大胆的想象。现在国家正在举全国之力支援灾区,前线的医疗人员一直在全力以赴救治患者。全国各个地区也在采取可以说是历史上最严格的防疫措施,全国范围内的商场、餐厅、娱乐场所几乎都被关停,各家各户的居民也都在家隔离,企业也延迟复工或者到现在还有很多企业都没有正式复工,口罩物资都已经全网脱销,一罩难求。但没有办法,在这个非常时刻,只要我们每个人都尽上自己的所能,相信疫情肯定会慢慢控制下来,请相信我们的国家。 观察了几天,从数据上来看,可能有这么两个好消息:
截止今天(2 月 9 日)晚上 9 点,全国确诊病例达到 37289 例,疑似病例 28942 例,每天还以好几千的数量增加,估计明天早上能突破 4 万。 全国 31 个省区均早已经启动了一级响应,这在过去是从未有过的,随着病毒的传播蔓延,事态的严重性远远超出人们最大胆的想象。现在国家正在举全国之力支援灾区,前线的医疗人员一直在全力以赴救治患者。全国各个地区也在采取可以说是历史上最严格的防疫措施,全国范围内的商场、餐厅、娱乐场所几乎都被关停,各家各户的居民也都在家隔离,企业也延迟复工或者到现在还有很多企业都没有正式复工,口罩物资都已经全网脱销,一罩难求。但没有办法,在这个非常时刻,只要我们每个人都尽上自己的所能,相信疫情肯定会慢慢控制下来,请相信我们的国家。 观察了几天,从数据上来看,可能有这么两个好消息: 
 CDC 称,在其流感活动地图上,美国大部分地区为深红色,表明「流感样疾病」活动水平达到最高级。由于美国的流感季还要持续一段时间,因此这一数据可能会继续上升。从地区上看,目前全美 50 个州里,有 48 个州出现流感疫情,其中 32 个州流感活动水平维持高位,人口稠密的纽约、华盛顿和加州无一幸免,纷纷中招。此次流感季将是 10 年来美国最严重的流感季之一,2019 - 2020 流感季中,美国 1900 万人感染流感,至少 1 万人死亡,包括 68 名儿童。预计流感季将持续至 5 月,而 2 月是高峰期。 我有几个亲戚朋友现在就住在美国,因为流感的问题,每天他们也是和我们一样,待在家里不敢出门,同样体会出来了 ”隔离“ 的滋味。
CDC 称,在其流感活动地图上,美国大部分地区为深红色,表明「流感样疾病」活动水平达到最高级。由于美国的流感季还要持续一段时间,因此这一数据可能会继续上升。从地区上看,目前全美 50 个州里,有 48 个州出现流感疫情,其中 32 个州流感活动水平维持高位,人口稠密的纽约、华盛顿和加州无一幸免,纷纷中招。此次流感季将是 10 年来美国最严重的流感季之一,2019 - 2020 流感季中,美国 1900 万人感染流感,至少 1 万人死亡,包括 68 名儿童。预计流感季将持续至 5 月,而 2 月是高峰期。 我有几个亲戚朋友现在就住在美国,因为流感的问题,每天他们也是和我们一样,待在家里不敢出门,同样体会出来了 ”隔离“ 的滋味。 这场火,不仅造成人命伤亡及经济损失,也对自然生态带来毁灭性破坏,使数亿动物遭遇灭顶之灾。已有近 5 亿只动物死于澳洲山火,并据相关报道显示考拉或将功能性灭绝。悉尼大学发布报告,全国约有 10 亿动物被大火波及,其中仅在澳大利亚袋鼠岛的大火中就有超 2 万只考拉死亡,考拉将被列为濒危动物。澳大利亚全境被烧毁的森林面积约 1120 万 公顷,而去年震惊世界的亚马孙雨林大火烧毁森林面积才约 180 万公顷。此外,有 1400 多公里的海岸线都在燃烧,相当从东北烧到了江浙沪。 慢慢地,前几天,山火逐渐逼近了堪培拉。1 月 31 日,因为山火的步步紧逼,澳大利亚政府宣布堪培拉进入紧急状态,这是自 2003 年山火危机之后 17 年以来,堪培拉首次进入紧急状态。2 月 2 日整天,堪培拉均处于高度戒备状态。堪培拉和周边地区的气温一度超过 42 摄氏度。 当时堪培拉就是这么一个状态:
这场火,不仅造成人命伤亡及经济损失,也对自然生态带来毁灭性破坏,使数亿动物遭遇灭顶之灾。已有近 5 亿只动物死于澳洲山火,并据相关报道显示考拉或将功能性灭绝。悉尼大学发布报告,全国约有 10 亿动物被大火波及,其中仅在澳大利亚袋鼠岛的大火中就有超 2 万只考拉死亡,考拉将被列为濒危动物。澳大利亚全境被烧毁的森林面积约 1120 万 公顷,而去年震惊世界的亚马孙雨林大火烧毁森林面积才约 180 万公顷。此外,有 1400 多公里的海岸线都在燃烧,相当从东北烧到了江浙沪。 慢慢地,前几天,山火逐渐逼近了堪培拉。1 月 31 日,因为山火的步步紧逼,澳大利亚政府宣布堪培拉进入紧急状态,这是自 2003 年山火危机之后 17 年以来,堪培拉首次进入紧急状态。2 月 2 日整天,堪培拉均处于高度戒备状态。堪培拉和周边地区的气温一度超过 42 摄氏度。 当时堪培拉就是这么一个状态:  其他的地区山火基本是这么一个状态:
其他的地区山火基本是这么一个状态:  以及那些被烧死的无辜的动物们:
以及那些被烧死的无辜的动物们:  澳大利亚的这场大火也对全球造成了影响。欧洲哥白尼大气监测服务发表数据:澳大利亚已经向大气排放约 4 亿吨二氧化碳,这个数据比全球 116 个二氧化碳排放量最低国家年排放量总和还要高。 不过,就在最近几天,现在澳洲的山火由于一场暴雨的到来,很多地区的火已经灭了。但,这还没完,由于雨过大,洪水又来了。 据《每日邮报》2 月 9 日报道,近日,澳大利亚遭遇了十年来最大降雨,东海岸被大规模破坏,悉尼正在全力应对洪水爆发,火车站都变成了游泳池。澳大利亚气象局预计,在新南威尔士州北部的一些气象站在 48 小时内录得超过 300 毫米的降雨后,降雨将持续到周日。 据报道,周六,在新南威尔士州北部,67 岁的吉尔·萨瑟兰和她 30 岁的侄女汉娜驱车前往位于新南威尔士州北部河流地区的宁宾,途中他们穿过了一条被洪水淹没的道路。然而,他们很快就失去了对汽车的控制,车子灌满了水,沉了下去,完全从视线中消失了。
澳大利亚的这场大火也对全球造成了影响。欧洲哥白尼大气监测服务发表数据:澳大利亚已经向大气排放约 4 亿吨二氧化碳,这个数据比全球 116 个二氧化碳排放量最低国家年排放量总和还要高。 不过,就在最近几天,现在澳洲的山火由于一场暴雨的到来,很多地区的火已经灭了。但,这还没完,由于雨过大,洪水又来了。 据《每日邮报》2 月 9 日报道,近日,澳大利亚遭遇了十年来最大降雨,东海岸被大规模破坏,悉尼正在全力应对洪水爆发,火车站都变成了游泳池。澳大利亚气象局预计,在新南威尔士州北部的一些气象站在 48 小时内录得超过 300 毫米的降雨后,降雨将持续到周日。 据报道,周六,在新南威尔士州北部,67 岁的吉尔·萨瑟兰和她 30 岁的侄女汉娜驱车前往位于新南威尔士州北部河流地区的宁宾,途中他们穿过了一条被洪水淹没的道路。然而,他们很快就失去了对汽车的控制,车子灌满了水,沉了下去,完全从视线中消失了。  但好在,大火已经基本停了,但愿这次洪水也能尽快过去,祝好!
但好在,大火已经基本停了,但愿这次洪水也能尽快过去,祝好! 军队现已对山区的村镇与交通设施展开全力救助,巴西政府也声称将努力建立一个全国性的灾害预防和早期预警系统。
军队现已对山区的村镇与交通设施展开全力救助,巴西政府也声称将努力建立一个全国性的灾害预防和早期预警系统。



 军方戒严了城区主要街道,喀土穆国际机场已关闭。中国驻苏丹使馆发出安全警告,提醒中国公民不要靠近机场区域。
军方戒严了城区主要街道,喀土穆国际机场已关闭。中国驻苏丹使馆发出安全警告,提醒中国公民不要靠近机场区域。 印尼国家抗灾署发言人阿古斯在一份声明中说,截至当地时间 6 日下午,灾害还造成 1 人失踪,另有 3.6 万人居住在临时避难所。由于强降雨引发洪灾、山体滑坡等灾害,雅加达周边的 12 个县市已陆续宣布进入为期一到两周的紧急状态,以便救援和物资运输工作展开。
印尼国家抗灾署发言人阿古斯在一份声明中说,截至当地时间 6 日下午,灾害还造成 1 人失踪,另有 3.6 万人居住在临时避难所。由于强降雨引发洪灾、山体滑坡等灾害,雅加达周边的 12 个县市已陆续宣布进入为期一到两周的紧急状态,以便救援和物资运输工作展开。 登录完成之后就可以看到 Splash 的界面了,如图所示。
登录完成之后就可以看到 Splash 的界面了,如图所示。 
推荐文章
|
|
聪明的电影票 · PS怎么把一个图片放到另一个图片里?-即时设计 9 月前 |