

本文介绍关于Pod异常问题的诊断流程、排查方法、常见问题及解决方案。
本文目录
|
类别 |
内容 |
|
诊断流程 |
|
|
常见排查方法 |
|
|
常见问题及解决方案 |
诊断流程
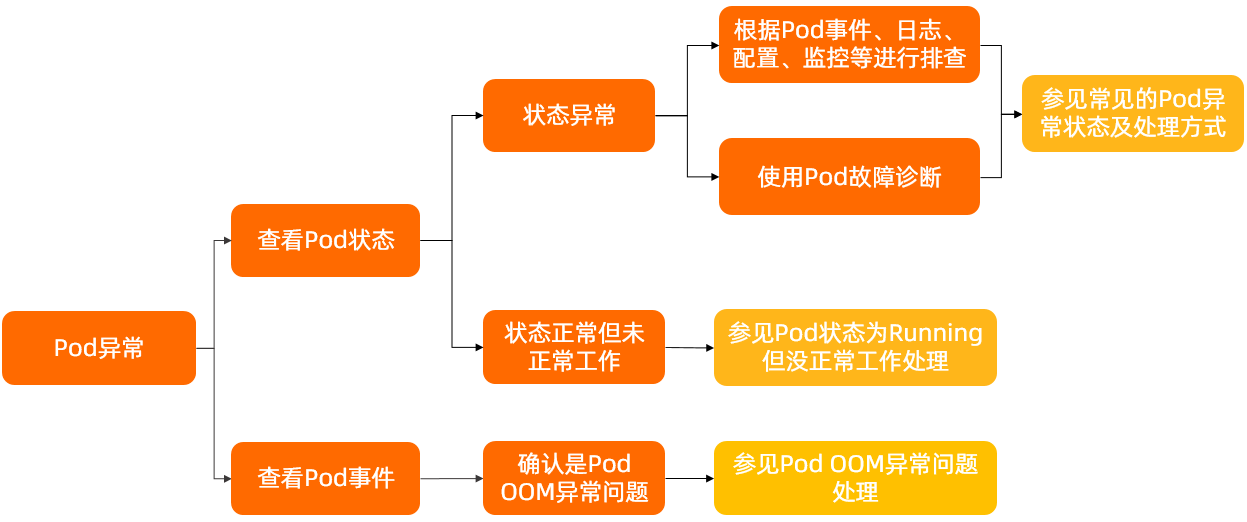
-
查看Pod是否处于异常状态,具体操作,请参见 检查Pod的状态 。
-
如果Pod状态异常,可通过查看Pod的事件、Pod的日志、Pod的配置等信息确定异常原因。具体操作,请参见 常见排查方法 。关于Pod异常状态及处理方式,请参见 常见的Pod异常状态及处理方式 。
-
如果Pod状态为Running但未正常工作,请参见 Pod状态为Running但没正常工作 。
-
-
若确认是Pod OOM异常问题,请参见 Pod OOM异常问题处理 。
-
如果问题仍未解决,请 提交工单 。
常见的Pod异常状态及处理方式
|
Pod状态 |
Pod含义 |
解决方案 |
|
Pending |
Pod未被调度到节点上。 |
|
|
Init:N/M |
Pod包含M个Init容器,其中N个已经启动完成。 |
|
|
Init:Error |
Init容器已启动失败。 |
|
|
Init:CrashLoopBackOff |
Init容器启动失败,反复重启。 |
|
|
Completed |
Pod的启动命令已执行完毕。 |
|
|
CrashLoopBackOff |
Pod启动失败,反复重启。 |
|
|
ImagePullBackOff |
Pod镜像拉取失败。 |
|
|
Running |
|
|
|
Terminating |
Pod正在关闭中。 |
|
|
Evicted |
Pod被驱逐。 |
常见排查方法
检查Pod的状态
-
登录 容器服务管理控制台 。
-
在控制台左侧导航栏,单击 集群 。
-
在 集群列表 页面,单击目标集群名称或者目标集群右侧 操作 列下的 详情 。
-
在集群管理页左侧导航栏,选择 。
-
在 容器组 页面左上角选择Pod所在的 命名空间 ,查看Pod状态。
-
若状态为Running,说明Pod运行正常。
-
若状态不为Running,说明Pod状态异常,请参见 常见的Pod异常状态及处理方式 进行处理。
-
检查Pod的详情
-
登录 容器服务管理控制台 。
-
在控制台左侧导航栏,单击 集群 。
-
在 集群列表 页面中,单击目标集群名称或者目标集群右侧 操作 列下的 详情 。
-
在集群管理页左侧导航栏,选择 。
-
在 容器组 页面左上角选择Pod所在的 命名空间 ,然后单击目标Pod名称或者目标Pod右侧操作列下的详情,查看Pod的名称、镜像、Pod IP、所在节点等详细信息。
检查Pod的配置
-
登录 容器服务管理控制台 。
-
在控制台左侧导航栏,单击 集群 。
-
在 集群列表 页面,单击目标集群名称或者目标集群右侧 操作 列下的 详情 。
-
在集群管理页左侧导航栏,选择 。
-
在 容器组 页面左上角选择Pod所在的 命名空间 ,然后单击目标Pod名称或者目标Pod右侧操作列下的详情。
-
在Pod详情页面右上角单击 编辑 ,查看Pod的YAML文件和详细配置。
检查Pod的事件
-
登录 容器服务管理控制台 。
-
在控制台左侧导航栏,单击 集群 。
-
在 集群列表 页面,单击目标集群名称或者目标集群右侧 操作 列下的 详情 。
-
在集群管理页左侧导航栏,选择 。
-
在 容器组 页面左上角选择Pod所在的 命名空间 ,然后单击目标Pod名称或者目标Pod右侧操作列下的详情。
-
在Pod详情页面下方单击 事件 页签,查看Pod的事件。
说明Kubernetes默认保留最近1小时的事件,若需保存更长时间的事件,请参见 创建并使用K8s事件中心 。
检查Pod的日志
-
登录 容器服务管理控制台 。
-
在控制台左侧导航栏,单击 集群 。
-
在 集群列表 页面,单击目标集群名称或者目标集群右侧 操作 列下的 详情 。
-
在集群管理页左侧导航栏,选择 。
-
在 容器组 页面左上角选择Pod所在的 命名空间 ,然后单击目标Pod名称或者目标Pod右侧操作列下的详情。
-
在Pod详情页面下方单击 日志 页签,查看Pod的日志。
说明阿里云ACK集群集成了日志服务,您可在创建集群时启用日志服务,快速采集集群的容器日志,包括容器的标准输出及容器内的文本文件。更多信息,请参见 通过日志服务采集Kubernetes容器日志 。
检查Pod的监控
-
登录 容器服务管理控制台 。
-
在控制台左侧导航栏,单击 集群 。
-
在 集群列表 页面,单击目标集群名称或者目标集群右侧 操作 列下的 详情 。
-
在集群管理页左侧导航栏中,选择 。
-
在 Prometheus监控 页面,单击 集群监控概览 页签,选择查看Pod的CPU、内存、网络I/O等监控大盘。
使用终端进入容器
-
登录 容器服务管理控制台 。
-
在控制台左侧导航栏,单击 集群 。
-
在 集群列表 页面,单击目标集群名称或者目标集群右侧 操作 列下的 详情 。
-
在集群管理页左侧导航栏,选择 。
-
在 容器组 页面,单击目标容器组右侧 操作 列下的 终端 。
可通过终端进入容器,在容器内查看本地文件等信息。
Pod故障诊断
Pod状态为Pending
问题原因
若Pod停留在Pending状态,说明该Pod不能被调度到某一个节点上。通常是由于资源依赖、资源不足、该Pod使用了hostPort、污点和容忍等原因导致集群中缺乏需要的资源。
问题现象
Pod的状态为Pending。
解决方案
查看Pod的事件,根据事件描述,定位Pod不能被调度到节点的原因。主要原因有以下几类:
-
资源依赖
创建Pod时,需要依赖于集群中ConfigMap、PVC等资源。例如,Pod添加存储卷声明前,存储卷声明需要先与存储卷绑定。
-
资源不足
-
在集群信息页面,选择 ,查看 容器组 、 CPU 、 内存 的使用情况,确定集群的资源使用率。
说明某个节点实际使用的CPU、内存资源非常低,新加入一个Pod时,如果会导致实际使用的资源超过该节点最大可供使用的资源,则调度程序不会将该Pod分配到该节点。这样可避免在日常的流量高峰时段,节点上出现资源短缺的情况。
-
若集群中的CPU或内存都已经耗尽,可参考如下方法处理。
-
删除或减少不必要的Pod。具体操作,请参见 管理容器组(Pod) 。
-
根据自身业务情况,调整Pod的资源配置。具体操作,请参见 设置容器的CPU和内存资源上下限 。
-
在集群中添加新的节点。具体操作,请参见 创建节点池 。
-
为节点进行升配。具体操作,请参见 升配Worker节点的资源 。
-
-
-
该Pod使用了hostPort
如果您使用了hostPort,那么Deployment或ReplicationController中
Replicas值不能超过集群中的节点数,因为每个实例的任意端口只有一个。如果该端口被其他应用占用,将导致Pod调度失败。因此建议您不要使用hostPort,您可以使用Service访问Pod,更多信息,请参见 Service 。 -
污点和容忍
当您在Pod的事件中看到 Taints 或 Tolerations 时,说明是由于污点导致,您可以删除污点或者给Pod设置容忍。更多信息,请参见 管理节点污点 、 创建无状态工作负载Deployment 和 污点和容忍 。
Pod状态为Init:N/M(Init:Error和Init:CrashLoopBackOff)
问题原因
-
若Pod停留在Init:N/M状态,说明该Pod包含M个Init容器,其中N个已经启动完成,但仍有M-N个Init容器未启动成功。
-
若Pod停留在Init:Error状态,说明Pod中的Init容器启动失败。
-
若Pod停留在Init:CrashLoopBackOff状态,说明Pod中的Init容器启动失败并处于反复重启状态。
问题现象
-
Pod的状态为Init:N/M。
-
Pod的状态为Init:Error。
-
Pod的状态为Init:CrashLoopBackOff。
解决方案
Pod状态为ImagePullBackOff
问题原因
若Pod停留在ImagePullBackOff状态,说明此Pod已被调度到某个节点,但拉取镜像失败。
问题现象
Pod的状态为ImagePullBackOff。
解决方案
通过查看该Pod的事件描述,查看具体拉取失败的镜像名称。
-
确认容器镜像名称是否正确。
-
登录到Pod所在的节点,执行
docker pull [$Image]命令,查看是否能正常抓取容器镜像。说明[$Image]为容器镜像的名称。-
若镜像拉取失败,请参见 docker pull失败 解决。
-
如果您使用的是私有镜像仓库,请参见 使用私有镜像仓库创建应用 解决。
-
Pod状态为CrashLoopBackOff
问题原因
若Pod停留在CrashLoopBackOff状态,说明容器中应用程序有问题。
问题现象
Pod的状态为CrashLoopBackOff。
解决方案
-
查看Pod的事件,确认当前Pod是否存在异常。具体操作,请参见 检查Pod的事件 。
-
查看Pod的日志,通过日志内容排查问题。具体操作,请参见 检查Pod的日志 。
-
查看Pod的配置,确认容器中的健康检查配置是否正常。具体操作,请参见 检查Pod的配置 。关于Pod健康检查的更多信息,请参见 配置存活、就绪和启动探测器 。
Pod状态为Completed
问题原因
若Pod出现Completed状态,说明容器中的启动命令已执行完毕,容器中的所有进程都已退出。
问题现象
Pod的状态为Completed。
解决方案
Pod状态为Running但没正常工作
问题原因
部署使用的YAML文件有问题。
问题现象
Pod状态为Running但没正常工作。
解决方案
-
查看Pod的配置,确定Pod中容器的配置是否符合预期。具体操作,请参见 检查Pod的配置 。
-
使用以下方法,排查环境变量中的某一个Key是否存在拼写错误。
以command拼写成commnd为例,说明拼写问题排查方法。
说明创建Pod时,环境变量中的某一个Key拼写错误的问题会被集群忽略,如Command拼写为Commnd,您仍能够使用该YAML文件创建资源。但容器运行时,不会执行有拼写问题的YAML文件,而是执行镜像中的默认命令。
-
在执行
kubectl apply -f命令前为其添加--validate,然后执行kubectl apply --validate -f XXX.yaml命令。如果您将command拼写成commnd,将看到错误信息
XXX] unknown field: commnd XXX] this may be a false alarm, see https://gXXXb.XXX/6842pods/test。 -
执行以下命令,将输出结果的 pod.yaml 文件与您创建Pod使用的文件进行对比。
kubectl get pods [$Pod] -o yaml > pod.yaml说明[$Pod]为异常Pod的名称,您可以通过kubectl get pods命令查看。-
pod.yaml 文件比您创建Pod所使用的文件多几行,说明已创建的Pod符合预期。
-
如果您创建Pod所使用文件里的代码行在 pod.yaml 文件中没有,说明您创建Pod使用的文件存在拼写问题。
-
-
-
查看Pod的日志,通过日志内容排查问题。具体操作,请参见 检查Pod的日志 。
-
可通过终端进入容器查看容器内的本地文件是否符合预期。具体操作,请参见 使用终端进入容器 。
Pod状态为Terminating
问题原因
若Pod的状态为Terminating,说明此Pod正处于关闭状态。
问题现象
Pod状态为Terminating。
解决方案
Pod停留在Terminating状态一段时间后会被自动删除。若Pod一直停留在Terminating状态,可执行如下命令强制删除:
kubectl delete pod [$Pod] -n [$namespace] --grace-period=0 --forcePod状态为Evicted
问题原因
当节点的内存、磁盘空间、文件系统的inode和操作系统可分配的PID等资源中的一个或者多个达到特定的消耗水平,就会引发kubelet主动地驱逐节点上一个或者多个Pod,以回收节点资源。
问题现象
Pod的状态为Evicted。
解决方案
-
执行以下命令,查看Pod的
status.message字段,来确定Pod被驱逐的原因。kubectl get pod [$Pod] -o yaml -n [$namespace]预期输出:
status: message: 'Pod the node had condition: [DiskPressure].' phase: Failed reason: Evicted通过上述
status.message字段,可以判断当前Pod是因为节点磁盘压力 (DiskPressure) 被驱逐。说明注意这里仅以磁盘压力驱逐为例,其它例如内存压力(MemoryPressure)和PID压力(PIDPressure)等也会以类似的方式展示。
-
执行以下命令,删除被驱逐的Pod。
kubectl get pods -n [$namespace]| grep Evicted | awk '{print $1}' | xargs kubectl delete pod -n [$namespace]
以下汇总如何避免Pod被驱逐的方法:
-
内存压力:
-
根据自身业务情况,调整Pod的资源配置。具体操作,请参见 设置容器的CPU和内存资源上下限 。
-
为节点进行升配。具体操作,请参见 升配Worker节点的资源 。
-
-
磁盘压力:
-
定时清理节点上的业务Pod日志,避免磁盘被日志打满。
-
为节点进行磁盘扩容。具体操作,请参见 步骤一:扩容云盘容量 。
-
-
PID压力:根据自身业务情况,调整Pod的资源配置,具体操作,请参见 进程ID约束与预留 。
Pod OOM异常问题处理
问题原因
当集群中的容器使用超过其限制的内存,容器可能会被终止,触发OOM(Out Of Memory)事件,导致容器异常退出。关于OOM事件,请参见 为容器和Pod分配内存资源 。
问题现象
-
若被终止的进程为容器的阻塞进程,可能会导致容器异常重启。
-
若出现OOM异常问题,登录 容器服务管理控制台 ,在Pod详情页面单击 事件 页签可看到OOM事件 pod was OOM killed 。具体操作,请参见 检查Pod的事件 。
-
若集群配置了集群容器副本异常报警,则OOM事件出现时可收到相关报警。关于配置报警,请参见 容器服务报警管理 。
解决方案
-
查看发生OOM异常的Pod所在的节点。
-
命令行方式查看 :执行以下命令,查看容器信息。
kubectl get pod [$Pod] -o wide -n [$namespace]预期输出:
NAME READY STATUS RESTARTS AGE IP NODE pod_name 1/1 Running 0 25h 172.20.6.53 cn-hangzhou.192.168.0.198 -
控制台方式查看 :查看Pod详情下的节点信息,请参见 检查Pod的详情 。
-
-
登录Pod所在的Node,查看内核日志
/var/log/message。在日志中查询关键字out of memory,确认具体被OOM终止的进程。如果该进程是容器的阻塞进程,OOM终止后容器会重启。 -
通过Pod内存监控查看内存增长曲线,确定异常出现时间。具体操作,请参见 检查Pod的监控 。
-
根据监控、内存增长时间点、日志、进程名等信息,排查Pod内对应进程是否存在内存泄漏。
-
若OOM是进程内存泄漏导致,请您自行排查泄露原因。
-
若进程运行状态正常,则根据实际运行需要,适当增大Pod的内存限制,建议Pod的内存实际使用量不超过内存限制值的80%。具体操作,请参见 设置容器的CPU和内存资源上下限 。
-
Pod访问数据库概率性网络断联
针对ACK集群中Pod访问数据库有概率性网络断联的问题,可以按照以下排查步骤进行分析和解决:
-
检查Pod:
-
检查节点:
-
查看节点的资源使用情况,确认是否有内存、磁盘等资源不足等情况。操作详情,请参见 监控节点 。
-
测试节点到与目标数据库是否出现概率性网络断联。
-
-
检查数据库 :
-
检查数据库的状态和性能指标,是否出现重启或性能瓶颈。
-
查看异常连接数,连接超时设置,并根据业务需要调整。
-
检查日志数据库可能有相关断开连接的日志。
-
-
集群组件状态 :
集群组件异常会影响Pod与集群内其他组件的通信。使用如下命令,检查ACK集群组件状态。
kubectl get pod -n kube-system # 查看组件Pod状态。-
检查网络插件:
-
coredns组件的状态和日志,确保Pod能正常解析数据库服务的地址。
-
Flannel插件可查看kube-flannel组件的状态和日志 。
-
Terway插件可查看terway-eniip组件的状态和日志 。
-
-
-
网络流量分析:
可以使用
tcpdump来抓包并分析网络流量,以帮助定位问题的原因。-
使用以下命令确定数据库连接断开问题发生在哪个Pod和哪个节点上。
kubectl get pod -n [namespace] -o wide -
登录到目标节点。操作步骤详情,请参见 通过密码或密钥认证登录Linux实例 。
使用以下命令,分别获取不同版本的容器进程PID。
-
1.22版本以上,使用containerd服务:
执行以下命令查看容器
CONTAINER。crictl ps |grep <Pod名称关键字>预期输出:
CONTAINER IMAGE CREATED STATE a1a214d2***** 35d28df4***** 2 days ago Running使用
CONTAINER ID参数,执行以下命令查看容器PIDcrictl inspect a1a214d2***** |grep -i PID预期输出:
"pid": 2309838, # 目标容器的PID进程号。 "pid": 1 "type": "pid" -
1.22版本及以下,使用Docker服务:
执行以下命令查看容器
CONTAINER ID。docker ps |grep <pod名称关键字>预期输出:
CONTAINER ID IMAGE COMMAND a1a214d2***** 35d28df4***** "/nginx使用
CONTAINER ID参数,执行以下命令查看容器PID。docker inspect a1a214d2***** |grep -i PID预期输出:
"Pid": 2309838, # 目标容器的PID进程号。 "PidMode": "", "PidsLimit": null,
-
-
执行抓包命令。
Pod端与目标数据库端之间抓包。使用获取到的容器PID,执行以下命令。
nsenter -t <容器PID> tcpdump -i any -n -s 0 tcp and host <数据库IP地址>Pod端与宿主机端之间抓包。使用获取到的容器PID,执行以下命令。
nsenter -t <容器PID> tcpdump -i any -n -s 0 tcp and host <节点IP地址>宿主机端与数据库端之间抓包。
tcpdump -i any -n -s 0 tcp and host <数据库IP地址>
-
-
优化业务应用程序:
-
在业务应用程序中实现数据库连接的自动重连机制,确保数据库发生切换或迁移时,应用程序能够无需人工干预自动恢复连接。
-
使用持久化的长连接而非短连接来与数据库通信。长连接能显著降低性能损耗和资源消耗,提高系统整体效率。
-