link管理
链接快照平台
- 输入网页链接,自动生成快照
- 标签化管理网页链接
相关文章推荐

|
暴躁的稀饭 · 【青春】-線上看(2023)~4K完整版 ...· 4 月前 · |
|
|
知识渊博的眼镜 · spring事务未提交是什么原因 • ...· 6 月前 · |
|
|
没有腹肌的电影票 · 5月份国民经济延续回升向好态势 ...· 8 月前 · |
|
|
爱跑步的松鼠 · 即时通讯服务器端口是什么 • Worktile社区· 8 月前 · |

After learning about ROT47, I was
testing
with ROT128 (full ASCII table).
This is my code:
Results when running the code above:

It can be seen that the decoding results are incorrect.
After that, I tried with ROT47, it could still decode correctly.
Is there something wrong in the above code, but as I noticed, ROT47 did not encode non-ASCII characters? How do I need to fix it so that the above `rot128` method can decode correctly?
This is my code:
Results when running the code above:
It can be seen that the decoding results are incorrect.
After that, I tried with ROT47, it could still decode correctly.
Is there something wrong in the above code, but as I noticed, ROT47 did not encode non-ASCII characters? How do I need to fix it so that the above `rot128` method can decode correctly?
What's ROT128? How is it defined to work?
What happens when you use ROT128 on char s with a value outwith the range 0...0xff(inclusive)? If you use ROT128 on a supplementary character, does that remain a supplementary character? Does ROT128 change both parts of the supplementary character or only one?
What output did you expect? How have you verified the output? What encoding does your terminal support? What OS are you using? What happens if you use a Java® GUI component to display it, e.g. JOptionPane.showMessageDialog(null, test); ?
What happens when you use ROT128 on char s with a value outwith the range 0...0xff(inclusive)? If you use ROT128 on a supplementary character, does that remain a supplementary character? Does ROT128 change both parts of the supplementary character or only one?
What output did you expect? How have you verified the output? What encoding does your terminal support? What OS are you using? What happens if you use a Java® GUI component to display it, e.g. JOptionPane.showMessageDialog(null, test); ?
Another thing, unrelated to your problem. Why are you converting each individual
char
to a
String
before appending it to your string builder? It's absolutely pointless. Just cast the
int
s back to
char
.
Not just that, the parameter name " codePoints " is misleading. You're not passing in code points . You're passing in UTF-16 code units .
Not just that, the parameter name " codePoints " is misleading. You're not passing in code points . You're passing in UTF-16 code units .
Campbell Ritchie wrote:
What's ROT128? How is it defined to work?
Unlike ROT47 that supports 94 printable ASCII characters, ROT128 (informal name) supports full ASCII table.
P/s: The name ROT128 is not made by me, I don't know what its official name is but in some C/C ++ programming documents and books that I "accidentally" read, they call it " ROT128 ".
As defined above, this cipher only shift/rotation of N letters in an alphabet. E.g. one letter is replaced by another (always the same) that is located further (exactly N letters further) in the alphabet. Therefore, it doesn't seem to be affected by external factors as you mentioned.
Rot-N/Rot cipher (for Rotation) is a simple character substitution based on a shift/rotation of N letters in an alphabet. E.g. one letter is replaced by another (always the same) that is located further (exactly N letters further) in the alphabet...
Source: What is Rot cipher? (Definition)Unlike ROT47 that supports 94 printable ASCII characters, ROT128 (informal name) supports full ASCII table.
P/s: The name ROT128 is not made by me, I don't know what its official name is but in some C/C ++ programming documents and books that I "accidentally" read, they call it " ROT128 ".
What happens when you use ROT128 on char s with a value outwith the range 0...0xff(inclusive)? If you use ROT128 on a supplementary character, does that remain a supplementary character? Does ROT128 change both parts of the supplementary character or only one?
What output did you expect? How have you verified the output? What encoding does your terminal support? What OS are you using? What happens if you use a Java® GUI component to display it, e.g. JOptionPane.showMessageDialog(null, test); ?
As defined above, this cipher only shift/rotation of N letters in an alphabet. E.g. one letter is replaced by another (always the same) that is located further (exactly N letters further) in the alphabet. Therefore, it doesn't seem to be affected by external factors as you mentioned.
Stephan van Hulst wrote:
What makes you think it doesn't work?
Maybe you should also print your original input string, before you encode it, and not only the decoded version.
That is my shortcoming, this is the code (that perhaps) you request:
And the result I received:
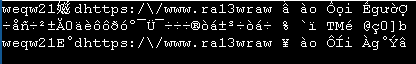
It can be seen that the test string is printed with no errors, then it was encoded, but until the decoding, the string I received was different from the original string.
As I explained to the Campbell on above, this is not an encryption, it is simply is "shift/rotation of N letters in an alphabet".
Maybe you should also print your original input string, before you encode it, and not only the decoded version.
That is my shortcoming, this is the code (that perhaps) you request:
And the result I received:
It can be seen that the test string is printed with no errors, then it was encoded, but until the decoding, the string I received was different from the original string.
As I explained to the Campbell on above, this is not an encryption, it is simply is "shift/rotation of N letters in an alphabet".
Tan Quang wrote:
. . . Source:
What is Rot cipher? (Definition)
You are going to have to work through your algorithm and explain it properly. You are probably rotating by 128 to encode the text. How are you rotating to decode it? What are you rotating? You have characters with a numeric value > 128 , and your algorithm isn't handling them properly.
That link doesn't define ROT128; where did you get that algorithm from?
ASCII only contains 128 different characters.. . . ROT128 (informal name) supports full ASCII table.
None of what you wrote answered my questions, and that your algorithm fails when presented with those “external factors”.. . . it doesn't seem to be affected by external factors as you mentioned.
You are going to have to work through your algorithm and explain it properly. You are probably rotating by 128 to encode the text. How are you rotating to decode it? What are you rotating? You have characters with a numeric value > 128 , and your algorithm isn't handling them properly.
Stephan van Hulst wrote:
Another thing, unrelated to your problem. Why are you converting each individual
char
to a
String
before appending it to your string builder? It's absolutely pointless. Just cast the
int
s back to
char
.
Not just that, the parameter name " codePoints " is misleading. You're not passing in code points . You're passing in UTF-16 code units .
That code I took from here: What is the java equivalent to javascript's String.fromCharCode?
It supports 1 or more character codes at the same time. But it's been a long time since I updated it, but in this case, it has only 1 character.
Thank you for mentioning, I think I will fix it into:
I use Character.toChars because it returns a char[] , while if using Character.toString , it will return a String , this will be quite similar to string concatenation use the "assignment operators." (+=) operator in the loop?!
Not just that, the parameter name " codePoints " is misleading. You're not passing in code points . You're passing in UTF-16 code units .
That code I took from here: What is the java equivalent to javascript's String.fromCharCode?
It supports 1 or more character codes at the same time. But it's been a long time since I updated it, but in this case, it has only 1 character.
Thank you for mentioning, I think I will fix it into:
I use Character.toChars because it returns a char[] , while if using Character.toString , it will return a String , this will be quite similar to string concatenation use the "assignment operators." (+=) operator in the loop?!
Campbell Ritchie wrote:
Please don't edit posts after they have been answered; the changes will go unnoticed and cause confusion. Please post the changes in a new post; I am refusing the changes.
It is also no different than before changing... But, anyway...
It is also no different than before changing... But, anyway...
Campbell Ritchie wrote:
That link doesn't define ROT128; where did you get that algorithm from?
As I explained, it was not my name for it, I searched it on Google: ROT128 cipher
I tried to find the documents that I "accidentally" read, but because I used incognito mode, the whole history of the browser was deleted, these were some documents that I have found again: Applying ROT128 Encryption On ByteArray
ROTate
The main document I use to form the algorithm: Thomas Laebel Madsen
Method of perfomes rotation: rot128.cpp (line 41)
I said: With ROT47 only supports 94 printable ASCII characters, I'm testing with full ASCII tables, not ROT47.
Yes, I have "imagined" somewhere because it was improperly handled with the characters outside the ASCII table, so it didn't decode exactly. And I have also "imagined" the cause of ROT47 that could accurately decode the characters outside the ASCII table simply when encode / decode, it ignored those characters. Probably so...
As I explained, it was not my name for it, I searched it on Google: ROT128 cipher
I tried to find the documents that I "accidentally" read, but because I used incognito mode, the whole history of the browser was deleted, these were some documents that I have found again: Applying ROT128 Encryption On ByteArray
ROTate
The main document I use to form the algorithm: Thomas Laebel Madsen
Method of perfomes rotation: rot128.cpp (line 41)
ASCII only contains 128 different characters.
I said: With ROT47 only supports 94 printable ASCII characters, I'm testing with full ASCII tables, not ROT47.
None of what you wrote answered my questions, and that your algorithm fails when presented with those “external factors”.
You are going to have to work through your algorithm and explain it properly. You are probably rotating by 128 to encode the text. How are you rotating to decode it? What are you rotating? You have characters with a numeric value > 128 , and your algorithm isn't handling them properly.
Yes, I have "imagined" somewhere because it was improperly handled with the characters outside the ASCII table, so it didn't decode exactly. And I have also "imagined" the cause of ROT47 that could accurately decode the characters outside the ASCII table simply when encode / decode, it ignored those characters. Probably so...
Tim Moores wrote:
That string contains characters that are outside the 0-255 range already, so you can't expect this transformation to be reversible. In other words, the resulting string will be different from the original string, so what you're seeing may well be correct.
Yes, thank you for your answer, your answer is what I need. I'm not sure why this error occurred and your answer answered it.
I changed the code to:
The result it printed was correct:

The code above is true to the idea that you want to say?
Yes, thank you for your answer, your answer is what I need. I'm not sure why this error occurred and your answer answered it.
I changed the code to:
The result it printed was correct:
The code above is true to the idea that you want to say?
Nobody can say it's correct, because there is no standardized spec for ROT128.
Who's to say that an implementation is not required to flat out refuse to encode a string that contains characters outside of the accepted character set?
If you're happy with it, you're happy with it. Most of the world probably doesn't have a need for any form of ROT128.
Who's to say that an implementation is not required to flat out refuse to encode a string that contains characters outside of the accepted character set?
If you're happy with it, you're happy with it. Most of the world probably doesn't have a need for any form of ROT128.
ROT47
or
ROTn
in general are the "variations" of
ROT13
,
ROT13
(and
Vigenère cipher
) based on the standard of
Caesar cipher
, so they all rely on the standard specifications of
Caesar cipher
.
Their common point is that it is only in the ASCII character set and does not say anything about handling characters outside the character set. But if you remove it, decoding will not be able to return the original string before encode, so it can only be ignored it.
ROT128 that I'm asking is also, it is still in the ASCII character set. But if you can "transform" it, so that it can work with the UTF-8 , well, we will have a new "variant" (and I welcome you to do that).
Their common point is that it is only in the ASCII character set and does not say anything about handling characters outside the character set. But if you remove it, decoding will not be able to return the original string before encode, so it can only be ignored it.
ROT128 that I'm asking is also, it is still in the ASCII character set. But if you can "transform" it, so that it can work with the UTF-8 , well, we will have a new "variant" (and I welcome you to do that).
Tan Quang wrote:
ROT47
or
ROTn
in general are the "variations" of
ROT13
Wrong. ROT47 may be a well known variant of ROT13 , but there is no standard specification for any " ROTn " in general. You say that ROT128 applies to ASCII. First, as Campbell already pointed out, ASCII contains only 128 characters, so rotating each character by 128 positions just leaves you with the input string. Secondly, even if you meant something like "Latin 1" instead of "ASCII", what's stopping me from defining the domain of ROT128 as the first 256 Unicode emoticons? Now we have two conflicting definitions, but no standard.
Wrong. "Caesar cipher" is a general concept in cryptography, and not a standard. A standard is a description of how to do something exactly. If two parties use the same standard to write their software, their software will behave the same way.
So you made an observation about two different algorithms and decided for yourself that that particular observation should apply to all other ciphers. I can make another observation: Neither ROT13 nor ROT47 operate on control characters. According to your logic, that means this observation should also apply to ROT128.
Well, what if I call my own version ROT128 as well?
Wrong. ROT47 may be a well known variant of ROT13 , but there is no standard specification for any " ROTn " in general. You say that ROT128 applies to ASCII. First, as Campbell already pointed out, ASCII contains only 128 characters, so rotating each character by 128 positions just leaves you with the input string. Secondly, even if you meant something like "Latin 1" instead of "ASCII", what's stopping me from defining the domain of ROT128 as the first 256 Unicode emoticons? Now we have two conflicting definitions, but no standard.
so they all rely on the standard specifications of Caesar cipher .
Wrong. "Caesar cipher" is a general concept in cryptography, and not a standard. A standard is a description of how to do something exactly. If two parties use the same standard to write their software, their software will behave the same way.
Their common point is that it is only in the ASCII character set and does not say anything about handling characters outside the character set.
So you made an observation about two different algorithms and decided for yourself that that particular observation should apply to all other ciphers. I can make another observation: Neither ROT13 nor ROT47 operate on control characters. According to your logic, that means this observation should also apply to ROT128.
But if you can "transform" it, so that it can work with the UTF-8 , well, we will have a new "variant" (and I welcome you to do that).
Well, what if I call my own version ROT128 as well?
Tan Quang wrote:
. . . does not say anything about handling characters outside the character set. . . .
If I use a car for travelling along the river, I have no business complaining if I get wet or drown.
So you are in the realms of behaviour not being specified nor defined. You cannot therefore say that the algorithm is or isn't behaving itself because it is being used for something it is not intended for.
If I use a car for travelling along the river, I have no business complaining if I get wet or drown.
Campbell's JShell wrote:
jshell> "weqw21𡞰dhttps:/\\/www.ra13wraw ấ ào Ổọi ỀgườỢ".chars().filter(i -> i >= 0x100).forEach(i -> System.out.printf("%c ", (char)i))
? ? ấ Ổ ọ Ề ư ờ Ợ
You are lucky to get the algorithm to work that well. You have only had one character mangled by your algorithm.
? ? ấ Ổ ọ Ề ư ờ Ợ
That shows eight characters outwith the range of ASCII and Latin‑1. The first is split into two char s which are supplementary code units, each showing as a ? . If you change chars() to codePoints() , you will only get one ? .
You are lucky to get the algorithm to work that well. You have only had one character mangled by your algorithm.
Stephan van Hulst wrote:
Wrong.
ROT47
may be a well known variant of
ROT13
, but there is no standard specification for any "
ROTn
" in general. You say that
ROT128
applies to ASCII. First, as Campbell already pointed out, ASCII contains only 128 characters, so rotating each character by 128 positions just leaves you with the input string. Secondly, even if you meant something like "Latin 1" instead of "ASCII", what's stopping me from defining the domain of ROT128 as the first 256 Unicode emoticons? Now we have two conflicting definitions, but no standard.
Wrong. "Caesar cipher" is a general concept in cryptography, and not a standard. A standard is a description of how to do something exactly. If two parties use the same standard to write their software, their software will behave the same way.
You're "too strict" with them.
Anyway... You're right, apart from ROT13 and ROT47 are the official names. ROTn , ROT128 ,... are unofficial names, and I also say those names aren't set by me, I use it as other documents calling it. I'm very lazy to name something, that's why I write the code and name them like the purpose I want (like the method fromCharCode above, I take that name from the same method of JavaScript ).
So you made an observation about two different algorithms and decided for yourself that that particular observation should apply to all other ciphers. I can make another observation: Neither ROT13 nor ROT47 operate on control characters. According to your logic, that means this observation should also apply to ROT128.
Yes, I observed on both ROT13 and ROT47 and found that they didn't work (a.k.a ignore) with the characters outside the ASCII character table, and with this ROT128 method, my purpose was still only done with it with ASCII characters but "expanded" than ROT47 so I will still do the same thing as ROT13 and ROT47 : Ignore the characters outside the ASCII character table instead of deleting them.
Well, I said:
1. It is an unofficial name.
2. It is not set by me.
3. It is not registered copyright.
So whatever you want to name it, that's your right.
Wrong. "Caesar cipher" is a general concept in cryptography, and not a standard. A standard is a description of how to do something exactly. If two parties use the same standard to write their software, their software will behave the same way.
You're "too strict" with them.
Anyway... You're right, apart from ROT13 and ROT47 are the official names. ROTn , ROT128 ,... are unofficial names, and I also say those names aren't set by me, I use it as other documents calling it. I'm very lazy to name something, that's why I write the code and name them like the purpose I want (like the method fromCharCode above, I take that name from the same method of JavaScript ).
Their common point is that it is only in the ASCII character set and does not say anything about handling characters outside the character set.
So you made an observation about two different algorithms and decided for yourself that that particular observation should apply to all other ciphers. I can make another observation: Neither ROT13 nor ROT47 operate on control characters. According to your logic, that means this observation should also apply to ROT128.
Yes, I observed on both ROT13 and ROT47 and found that they didn't work (a.k.a ignore) with the characters outside the ASCII character table, and with this ROT128 method, my purpose was still only done with it with ASCII characters but "expanded" than ROT47 so I will still do the same thing as ROT13 and ROT47 : Ignore the characters outside the ASCII character table instead of deleting them.
Well, what if I call my own version ROT128 as well?
Well, I said:
1. It is an unofficial name.
2. It is not set by me.
3. It is not registered copyright.
So whatever you want to name it, that's your right.
Campbell Ritchie wrote:
So you are in the realms of behaviour not being specified nor defined. You cannot therefore say that the algorithm is or isn't behaving itself because it is being used for something it is not intended for.
If I use a car for travelling along the river, I have no business complaining if I get wet or drown.
That shows eight characters outwith the range of ASCII and Latin‑1. The first is split into two char s which are supplementary code units, each showing as a ? . If you change chars() to codePoints() , you will only get one ? .
You are lucky to get the algorithm to work that well. You have only had one character mangled by your algorithm.
Actually, you don't get a ? but a mangled character.
Well, I also realized this problem not long ago after reading this question: What exactly does String.codePointAt do?
Yes, charAt doesn't work in new Unicode characters, instead will have to use codePointAt . But it also can't work with new Unicode characters in a loop. Like this answer , assuming the code will be like this:
In your opinion, what is the solution in the case of a new Unicode character in the loop? If you can say with the way to combine with ROTn as possible.
P/s: Sorry for ignoring your code quote.
If I use a car for travelling along the river, I have no business complaining if I get wet or drown.
That shows eight characters outwith the range of ASCII and Latin‑1. The first is split into two char s which are supplementary code units, each showing as a ? . If you change chars() to codePoints() , you will only get one ? .
You are lucky to get the algorithm to work that well. You have only had one character mangled by your algorithm.
Actually, you don't get a ? but a mangled character.
Well, I also realized this problem not long ago after reading this question: What exactly does String.codePointAt do?
Yes, charAt doesn't work in new Unicode characters, instead will have to use codePointAt . But it also can't work with new Unicode characters in a loop. Like this answer , assuming the code will be like this:
In your opinion, what is the solution in the case of a new Unicode character in the loop? If you can say with the way to combine with ROTn as possible.
P/s: Sorry for ignoring your code quote.
Tan Quang wrote:
. . . You're "too strict" with them.
You want the algorithm to work on supplementary characters, and you have demonstrated it not working correctly. It is for you to correct your code, not for us.
There are a few occupations that are really strict. Airline pilots, for example. And programmers. Both know that a mistake can cost money running into nine digits, or kill people by the hundred. There is no such thing as “too strict” in programming.
You want the algorithm to work on supplementary characters, and you have demonstrated it not working correctly. It is for you to correct your code, not for us.
Yes, you did say that earlier. . . unofficial names . . .
So why are you using it on non‑Latin 1 characters? Either design the algorithm to handle all characters, or restrict its use to 0...0xff(inclusive).Their common point is that it is only in the ASCII character set and does not say anything about handling characters outside the character set. . . .
Tan Quang wrote:
. . . after reading this question:
What exactly does String.codePointAt do?

Have you work4ed out the error in the code you showed with the 💖?
That is a good answer, but you should always start by looking in the Oracle API documentation.
Of course you can use code points in a loop. But there are better ways to iterate something without using a loop.. . . But it also can't work with new Unicode characters in a loop. . . .
Apology accepted. . .
P/s: Sorry for ignoring your code quote.
Have you work4ed out the error in the code you showed with the 💖?
Campbell Ritchie wrote:
There are a few occupations that are really strict. Airline pilots, for example. And programmers. Both know that a mistake can cost money running into nine digits, or kill people by the hundred. There is no such thing as “too strict” in programming.
You want the algorithm to work on supplementary characters, and you have demonstrated it not working correctly. It is for you to correct your code, not for us.
I mean you "too strict" in naming a "variant" without the official name.
Well, that's not forcing you not to use the characters outside the ASCII character table because the ASCII character table is not the only character table. I may not use it but that doesn't mean others don't use it, but to ensure the "rules" of the string after decoding must be the same as the string before encode, with the characters outside the ASCII, I can only ignore it.
P/s: Suppose Caesar and the creators of ROT13 are alive, I also want to know how they will handle modern characters? Will be ignoring or something else?
Yes, I was a little confused between String.charAt and String.codePointAt after reading Oracle's document, so I found that question (mostly I wanted to see examples of differences).
Do you have another way to do this without using a loop? Can you share it with me?
Not really, with the "💖" character as explained in this answer , it is outside the limit of 1 char , it will be equivalent to 2 char . Suppose I only took the high surrogate and ignored low surrogate, (it seems) it will still return the character "💖", but it is "full" or not, I'm not sure, but this is definitely this is a bad idea.
Within the initial framework of this topic, I (initially) simply wanted it to work with char and the characters in the ASCII table. But after that, people pointed out the problem if encountering characters outside the char and the ASCII table - something I didn't (really) thought before.
Anyway, once again, as I told Stephan van Hulst above, I welcome everyone to expand (and comfortably named it like everyone's hobby) for it.
You want the algorithm to work on supplementary characters, and you have demonstrated it not working correctly. It is for you to correct your code, not for us.
I mean you "too strict" in naming a "variant" without the official name.
So why are you using it on non‑Latin 1 characters? Either design the algorithm to handle all characters, or restrict its use to 0...0xff(inclusive).
Well, that's not forcing you not to use the characters outside the ASCII character table because the ASCII character table is not the only character table. I may not use it but that doesn't mean others don't use it, but to ensure the "rules" of the string after decoding must be the same as the string before encode, with the characters outside the ASCII, I can only ignore it.
P/s: Suppose Caesar and the creators of ROT13 are alive, I also want to know how they will handle modern characters? Will be ignoring or something else?
That is a good answer, but you should always start by looking in the Oracle API documentation.
Yes, I was a little confused between String.charAt and String.codePointAt after reading Oracle's document, so I found that question (mostly I wanted to see examples of differences).
Of course you can use code points in a loop. But there are better ways to iterate something without using a loop.
Do you have another way to do this without using a loop? Can you share it with me?
Have you work4ed out the error in the code you showed with the 💖?
Not really, with the "💖" character as explained in this answer , it is outside the limit of 1 char , it will be equivalent to 2 char . Suppose I only took the high surrogate and ignored low surrogate, (it seems) it will still return the character "💖", but it is "full" or not, I'm not sure, but this is definitely this is a bad idea.
Within the initial framework of this topic, I (initially) simply wanted it to work with char and the characters in the ASCII table. But after that, people pointed out the problem if encountering characters outside the char and the ASCII table - something I didn't (really) thought before.
Anyway, once again, as I told Stephan van Hulst above, I welcome everyone to expand (and comfortably named it like everyone's hobby) for it.
Tan Quang wrote:
I mean you "too strict" in naming a "variant" without the official name.
I wasn't saying that you couldn't name your algorithm ROT128.
I said that we couldn't tell you whether your algorithm was correct or not, because there is no standard for ROT128.
No. You can also reject the input. We are simply asking you why you wrote a permissive algorithm instead. I'd like to remind you that "Postel's Law" made the world a worse place.
I don't see how that matters to anything at all. ROT13 is simply undefined for characters other than the basic Latin alphabet. If you asked Julius Caesar what he would do when he wanted to encrypt the Chinese ideograph 𡞰, he might just roll his eyes at you and then march off to conquer another Germanic village.
If one were to actually write a spec for ROT128 , it would be perfectly valid to specify undefined results. It might read something like " ROT128 is defined for the first 256 Unicode code points. The result of applying ROT128 to a string that contains other characters is undefined."
PLEASE stop saying "ASCII". ASCII contains only 128 characters. Applying ROT128 to an ASCII string does nothing at all. You would need to define a ROT64 algorithm for it to be useful with ASCII.
Either refer to an existing 8 bit character set such as "Latin-1", or define your own "ROT128" character set.
I wasn't saying that you couldn't name your algorithm ROT128.
I said that we couldn't tell you whether your algorithm was correct or not, because there is no standard for ROT128.
but to ensure the "rules" of the string after decoding must be the same as the string before encode, with the characters outside the ASCII, I can only ignore it.
No. You can also reject the input. We are simply asking you why you wrote a permissive algorithm instead. I'd like to remind you that "Postel's Law" made the world a worse place.
Suppose Caesar and the creators of ROT13 are alive, I also want to know how they will handle modern characters? Will be ignoring or something else?
I don't see how that matters to anything at all. ROT13 is simply undefined for characters other than the basic Latin alphabet. If you asked Julius Caesar what he would do when he wanted to encrypt the Chinese ideograph 𡞰, he might just roll his eyes at you and then march off to conquer another Germanic village.
If one were to actually write a spec for ROT128 , it would be perfectly valid to specify undefined results. It might read something like " ROT128 is defined for the first 256 Unicode code points. The result of applying ROT128 to a string that contains other characters is undefined."
I (initially) simply wanted it to work with char and the characters in the ASCII table.
PLEASE stop saying "ASCII". ASCII contains only 128 characters. Applying ROT128 to an ASCII string does nothing at all. You would need to define a ROT64 algorithm for it to be useful with ASCII.
Either refer to an existing 8 bit character set such as "Latin-1", or define your own "ROT128" character set.
Tan Quang wrote:
. . . not the only character table. I may not use it but that doesn't mean others don't use it . . .
I am surprised that you don't know what the alternative to a loop is. ( In this case, no, it isn't recursion. ) And if you go through that SO link you quoted, it should give you a hint about how to rewrite your loop to iterate “1💖3” as three parts. It is quite simple, really.
And who needs to have anything to do with those char[] s, when StringBuilder has methods for dealing with individual code points directly?
You need to work out the algorithms for yourself; you will learn nothing if I tell you the code myself. I shall learn something by creating that code, but you won't.
As Stephan has explained, that will not work. If you design and test your algorithm on Latin‑1 only, you can expect something to go wrong on other inputs; that is why Stephan called the results undefined.
I am surprised that you don't know what the alternative to a loop is. ( In this case, no, it isn't recursion. ) And if you go through that SO link you quoted, it should give you a hint about how to rewrite your loop to iterate “1💖3” as three parts. It is quite simple, really.
And who needs to have anything to do with those char[] s, when StringBuilder has methods for dealing with individual code points directly?
You need to work out the algorithms for yourself; you will learn nothing if I tell you the code myself. I shall learn something by creating that code, but you won't.
Stephan van Hulst wrote:
I wasn't saying that you couldn't name your algorithm ROT128.
I said that we couldn't tell you whether your algorithm was correct or not, because there is no standard for ROT128.
I didn't say that you said I was not named algorithm ROT128. Anyway, it's just a name, I don't expect it to take up too many "highlights" in this topic.
Yes, I didn't give any standard for this algorithm. But I also said, maybe it will have the same standard as ROT13 or Caesar cipher .
Why did I write an permissive algorithm? Maybe I'm like everything simple? I'm not sure why.
"Postel's law" has made the world a worse place. I'm still the first time I heard this law, is it the law of talking about compatible functions? Anyway, it makes the world worse but I feel it is still quite useful.
It sounded "grim" but at least he might just roll his eyes at
me before
march off to conquer another Germanic village
.
at
me before
march off to conquer another Germanic village
.
But anyway, ROT128 is a "unofficial variant" of ROT13 , so maybe it also undefined for characters other than the basic Latin alphabet .
Yes, sorry. Up to now, it is no longer just ASCII , I have to turn into Latin-1 . Perhaps now, it has done the same thing as ROT13 , but has "expanded" more, up to Latin-1 .
I said that we couldn't tell you whether your algorithm was correct or not, because there is no standard for ROT128.
I didn't say that you said I was not named algorithm ROT128. Anyway, it's just a name, I don't expect it to take up too many "highlights" in this topic.
Yes, I didn't give any standard for this algorithm. But I also said, maybe it will have the same standard as ROT13 or Caesar cipher .
No. You can also reject the input. We are simply asking you why you wrote a permissive algorithm instead. I'd like to remind you that "Postel's Law" made the world a worse place.
Why did I write an permissive algorithm? Maybe I'm like everything simple? I'm not sure why.
"Postel's law" has made the world a worse place. I'm still the first time I heard this law, is it the law of talking about compatible functions? Anyway, it makes the world worse but I feel it is still quite useful.
I don't see how that matters to anything at all. ROT13 is simply undefined for characters other than the basic Latin alphabet. If you asked Julius Caesar what he would do when he wanted to encrypt the Chinese ideograph 𡞰, he might just roll his eyes at you and then march off to conquer another Germanic village.
If one were to actually write a spec for ROT128 , it would be perfectly valid to specify undefined results. It might read something like " ROT128 is defined for the first 256 Unicode code points. The result of applying ROT128 to a string that contains other characters is undefined."
It sounded "grim" but at least he might just roll his eyes
at
me before
march off to conquer another Germanic village
.
But anyway, ROT128 is a "unofficial variant" of ROT13 , so maybe it also undefined for characters other than the basic Latin alphabet .
PLEASE stop saying "ASCII". ASCII contains only 128 characters. Applying ROT128 to an ASCII string does nothing at all. You would need to define a ROT64 algorithm for it to be useful with ASCII.
Either refer to an existing 8 bit character set such as "Latin-1", or define your own "ROT128" character set.
Yes, sorry. Up to now, it is no longer just ASCII , I have to turn into Latin-1 . Perhaps now, it has done the same thing as ROT13 , but has "expanded" more, up to Latin-1 .
Campbell Ritchie wrote:
As Stephan has explained, that will not work. If you design and test your algorithm on Latin‑1 only, you can expect something to go wrong on other inputs; that is why Stephan called the results undefined.
I am surprised that you don't know what the alternative to a loop is. ( In this case, no, it isn't recursion. ) And if you go through that SO link you quoted, it should give you a hint about how to rewrite your loop to iterate “1💖3” as three parts. It is quite simple, really.
And who needs to have anything to do with those char[] s, when StringBuilder has methods for dealing with individual code points directly?
You need to work out the algorithms for yourself; you will learn nothing if I tell you the code myself. I shall learn something by creating that code, but you won't.
I paid attention to the phrase ( In this case, no, it isn't recursion. ) which you say, pay attention many times. I'm not good at speculating the meaning of other people's words, so that sentence is you in the literal sense, right?
You say:
I quoted quite a lot of links on SO, but you pointed out the target of 1💖3 , so surely SO link that you want to say is this link ?
3 parts ... I'm not sure but probably like this?
Well, that's yet I haven't tried to write it in combination with ROT128 because I'm not sure if it's true or not?!
I am surprised that you don't know what the alternative to a loop is. ( In this case, no, it isn't recursion. ) And if you go through that SO link you quoted, it should give you a hint about how to rewrite your loop to iterate “1💖3” as three parts. It is quite simple, really.
And who needs to have anything to do with those char[] s, when StringBuilder has methods for dealing with individual code points directly?
You need to work out the algorithms for yourself; you will learn nothing if I tell you the code myself. I shall learn something by creating that code, but you won't.
I paid attention to the phrase ( In this case, no, it isn't recursion. ) which you say, pay attention many times. I'm not good at speculating the meaning of other people's words, so that sentence is you in the literal sense, right?
You say:
Campbell Ritchie wrote: ...And if you go through that SO link you quoted...
I quoted quite a lot of links on SO, but you pointed out the target of 1💖3 , so surely SO link that you want to say is this link ?
3 parts ... I'm not sure but probably like this?
Well, that's yet I haven't tried to write it in combination with ROT128 because I'm not sure if it's true or not?!
Tan Quang wrote:
. . .
SO link
that you want to say is
this link
?
I think that is the correcct link, yes
Well, that works but I think there is a simpler way to do it. Use this method .3 parts ... I'm not sure but probably like this? . . .
Campbell Ritchie wrote:
I think that is the correcct link, yes
Well, that works but I think there is a simpler way to do it. Use this method .
Well, I know that method after posting the answer above not long. So, I tried to rewrite the code:
It is true that it is more concise, but the loop still has to run through 4 steps (using String.length ) instead of 3 steps (using String.codePointCount ). Did I do wrong? Not as suggested by you?
Well, that works but I think there is a simpler way to do it. Use this method .
Well, I know that method after posting the answer above not long. So, I tried to rewrite the code:
It is true that it is more concise, but the loop still has to run through 4 steps (using String.length ) instead of 3 steps (using String.codePointCount ). Did I do wrong? Not as suggested by you?
Tan Quang wrote:
It is true that it is more concise, but the loop still has to run through 4 steps (using
String.length
) instead of 3 steps (using
String.codePointCount
).
Well, no, that isn't true. If line 11 said "i += 1" it would be true, but it doesn't say that. Given the input in your example, the loop body is executed 3 times.
Which to me demonstrates that the code isn't all that easy to understand. So I thought "Why isn't there a way to iterate directly over the code points in a String?" Which of course there is a way.
The String class has a method codePoints() which returns an IntStream containing the code points. You can do anything you like with that stream. So here you have one line of code which is easy to understand instead of eight or ten lines which are not easy to understand.
But it gets worse. That code appears to be creating a StringBuilder and copying the contents of a String into it one code point at a time. But there's a StringBuilder constructor for that. So:
Now it's more obvious that the code copies data from a String into a StringBuilder, then copies the data back into a String, and compares to make sure the copying didn't damage any data. Which as you would expect it doesn't.
Well, no, that isn't true. If line 11 said "i += 1" it would be true, but it doesn't say that. Given the input in your example, the loop body is executed 3 times.
Which to me demonstrates that the code isn't all that easy to understand. So I thought "Why isn't there a way to iterate directly over the code points in a String?" Which of course there is a way.
The String class has a method codePoints() which returns an IntStream containing the code points. You can do anything you like with that stream. So here you have one line of code which is easy to understand instead of eight or ten lines which are not easy to understand.
But it gets worse. That code appears to be creating a StringBuilder and copying the contents of a String into it one code point at a time. But there's a StringBuilder constructor for that. So:
Now it's more obvious that the code copies data from a String into a StringBuilder, then copies the data back into a String, and compares to make sure the copying didn't damage any data. Which as you would expect it doesn't.
Tan Quang wrote:
. . . 3 parts ... I'm not sure but probably like this? . . .
That code would probably would work, but it is inelegant; you are using an additional array, and you have an int variable neither of which is actually necessary.
You should have worked out whether your ROT128 algorithm does or doesn't work in those circumstance.. . . I haven't tried to write it in combination with ROT128 because I'm not sure if it's true or not?!
Paul Clapham wrote:
Well, no, that isn't true. If line 11 said "i += 1" it would be true, but it doesn't say that. Given the input in your example, the loop body is executed 3 times.
Which to me demonstrates that the code isn't all that easy to understand. So I thought "Why isn't there a way to iterate directly over the code points in a String?" Which of course there is a way.
The String class has a method codePoints() which returns an IntStream containing the code points. You can do anything you like with that stream. So here you have one line of code which is easy to understand instead of eight or ten lines which are not easy to understand.
But it gets worse. That code appears to be creating a StringBuilder and copying the contents of a String into it one code point at a time. But there's a StringBuilder constructor for that. So:
Now it's more obvious that the code copies data from a String into a StringBuilder, then copies the data back into a String, and compares to make sure the copying didn't damage any data. Which as you would expect it doesn't.
Oh, that's how Campbell instructed me to handle characters outside the scope of char , because I had not really thought of Unicode (2 char ) cases. It is part of this topic, the first part, processing the code points before proceeding to shift/rotation.
Which to me demonstrates that the code isn't all that easy to understand. So I thought "Why isn't there a way to iterate directly over the code points in a String?" Which of course there is a way.
The String class has a method codePoints() which returns an IntStream containing the code points. You can do anything you like with that stream. So here you have one line of code which is easy to understand instead of eight or ten lines which are not easy to understand.
But it gets worse. That code appears to be creating a StringBuilder and copying the contents of a String into it one code point at a time. But there's a StringBuilder constructor for that. So:
Now it's more obvious that the code copies data from a String into a StringBuilder, then copies the data back into a String, and compares to make sure the copying didn't damage any data. Which as you would expect it doesn't.
Oh, that's how Campbell instructed me to handle characters outside the scope of char , because I had not really thought of Unicode (2 char ) cases. It is part of this topic, the first part, processing the code points before proceeding to shift/rotation.
Campbell Ritchie wrote:
That code would probably would work, but it is inelegant; you are using an additional array, and you have an
int
variable neither of which is actually necessary.
Oh that's right, the conversion into a char array is not necessary, I can write briefly to this:
Perhaps before that I misunderstood you, you said I could do it within 3 steps so I thought something like this:
Anyway, maybe now I understand what you mean if I use Character.charCount instead of ++i .
According to Stephan mentioned above, this algorithm has now "expanded" than the ASCII table, which can shift/rotation with all characters in the Latin-1 table. To avoid you have to pull up to review the code, I will rewrite it like this:
P/s: I have updated with the Unicode character processing code that you suggest, as well as try with ASCII < characters <= Latin-1 .
Returning to the main topic, can I continue to "expand" it, so that it can be shift/rotation with UTF-8 or UTF-16 characters? If so, how should it be changed?
P/s: I didn't expect it to be able to handle up to 4 bytes as it seemed so hard and "too cumbersome" (I'm not sure, but most of the answers on SO say so) but I really hope it can handle up to 3 bytes (UTF-8 BMP) or 2 bytes (UTF-16 BMP).
And of course, if up to 3 bytes (UTF-8 BMP) or 2 bytes (UTF-16 BMP) can be processed, still following the "standard" as "non-standard", 4 bytes characters (UTF-8MB4, UTF-16 4 bytes - as far as I remember correctly Java uses UTF-16 2 bytes as the default) will be "ignored", don't make shift/rotation.
Oh that's right, the conversion into a char array is not necessary, I can write briefly to this:
Perhaps before that I misunderstood you, you said I could do it within 3 steps so I thought something like this:
Anyway, maybe now I understand what you mean if I use Character.charCount instead of ++i .
Campbell Ritchie wrote: You should have worked out whether your ROT128 algorithm does or doesn't work in those circumstance.
According to Stephan mentioned above, this algorithm has now "expanded" than the ASCII table, which can shift/rotation with all characters in the Latin-1 table. To avoid you have to pull up to review the code, I will rewrite it like this:
P/s: I have updated with the Unicode character processing code that you suggest, as well as try with ASCII < characters <= Latin-1 .
Returning to the main topic, can I continue to "expand" it, so that it can be shift/rotation with UTF-8 or UTF-16 characters? If so, how should it be changed?
P/s: I didn't expect it to be able to handle up to 4 bytes as it seemed so hard and "too cumbersome" (I'm not sure, but most of the answers on SO say so) but I really hope it can handle up to 3 bytes (UTF-8 BMP) or 2 bytes (UTF-16 BMP).
And of course, if up to 3 bytes (UTF-8 BMP) or 2 bytes (UTF-16 BMP) can be processed, still following the "standard" as "non-standard", 4 bytes characters (UTF-8MB4, UTF-16 4 bytes - as far as I remember correctly Java uses UTF-16 2 bytes as the default) will be "ignored", don't make shift/rotation.
<br /> Or to get rid of the loop and write more streamlined code, code which strictly works with code points and not with chars:
<br />
Tan Quang wrote:
P/s: I have updated with the Unicode character processing code that you suggest, as well as try with
ASCII
< characters <=
Latin-1
.
Returning to the main topic, can I continue to "expand" it, so that it can be shift/rotation with UTF-8 or UTF-16 characters? If so, how should it be changed?
P/s: I didn't expect it to be able to handle up to 4 bytes as it seemed so hard and "too cumbersome" (I'm not sure, but most of the answers on SO say so) but I really hope it can handle up to 3 bytes (UTF-8 BMP) or 2 bytes (UTF-16 BMP).
And of course, if up to 3 bytes (UTF-8 BMP) or 2 bytes (UTF-16 BMP) can be processed, still following the "standard" as "non-standard", 4 bytes characters (UTF-8MB4, UTF-16 4 bytes - as far as I remember correctly Java uses UTF-16 2 bytes as the default) will be "ignored", don't make shift/rotation.
Just work with the code points. You don't have to concern yourself with what they represent, what Unicode plane they come from, or any of that. A Java String is simply composed of a list of Unicode characters, which Java calls "code points" because it already uses "characters" for an older concept.
Returning to the main topic, can I continue to "expand" it, so that it can be shift/rotation with UTF-8 or UTF-16 characters? If so, how should it be changed?
P/s: I didn't expect it to be able to handle up to 4 bytes as it seemed so hard and "too cumbersome" (I'm not sure, but most of the answers on SO say so) but I really hope it can handle up to 3 bytes (UTF-8 BMP) or 2 bytes (UTF-16 BMP).
And of course, if up to 3 bytes (UTF-8 BMP) or 2 bytes (UTF-16 BMP) can be processed, still following the "standard" as "non-standard", 4 bytes characters (UTF-8MB4, UTF-16 4 bytes - as far as I remember correctly Java uses UTF-16 2 bytes as the default) will be "ignored", don't make shift/rotation.
Just work with the code points. You don't have to concern yourself with what they represent, what Unicode plane they come from, or any of that. A Java String is simply composed of a list of Unicode characters, which Java calls "code points" because it already uses "characters" for an older concept.
I reformatted your code a little bit to comment on it a bit more easily. A few things:
I'd tell you to fix these things, but they all become moot when you follow Paul's advice. The entire loop is way too complex and error-prone. Paul already explained how you can iterate over code points instead of mucking around with char counts.
Returning to the main topic, can I continue to "expand" it, so that it can be shift/rotation with UTF-8 or UTF-16 characters?
Stop. UTF-8 and UTF-16 are NOT character sets. They are binary encoding schemes. They have NOTHING to do with mapping characters to other characters.
What exactly is it that you want to expand? Do you want your algorithm to rotate all existing Unicode characters? That's a whole 'nother can of worms:
I didn't expect it to be able to handle up to 4 bytes as it seemed so hard and "too cumbersome" (I'm not sure, but most of the answers on SO say so) but I really hope it can handle up to 3 bytes (UTF-8 BMP) or 2 bytes (UTF-16 BMP).
Why are you talking about bytes at all? Your algorithm operates (or should operate) on abstract characters, or code points. Their binary representation in some encoding scheme is completely beside the point.
Paul Clapham wrote:
<br /> Or to get rid of the loop and write more streamlined code, code which strictly works with code points and not with chars:
<br />
Oh, that's right, I didn't think of the ternary operator before.
P/s: Something is wrong for the forum's code:

Oh, that's right, I didn't think of the ternary operator before.
P/s: Something is wrong for the forum's code:
Paul Clapham wrote:
Just work with the code points. You don't have to concern yourself with what they represent, what Unicode plane they come from, or any of that. A Java String is simply composed of a list of Unicode characters, which Java calls "code points" because it already uses "characters" for an older concept.
Yes, the current code is capable of shift/rotation the code points of value <= 255 (the entire Latin-1 character set). I want to expand it, can it shift/rotation with codes with a value greater than 255? If so, how to do? <br /> P/S: Still according to the old "rule": Original string + shift/rotation of N letters -> new string + shift/rotation of N letters -> original string.
Yes, the current code is capable of shift/rotation the code points of value <= 255 (the entire Latin-1 character set). I want to expand it, can it shift/rotation with codes with a value greater than 255? If so, how to do? <br /> P/S: Still according to the old "rule": Original string + shift/rotation of N letters -> new string + shift/rotation of N letters -> original string.
I child proofed my house but they still get in. Distract them with this tiny ad:
Smokeless wood heat with a rocket mass heater
https://woodheat.net
current ranch time (not your local time) is
Oct 21, 2024 17:52:04
contact us
|
advertise
|
推荐文章
|
|
爱跑步的松鼠 · 即时通讯服务器端口是什么 • Worktile社区 8 月前 |