

一、爬取目标
本次爬取的目标页面是,网易云音乐的四个排行榜:
https://music.163.com/#/discover/toplist
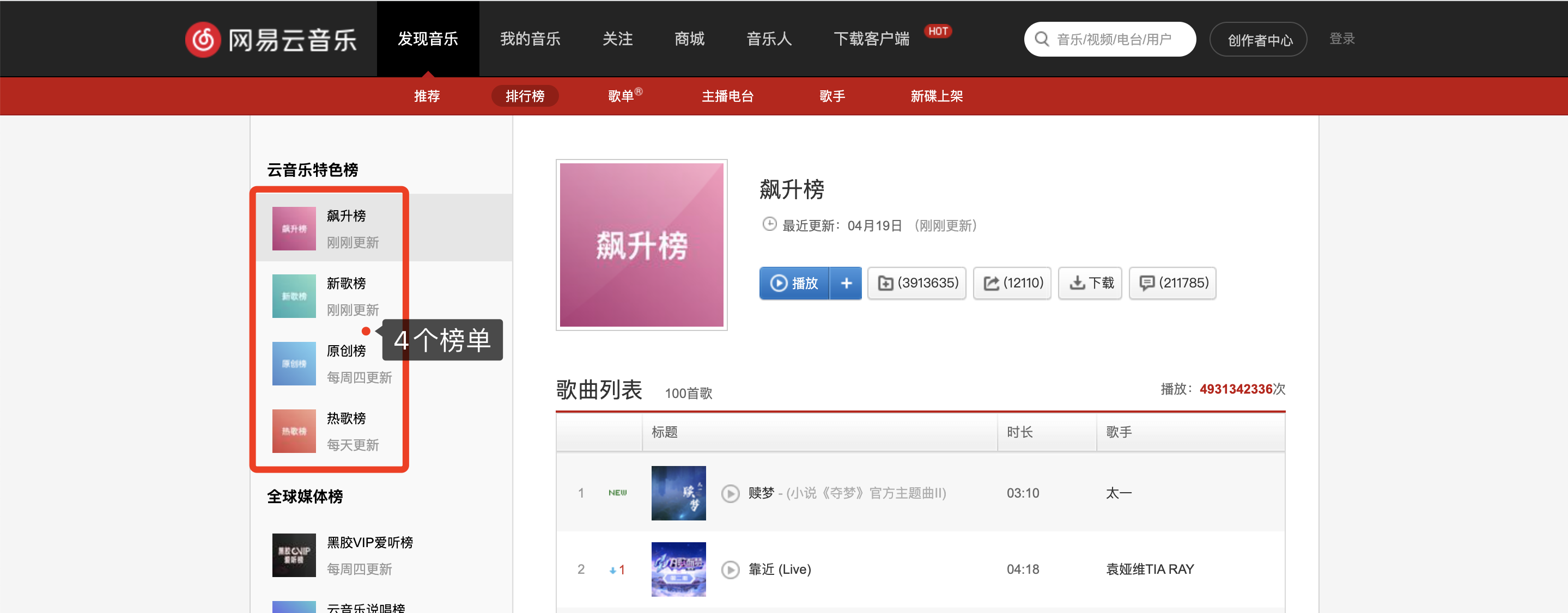
本次分析,依然从网页接口入手,按F12进入开发者模式:
刷新一下页面,在右侧可以看到每首歌曲的数据,所以就对这个目标链接发送请求。
二、代码分解
首先,导入需要用到的库:
然后,定义一个请求地址:
然后,定义一个请求地址:
然后,还需要定义请求参数,params,这也是这个爬虫的关键,经过分析,4个榜单的参数都不一样,以飙升榜为例:
![]()
请求参数

下面是发送POST请求:
后面,就是解析每个字段信息了,不再赘述。
最后,保存Excel数据:
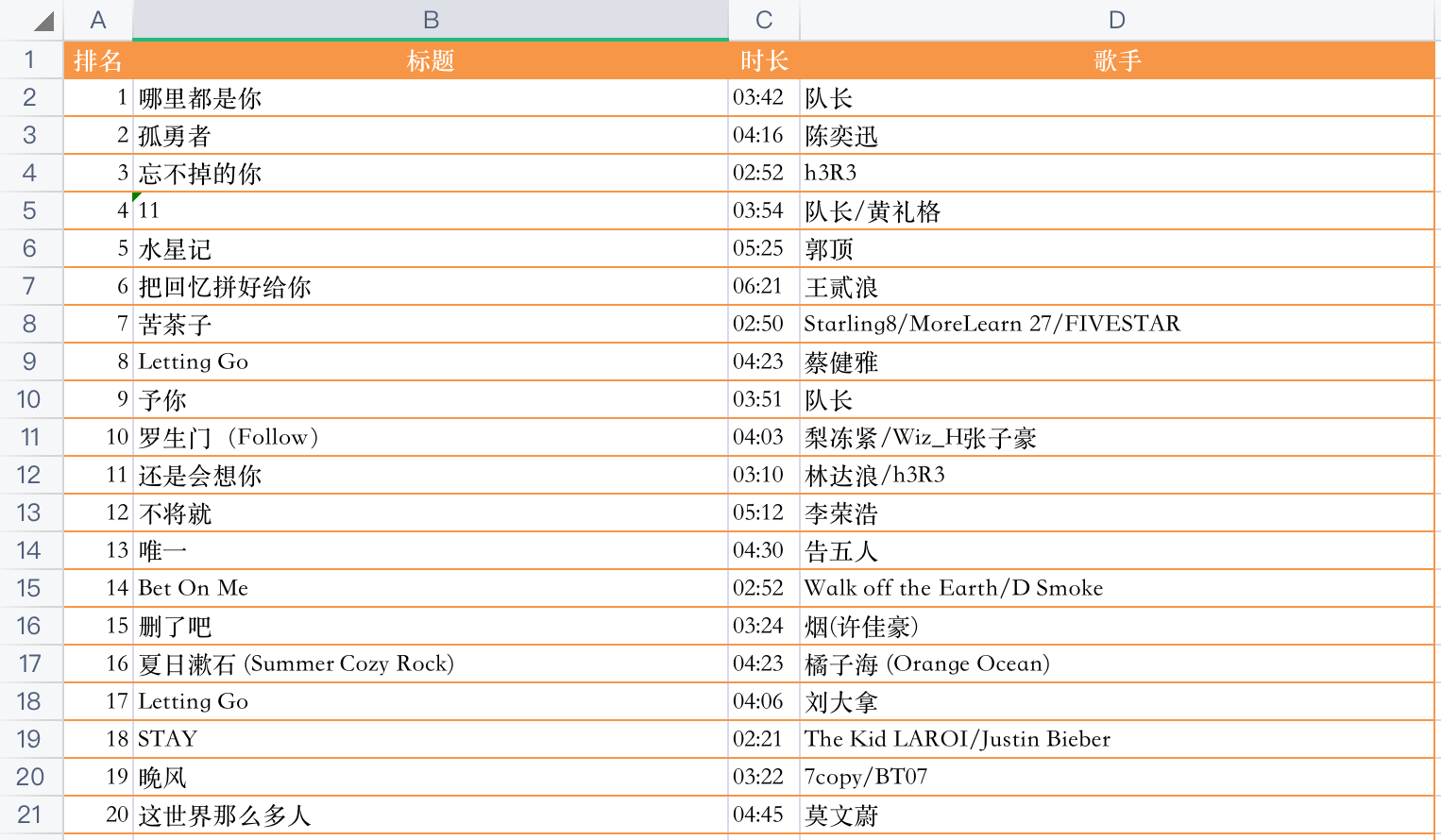
看下结果,以热歌榜前20名为例:
![]()
爬取结果
三、同步视频演示
三、同步视频演示
视频演示爬取过程:
![]()

四、获取python源码
四、获取python源码
爱学习的小伙伴,本次案例的完整python源码及4个榜单Excel数据,已上传微信公众号“
老男孩的平凡之路
”,后台回复“
爬云音乐
”即可获取。
![]()

我是
@马哥python说
,关注我,持续分享python源码干货!