

Azure OpenAI 入门教程 - LangChain 篇 :实战 - 构建企业内部知识库问答机器人 - 持久化向量存储

在上一篇中,我们实现了一个基础的企业内部知识库问答机器人。其中用到了 LangChain的文档加载器,文本切割器,向量存储,问答链。
但按照当时的写法,向量化后的信息是临时存入到 Chroma 的,这个时候你每次都需要进行一次 Embeddings ,这样写个 demo 还行,但肯定没法作为生产项目。
所以今天我们就先来解决这个问题,一起看下向量化后的数据如何进行持久化保存。
向量数据库
要想持久化保存就必须借用向量数据库,目前市面上最常用的向量数据库是 Chroma 和 Pinecone。
Chroma
Chroma是我们上一期用到的,它是一个本地向量数据库,虽然我们上期将向量化后的结果临时存到内存当中了,但实际上我们是可以利用 Chroma 将向量化后的信息存储到本地的一个目录中,从而实现持久化保存的。
要想本地存储,我们需要在存储时设置 persist_directory ,来指定存储的目录。
并通过调用 .persist 方法来实现存储。


等我们需要加载本地目录中的向量数据时,需要再次调用 Chroma ,传递参数 persist_directory 来指定从哪个本地目录进行读取,并通过 embedding_function 来指定向量化的方法。


Pinecone
Pinecone 是一个云端的向量数据库,可以高性能存储和查询向量信息,并支持多种相似度匹配算法来满足不同场景需求。也支持动态添加和删除向量,批量导入导出向量。
可以免费使用,但免费版本的索引如果超过7天没被使用会被自动删除。
要想使用 Pinecone ,我们需要先前往官网 http:// app.pinecone.io 进行注册
账户登录成功后,就可以去创建向量数据库,这一步也是在云端操作的。
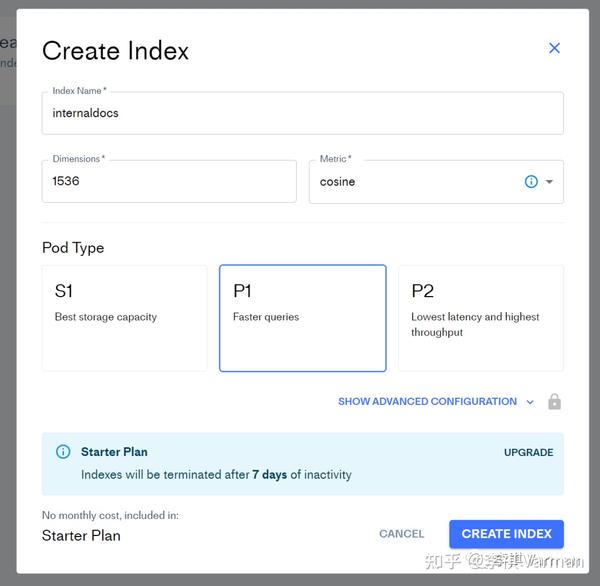
Index Name:索引的名字,我们按照需求场景写一个就行
Dimensions:指向量维度,如果你使用的是 OpenAI 进行 Embedding ,那么这里要填写 OpenAI Embeddings 的 Output Dimensions 为1536. 这里的1536 表示向量是由 1536个浮点数组成的列表
Metric:是指用于计算向量之间距离的度量方式,这里设置为cosine,表示用余弦相似度来计算2个向量之间的距离。
Pod Type:是用来配置存储容量和吞吐量的。

在云端创建好 Pinecone 数据库后,我们就可以回到代码的部分。
先安装 Pinecone

然后导入 Pinecone


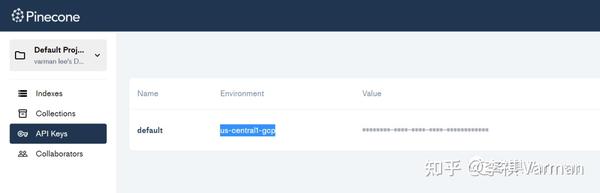
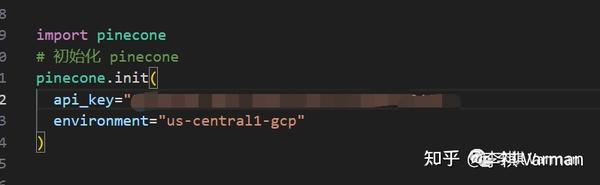
初始化时,需要拿到 api key 和 envionrment。在Pinecone 界面可以直接查看。


这里需要通过 Pinecone.from_texts 将文本进行向量化存储,需要指定文本,Embeddings 和 index_name。


执行完上一步操作,就已经将向量化后的结果持久化存储到云端的 Pinecone 了,后面我们想要加载数据的时候,需要调用Pinecone.from_existing_index 从指定的 index_name 中拿到向量化的信息。


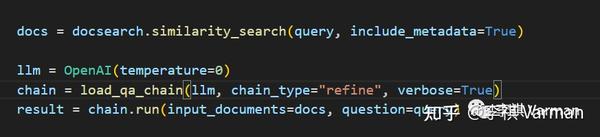
拿到信息以后,你可以用 Pinecone 提供的向量搜索 similarity_search 进行向量搜索,也可以用原本的向量搜索方式,再使用 Langchain 的load_qa_chain 进行问答。

总结
今天主要介绍的是持久化向量存储的方式,在我们实现企业内部知识库的时候,必然会用到持久化向量存储。
这时候就需要选择合适的向量数据库,调用对应的向量存储代码,就能实现持久化向量存储。
并且一些云端的向量数据库,都专门针对向量搜索进行过优化,可以帮助我们以更高效稳定的方式进行向量搜索。
END
我是李祺,微软 Power Platform 方向 MVP ,2014 年进入开发领域,了解微软云全系产品。2020 年以来专注在 Power Platform 领域,曾为微软和多家客户提供售前、培训和实施服务,2023年进入 Azure OpenAI 相关领域。为普及产品知识,帮助国内用户快速上手。从 2021 年开始创建个人公众号和知乎【李祺 Varman】,目前已提供 200+ Power Platform 中文学习资料,并在持续更新 ChatGPT 和 Azure OpenAI 相关内容,欢迎大家进入公众号菜单【问答社区】进行问题咨询。
