正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
一. 正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。
非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。这个地方不正确,有问题
此处用或任意一项都不能超过2位,如“(?<!95|98|NT|20)Windows正确,“(?<!95|980|NT|20)Windows 报错,若是单独使用则***制,如(?<!2000)Windows 正确匹配
小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode 字符集七个字符属性之一:标点字符。
其他六个属性:
L:字母;
M:标记符号(一般不会单独出现);
Z:分隔符(比如空格、换行等);
S:符号(比如数学符号、货币符号等);
N:数字(比如阿拉伯数字、罗马数字等);
C:其他字符。
*注:此语法部分语言不支持,例:javascript。
匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the\>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。
将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。
将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。
在linux中,通配符是由shell解释的,而正则表达式则是由命令解释的,下面我们就为大家介绍三种文本处理工具/命令:grep、sed、awk,它们三者均可以解释正则。
二. grep
1. grep指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为"-",则grep指令会从标准输入设备读取数据。
- grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][
-a或--text 不要忽略二进制的数据。
-A<显示列数>或--after-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之后的内容。
-b或--byte-offset 在显示符合范本样式的那一列之前,标示出该列***个字符的位编号。
-B<显示列数>或--before-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前的内容。
-c或--count 计算符合范本样式的列数。
-C<显示列数>或--context=<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作>或--directories=<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式>或--regexp=<范本样式> 指定字符串做为查找文件内容的范本样式。
-E或--extended-regexp 将范本样式为延伸的普通表示法来使用。
-f<范本文件>或--file=<范本文件> 指定范本文件,其内容含有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每列一个范本样式。
-F或--fixed-regexp 将范本样式视为固定字符串的列表。
-G或--basic-regexp 将范本样式视为普通的表示法来使用。
-h或--no-filename 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H或--with-filename 在显示符合范本样式的那一列之前,表示该列所属的文件名称。
-i或--ignore-case 忽略字符大小写的差别。
-l或--file-with-matches 列出文件内容符合指定的范本样式的文件名称。
-L或--files-without-match 列出文件内容不符合指定的范本样式的文件名称。
-n或--line-number 在显示符合范本样式的那一列之前,标示出该列的列数编号。
-q或--quiet或--silent 不显示任何信息。
-r或--recursive 此参数的效果和指定"-d recurse"参数相同。
-s或--no-messages 不显示错误信息。
-v或--revert-match 反转查找。
-V或--version 显示版本信息。
-w或--word-regexp 只显示全字符合的列。
-x或--line-regexp 只显示全列符合的列。
-y 此参数的效果和指定"-i"参数相同。
--help 在线帮助。
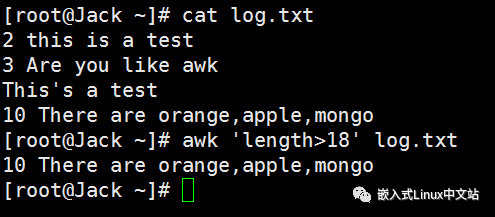
实例1 查找当前目录下包含”test“内容的所有文件
grep -r 匹配内容 目录,以递归的方式查找此目录及子目录下文件的内容
实例2 反向查找(-v)
查找文件中不包含”test“内容的行
2. egrep(扩展正则)
egrep执行效果与"grep-E"相似,使用的语法及参数可参照grep指令,与grep的不同点在于解读字符串的方法。
egrep是用extended regular expression语法来解读的,而grep则用basic regular expression 语法解读,extended regular expression比basic regular expression的表达更规范。
- egrep [范本模式] [文件或目录]
参数说明:
[范本模式] :查找的字符串规则。
[文件或目录] :查找的目标文件或目录。
实例1 查找当前目录下包含“Apple”内容的文件,并显示匹配的行
实例2 匹配用户配置文件中以“字母+数字+字母”命名的用户
三. sed
Linux sed命令是利用script来处理文本文件。
sed可依照script的指令,来处理、编辑文本文件。
Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
- sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
-e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
-f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
-h或--help 显示帮助。
-n或--quiet或--silent 仅显示script处理后的结果。
-V或--version 显示版本信息。
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
实例1 在“log.txt"的第4行后添加一行
实例2 将文件中的第2,3行删除并显示出来(注意,实际上”log.txt“文件并没有被修改)
实例3 将文件中的2,3行用”No 2-3 number“取代
实例4 匹配每一行是否有”is“,然后仅输出匹配的行的内容
实例5 匹配包含”is“的行,并将其中的’a‘替换为’A‘
{}内为执行的命令,每条命令之间用”;“隔开
实例6 多点编辑,将文件中的第3行删除,并将”test“替换为”TEST“
实例7 直接修改文件内容(危险动作)
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向! 不过,由於这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试!
在文件***一行插入一行内容”How are you today“,并保存
四. awk
之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的Family Name的首字符。
awk [选项参数]
'script'
var=value file(s)
awk [选项参数] -f scriptfile var=value file(s)
选项参数说明:
-F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v var=value or --asign var=value
赋值一个用户定义变量。
-f scripfile or --file scriptfile
从脚本文件中读取awk命令。
-mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的***块数目;-mr选项限制记录的***数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
-W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
-W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息。
-W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明。
-W lint or --lint
打印不能向传统unix平台移植的结构的警告。
-W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告。
-W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。
-W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
-W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用。
-W version or --version
打印bug报告信息的版本。