

扩散模型能不能和生成对抗网络、强化学习相结合?
关注者
64
被浏览
21,638
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

OpenDILab 开源决策智能平台知识传播星球
谢邀 ~ 扩散模型和强化学习的结合方式有多种类型,可以将扩散模型作为强化学习中更好的基础工具去学习价值函数/策略/状态转移函数,也可以使用强化学习去指导扩散模型的优化。这里我们 OpenDILab 就首先介绍下后者的代表性工作——DDPO
P.S. 本期回答节选于本账号的 Diffusion Model + RL 系列博客第六期,也欢迎了解我们的其他博客
0. 引言
如何利用扩散模型 (Diffusion model) 解决序列决策问题 (Decision-making problem) 这一领域已经涌现了很多经典的工作,反过来想,我们是否可以利用解决序列决策问题的主流思路——强化学习来优化扩散模型,使得扩散模型满足一些特有的性质呢?论文 “ Training Diffusion Models with Reinforcement Learning ”[1] 提供了一个思路,通过将扩散模型的去噪过程建模为多步 MDP (Markov Decision Process, 马尔可夫决策过程),利用成熟的强化学习理论达到优化扩散模型的目的。
1. 动机
现成的条件扩散模型已经达到文本生成图像的目的了,那么还需要优化什么呢?回顾条件扩散模型优化目标:
\theta^* =\mathop{\arg \min}_{\theta} -\mathbb{E}_{\mathbf{x}_0,\mathbf{c}}[\log\ p_\theta(\mathbf{x}_0|\mathbf{c})] \\ 优化的是图像数据 \mathbf{x}_0 在文本条件 c 下似然估计的负对数 (negative log likelihood) 。但实际使用中,有时用户不会很在意训练数据的对数似然这一指标,而是生成结果的其他属性,比如被人类所感知的图像质量 (human-perceived image quality,通俗说就是即使上述目标优化地很好,但生成出来的图像还是不能和 prompt 很好地对应),或者药物有效性(drug effectiveness,扩散模型也会被用在药物设计问题上)。除此之外,用户可能有各式各样的需求,这些需求可以被形式化为一个奖励模型 r(\mathbf{x}_0, \mathbf{c}) ,它量化了生成结果对用户需求的满足程度。
为了让扩散模型直接满足任意目标函数(最大化任意奖励模型输出),而不是仅仅建模匹配训练数据集的分布,论文[1]提出了针对扩散模型的 finetune 算法: DDPO (denoising diffusion policy optimization) 。
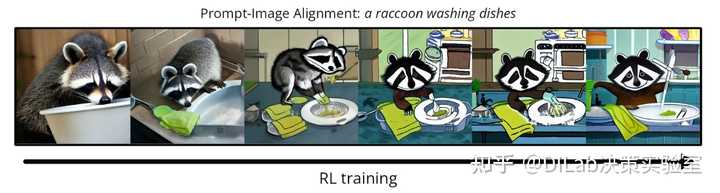
我们提前感受下 DDPO 对扩散模型带来的影响。以下图为例,如果我们直接使用现成的 Stable Diffusion v1.4 [5]并输入 prompt :a raccoon washing dishes ,会采样出最左边浣熊喝水的图片,这与期望的结果是不相符的。但经过算法 DDPO 的训练,生成结果会逐渐与“浣熊洗碗”的含义对齐。

2. DDPO
DDPO 算法需要两个前提条件:一个预训练好的扩散模型 \mu_\theta(\mathbf{x}_t, \mathbf{c},t) 以及一个上文提到的奖励模型 r(\mathbf{x}_0, c) 。DDPO 的目标便是最大化奖励模型的输出,即:
\mathcal{J}_{DDRL} (\theta) = \mathbb{E}_{\mathbb{c}\sim p(\mathbf{c}),\mathbf{x}_0 \sim p_\theta(\mathbf{x}_0|\mathbf{c})}[r(\mathbf{x}_0,\mathbf{c})]\\ DDPO 算法的设计基于两个方面:将图片去噪过程建模为一个多步 MDP (multi-step MDP);之后利用成熟的策略优化算法优化扩散模型。
2.1 将扩散模型建模为多步 MDP
作为一个六元组,MDP 可以被形式化为 (\mathcal{S}, \mathcal{A}, \rho_0,P,R) 。其中 \mathcal{S} 是状态空间, \mathcal{A} 是动作空间, \rho_0 是初始状态分布, P 是状态转移矩阵, R 则是奖励函数。强化学习的优化目标便是最大化策略的累计收益:
\mathcal{J}_{RL}(\pi) = \mathbb{E}_{\tau\sim p(\tau|\pi)}[\sum_{t=0}^T R(s_t, a_t)]\\
论文[1]按照如下方式将扩散模型多步去噪过程与 MDP 联系了起来:
- s_t \triangleq (\mathbf{c},t,\mathbf{x}_t)
即每一步的状态被定义为一个元组,其中包含条件变量,去噪时间步以及当前时间步的去噪结果。
- \pi(a_t|s_t) \triangleq p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t, \mathbf{c})
自然的,策略便是在给定当前状态下,下一步去噪结果的条件分布。
- a_t \triangleq \mathbf{x}_{t-1}
动作就是下一步的去噪结果。
- P(s_{t+1}|s_t, a_t) \triangleq (\delta_\mathbf{c}, \delta_{t-1}, \delta_{\mathbf{x}_{t-1}})
去噪过程中,在采样出下一步去噪结果 \mathbf{x}_{t-1} 后,状态的转移便是确定性的。因此,这里用三个狄拉克德尔塔分布 (Dirac delta distribution) 表示状态转移概率。
- \rho_0(s_0) \triangleq (p(\mathbf{c}), \delta_T, \mathcal{N}(\mathbf{0}, \mathbf{I}))
对于初始状态分布,条件变量 $$c$$ 服从其先验分布, 时间步 T 是确定的,最后 \mathbf{x}_T 则服从标准高斯噪声。
- R(s_t, a_t) \triangleq \begin{cases}r(\mathbf{x}_0, \mathbf{c})\ &if\ \ t=0 \\ 0 &otherwise\end{cases}
在去噪过程中,只有最终的去噪结果会依据上文提到的奖励模型获得一个分数,而去噪过程中的奖励值都定义为 0 。
注意:上述 MDP 的时间戳是从 0 到 T;对应去噪过程的时间戳则是从 T 到 0 。
至此,本节完成了扩散模型去噪过程与 MDP 的对齐,从而使优化目标 \mathcal{J}_{DDRL} 等价于 \mathcal{J}_{RL} 。下一节介绍如何将强化学习领域中成熟的策略梯度算法应用到扩散模型优化过程中。
2.2 策略梯度估计
为了优化 \mathcal{J}_{DDRL} ,我们需要估计它的梯度 \nabla_\theta\mathcal{J}_{DDRL} 。论文中对 \nabla_\theta\mathcal{J}_{DDRL} 的估计则源自强化学习领域中十分经典的两个算法:REINFORCE[3] 和 PPO[4] 。与之对应的,也就有了两个版本的 DDPO ,原作者将这两种算法称为 DDPO_{SF} 和 DDPO_{IS} 。
其中 DDPO_{SF} 对 \mathcal{J}_{DDRL} 梯度的估计如下:
\nabla_\theta \mathcal{J}_{DDRL} = \mathbb{E}[\nabla_\theta \log p_\theta (\mathbf{x}_{t-1}|\mathbf{x}_t , \mathbf{c}) r(\mathbf{x}_0 , \mathbf{c})]\\
这里默认读者对 策略梯度定理 有所了解, 它的推导过程源于 REINFORCE[3] 。注意公式中的 r(\mathbf{x}_0 , \mathbf{c}) = \sum_{t=0}^T R(s_t, a_t)
其中 DDPO_{IS} 对 \mathcal{J}_{DDRL} 梯度的估计如下:
\nabla_\theta \mathcal{J}_{DDRL} = \mathbb{E}[clip(\frac{p_\theta(\mathbf{x}_{t-1}| \mathbf{x}_{t}, \mathbf{c})}{p_{\theta_{old}}(\mathbf{x}_{t-1}| \mathbf{x}_{t}, \mathbf{c})}, 1-\epsilon, 1+\epsilon)\nabla_\theta \log p_\theta (\mathbf{x}_{t-1}|\mathbf{x}_t , \mathbf{c}) r(\mathbf{x}_0 , \mathbf{c})]\\
Schulman 等人于 2015 年提出的 TRPO[4] 和 2017 年提出的 PPO[3] 算法是对策略梯度估计一类强化学习算法的重大改进,通过重要性采样 (importance sampling) 和信赖域 (trust region) 约束,PPO/TRPO 相比 REINFORCE 极大地提高了样本效率。
得到 \nabla_\theta\mathcal{J}_{DDRL} 的估计以后,应用各种梯度下降算法便可以优化 Unet 的参数,使其最大化 \mathcal{J}_{DDRL} 。下图展示了 DDPO_{IS} 的算法流程:
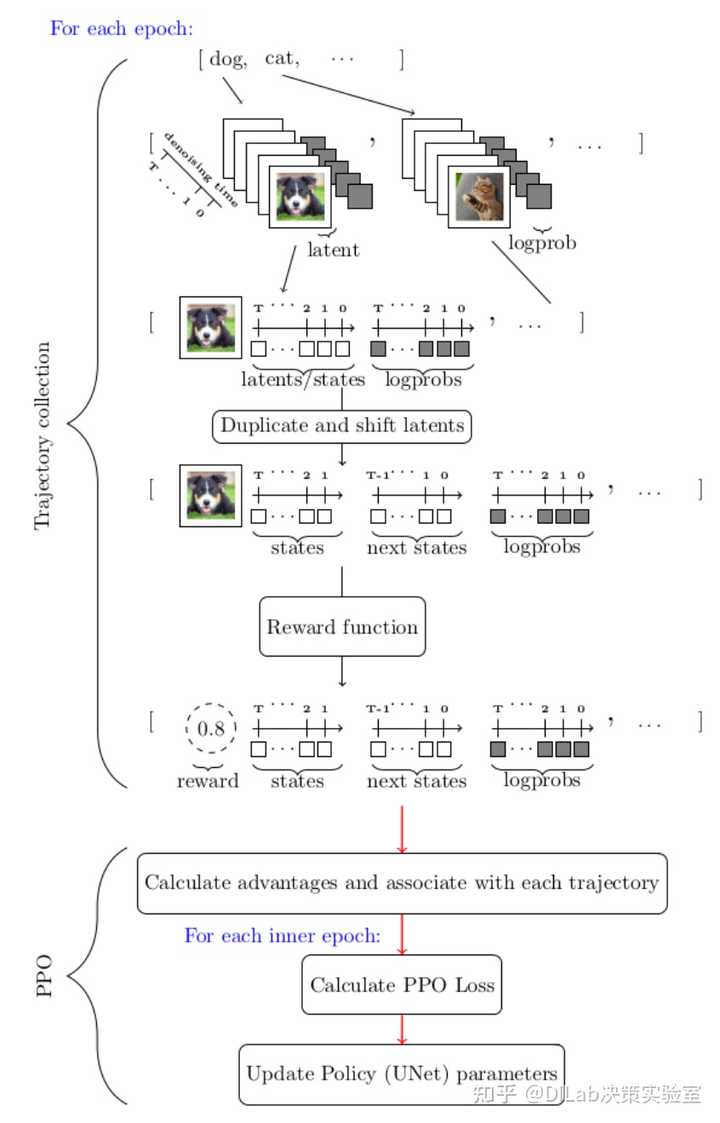

每一个 epoch 分为轨迹收集 (Trajectory collection) 和 PPO 两个阶段。其中轨迹收集阶段便是一轮轮去噪过程, 在此阶段算法保留了每一步状态、动作以及最终的奖励值,用于在 PPO 阶段估计 \nabla_\theta\mathcal{J}_{DDRL} 并优化 Unet 。
以上便是 DDPO 算法的核心内容。下面以文本生成图像扩散模型为例,论文[1]给出了几种不同的奖励模型,并通过实验验证了 DDPO 算法的有效性。
3. 文生图扩散模型的各种奖励模型
3.1 压缩性和反压缩性 (compressibility and incompressibility)
文生图扩散模型的能力受到文本和图像在其训练分布中的共同出现的限制。举个例子,对于扩散模型预训练的训练集,与图像相匹配的文本(也就是图像的标题\文件名)很少带有图像大小的信息。这就导致了在使用扩散模型生成图像时,很难通过提供文件大小 (file size) 的 prompt 而采样出相应大小的图片。预训练模型的这一限制使得基于文件大小的奖励函数成为一个方便的研究示例:图片大小(file size)易于计算,但无法通过最大化似然估计和提示工程的传统方法控制采样结果。
之后的实验基于预训练模型 Stable Diffusion v1.4 [5] ,其中 Unet 输出大小固定为 512x512 。这里读者可能会疑惑,网络结构已经决定了图片的大小,DDPO 难道还能改变输出大小?事实上,论文[1]中图片大小的量化方式不是像素数量,而是 512x512 的图片经过 JPEG 压缩后的文件大小。关于 JPEG 压缩算法,读者可以参考博客[6],这里读者可以简单理解为图片细节越丰富(而不是像素数越多),JPEG 压缩后的文件越大,“图片大小”越大。
基于此,论文[1]定义了两种任务:
- compressibility,采样结果经过 JPEG 压缩后的文件越小越好
- incompressibility,采样结果经过 JPEG 压缩后的文件越大越好
3.2 艺术性 (aesthetic quality)
下面介绍一个比较实用的奖励模型,名为 LAION aesthetics predictor [7]。它是以 CLIP[8] 图片编码为输入的一个线性模型,基于 17600 张由人类打分的图片训练而成。训练集中各图片分数从 1 到 10,其中评分较高的往往是艺术作品。之后的实验 LAION aesthetics predictor 会对扩散模型采样结果评分,分数越高,图片的艺术性越强。因此以此模型作为 DDPO 奖励模型,预计 finetune 过后的采样结果会更具有艺术性。
3.3 自动生成提示词与视觉语言模型对齐 (Automated prompt alignment with Vision-Language Models)
用于训练文本到图像模型的一个非常通用的奖励函数是提示文本与图像的对齐。然而,定义文本与图像是否对齐的奖励是困难的,通常需要大规模的人工标记工作。论文[1]选择现有的 VLM (Vision-Language Model) 来取代额外的人工注释。
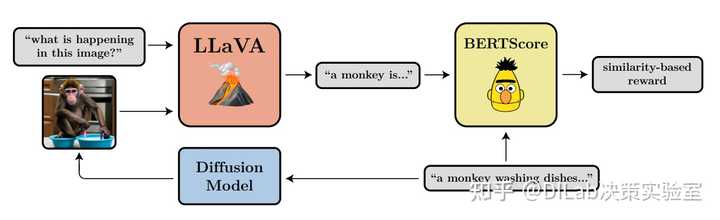
如下图所示,论文[1]选用 SOTA 模型 LLaVA[9] 来描述图片中的内容。此外,用来 finetune 扩散模型的奖励值出自 BERTSore[10] 模型,它通过比对扩散模型的提示文本(prompt)与 LLaVA 输出的描述文本间的语义相似性,从而会对包含提示文本的所有细节的采样结果给出更高的奖励。

4. 实验
论文[1]的实验设计围绕以下三个问题:
- 两种 DDPO 算法与现有的扩散模型 finetune 算法 RWR[11] 相比,效果如何?
- 是否可以利用 VLM 来优化难以手动指定的奖励?
- 基于 RL finetune 的结果是否可以推广到训练时未曾见过的 prompt ?
4.1 算法间的比较
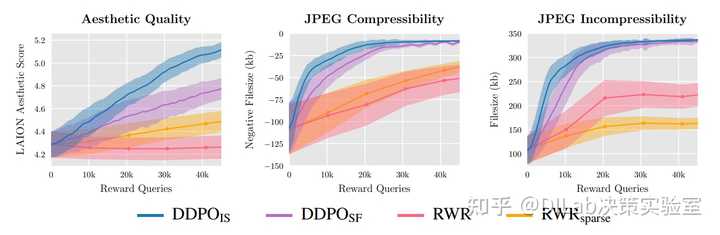
本节展示了 DDPO_{SF}, DDPO_{IS}, RWR, RWR_{sparse} 四种算法在 compressibility ,incompressibility 以及 aesthetic quality 三个任务上的影响。其中 compressibility 和 incompressibility 任务均匀地从 ImageNet-1000[12] 数据集中采样出 398 种动物作为提示词。而 aesthetic quality 任务则是从 45 种常见动物中均匀采样。实验效果如下,可以看到 DDPO_{IS} 的表现要优于其他算法。

下图可以更加直观地感受到 DDPO finetune 对扩散模型带来的影响。对 aesthetic quality 任务的优化使得采样结果更具有艺术性。最大化 compressibility 奖励值,使得采样结果移除了背景信息,并且保留下来的内容更加平滑。最大化 incompressibility 奖励值,会为采样结果引入更多高频噪声和更尖锐的边缘,从而提升 JPEG 的压缩难度。


4.2 自动提示对齐
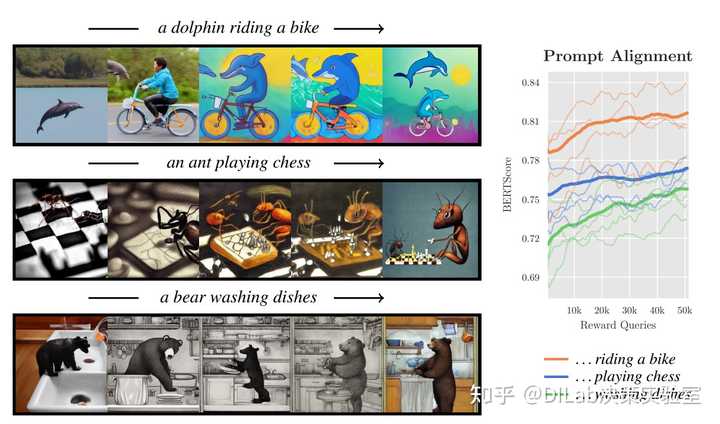
接下来,原论文评估了 VLMs 与 DDPO 结合的能力,以自动改善预训练模型的图像提示对齐,而无需额外的人工标签。本实验将重点放在 DDPO_{IS} 上,因为上面的实验可以发现它是最有效的算法。此任务的提示文本都具有 “a(n) [animal] [activity]”的形式,其中 "animal" 来自上文所述的 45 种常见动物,"activity" 从 3 个活动中选择:“骑自行车”,“下棋”和“洗碗”。
下图展示了 DDPO + VLM 所带来的效果。从右图可以看到三种活动的提示文本下,BERTScore 是波动上升的。从左图可以看出,随着 RL 训练的进行,图片内容愈发符合提示文本。

4.3 泛化性
在本实验中,原论文在 finetune 结束后,将提示文本中的主语和活动替换为 finetune 时未曾见过的内容以测试泛化性。结果发现模型对训练集外的动物,非生命体,或者新的活动,都会采样出预期的结果。
结果如下图所示:


最后,欢迎了解 OpenDILab 开源决策智能平台和社区,期待与广大开发者一起探索决策智能技术的最前沿!
5. 参考文献
[1] Black K, Janner M, Du Y, et al. Training diffusion models with reinforcement learning[J]. arXiv preprint arXiv:2305.13301, 2023.
[2] Training Diffusion Models with Reinforcement Learning (rl-diffusion.github.io)
[3] Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Reinforcement learning, pp. 5–32, 1992
[4] John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In International Conference on Machine Learning, 2015.
[5] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
[6] 令人拍案叫绝的JPEG图像压缩原理 - 知乎 (zhihu.com)
[7] Chrisoph Schuhmann. Laion aesthetics, Aug 2022. URL https:// laion.ai/blog/ laion-aesthetics/.
[8] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
[9] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. 2023.
[10] Tianyi Zhang, Varsha Kishore*, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. BERTScore: Evaluating text generation with BERT. In International Conference on Learning Representations, 2020.
[11] Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. Aligning text-to-image models using human feedback. arXiv preprint arXiv:2302.12192, 2023.
[12] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In Conference on Computer Vision and Pattern Recognition, 2009.
[13] Finetune Stable Diffusion Models with DDPO via TRL (huggingface.co)
[14] https:// pixabay.com/illustratio ns/a-book-read-old-literature-drawing-1840910/ (封面图源)
发布于 2024-03-21 12:33
・IP 属地上海